
第 4-1 章 Linux Ansible 入门知识
4.1、Ansible 简介
Ansible 是一个基于 Python 开发的配置管理和应用部署工具,现在也在自动化管理领域大放异彩。它融合了众多老牌运维工具的优点,Pubbet 和 Saltstack 能实现的功能,Ansible 基本上都可以实现。
Ansible 能批量配置、部署、管理一大堆的主机。比如以前需要切换到每个主机上执行的一或多个操作,使用Ansible 只需在固定的一台 Ansible 控制节点上去完成所有主机的操作。
Ansible 是基于模块工作的,它只是提供了一种运行框架,它本身没有完成任务的能力,真正执行操作的是 Ansible 的模块,比如 copy 模块用于拷贝文件到远程主机上,service 模块用于管理服务的启动、停止、重启等。
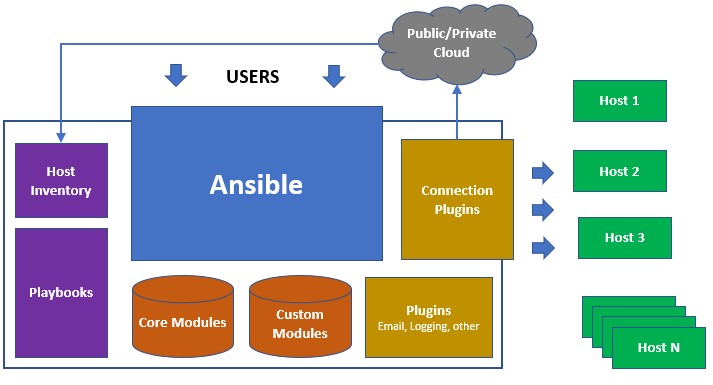
Ansible 其中一个比较鲜明的特性是 Agentless,即无 Agent 的存在,它就像普通命令一样,并非 C/S 软件,也只需在某个作为控制节点的主机上安装一次 Ansible 即可,通常它基于 ssh 连接来控制远程主机,远程主机上不需要安装 Ansible 或其它额外的服务。
Ansible 的另一个比较鲜明的特性是它的绝大多数模块都具备幂等性(idempotence)。重复执行某个任务绝大多数时候不会产生任何副作用。
4.2、Ansible 体验
4.2.1、Ansible 环境准备
Ansible 的作用是批量控制其它远程主机,并指挥远程主机节点做一些操作、完成一些任务。所以在这个结构中,分为控制节点和被控制节点。Ansible 是 Agentless 的软件,只需在控制节点安装 Ansible,被控制节点一般不需额外安装任何程序。
注意:Ansible 的模块是用 Python 来执行的,且默认远程连接的方式是 ssh,所以控制端和被控制端都需要有 Python 环境,并且被控制端需要启动 sshd 服务,但通常这两个条件在安装 Linux 系统时就已经具备了。所以使用 Ansible 的安装过程只有一个:在控制端安装 Ansible。
在本文中,将配置如下测试环境:包括一个 Ansible 控制节点和 7 个被控制节点。后面的文章中如果没有特别说明,也都使用此处的主机环境。
注意:该 Ansible 环境是基于 x86 架构,与 ARM64 架构使用方式相同。
| 主机 | IP 地址 | 主机名 | 操作系统 | Ansible 版本 |
|---|---|---|---|---|
| controller | 192.168.95.88 | controller | Centos79 | v2.9.27 |
| node1 | 192.168.95.131 | node1 | Centos79 | 无 |
| node2 | 192.168.95.132 | node2 | Centos79 | 无 |
| node3 | 192.168.95.133 | node3 | Centos79 | 无 |
| node4 | 192.168.95.134 | node4 | Centos79 | 无 |
| node5 | 192.168.95.135 | node5 | Centos79 | 无 |
| node6 | 192.168.95.136 | node6 | Centos79 | 无 |
| node7 | 192.168.95.137 | node7 | Centos79 | 无 |
所有主机上都已启动 sshd 服务并监听在 22 端口上。因为有时候也会使用主机名去控制目标节点,所以这里也在 controller 节点上配置了其余 7 个节点的 DNS 解析,可在 controller 节点的 /etc/hosts 文件中加入如下内容:
[root@controller ~]# cat >>/etc/hosts<<EOF
192.168.95.131 node1
192.168.95.132 node2
192.168.95.133 node3
192.168.95.134 node4
192.168.95.135 node5
192.168.95.136 node6
192.168.95.137 node7
EOF4.2.2、安装 Ansible
官方文档:https://docs.ansible.com/ansible/latest/
对于 RHEL 系列的系统来说,配置好 epel 镜像即可安装最新版的 Ansible。使用阿里云的 epel 源。
[root@controller ~]# wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
[root@controller ~]# yum info ansible
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: mirrors.aliyun.com
* extras: mirrors.njupt.edu.cn
* updates: mirrors.aliyun.com
Available Packages
Name : ansible
Arch : noarch
Version : 2.9.27
Release : 1.el7
Size : 17 M
Repo : epel/x86_64
Summary : SSH-based configuration management, deployment, and task execution system
URL : http://ansible.com
License : GPLv3+
Description : Ansible is a radically simple model-driven configuration management,
: multi-node deployment, and remote task execution system. Ansible works
: over SSH and does not require any software or daemons to be installed
: on remote nodes. Extension modules can be written in any language and
: are transferred to managed machines automatically.然后安装即可:
[root@controller ~]# yum install ansible -yAnsible 每个版本释放出来之后,都首先提交到 Pypi,所以任何操作系统,都可以使用 pip 工具来安装最新版的 Ansible。
[root@controller ~]# pip3 install ansible- 注意:python2.x 的环境和 python3.x 的环境是不兼容的,需要注意区分。
- 注意:使用各系统的包管理工具(如 yum)安装 Ansible 时会自动提供一些配置文件,如 /etc/ansible/ansible.cfg。而使用 pip 安装的 Ansible 默认不提供配置文件。
4.2.3、Ansible 命令补全
从 Ansible 2.9 版本开始,它支持命令的选项补全功能,它依赖于 python 的 argcomplete 插件。
安装 argcomplete:
# CentOS/RHEL
yum -y install python-argcomplete
# 任何系统都可以使用pip工具安装argcomplete
pip3 install argcomplete安装完成后,还需激活该插件:
# 要求bash版本大于等于4.2
sudo activate-global-python-argcomplete
# 如果bash版本低于4.2,则单独为每个ansible命令注册补全功能
eval $(register-python-argcomplete ansible)
eval $(register-python-argcomplete ansible-config)
eval $(register-python-argcomplete ansible-console)
eval $(register-python-argcomplete ansible-doc)
eval $(register-python-argcomplete ansible-galaxy)
eval $(register-python-argcomplete ansible-inventory)
eval $(register-python-argcomplete ansible-playbook)
eval $(register-python-argcomplete ansible-pull)
eval $(register-python-argcomplete ansible-vault)最后,退出当前 Shell 重新进入,或者简单的直接执行如下命令即可:
exec $SHELL然后就可以按 tab 一次或两次补全参数或提示参数。例如,下面选项输入到一半的时候,按一下 tab 键就会补全得到 ansible --syntax-check。
ansible --syn4.2.4、配置主机互信
因为 Ansible 默认是基于 ssh 连接的,所以要控制其它节点首先需要建立好 ssh 连接,而建立 ssh 连接要么需要提供密码,要么需要配置好认证方式。为了方便后文的测试,这里先配置好 controller 和其它被控节点之间的主机互信。
为了避免配置主机互信过程中的交互式询问,这里使用 ssh-keyscan 工具添加主机认证信息以及 sshpass 工具(安装 Ansible 时会自动安装 sshpass,也可以 yum -y install sshpass 安装)直接指定 ssh 连接密码。
- 在 controller 节点上生成密钥对
ssh-keygen -t rsa -f ~/.ssh/id_rsa -N ''- 将各节点的主机信息(host key)写入 controller 的
~/.ssh/known_hosts文件
for host in node{1..7};do
ssh-keyscan $host >>~/.ssh/known_hosts 2>/dev/null
done- 将 controller 上的 ssh 公钥分发给各节点
# sshpass -p 选项指定的是密码
for host in node{1..7};do
sshpass -p'123456' ssh-copy-id root@$host &>/dev/null
done注意:通过上面三步可以完成 controller 到其它 7 个主机的免密认证,但是反过来其它主机到 controller 不是免密认证。
4.2.5、Ansible 体验
前面我们提到过,Ansible 的功能之所以强大,是因为 Ansible 提供了成千上万个模块,每个模块都对应一个功能。其中 100 多个核心模块是 Ansible 团队自己维护的,剩余的模块都是 Ansible 社区维护。另外,Ansible 也允许用户自定义模块,解决某些个性化的问题 。
在控制节点上执行:
[root@controller ~]# ansible localhost -m copy -a 'src=/etc/passwd dest=/tmp'
localhost | CHANGED => {
"changed": true,
"checksum": "f46e74616780e28c950837c16571665b058c3233",
"dest": "/tmp/passwd",
"gid": 0,
"group": "root",
"md5sum": "388824fe0e2029fba5ef752f0e0fab2c",
"mode": "0644",
"owner": "root",
"size": 798,
"src": "/root/.ansible/tmp/ansible-tmp-1657750978.04-11732-253772452173510/source",
"state": "file",
"uid": 0
}- 该命令的作用是拷贝本机的 /etc/passwd 文件到本机的 /tmp 目录下。
- 其中的 ansible 是一个命令,这个自不需要多做解释。除 ansible 命令外,后面还会用到 ansible-playbook 命令。
- localhost 参数表示 ansible 要控制的节点,即 ansible 将指挥本机执行任务。
- 执行任务主要是执行模块,模块的执行还可以依赖一些模块参数。在 ansible 命令行中,使用 -m Module 来指定要执行哪个模块,即执行什么任务,使用 -a ARGS 来指定模块运行时的参数。
- 本示例中的模块为 copy 模块,传递给 copy 模块的参数包含两项:
src=/etc/passwd指定源文件dest=/tmp指定拷贝的目标路径
初学之时,只需学习一些常用的模块,在本文以及后面的文章中会介绍一些常见模块的功能以及用法。熟悉了 Ansible 之后,再按需求到官方手册中去寻找:https://docs.ansible.com/ansible/latest/modules/modules_by_category.html。
有时候为了方便快速寻找模块,可以使用 ansible-doc -l | grep 'xxx' 命令来筛选模块。例如,想要筛选具有拷贝功能的模块:
[root@controller ~]# ansible-doc -l | grep "copy"
vsphere_copy Copy a file to a VMware datastore
win_copy Copies files to remote locations on windows ho...
bigip_file_copy Manage files in datastores on a BIG-IP
ec2_ami_copy copies AMI between AWS regions, return new ima...
win_robocopy Synchronizes the contents of two directories u...
copy Copy files to remote locations
na_ontap_lun_copy NetApp ONTAP copy LUNs
icx_copy Transfer files from or to remote Ruckus ICX 70...
unarchive Unpacks an archive after (optionally) copying ...
ce_file_copy Copy a file to a remote cloudengine device ove...
postgresql_copy Copy data between a file/program and a Postgre...
ec2_snapshot_copy copies an EC2 snapshot and returns the new Sna...
nxos_file_copy Copy a file to a remote NXOS device
netapp_e_volume_copy NetApp E-Series create volume copy pairs根据描述,大概找出是否有想要的模块。找到模块后,想要看看它的功能描述以及用法,可以继续使用 ansible-doc 命令。
# 详细的模块描述手册
ansible-doc copy
# 只包含模块参数用法的模块描述手册
ansible-doc -s copy再来一个示例,通过 Ansible 删除本地文件 /tmp/passwd。需要使用的模块是 file 模块,file 模块的主要作用是创建或删除文件/目录。
ansible localhost -m file -a 'path=/tmp/passwd state=absent'- 参数
path=指定要操作的文件路径,state=参数指定执行何种操作,此处指定为 absent 表示删除操作。
Ansible 的很多模块都提供了一个 state 参数,它是一个非常重要的参数。它的值一般都会包含 present 和 absent 两种状态值(并非一定),不同模块的 present 和 absent 状态表示的含义不同,但通常来说,present 状态表示肯定、存在、会、成功等含义,absent 则相反,表示否定、不存在、不会、失败等含义。
例如这里的 file 模块,absent 状态表示递归删除文件 / 目录,类似于 rm -r 命令,touch 状态和 touch 命令的功能一样,directory 状态表示递归创建目录,类似于 mkdir -p 命令。
所以,在本地创建文件、创建目录的命令如下:
# 创建文件
ansible localhost -m file -a 'path=/tmp/a.log state=touch'
# 创建目录
ansible localhost -m file -a 'path=/tmp/dir1/dir2 state=directory'再说一个 debug 模块,顾名思义,用于输出或调试一些数据。debug 模块的用法非常简单,就两个常用参数:msg 参数和 var 参数。这两个参数是互斥的,所以只能使用其中一个。msg 参数可以输出字符串,也可以输出变量的值;var 参数只能输出变量的值。
例如,输出 ”hello world”,需要使用 msg 参数:
[root@controller ~]# ansible localhost -m debug -a 'msg="hello world"'
localhost | SUCCESS => {
"msg": "hello world"
}Ansible 中也支持使用变量,这里仅演示最简单的设置变量和引用变量的方式。ansible 命令的 -e 选项或 --extra-vars 选项可以设置变量,设置的方式为 -e 'var1="aaa" var2="bbb"'。
例如,设置变量后使用 debug 的 msg 参数输出:
[root@controller ~]# ansible localhost -e 'str=world' -m debug -a 'msg="hello {{str}}"'
localhost | SUCCESS => {
"msg": "hello world"
}- 注意上面示例中的
msg="hello {{str}}",Ansible 的字符串是可以不用引号去包围的,例如msg=hello是允许的,但如果字符串中包含了特殊符号,则可能需要使用引号去包围,例如此处的示例出现了会产生歧义的空格。 - 此外,要区分变量名和普通的字符串,需要在变量名上加一点标注:用
{}包围 Ansible 的变量,这其实是 Jinja2 模板的语法。其实不难理解,它的用法和 Shell 下引用变量使用$符号或${}是一样的,例如echo "hello ${var}"。
debug 模块除了 msg 参数,还有一个 var 参数,它只能用来输出变量(还包括以后要介绍的 Jinja2 表达式),而且 var 参数引用变量的时候,不能使用 {} 包围,因为 var 参数已经隐式地包围了一层 {}。例如:
[root@controller ~]# ansible localhost -e 'str="hello world"' -m debug -a 'var=str'
localhost | SUCCESS => {
"str": "hello world"
}4.3、Ansible 配置文件
通过操作系统自带的包管理器(比如 yum、dnf、apt)安装的 Ansible 一般都会提供好 Ansible 的配置文件 /etc/ansible/ansible.cfg。
这是 Ansible 默认的全局配置文件。实际上,Ansible 支持 4 种方式指定配置文件,它们的解析顺序从上到下:
ANSIBLE_CFG:环境变量指定的配置文件。ansible.cfg:当前目录下的 ansible.cfg。~/.ansible.cfg:家目录下的 ansible.cfg。/etc/ansible/ansible.cfg:默认的全局配置文件。
Ansible 配置文件采用 ini 风格进行配置,每一项配置都使用 key=value 的方式进行配置。
例如,下面是我从默认的 /etc/ansible/ansible.cfg 中截取的 [defaults] 段落和 [inventory] 段落的部分配置信息。
[defaults]
# some basic default values...
#inventory = /etc/ansible/hosts
#library = /usr/share/my_modules/
#module_utils = /usr/share/my_module_utils/
#remote_tmp = ~/.ansible/tmp
#local_tmp = ~/.ansible/tmp
#plugin_filters_cfg = /etc/ansible/plugin_filters.yml
#forks = 5
[inventory]
#enable_plugins = host_list, virtualbox, yaml, constructed
#ignore_extensions = .pyc, .pyo, .swp, .bak, ~, .rpm, .md, .txt, ~, .orig, .ini, .cfg, .retry
#ignore_patterns=
#unparsed_is_failed=False4.4、Inventory
让 Ansible 发挥强大作用的第一步是配置 inventory。inventory 表示清单的意思,在计算机领域里往往表示的资源清单,在 Ansible 中它表示主机节点清单,也是资源的一种。通过配置 inventory,就可以定义哪些目标主机是可以被控制的。
4.4.1、Inventory 文件路径
默认的 inventory 文件是 /etc/ansible/hosts,可以通过 Ansible 配置文件的 inventory 配置指令去修改路径。
grep '/etc/ansible/hosts' /etc/ansible/ansible.cfg
#inventory = /etc/ansible/hosts但通常不会去修改这个配置项,如果在其它地方定义了 inventory 文件,可以直接在 ansible 的命令行中使用 -i 选项去指定自定义的 inventory 文件。
ansible -i /tmp/myinv.ini ...
ansible-playbook -i /tmp/myinv.ini ...4.4.2、配置 Inventory
Ansible inventory 文件的书写格式遵循 ini 配置格式。从 Ansible 2.4 开始支持其它格式,比如 yaml 格式的 inventory。此处以 ini 格式为例,循序渐进地介绍 inventory 的规则。假设所有的规则都定义在 /etc/ansible/hosts 文件中。
4.4.2.1、一行一主机的定义方式
Ansible 默认是基于 ssh 连接的,所以一般情况下 inventory 中的每个目标节点都配置主机名或 IP 地址、sshd 监听的端口号、连接的用户名和密码、ssh 连接时的参数等等。当然,很多参数有默认值,所以最简单的是直接指定主机名或 IP 地址即可。
例如,在默认的 inventory 文件 /etc/ansible/hosts 添加几个目标主机:
node1
node2 ansible_host=192.168.95.132
192.168.95.133
192.168.95.134:22
192.168.95.13[5:6] ansible_port=22- 第一行通过主机名定义,在 ansible 连接该节点时会进行主机名 DNS 解析。
- 第二行也是通过主机名定义,但是使用了一个主机变量 ansible_host=IP,此时该 ansible 去连接该主机时将直接通过 IP 地址进行连接,而不会进行 DNS 解析,此时 node2 相当于主机别名并且可以命名为任何其它名称。
- 第三行通过 IP 地址定义主机节点。
- 第四行通过 IP 地址和端口号定义主机节点。
- 最后一行通过范围的方式展开成了两个主机节点 192.168.95.135 和 192.168.95.136,同时还定义了这两个节点的主机变量 ansible_port=22 表示连接这两个主机时的端口号为 22。
范围展开的方式还支持字母范围。下面都是有效的:
范围表示 展开结果
--------------------
a[1:3] --> a1,a2,a3
[08:12] --> 08,09,10,11,12
a[a:c] --> aa,ab,ac上面示例中使用了两个主机变量 ansible_port 和 ansible_host,它们直接定义在主机的后面,这些变量都是连接目标主机时的行为控制变量,通常它们都能见名知意。Ansible 支持很多个连接时的行为控制变量,而且不同版本的 Ansible 的行为控制变量名称可能还不同,比如在以前版本中指定端口号的行为变量是 ansible_ssh_port。
完整的连接行为控制变量参见官方手册。
这样定义之后,Ansible 就可以控制任何一个目标主机了:
ansible node1 -m copy -a 'src=/etc/passwd dest=/tmp'
ansible 192.168.95.133 -m copy -a 'src=/etc/passwd dest=/tmp'4.4.2.2、Inventory 中的普通变量
在定义 inventory 时,除了可以指定连接的行为控制变量,也可以指定 Ansible 的普通变量,以便在 ansible 执行任务时使用。
node1 node1_var="hello world"
node2 ansible_host=192.168.95.132在 ansible 执行任务时可以引用普通变量:
$ ansible node1 -m debug -a 'var=node1_var'
node1 | SUCCESS => {
"node1_var": "hello world"
}4.4.2.3、主机分组
上面的示例中是每行单独定义一个主机,这样的方式虽然简单,但是极其不方便管理多个节点。为此,Inventory 支持对主机进行分组,每个组内可以定义多个主机,每个主机都可以定义在任何一个或多个主机组内。
node1 node1_var="hello world"
node2 ansible_host=192.168.95.132
192.168.95.133
192.168.95.134:22
192.168.95.13[5:6] ansible_port=22
[nginx]
192.168.95.131
192.168.95.132 ansible_password='123456'
192.168.95.133
[apache]
192.168.95.13[4:7]
[mysql]
192.168.95.131
192.168.95.132- 这里定义了 3 个主机组:nginx 主机组、apache 主机组和 mysql 主机组。nginx 组包含 3 个节点,apache 主机组包含 4 个节点,mysql 主机组包含 2 个节点。
- Ansible 默认预定义了两个主机组:all 分组和 ungrouped 分组。
all分组中包含所有分组内的节点ungrouped分组包含所有不在分组内的节点- 这两个分组都不包含 localhost 这个特殊的节点
需要注意的是,mysql 组中的节点也同时存在于 nginx 组内,一个主机同时存在于多个组内是允许也是必要的功能,只有这样才能更为灵活的对各个节点进行分类管理。
有了主机组,就可以让 ansible 控制一个组,从而让该组内所有主机执行任务:
ansible apache -m copy -a 'src=/etc/passwd dest=/tmp'定义了 inventory 之后,可以使用 ansible --list 或 ansible--playbook --list 命令来查看主机组的信息,还可以使用更为专业的 ansible-inventory 命令来查看主机组信息。
# 使用ansible或ansible-playbook列出所有主机
[root@controller ~]# ansible -i /etc/ansible/hosts nginx --list
hosts (3):
192.168.95.131
192.168.95.132
192.168.95.133
# 使用ansible-inventory列出nginx组中的主机
[root@controller ~]# ansible-inventory -i /etc/ansible/hosts nginx --graph
@nginx:
|--192.168.95.131
|--192.168.95.132
|--192.168.95.133
# 使用ansible-inventory列出nginx组中的主机,同时带上变量
[root@controller ~]# ansible-inventory nginx --graph --vars
@nginx:
|--192.168.95.131
|--192.168.95.132
| |--{ansible_password = 123456}
|--192.168.95.133
# 使用ansible-inventory列出all组内的主机
[root@controller ~]# ansible-inventory --graph all
@all:
|--@apache:
| |--192.168.95.134
| |--192.168.95.135
| |--192.168.95.136
| |--192.168.95.137
|--@mysql:
| |--192.168.95.131
| |--192.168.95.132
|--@nginx:
| |--192.168.95.131
| |--192.168.95.132
| |--192.168.95.133
|--@ungrouped:
| |--node1
| |--node2
# 使用ansible-inventory以json格式列出所有主机的信息
[root@controller ~]# ansible-inventory --list4.4.2.4、主机组变量
有了主机组之后,可以直接为主机组定义变量,这样组内的所有主机都具有该变量。
[nginx]
192.168.95.131
192.168.95.132 ansible_password='123456'
192.168.95.133
[nginx:vars]
ansible_password='123456'
[all:vars]
ansible_port=22
[ungrouped:vars]
ansible_port=22- 上面
[nginx:vars]表示为 nginx 组内所有主机定义变量ansible_password='123456'。而[all:vars]和[ungrouped:vars]分别表示为 all 和 ungrouped 这两个特殊的主机组内的所有主机定义变量。
4.4.2.5、组嵌套
Inventory 还支持主机组的分组嵌套,可以通过 [GROUP:children] 的方式定义一个主机组,并在其中包含子组。
[nginx]
192.168.95.131
192.168.95.132 ansible_password='123456'
192.168.95.133
[apache]
192.168.95.13[4:7]
[mysql]
192.168.95.131
192.168.95.132
[webservers:children]
nginx
apache
[centos7:children]
webservers # 递归嵌套
mysql4.4.2.6、Multi Inventory 文件
当 Ansible 要管理的节点非常多时,仅靠分组的逻辑可能也不足够方便管理,这个时候可以定义多个 inventory 文件并放在一个目录下,并按一定的命名规则为每个 inventory 命名,以便见名知意。
例如,创建一个名为 /etc/ansible/inventorys 的目录,在其中定义 web 和 database 两个 inventory 文件:
/etc/ansible/inventorys/
├── web
└── database内容分别如下:
# /etc/ansible/inventorys/web的内容:
[nginx]
192.168.95.131
192.168.95.132 ansible_password='123456'
192.168.95.133
[apache]
192.168.95.13[4:7]
[web:children]
apache
nginx
# /etc/ansible/inventorys/database的内容:
[mysql]
192.168.95.131
192.168.95.132现在要使用多个 inventory 的功能,需要将 inventory 指定为目录路径。
例如,Ansible 配置文件将 inventory 指令设置为对应的目录:
inventory = /etc/ansible/inventorys或者,ansible 或 ansible-playbook 命令使用 -i INVENTORY 选项指定的路径应当为目录。
执行下面的命令将列出所有主机:
ansible-inventory -i /etc/ansible/inventorys --graph allinventory 指定为目录时,inventory 文件最好不要带有后缀,就像示例中的 web 和 database 文件。因为 Ansible 当使用目录作为 inventory 时,默认将忽略一些后缀的文件,不去解析。需要修改配置文件中的 inventory_ignore_extensions 项来禁止忽略指定后缀(如 ini 后缀)的文件。
#inventory_ignore_extensions = ~, .orig, .bak, .ini, .cfg, .retry, .pyc, .pyo
inventory_ignore_extensions = ~, .orig, .bak, .cfg, .retry, .pyc, .pyo4.4.3、实验 Inventory 文件
下面是本文使用的 inventory 文件 /etc/ansible/hosts 的内容,在后面的文章中如果没有特别说明,也将使用此处的 inventory 配置。
[nginx]
192.168.95.131
192.168.95.132
192.168.95.133
[apache]
192.168.95.13[4:7]
[webservers:children]
nginx
apache
[mysql]
192.168.95.1374.5、Playbook
ansible 命令每次只能执行一个任务,这种运行方式称为 Ad-hoc(点对点模式);ansible playbook 可以集成多个任务,编排好任务的执行顺序,像电影剧本一样一直演下去直到杀青。
4.5.1、playbook、play 和 task 的关系
playbook 相当于一整套电视剧剧本,play 相当于一集片段,tasks 相当于一集片段当中的某一节剧情。
- playbook 中可以定义一个或多个 play。
- 每个 play 中可以定义一个或多个 task。
- 其中还可以定义两类特殊的 task:pre_tasks 和 post_tasks。
- pre_tasks 表示执行执行普通任务之前执行的任务列表。
- post_tasks 表示普通任务执行完之后执行的任务列表。
- 其中还可以定义两类特殊的 task:pre_tasks 和 post_tasks。
- 每个 play 都需要通过 hosts 指令指定要执行该 play 的目标主机。
- 每个 play 都可以设置一些该 play 的环境控制行为,比如定义 play 级别的变量。
例如,下面是一个 playbook 示例,文件名为 first.yml,内容如下:
---
- name: play 1
hosts: nginx
gather_facts: false
tasks:
- name: task1 in play1
debug:
msg: "output task1 in play1"
- name: task2 in play1
debug:
msg: "output task2 in play1"
- name: play 2
hosts: apache
gather_facts: false
tasks:
- name: task1 in play2
debug:
msg: "output task1 in play2"
- name: task2 in play2
debug:
msg: "output task2 in play2"- playbook 中包含两个 play:”play 1” 和 ”play 2”,每个 play 中又包含了两个 task。且执行 ”play 1” 的是 nginx 主机组中的主机节点,执行 ”play 2” 的是 apache 主机组中的主机节点。
使用 ansible-playbook 命令执行这个 playbook:
[root@controller ~]# ansible-playbook first.yml
PLAY [play 1] ***************************************************************************************************
TASK [task1 in play1] *******************************************************************************************
ok: [192.168.95.131] => {
"msg": "output task1 in play1"
}
ok: [192.168.95.132] => {
"msg": "output task1 in play1"
}
ok: [192.168.95.133] => {
"msg": "output task1 in play1"
}
......
PLAY RECAP ******************************************************************************************************
192.168.95.131 : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.95.132 : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.95.133 : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.95.134 : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.95.135 : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.95.136 : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.95.137 : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0对照输出结果和 first.yml 中的定义,可以很容易对应上执行的流程。
4.5.2、YAML 语法
ansible 的 playbook 采用 yaml 语法,它以非常简洁的方式实现了 json 格式的事件描述。yaml 之于 json 就像 markdown 之于 html 一样,极度简化了 json 的书写。
YAML 文件后缀通常为 .yaml 或 .yml。
YAML 在不少工具里都使用,学习它是”一次学习、终生受益”的,所以很有必要把 yaml 的语法格式做个梳理,系统性地去学一学。
YAML 的基本语法规则如下:
- 使用缩进表示层级关系。
- 缩进时不允许使用 Tab 键,只允许使用空格。
- 缩进的空格数目不重要,只要相同层级的元素左对齐即可。
- yaml 文件以 "---" 作为文档的开始,以表明这是一个 yaml 文件。当然 "---" 可以省略。
#表示注释,从这个字符开始到结尾,都会被解析器忽略。- 字符串不用加引号,但在可能产生歧义时,加引号(单双引号都可以)。
- 布尔值非常灵活,不区分大小写的 true/false、yes/no、on/off、y/n、0 和 1 都允许。
YAML 支持三种数据结构:
- 对象:key/value 格式,也称为哈希结构、字典结构或关联数组。
- 数组:也称为列表。
- 标量(scalars):单个值。
可以去找一些在线 YAML 转换 JSON 网站,比如http://yaml-online-parser.appspot.com,通过在线转换可以验证或查看自己所写的 YAML 是否出错以及哪里出错。也可以安装 yq(yaml query) 命令将 yaml 数据转换成 json 格式数据。
yum -y install jq
pip3 install yq
cat a.yml | yq .4.5.2.1、对象
一组键值对,使用冒号隔开 key 和 value。注意,冒号后必须至少一个空格。
name: junmajinlong等价于 json:
{
"name": "junmajinlong"
}4.5.2.2、数组
---
- Shell
- Perl
- Python等价于 json:
["Shell","Perl","Python"]也可以使用行内数组(内联语法)的写法:
---
["Shell","Perl","Python"]再例如:
---
- lang1: Shell
- lang2: Perl
- lang3: Python等价于 json:
[
{"lang1": "Shell"},
{"lang2": "Perl"},
{"lang3": "Python"}
]将对象和数组混合:
---
languages:
- Shell
- Perl
- Python等价于 json:
{
"languages": ["Shell","Perl","Python"]
}4.5.2.3、字典
---
person1:
name: junmajinlong
age: 18
gender: male
person2:
name: xiaofanggao
age: 19
gender: female等价于 json:
{
"person2": {
"gender": "female",
"age": 19,
"name": "xiaofanggao"
},
"person1": {
"gender": "male",
"age": 18,
"name": "junmajinlong"
}
}也可以使用行内对象的写法:
---
person1: {name: junmajinlong, age: 18, gender: male}4.5.2.4、复合结构
---
- person1:
name: junmajinlong
age: 18
langs:
- Perl
- Ruby
- Shell
- person2:
name: xiaofanggao
age: 19
langs:
- Python
- Javascript等价于 json:
[
{
"langs": [
"Perl",
"Ruby",
"Shell"
],
"person1": null,
"age": 18,
"name": "junmajinlong"
},
{
"person2": null,
"age": 19,
"langs": [
"Python",
"Javascript"
],
"name": "xiaofanggao"
}
]4.5.2.5、字符串续行
字符串可以写成多行,从第二行开始,必须至少有一个单空格缩进。换行符会被转为空格。
str: hello
world
hello world等价于 json:
{
"str": "hello world hello world"
}也可以使用 > 换行,它类似于上面的多层缩进写法。此外,还可以使用 | 在换行时保留换行符。
this: |
Foo
Bar
that: >
Foo
Bar等价于 json:
{'that': 'Foo Bar', 'this': 'Foo\nBar\n'}4.5.2.6、空值
YAML 中某个 key 有时候不想为其赋值,可以直接写 key 但不写 value,另一种方式是直接写 null,还有一种比较少为人知的方式:波浪号 ~。
例如,下面几种方式全是等价的:
key1:
key2: null
key3: Null
key4: NULL
key5: ~4.5.2.7、单双引号和转义
YAML 中的字符串是可以不用使用引号包围的,但是如果包含了特殊符号,则需要使用引号包围。
单引号包围字符串时,会将特殊符号保留。
双引号包围字符串时,反斜线需要额外进行转义。
例如,下面几对书写方式是等价的:
- key1: "~"
- key2: '~'
- key3: '\.php$'
- key4: "\\.php$"
- key5: \.php$
- key6: \n
- key7: '\n'
- key8: "\\n"等价于 json:
[
{ "key1": "~" },
{ "key2": "~" },
{ "key3": "\\.php$" },
{ "key4": "\\.php$" },
{ "key5": "\\.php$" },
{ "key6": "\\n" },
{ "key7": "\\n" },
{ "key8": "\\n" }
]4.5.3、playbook 的写法
了解 YAML 写法之后,就可以来写 Ansible 的 playbook 了。
回顾一下前文对 playbook、play 和 task 关系的描述,playbook 可以包含一个或多个 play,每个 play 可以包含一个或多个任务,且每个 play 都需要指定要执行该 play 的目标主机。
于是,将下面这个 ad-hoc 模式的 ansible 任务改成等价的 playbook 模式:
$ ansible nginx -m copy -a 'src=/etc/passwd dest=/tmp'假设这个 playbook 的文件名为 copy.yml,其内容如下:
---
- hosts: nginx
gather_facts: false
tasks:
- copy: src=/etc/passwd dest=/tmp然后使用 ansible-playbook 命令执行该 playbook。
$ ansible-playbook copy.yml再来解释一下这个 playbook 文件的含义。
playbook 中,每个 play 都需要放在数组中,所以在 playbook 的顶层使用列表的方式 - xxx: 来表示这是一个 play(此处是 - hosts:)。
每个 play 都必须包含 hosts 和 tasks 指令。
hosts 指令用来指定要执行该 play 的目标主机,可以是主机名,也可以是主机组,还支持其它方式来更灵活的指定目标主机。具体的规则后文再做介绍。
tasks 指令用来指定这个 play 中包含的任务,可以是一个或多个任务,任务也需要放在 play 的数组中,所以 tasks 指令内使用 - xxx: 的方式来表示每一个任务(此处是 - copy:)。
gather_facts 是一个 play 级别的指令设置,它是一个负责收集目标主机信息的任务,由 setup 模块提供。默认情况下,每个 play 都会先执行这个特殊的任务,收集完信息之后才开始执行其它任务。
但是,收集目标主机信息的效率很低,如果能够确保 playbook 中不会使用到所收集的信息,可以显式指定 gather_facts: no 来禁止这个默认执行的收集任务,这对效率的提升是非常可观的。
此外每个 play 和每个 task 都可以使用 name 指令来命名,也建议尽量为每个 play 和每个 task 都命名,且名称具有唯一性。
所以,将上面的 playbook 改写:
---
- name: first play
hosts: nginx
gather_facts: false
tasks:
- name: copy /etc/passwd to /tmp
copy: src=/etc/passwd dest=/tmp4.5.4、playbook 模块参数的传递方式
在刚才的示例中,copy 模块的参数传递方式如下:
tasks:
- name: copy /etc/passwd to /tmp
copy: src=/etc/passwd dest=/tmp这是标准的 yaml 语法,参数部分 src=/etc/passwd dest=/tmp 是一个字符串,当作 copy 对应的值。
根据前面介绍的 yaml 语法,还可以换行书写。有以下几种方式:
---
- name: first play
hosts: nginx
gather_facts: false
tasks:
- copy:
src=/etc/passwd dest=/tmp
- copy:
src=/etc/passwd
dest=/tmp
- copy: >
src=/etc/passwd
dest=/tmp
- copy: |
src=/etc/passwd
dest=/tmp除此之外,Ansible 还提供了另外两种传递参数的方式:
- 将参数和参数值写成
key: value的方式 - 使用
args参数声明接下来的是参数
通过示例便可对其用法一目了然:
---
- name: first play
hosts: nginx
gather_facts: false
tasks:
- name: copy1
copy:
src: /etc/passwd
dest: /tmp
- name: copy2
copy:
args:
src: /etc/passwd
dest: /tmp大多数时候,使用何种方式传递参数并无关紧要,只要个人觉得可读性高、方便、美观即可。
4.5.5、play 的目标主机
每一个 play 都包含 hosts 指令,它用来指示在解析 inventory 之后选择哪些主机执行该 play 中的 tasks。
hosts 指令通过 pattern 的方式来筛选节点,pattern 的指定方式有以下几种规则:
- 直接指定 inventory 中定义的主机名
hosts: localhost
- 直接指定 inventory 中的主机组名
hosts: nginxhosts: all
- 使用组名时,可以使用数值索引的方式表示组中的第几个主机
hosts: nginx[1]:mysql[0]
- 可使用冒号或逗号隔开多个 pattern
hosts: nginx:localhost
- 可以使用范围表示法
hosts: 192.168.200.3[0:3]hosts: web[A:D]
- 可以使用通配符
*hosts: *.example.comhosts: *,这等价于hosts: all
- 可以使用正则表达式,需使用
~开头hosts: ~(web|db)\.example\.com
此外:
- 所有 pattern 选中的主机都是包含性的,第一个 pattern 选中的主机会添加到下一个 pattern 的范围内,直到最后一个 pattern 筛选完,于是取得了所有 pattern 匹配的主机。
- pattern 前面加一个
&符号表示取交集pattern1:&pattern2要求同时存在于 pattern1 和 pattern2 中的主机
- pattern 前面加一个
!符号表示排除pattern1:!pattern2要求出现在 pattern1 中但未出现在 pattern2 中
4.6、默认的任务执行策略
假设有 10 个目标节点要执行某个 play 中的 3 个任务:tA、tB、tC。
默认情况下,会从 10 个目标节点中选择 5 个节点作为第一批次的节点执行任务 tA,第一批次的 5 个节点都执行 tA 完成后,将选择剩下的 5 个节点作为第二批次执行任务 tA。
所有节点都执行完任务 tA 后,第一批次的 5 节点开始执行任务 tB,然后第二批次的 5 个节点执行任务 tB。
所有节点都执行完任务 tB 后,第一批次的 5 节点开始执行任务 tC,然后第二批次的 5 个节点执行任务 tC。
整个过程如下:
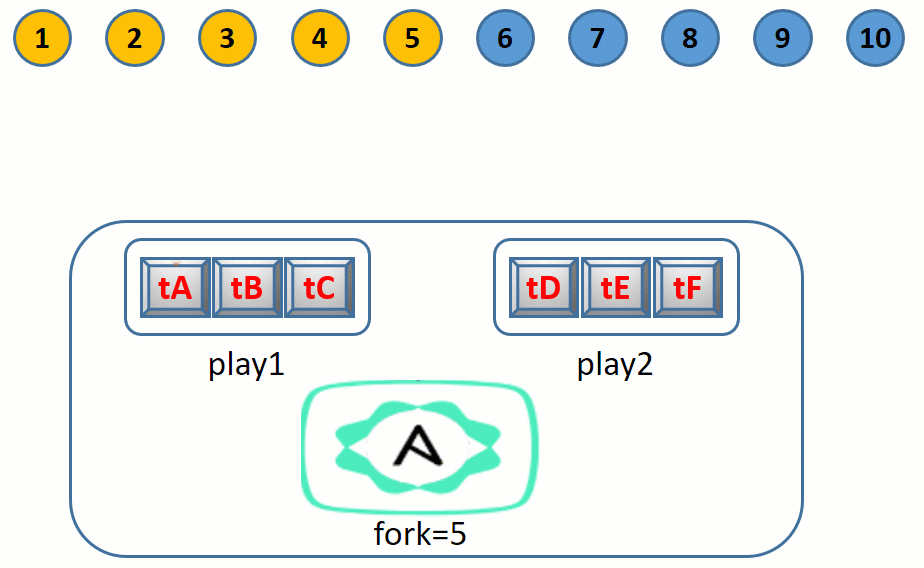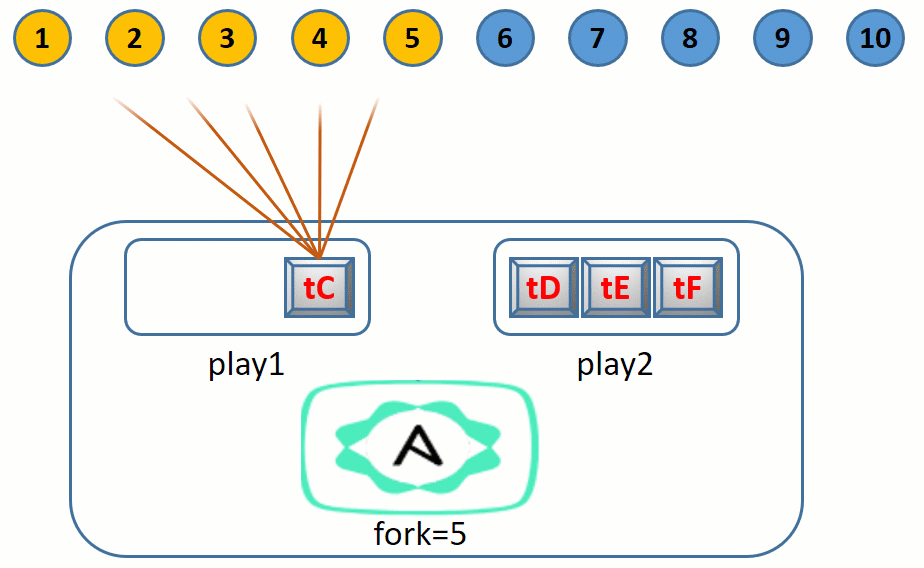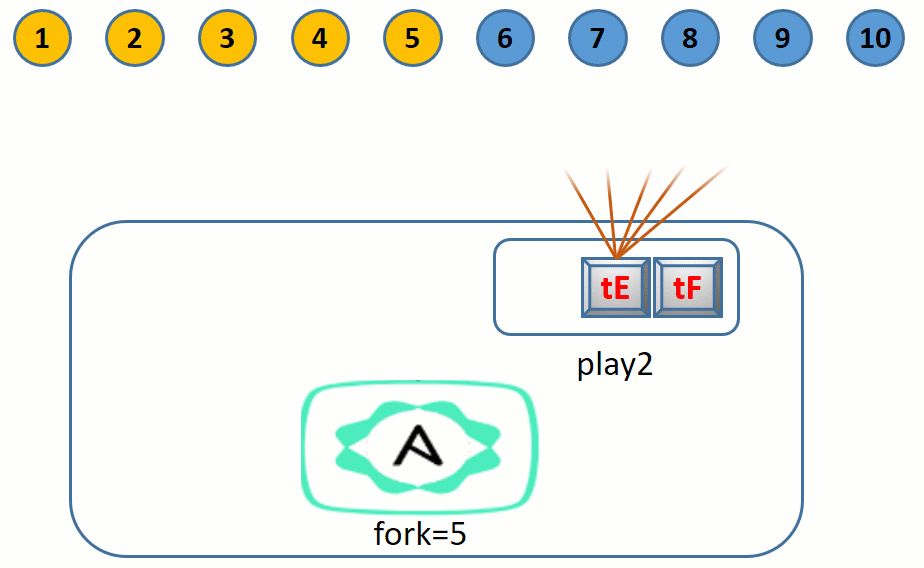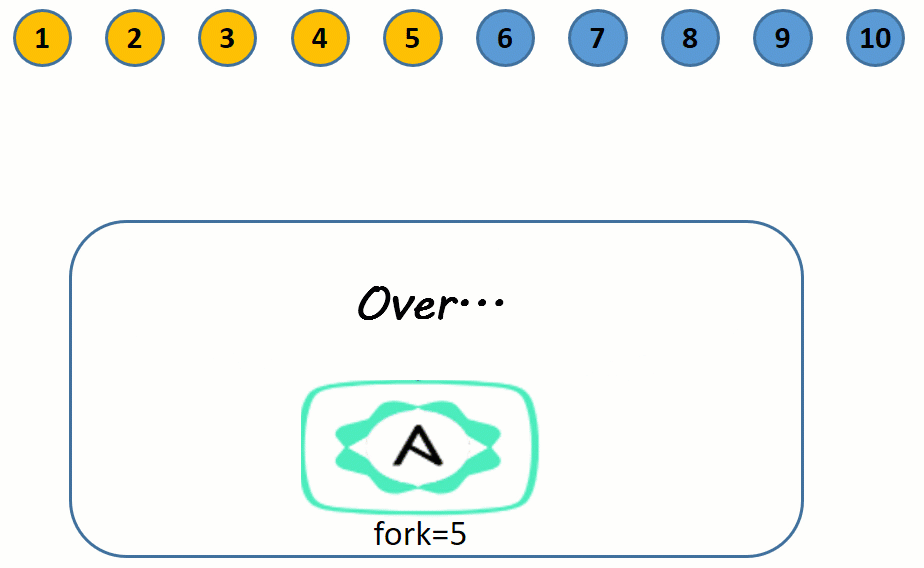
这个流程图虽然简单形象,但是不严谨,稍后会解释为何不严谨。
这里提到的 5 个节点的数量 5,是由配置文件中 forks 指令的值决定的,默认值为 5。
$ grep 'fork' /etc/ansible/ansible.cfg
#forks = 5forks 指令用来指定 Ansible 最多要创建几个子进程来执行任务,每个节点默认对应一个 ansible-playbook 进程和 ssh 进程,例如 forks=5 表示最多创建 5 个 ansible-playbook 子进程。所以,forks 的值也代表了最多有几个节点同时执行任务。
例如,将 hosts 指令指定为 all,并将 gather_facts 指令取消注释,因为这个任务执行比较慢,方便观察进程列表。
---
- name: first play
hosts: all
#gather_facts: false执行该 playbook。然后在另外一个终端上去查看进程列表:
[root@controller ~]# ansible-playbook first.yml
[root@controller ~]# pstree -c | grep 'ansible'
|-sshd-+-sshd---bash---ansible-playboo-+-ansible-playboo---ssh
| | |-ansible-playboo---ssh
| | |-ansible-playboo---ssh
| | |-ansible-playboo---ssh
| | |-ansible-playboo
| | `-{ansible-playboo}- 结果表明 forks=5 时共有 6 个 Ansible 进程,其中父进程是 Ansible 主控进程,负责监控节点执行任务的状态以及创建子进程来执行任务。
- 如果某个节点连接失败或执行某个任务失败,则该节点将不再执行该 play 中的后续任务(但会执行后续的 play)。
根据上面对 forks 指令的效果描述,前面的执行策略流程图并不严谨。因为 forks 的效果并不是选中一批节点,本批节点执行完任务才选下一批节点。
forks 是保证最多有 N 个节点同时执行任务,但有的节点可能执行任务较慢。比如有 10 个节点,且 forks=5 时,第一批选中 5 个节点执行任务,假如第 1 个节点先执行完任务,Ansible 主控进程不会等待本批中其它 4 个节点执行完任务,而是直接创建一个新的 Ansible 进程,让第 6 个节点执行任务。
4.7、综合案例
在生产环境中,有大量的集群需要进行初始化工作,这里使用 playbook 写一个批量初始化服务器的案例。
参见批量初始化服务器