
3、Python3 爬虫基础
爬虫,应该称为网络爬虫,也叫网页蜘蛛、网络机器人、网络蚂蚁等。
搜索引擎,就是网络爬虫的应用者。为什么到了今天,反而这个词汇被频繁的提起呢?有搜索引擎不就够了吗?
实际上,大数据时代的到来,所有的企业都希望通过海量数据发现其中的价值。所以,需要爬取特定网站、特定类别的数据,而搜索引擎不能提供这样的功能,因此,需要自己开发爬虫来解决。
3.1、爬虫分类
3.1.1、通用爬虫
常见的就是搜索引擎,无差别的收集数据、存储,提取关键字,构建索引库,给用户提供搜索接口。
爬取一般流程:
- 初始化一批 URL,将这些 URL 放到待爬取队列。
- 从队列取出这些 URL,通过 DNS 解析 IP,从 IP 对应的站点下载 HTML 页面,保存到本地服务器中,爬取完的 URL 放到已爬取队列。
- 分析这些网页内容,找出网页里面其他关心的 URL 链接,继续执行第 2 步,直到爬取条件结束。
搜索引擎如何获取一个新网站的 URL:
- 新网站主动提交给搜索引擎。
- 通过其它网站页面中设置的外链接。
- 搜索引擎和 DNS 服务商合作,获取最新收录的网站。
3.1.2、聚焦爬虫
有针对性地编写特定领域数据的爬取程序,属于某类数据采集的爬虫,面向特定主题。
3.1.3、Robots 协议
指定一个 robots.txt 文件,告诉爬虫引擎什么可以爬取。
阿里巴巴:https://www.alibabacloud.com/robots.txt
User-agent: *
Disallow: /api/*
Disallow: /*.json
Disallow: /*.jsonp
Disallow: /open/api/*
Disallow: /*?callback=*
Disallow: /*?utm_key=*
Disallow: /*?tracelog=*
Disallow: /*?page=*
Disallow: /template
Disallow: /admin
Disallow: /config
Disallow: /classes
Disallow: /log
Disallow: /language
Disallow: /script
Disallow: /static
Disallow: /alilog
Disallow: /s/*
Disallow: /b/*
Disallow: /tech-news/*
Disallow: /topic-center/*
Sitemap: https://www.alibabacloud.com/sitemaps/sitemap.xml马蜂窝:https://www.mafengwo.cn/robots.txt
User-agent: Baiduspider
Disallow: /musi
Disallow: /boo
Disallow: /secre
Disallow: /ran
Disallow: /order_cen
Disallow: /hotel_z
Disallow: /sales/or
Disallow: /u/*.html
User-agent: Bytespider
Disallow: /musi
Disallow: /boo
Disallow: /secre
Disallow: /ran
Disallow: /order_cen
Disallow: /hotel_z
Disallow: /sales/or
Disallow: /u/*.html
User-agent: Sosospider
Disallow: /musi
Disallow: /boo
Disallow: /secre
Disallow: /ran
Disallow: /order_cen
Disallow: /hotel_z
Disallow: /sales/or
Disallow: /u/*.html
......其它爬虫,不允许爬取:
User-Agent: *
Disallow: /
这是一个君子协定,“爬亦有道”,这个协议为了让搜索引擎更有效率搜索自己内容,提供了如 Sitemap 这样的文件。这个文件禁止抓取的往往又是我们感兴趣的内容,它反而泄露了这些地址。
3.2、HTTP 请求和响应处理
其实爬取网页就是通过 HTTP 协议访问网页,不过通过浏览器访问往往是人的行为,把这种行为变成使用程序来访问。
3.2.1、urllib 包
urllib 是标准库,包含下面模块来处理 url:
-
urllib.request用于打开和读写 url。 -
urllib.error包含了由urllib.request引起的异常。 -
urllib.parse用于解析 url。 -
urllib.robotparser分析 robots.txt 文件。
Python2 中提供了 urllib 和 urllib2。urllib 提供较为底层的接口,urllib2 对 urllib 进行了进一步封装。Python3 中将 urllib 合并到了 urllib2 中,并只提供了标准库 urllib 包。
3.2.1.1、urllib.request 模块
该模块针对基本和摘要式身份验证、 重定向、 cookies 等应用定义了打开 URL(主要是 HTTP) 的函数和类。
urlopen 方法:urlopen(url, data=None)
-
url 是链接地址字符串,或请求对象。
-
data 是提交的数据,如果 data 为 None 则发起 GET 请求,否则发起 POST请求。见
urllib.request.Request#get_method。 -
返回
http.client.HTTPResponse类的响应对象,这是一个类文件对象。
from urllib.request import urlopen
response = urlopen('http://www.bing.com') # GET 方法
print('-->', response.closed)
# 打开一个url返回一个响应对象,类文件对象
# 下面的链接访问后会有跳转
with response:
print(1, '-->', type(response)) # http.client.HTTPResponse 类文件对象
print(2, '-->', response.status, response.reason) # 状态
print(3, '-->', response.geturl()) # 返回真正的URL
print(4, '-->', response.info()) # headers
print(5, '-->', response.read()) # 读取返回的内容
print('-->', response.closed)上例,通过 urllib.request.urlopen 方法,发起一个 HTTP 的 GET 请求,WEB 服务器返回了网页内容。响应的数据被封装到类文件对象中,可以通过 read 方法、readline 方法、readlines 方法获取数据,status 和 reason 属性表示返回的状态码,info 方法返回头信息,等等。
User-Agent 问题
上例的代码非常精简,即可以获得网站的响应数据。urlopen 方法只能传递 url 和 data 这样的数据,不能构造 HTTP 的请求,例如 useragent。源码中构造的 useragent 如下:
# urllib.request.OpenerDirector
class OpenerDirector:
def __init__(self):
client_version = "Python-urllib/%s" % __version__
self.addheaders = [('User-agent', client_version)]当前显示为 Python-urllib/3.10.10
有些网站是反爬虫的,所以要把爬虫伪装成浏览器。随便打开一个浏览器,复制浏览器的 UA 值,用来伪装。
Request 类:Request(url, data=None, headers={})
初始化方法,构造一个请求对象。可添加一个 header 的字典。data 参数决定是 GET 还是 POST 请求。
add_header(key, val) 为 header 中增加一个键值对。
from urllib.request import Request, urlopen
import random
# 打开一个url返回一个Request请求对象
# url = 'https://movie.douban.com/' # 注意尾部的斜杠一定要有
url = 'http://www.bing.com/'
ua_list = [
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; zh-CN) AppleWebKit/537.36 (KHTML, like Gecko) Version/5.0.1 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)"
]
ua = random.choice(ua_list) # pick one
# ua需要加到请求头中
request = Request(url)
request.add_header('User-Agent', random.choice(ua_list))
print(1, "-->", type(request))
response = urlopen(request, timeout=20) # request对象或者url都可以
print(2, "-->", type(response))
with response:
print(3, '-->', response.status, response.getcode(), response.reason) # 状态,getcode本质上就是返回status
print(4, '-->', response.geturl()) # 返回数据的url。如果重定向,这个url和原始url不一样
# 例如原始url是http://www.bing.com/,返回http://cn.bing.com/
print(5, '-->', response.info()) # 返回响应头headers
print(6, '-->', response.read()) # 读取返回的内容
print(7, '-->', request.get_header('User-agent'))
print(8, '-->', 'user-agent'.capitalize())3.2.1.2、urllib.parse 模块
该模块可以完成对 url 的编解码。先看一段代码,进行编码:
from urllib import parse
u = parse.urlencode('https://brinnatt.com/category/primary/')
# 运行结果如下
Traceback (most recent call last):
File "C:\Users\Brinnatt\PycharmProjects\pythonProject\t1.py", line 3, in <module>
u = parse.urlencode('https://brinnatt.com/category/primary/')
File "D:\Python\Python310\lib\urllib\parse.py", line 943, in urlencode
raise TypeError("not a valid non-string sequence "
File "D:\Python\Python310\lib\urllib\parse.py", line 936, in urlencode
raise TypeError
TypeError: not a valid non-string sequence or mapping objecturlencode 函数第一参数要求是一个字典或者二元组序列。
from urllib import parse
u = parse.urlencode({
'url': 'https://brinnatt.com/category/primary/',
'p_url': 'https://brinnatt.com/primary/python?id=1&name=张三'
})
print(u)
# 运行结果如下
url=https%3A%2F%2Fbrinnatt.com%2Fcategory%2Fprimary%2F&p_url=https%3A%2F%2Fbrinnatt.com%2Fprimary%2Fpython%3Fid%3D1%26name%3D%E5%BC%A0%E4%B8%89从运行结果来看冒号、斜杠、&、等号、问号等符号全部被编码了,% 之后实际上是单字节十六进制表示的值。
一般来说 url 中的地址部分,一般不需要使用中文路径,但是参数部分,不管 GET 还是 POST 方法,提交的数据中,可能有斜杆、等号、问号等符号,这些字符表示数据,不表示元字符。
如果直接发给服务器端,就会导致接收方无法判断谁是元字符,谁是数据了。为了安全,一般会将数据部分的字符做 url 编码,这样就不会有歧义了。
后来可以传送中文,同样会做编码,一般先按照字符集的 encoding 要求转换成字节序列,每一个字节对应的十六进制字符串前加上百分号即可。
# 网页使用utf-8编码
# https://www.baidu.com/s?wd=中
# 上面的url编码后,如下
# https://www.baidu.com/s?wd=%E4%B8%AD
from urllib import parse
u = parse.urlencode({'wd': '中'}) # 编码
url = f"https://www.baidu.com/s?{u}"
print(1, '-->', url)
print(2, '-->', '中'.encode('utf-8')) # b'\xe4\xb8\xad'
print(3, '-->', parse.unquote(u)) # 解码
print(4, '-->', parse.unquote(url))3.2.2、提交方法 method
最常用的 HTTP 交互数据的方法是 GET、POST。
-
GET 方法,数据是通过 URL 传递的,也就是说数据是在 HTTP 报文的 header 部分。
-
POST 方法,数据是放在 HTTP 报文的 body 部分提交的。
-
数据都是键值对形式,多个参数之间使用
&符号连接。例如a=1&b=abc。
3.2.2.1、GET 方法
连接必应搜索引擎官网,获取一个搜索的 URL http://cn.bing.com/search?q=亮天生。
需求:请写程序完成对关键字的bing搜索,将返回的结果保存到一个网页文件。
from urllib.request import Request, urlopen
from urllib.parse import urlencode
kw = input("Please input key word -> ")
data = urlencode({
'q': kw
})
base_url = 'http://cn.bing.com/search'
url = f'{base_url}?{data}'
print(url)
# 伪装
ua = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36"
request = Request(url, headers={'User-agent': ua})
response = urlopen(request)
with response:
with open('I:/bing.html', 'wb+') as f:
f.write(response.read())
print("成功")3.2.2.2、POST 方法
http://httpbin.org/ 测试网站。
from urllib.request import Request, urlopen
from urllib.parse import urlencode
request = Request('http://httpbin.org/post')
request.add_header(
'User-agent',
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36"
)
data = urlencode({
'name': '张三,@=/&*',
'age': '6'
})
print(1, '-->', data)
# res = urlopen(request, data='name=张三,@=/&*,&age=6'.encode()) # 不做url编码有风险
res = urlopen(request, data=data.encode()) # POST方法,Form提交数据
with res:
print(2, '-->', res.read())3.2.2.3、处理 JSON 数据
查看“豆瓣电影”,看到“最近热门电影”的“热门”。
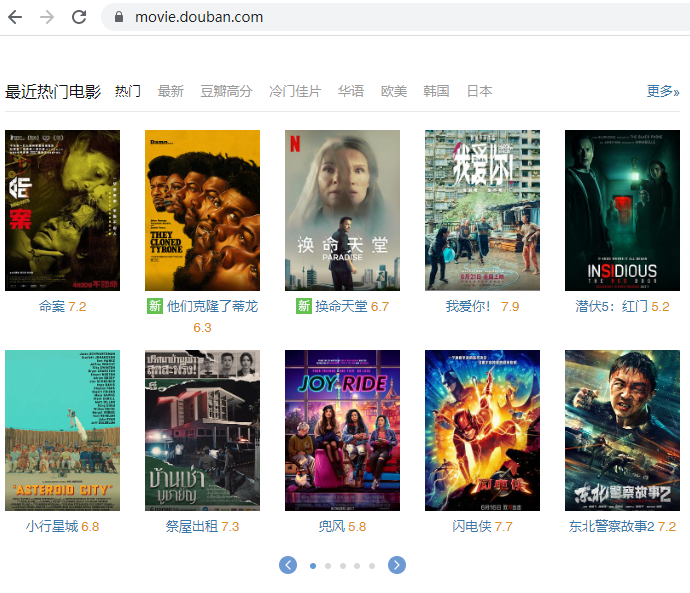
通过分析,我们知道这部分内容,是通过 AJAX 从后台拿到的 Json 数据。
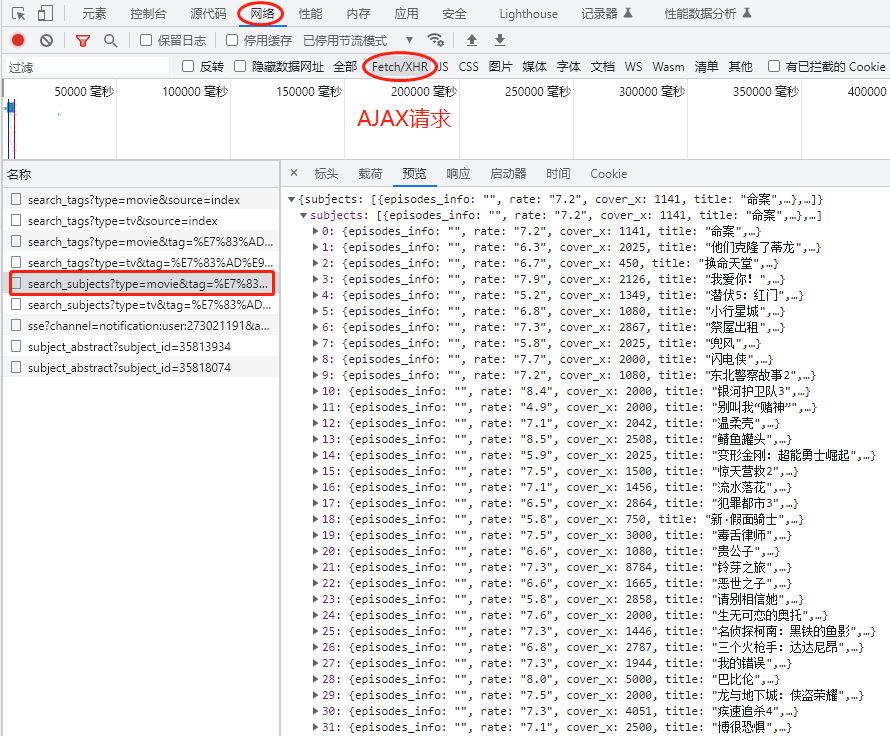
访问 URL 是 https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&page_limit=50&page_start=0。
-
tag 标签“热门”,表示热门电影;
-
type 数据类型,movie 是电影;
-
page_limit 表示返回数据的总数;
-
page_start 表示数据偏移。
-
%E7%83%AD%E9%97%A8是 utf-8 编码的中文 “热门”。
服务器返回的 Json 数据如上图所示,轮播组件,共需要 50 条数据。
from urllib.request import Request, urlopen
from urllib.parse import urlencode
url = 'https://movie.douban.com/j/search_subjects'
request = Request(url)
request.add_header(
'User-agent',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'
)
data = urlencode(
{
'type': 'movie',
'tag': '热门',
'page_limit': 10,
'page_start': 10
}
)
# POST方法
res = urlopen(request, data=data.encode())
with res:
print(1, '-->', res._method)
print(2, '-->', res.read().decode())
# 新版本的urlopen要求必须有User-agent
request = Request(f'{url}?{data}')
request.add_header(
'User-agent',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'
)
with urlopen(request) as f:
print(3, '-->', f._method)
print(4, '-->', f.read().decode())3.2.3、HTTPS 证书忽略
HTTPS 使用 SSL 安全套接层协议,在传输层对网络数据进行加密。HTTPS 使用的时候需要证书,而证书需要 CA 认证。
CA(Certificate Authority) 是数字证书认证中心的简称,是指发放、管理、废除数字证书的机构。
CA 是受信任的第三方,有 CA 签发的证书具有可信性。如果用户由于信任了 CA 签发的证书导致的损失,可以追究 CA 的法律责任。
CA 是层级结构,下级 CA 信任上级 CA,且有上级 CA 颁发给下级 CA 证书并认证。
一些网站,例如淘宝,使用 HTTPS 加密数据更加安全。
from urllib.request import Request, urlopen
# request = Request('https://www.baidu.com/') # 可以访问
request = Request('https://www.12306.cn/mormhweb/') # 报SSL认证异常
request.add_header(
'User-agent',
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36"
)
with urlopen(request) as res:
print(1, '-->', res._method)
print(2, '-->', res.read())通过 HTTPS 访问 12306 的时候,失败的原因在于 12306 的证书未通过 CA 认证,它是自己生成的证书,不可信。而其它网站访问,如 https://www.baidu.com/ 并没有提示 SSL 错误,因为它的证书发行者受信任,且早就存储在当前系统中。
能否像浏览器一样,忽略证书不安全信息呢?
from urllib.request import Request, urlopen
import ssl # 导入ssl模块
# request = Request('https://www.baidu.com/') # 可以访问
request = Request('https://www.12306.cn/mormhweb/') # 报SSL认证异常
request.add_header(
'User-agent',
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36"
)
# 忽略不信任的证书
context = ssl._create_unverified_context()
res = urlopen(request, context=context)
with res:
print(1, '-->', res._method)
print(2, '-->', res.geturl())
print(3, '-->', res.read().decode())3.2.4、urllib3 库
https://urllib3.readthedocs.io/en/latest/
标准库 urllib 缺少了一些关键的功能,非标准库的第三方库 urllib3 提供了,比如说连接池管理。
安装 $ pip install urllib3。
import urllib3
# 打开一个url返回一个对象
url = 'https://movie.douban.com'
ua = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36"
# 连接池管理器
with urllib3.PoolManager() as http:
response = http.request('GET', url, headers={
'User-Agent': ua
})
print(1, '-->', type(response))
print(2, '-->', response.status, response.reason)
print(3, '-->', response.headers)
print(4, '-->', response.data.decode())3.2.5、requests 库
requests 使用了 urllib3,但是 API 更加友好,推荐使用。
import requests
ua = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36"
url = 'https://movie.douban.com/'
response = requests.request('GET', url, headers={"User-Agent": ua})
with response:
print(1, '-->', type(response))
print(2, '-->', response.url)
print(3, '-->', response.status_code)
print(4, '-->', response.request.headers) # 请求头
print(5, '-->', response.headers) # 响应头
print(6, '-->', response.text[:200]) # HTML的内容
with open('I:/movie.html', 'w', encoding='utf-8') as f:
f.write(response.text) # 保存文件,以后备用requests 默认使用 Session 对象,是为了多次和服务器端交互过程中保留会话的信息,例如 cookie。
# 直接使用Session
import requests
ua = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36"
urls = ['https://movie.douban.com/', 'https://www.baidu.com/s?wd=brinnatt']
session = requests.Session()
with session:
for url in urls:
response = session.get(url, headers={'User-Agent': ua})
with response:
print(1, '-->', type(response))
print(2, '-->', response.url)
print(3, '-->', response.status_code)
print(4, '-->', response.request.headers) # 请求头
print(5, '-->', response.cookies) # 响应的cookie
print(6, '-->', response.text[:20]) # HTML的内容3.3、HTML 解析
通过上面的库,都可以拿到 HTML 内容。HTML 的内容返回给浏览器,浏览器就会解析它,并对它渲染。HTML 超文本标记语言,设计的初衷就是为了超越普通文本,让文本表现力更强。
XML 扩展标记语言,不是为了代替 HTML,而是觉得 HTML 的设计中包含了过多的格式,承担了一部分数据之外的任务,所以才设计了 XML 只用来描述数据。
HTML 和 XML 都有结构,使用标记形成树型的嵌套结构。DOM(Document Object Model)来解析这种嵌套树型结构,浏览器往往都提供了对 DOM 操作的 API,可以用面向对象的方式来操作 DOM。
3.3.1、XPath
http://www.w3school.com.cn/xpath/index.asp 中文教程。
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
3.3.1.1、节点(Node)
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
请看下面这个 XML 文档:
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>上面的 XML 文档中的节点例子:
<bookstore> (文档节点)
<author>J K. Rowling</author> (元素节点)
lang="en" (属性节点)基本值(或称原子值,Atomic value)
基本值是无父或无子的节点。基本值的例子:
J K. Rowling
"en"项目(Item)
项目是基本值或者节点。
节点关系
示例:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>父(Parent)
每个元素以及属性都有一个父。
示例中,book 元素是 title、author、year 以及 price 元素的父。
子(Children)
元素节点可有零个、一个或多个子。
示例中,title、author、year 以及 price 元素都是 book 元素的子。
同胞(Sibling)
拥有相同的父的节点
示例中,title、author、year 以及 price 元素都是同胞。
先辈(Ancestor)
某节点的父、父的父,等等。
示例中,title 元素的先辈是 book 元素和 bookstore 元素。
后代(Descendant)
某个节点的子,子的子,等等。
示例中,bookstore 的后代是 book、title、author、year 以及 price 元素。
3.3.1.2、语法
XML 实例文档,我们将在下面的例子中使用这个 XML 文档:
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>3.3.1.2.1、选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式:
| 表达式 | 描述 |
|---|---|
nodename |
选取此节点的所有子节点。 |
/ |
从根节点选取。 |
// |
从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
. |
选取当前节点。 |
.. |
选取当前节点的父节点。 |
@ |
选取属性。 |
实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
bookstore |
选取 bookstore 元素的所有子节点。 |
/bookstore |
选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
bookstore/book |
选取属于 bookstore 的子元素的所有 book 元素。 |
//book |
选取所有 book 子元素,而不管它们在文档中的位置。 |
bookstore//book |
选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
//@lang |
选取名为 lang 的所有属性。 |
3.3.1.2.2、谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
/bookstore/book[1] |
选取属于 bookstore 子元素的第一个 book 元素。 |
/bookstore/book[last()] |
选取属于 bookstore 子元素的最后一个 book 元素。 |
/bookstore/book[last()-1] |
选取属于 bookstore 子元素的倒数第二个 book 元素。 |
/bookstore/book[position()<3] |
选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
//title[@lang] |
选取所有拥有名为 lang 的属性的 title 元素。 |
//title[@lang='eng'] |
选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
/bookstore/book[price>35.00] |
选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
/bookstore/book[price>35.00]/title |
选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
3.3.1.2.3、选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
* |
匹配任何元素节点。 |
@* |
匹配任何属性节点。 |
node() |
匹配任何类型的节点。 |
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
/bookstore/* |
选取 bookstore 元素的所有子元素。 |
//* |
选取文档中的所有元素。 |
//title[@*] |
选取所有带有属性的 title 元素。 |
3.3.1.2.4、选取若干路径
通过在路径表达式中使用 | 运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
//book/title | //book/price |
选取 book 元素的所有 title 和 price 元素。 |
//title | //price |
选取文档中的所有 title 和 price 元素。 |
/bookstore/book/title | //price |
选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
3.3.1.3、轴
轴可定义相对于当前节点的节点集。
| 轴名称 | 结果 |
|---|---|
| ancestor | 选取当前节点的所有先辈(父、祖父等)。 |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
| attribute | 选取当前节点的所有属性。 |
| child | 选取当前节点的所有子元素。 |
| descendant | 选取当前节点的所有后代元素(子、孙等)。 |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
| following | 选取文档中当前节点的结束标签之后的所有节点。 |
| namespace | 选取当前节点的所有命名空间节点。 |
| parent | 选取当前节点的父节点。 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling | 选取当前节点之前的所有同级节点。 |
| self | 选取当前节点。 |
步的语法:
轴名称::节点测试[谓语]实例
| 例子 | 结果 |
|---|---|
child::book |
选取所有属于当前节点的子元素的 book 节点。 |
attribute::lang |
选取当前节点的 lang 属性。 |
child::* |
选取当前节点的所有子元素。 |
attribute::* |
选取当前节点的所有属性。 |
child::text() |
选取当前节点的所有文本子节点。 |
child::node() |
选取当前节点的所有子节点。 |
descendant::book |
选取当前节点的所有 book 后代。 |
ancestor::book |
选择当前节点的所有 book 先辈。 |
ancestor-or-self::book |
选取当前节点的所有 book 先辈以及当前节点(如果此节点是 book 节点) |
child::*/child::price |
选取当前节点的所有 price 孙节点。 |
3.3.1.4、XPath 运算符
下面列出了可用在 XPath 表达式中的运算符:
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| |
计算两个节点集 | //book | //cd |
返回所有拥有 book 和 cd 元素的节点集 |
+ |
加法 | 6 + 4 |
10 |
- |
减法 | 6 - 4 |
2 |
* |
乘法 | 6 * 4 |
24 |
div |
除法 | 8 div 4 |
2 |
= |
等于 | price=9.80 |
如果 price 是 9.80,则返回 true。如果 price 是 9.90,则返回 false。 |
!= |
不等于 | price!=9.80 |
如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
< |
小于 | price<9.80 |
如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
<= |
小于或等于 | price<=9.80 |
如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
> |
大于 | price>9.80 |
如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
>= |
大于或等于 | price>=9.80 |
如果 price 是 9.90,则返回 true。如果 price 是 9.70,则返回 false。 |
or |
或 | price=9.80 or price=9.70 |
如果 price 是 9.80,则返回 true。如果 price 是 9.50,则返回 false。 |
and |
与 | price>9.00 and price<9.90 |
如果 price 是 9.80,则返回 true。如果 price 是 8.50,则返回 false。 |
mod |
计算除法的余数 | 5 mod 2 |
1 |
3.3.2、lxml
lxml 是 Python 下功能丰富的 XML、HTML 解析库,性能非常好,是对 libxml2 和 libxslt 的封装。
CentOS 编译需要安装:
# yum install libxml2-devel libxslt-devel注意,不同平台不一样,参看 http://lxml.de/installation.html
lxml 安装:
$ pip install lxmlfrom lxml import etree
# 使用etree构建HTML
root = etree.Element('html')
print(1, '-->', type(root))
print(2, '-->', root.tag)
body = etree.Element('body')
root.append(body)
print(3, '-->', etree.tostring(root))
sub = etree.SubElement(body, 'child1') # 增加子节点
print(4, '-->', type(sub))
sub = etree.SubElement(body, 'child2').append(etree.Element('child21'))
print(5, '-->', '\n', etree.tostring(root, pretty_print=True).decode())etree 还提供了 2 个有用的函数:
-
etree.HTML(text)解析 HTML 文档,返回根节点。 -
某节点.xpath('xpath路径')对节点使用 xpath 语法。
从豆瓣电影中提取“本周口碑榜”:
from lxml import etree
import requests
url = 'https://movie.douban.com/'
ua = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36"
with requests.get(url, headers={'User-agent': ua}) as response:
content = response.text # HTML 内容
html = etree.HTML(content) # 分析HTML,返回DOM根节点
titles = html.xpath("//div[@class='billboard-bd']//tr/td/a/text()") # 返回文本列表
for title in titles: # 豆瓣电影之 本周口碑榜
print(title)3.3.3、BeautifulSoup4
BeautifulSoup 可以从 HTML、XML 中提取数据。目前 BS4 在持续开发。
官方中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
$ pip install beautifulsoup4BeautifulSoup(markup="", features=None)
-
markup 可以是文件对象或者 html 字符串
-
features 指定解析器,返回一个文档对象
from bs4 import BeautifulSoup
# 文件对象
soup = BeautifulSoup(open("t1.html"), 'lxml')
print(1, '-->', '\n', soup, sep="")
# 标记字符串
soup = BeautifulSoup("<html>data</html>", 'lxml')
print(2, '-->', '\n', soup, sep="")可以不指定解析器,就依赖系统已经安装的解析器库了。
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, "html.parser") |
Python的内置标准库 执行速度适中 文档容错能力强 |
Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") |
速度快 文档容错能力强 |
需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, ["lxml-xml"])BeautifulSoup(markup, "xml") |
速度快 唯一支持XML的解析器 |
需要安装C语言库 |
| html5lib | BeautifulSoup(markup, "html5lib") |
最好的容错性 以浏览器的方式解析文档 生成HTML5格式的文档 |
速度慢 不依赖外部扩展 |
推荐使用 lxml 作为解析器,因为效率更高。在 Python2.7.3 之前的版本和 Python3 中 3.2.2 之前的版本,必须安装 lxml 或 html5lib,因为那些 Python 版本的标准库中内置的 HTML 解析方法不够稳定。
提示:如果一段 HTML 或 XML 文档格式不正确的话,那么在不同的解析器中返回的结果可能是不一样的,查看 解析器之间的区别 了解更多细节。
3.3.3.1、四种对象
BeautifulSoup 将 HTML 文档解析成复杂的树型结构,每个节点都是 Python 的对象,可分为 4 种:BeautifulSoup、Tag、NavigableString、Comment。
BeautifulSoup 对象
BeautifulSoup 对象代表整个文档。
Tag 对象
它对应着 HTML 中的标签。有 2 个常用的属性:
- name,标签名称。
- attrs,标签的属性字典。
- 多值属性,对于 class 属性可能是这样的形式,
<h3 class="title highlight">python高级班</h3>,这个属性就是多值。属性可以被修改、删除。
- 多值属性,对于 class 属性可能是这样的形式,
使用下面内容构建 t1.html,使用 bs4 解析它:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>首页</title>
</head>
<body>
<h1>Welcome to www.brinnatt.com</h1>
<div>
<h3 class="title highlight">python高级班</h3>
<div class="content">
<p id='first'>字典</p>
<p id='second'>列表</p>
<input type="hidden" name="_csrf" value="7139e401481ef2f46ce98b22af4f4bed">
<!-- comment -->
<img id="bg1" src="http://www.brinnatt.com/">
<img id="bg2" src="http://httpbin.org/">
</div>
</div>
<p>bottom</p>
</body>
</html>from bs4 import BeautifulSoup
with open('t1.html', encoding='utf-8') as f:
soup = BeautifulSoup(f, 'lxml')
print('-->', soup.builder)
print(0, '-->', '\n', soup, sep='') # 输出整个解析的文档对象
print(1, '-->', '\n', soup.prettify(), sep='') # 输出整个解析的文档对象
print('->' * 50)
print(2, '-->', '\n', soup.div, type(soup.div), sep='') # bs4.element.Tag, Tag对象
print(3, '-->', '\n', soup.div.name, soup.div.attrs, sep='') # bs4.element.Tag, Tag对象
# print(soup.div['class']) # KeyError,div没有class属性
print(3, '-->', '\n', soup.div.get('class'), sep='')
print(4, '-->', '\n', soup.h3['class'], sep='') # 多值属性
print(4, '-->', '\n', soup.h3.get('class'), sep='') # 多值属性
print(4, '-->', '\n', soup.h3.attrs.get('class'), sep='') # 多值属性
print(5, '-->', '\n', soup.img.get('src'), sep='')
soup.img['src'] = 'http://www.python.org/' # 修改属性
print(5, '-->', '\n', soup.img['src'], sep='')
print(6, '-->', '\n', soup.a, sep='') # 找不到返回None
del soup.h3['class'] # 删除属性
print(4, '-->', '\n', soup.h3.get('class'))注意,我们一般不使用上面这种方式来操作 HTML,此代码是为了熟悉对象类型。
NavigableString
如果只想输出标记内的文本,而不关心标记的话,就要使用 NavigableString。
from bs4 import BeautifulSoup
with open('t1.html', encoding='utf-8') as f:
soup = BeautifulSoup(f, 'lxml')
print(soup.div.p.string) # 第一个div下第一个p的字符串
print(soup.p.string) # 同上,深度优先注释对象
这就是 HTML 中的注释,它被 BeautifulSoup 解析后对应 Comment 对象。
3.3.3.2、遍历文档树
在文档树中找到关心的内容才是日常的工作,也就是说如何遍历树中的节点。使用上面的 t1.html 来测试。
使用 Tag
soup.div 从根节点开始查找到第一个 div 节点。
soup.div.p 从根节点开始找到第一个 div 后返回一个 Tag 对象,在 Tag 对象下继续找第一个 p,找到返回 Tag 对象。
soup.p 说明遍历是深度优先,返回了文字“字典”,而不是文字 “bottom”。
遍历直接子节点
print(soup.div.contents) # 将对象的所有类型直接子节点以列表方式输出
print(soup.div.children) # 返回子节点的迭代器
print(list(soup.div.children)) # 等价于 soup.div.contents
遍历所有子孙节点
print(list(soup.div.descendants)) # 返回第一个 div 节点的所有类型子孙节点,可以看出迭代次序是深度优先。
遍历字符串
在前面的例子中,soup.div.string 返回 None,是因为 string 要求 soup.div 只能有一个 NavigableString 类型子节点,也就是如这样 <div>only string</div>。
如果 div 有很多子孙节点,如何提取字符串?
print(soup.div.string) # 返回 None
print("".join(soup.div.strings)) # 返回迭代器,带多余的空白字符
print("".join(soup.div.stripped_strings)) # 去除多余空白符
注意:string 和 strings 的区别。
遍历祖先节点
print(soup.parent) # None 根节点没有父节点
print(soup.div.parent.name) # body,第一个 div 的父节点
print(soup.p.parent.parent.get('id')) # main
print(list(map(lambda x: x.name, soup.p.parents))) # 父迭代器,由近及远
遍历兄弟节点
print('{} [{}]'.format(1, soup.p.next_sibling)) # 第一个 p 元素的下一个兄弟节点,注意可能是一个文本节点
print('{} [{}]'.format(2, soup.p.previous_sibling))
print(list(soup.p.next_siblings)) # previous_siblings
遍历其他元素
next_element 是下一个可被解析的对象(字符串或 tag),和下一个兄弟节点 next_sibling 不一样
print(soup.p.next_element) # 返回"字典" 2 个字
print(soup.p.next_element.next_element.next_element)
print(list(soup.p.next_elements))
3.3.3.3、搜索文档树
find 系有很多方法,请自行查帮助。
find_all(name=None, attrs={}, recursive=True, text=None, limit=None, **kwargs),立即返回一个列表。
name 参数,官方称为 filter 过滤器,这个参数可以是以下类型:
-
字符串
一个标签名称的字符串,会按照这个字符串全长匹配标签名。
print(soup.find_all('p'))# 返回文档中所有 p 标签。 -
正则表达式对象
按照“正则表达式对象”的模式匹配标签名。
import re
print(soup.find_all(re.compile('^h\d')))# 标签名以 h 开头后接数字。 -
列表
print(soup.find_all(['p', 'h1', 'h3']))# 或,找出列表所有的标签。print(soup.find_all(re.compile(r'^(p|h\d)$')))# 使用正则完成。 -
True 或 None
True 或 None,则 find_all 返回全部非字符串节点、非注释节点,即 Tag 标签类型。
print(list(map(lambda x:x.name, soup.find_all(True))))print(list(map(lambda x:x.name, soup.find_all(None))))print(list(map(lambda x:x.name, soup.find_all())))# 数目一致,所以返回的是Tag类型的节点,源码中确实返回的Tag类型 from bs4 import BeautifulSoup from bs4.element import Tag with open('t1.html', encoding='utf-8') as f: soup = BeautifulSoup(f, 'lxml') values = [True, None, False] for value in values: all = soup.find_all(value) print(len(all)) print('-' * 30) count = 0 for index, tag in enumerate(soup.descendants): print(index, type(tag), tag.name) if isinstance(tag, Tag): count += 1 print(count) -
函数
如果使用以上过滤器还不能提取出想要的节点,可以使用函数,此函数仅只能接收一个参数。
如果这个函数返回 True,表示当前节点匹配;返回 False 则是不匹配。
例如,找出所有有 class 属性且有多个值的节点,符合这个要求只有 h3 标签。
from bs4 import BeautifulSoup def many_class(tag): # print(type(tag)) # print(tag.attrs) return len(tag.attrs.get('class', [])) > 1 with open('t1.html', encoding='utf-8') as f: soup = BeautifulSoup(f, 'lxml') print(soup.find_all(many_class))
keyword 传参
使用关键字传参,如果参数名不是已定义的位置参数名,参数会被 kwargs 收集并被当做标签的属性来搜索。
属性的传参可以是字符串、正则表达式对象、True、列表。
print(soup.find_all(id='first')) # id 为 first 的所有节点列表
print(soup.find_all(id=re.compile('\w+'))) # 相当于找有 id 的所有节点
print(soup.find_all(id=True)) # 所有有 id 的节点
print(list(map(lambda x:x['id'], soup.find_all(id=True))))
print(soup.find_all(id=['first', 'second'])) # 指定 id 的名称列表
print(soup.find_all(id=True, src=True)) # 相当于条件 and,既有 id 又有 src 属性的节点列表
css 的 class 的特殊处理
class 是 Python 关键字,所以使用 class_。class 是多值属性,可以匹配其中任意一个,也可以完全匹配。
print(soup.find_all(class_="content"))
print(soup.find_all(class_="title")) # 可以使用任意一个 css 类
print(soup.find_all(class_="highlight")) # 可以使用任意一个 css 类
print(soup.find_all(class_="highlight title")) # 顺序错了,找不到
print(soup.find_all(class_="title highlight")) # 顺序一致,找到,就是字符串完全匹配
attrs 参数
attrs 接收一个字典,字典的 key 为属性名,value 可以是字符串、正则表达式对象、True、列表。
print(soup.find_all(attrs={'class':'title'}))
print(soup.find_all(attrs={'class':'highlight'}))
print(soup.find_all(attrs={'class':'title highlight'}))
print(soup.find_all(attrs={'id':True}))
print(soup.find_all(attrs={'id':re.compile(r'\d$')}))
text 参数
可以通过 text 参数搜索文档中的字符串内容,接受字符串、正则表达式对象、True、列表。
print(list(map(lambda x: (type(x), x), soup.find_all(text=re.compile('\w+')))))
print(list(map(lambda x: (type(x), x), soup.find_all(text=re.compile('[a-z]+')))))
print(soup.find_all(re.compile(r'h|p'), text=re.compile('[a-z]+'))) # 相当于过滤出 Tag 对象,并看它的 string 是否符合 text 参数的要求
limit 参数
限制返回结果的数量。
print(soup.find_all(id=True, limit=3)) # 返回列表中有 3 个结果
recursive 参数
默认是递归搜索所有子孙节点,如果不需要请设置为 False。
简化写法
find_all() 是非常常用的方法,可以简化省略掉:
soup.find_all("a") ==> soup("a") # 注意,不等价于 soup.a
soup.a.find_all(text=True) ==> soup.a(text=True)
print(soup.find_all('img', attrs={'id':'bg1'}))
print(soup('img', attrs={'id':'bg1'})) # find_all 的省略
print(soup('img', attrs={'id':'bg1'}))
find 方法
find( name , attrs , recursive , text , **kwargs ),参数几乎和 find_all 一样。
找到了,find_all 返回一个列表,而 find 返回一个单值,元素对象。
找不到,find_all 返回一个空列表,而 find 返回一个 None。
print(soup.find('img', attrs={'id':'bg1'}).attrs.get('src', 'brinnatt'))
print(soup.find('img', attrs={'id':'bg1'}).get('src')) # 简化了 attrs
print(soup.find('img', attrs={'id':'bg1'})['src'])
3.3.4、CSS 选择器
和 JQuery 一样,可以使用 CSS 选择器来查找节点。使用 soup.select() 方法,select 方法支持大部分 CSS 选择器,返回列表。
CSS 中,标签名直接使用,类名前加 . 点号,id 名前加 # 井号。
from bs4 import BeautifulSoup
with open('t1.html', encoding='utf-8') as f:
soup = BeautifulSoup(f, 'lxml')
# 元素选择器
print(1, soup.select('p')) # 所有的p标签
# 类选择器
print(2, soup.select('.title'))
# 使用了伪类
print(3, soup.select('div.content > p:nth-of-type(2)')) # 同标签名p的第2个,伪类只实现了nth-of-type,且要求是数字
# id选择器
print(4, soup.select('p#second'))
print(5, soup.select('#bg1'))
# 后代选择器
print(6, soup.select('div p')) # div下逐层找p
print(7, soup.select('div div p')) # div下逐层找div下逐层找p
# 子选择器,直接后代
print(8, soup.select('div > p')) # div下直接子标签的p
# 相邻兄弟选择器
print(9, soup.select('div p:nth-of-type(1) + [src]')) # 返回[]
# 普通兄弟选择器
print(10, soup.select('div p:nth-of-type(1) ~ [src]'))
# 属性选择器
print(11, soup.select('[src]')) # 有属性src
print(12, soup.select('[src="/"]')) # 属性src等于/
print(13, soup.select('[src="http://www.brinnatt.com/"]')) # 完全匹配
print(14, soup.select('[src^="http://www"]')) # 以http://www开头
print(15, soup.select('[src$="com/"]')) # 以com/结尾
print(16, soup.select('img[src*="brinnatt"]')) # 包含brinnatt
print(17, soup.select('img[src*=".com"]')) # 包含.com
print(18, soup.select('[class~=title]')) # 多值属性中有一个title获取文本内容
搜索节点的目的往往是为了提取该节点的文本内容,一般不需要 HTML 标记,只需要文字。
from bs4 import BeautifulSoup
with open('t1.html', encoding='utf-8') as f:
soup = BeautifulSoup(f, 'lxml')
# 元素选择器
ele = soup.select('div') # 所有的div标签
print(1, '-->', ele[0].string, end='\n------------\n') # 内容仅仅只能是文本类型,否则返回None
print(2, '-->', list(ele[0].strings), end='\n------------\n') # 迭代保留空白字符
print(3, '-->', list(ele[0].stripped_strings), end='\n------------\n') # 迭代不保留空白字符
print(4, '-->', ele[0], end='\n------------\n')
print(5, '-->', ele[0].text, end='\n------------\n') # 本质上就是get_text(),保留空白字符的strings
print(6, '-->', ele[0].get_text(), end='\n------------\n') # 迭代并join,保留空白字符,strip默认为False
print(7, '-->', ele[0].get_text(strip=True)) # 迭代并join,不保留空白字符3.3.5、Json 解析
拿到一个 Json 字符串,如果想提取其中的部分内容,就需要遍历了。在遍历过程中进行判断。
还有一种方式,类似于 XPath,叫做 JsonPath。
官网 http://goessner.net/articles/JsonPath/
安装:$ pip install jsonpath
| XPath | JSONPath | Description |
|---|---|---|
/ |
$ |
根元素 |
. |
@ |
当前节点 |
/ |
. or [] |
获取子节点 |
.. |
n/a |
父节点 |
// |
.. |
任意层次 |
* |
* |
通配符,匹配任意节点 |
@ |
n/a |
Json中没有属性 |
[] |
[] |
下标操作 |
| |
[,] |
Union operator in XPath results in a combination of node sets. JSONPath allows alternate names or array indices as a set. |
n/a |
[start:end:step] |
切片 |
[] |
?() |
过滤操作 |
n/a |
() |
表达式计算 |
() |
n/a |
分组 |
依然用豆瓣电影的热门电影的 Json,https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&page_limit=10&page_start=0
找到得分高于 8 分的电影
思路:
找到 title 非常容易,但是要用其兄弟节点 rate 判断是否大于 8 分,就不好做了。
能够从父节点下手,subjects 的多个子节点中,要用 [ ],某一个当前节点的 rate 和字符串 8 比较来过滤得到符合要求的 subjects 的子节点,取这个子节点的 title。
# 返回json的解析和处理
from jsonpath import jsonpath
import requests
import json
ua = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36"
url = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&page_limit=10&page_start=0'
with requests.get(url, headers={'User-agent': ua}) as response:
text = response.text
print(text, '\n', type(text)) # str类型的json数据
js = json.loads(text)
print(js, '\n', type(js)) # Json转为Python数据结构
# 找到所有电影的名称
rs1 = jsonpath(js, '$..title')
print(rs1)
# 找到所有得分高于8分的电影名称
# 根下任意层的subjects的子节点rate大于字符串8
rs2 = jsonpath(js, '$..subjects[?(@.rate > "8")]')
print(rs2)
# 根下任意层的subjects的子节点rate大于字符串8的节点的子节点title
rs3 = jsonpath(js, '$..subjects[?(@.rate > "8")].title')
print(rs3)3.4、模拟登陆 oschina
一般用户登录后,可以在一段时间内使用该用户进行必要操作,不需要频繁登录了。这背后往往使用了 Cookie 技术。
登录后,用户获得一个 cookie 值,这个值在浏览器当前会话中保存,只要不过期甚至可以保存很久。
用户每次向服务器提交请求时,将这些 Cookie 提交到服务器,服务器经过分析 Cookie 中的信息,以确认用户身份,确认是信任的用户身份,就可以继续使用网站功能。
Cookie,网景公司发明。cookie 一般是一个键值对 name=value,但还可以包括 expire 过期时间、path 路径、domain 域、secure 安全等信息。
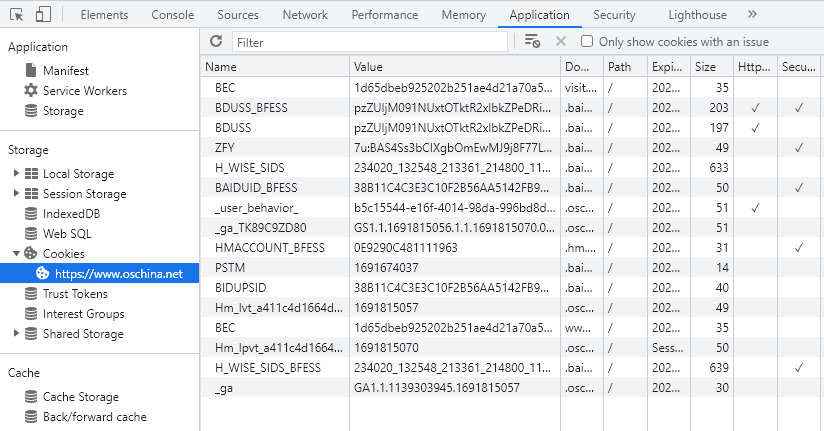
清空 oschina.net 的所有 cookies,浏览器地址栏输入 https://www.oschina.net/home/login,跳到登陆页面,勾选"记住密码"。
# 未登录oschina前,F12抓取HTTP请求头如下:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Connection: keep-alive
Host: www.oschina.net
sec-ch-ua: "Chromium";v="110", "Not A(Brand";v="24", "Google Chrome";v="110"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: none
Sec-Fetch-User: ?1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36输入用户名密码登陆后,再次使用 https://www.oschina.net/home/login 登陆试试,请求头如下:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Connection: keep-alive
Cookie: _user_behavior_=e673d52f-6c29-454a-8b31-ce7b7bdb55ef; BEC=1d65dbeb925202b251ae4d21a70a56af; yp_riddler_id=932915b1-dce4-43f8-bfe0-b556b5e2d4a4; _reg_key_=gjXbyfCp3j5pEoQbU7AR; Hm_lvt_a411c4d1664dd70048ee98afe7b28f0b=1691816615,1691816695,1691816928,1691818600; oscid=mCOSUQvcQzty9lz37EExXg9gK3%2FAXkfhgeU2UU6izJzKuuLmm2SxrHBC%2FULZ3ibP4eYPm0opK16WQQA6SFPncdhUGGrofFqaE%2FOMtDUh9zWghgnVG3cgC3a3SWGa0PqnP9jzn5Z%2BxErrCMvUVOA7Rw%3D%3D; _ga_TK89C9ZD80=GS1.1.1691818953.1.0.1691818953.0.0.0; _ga=GA1.1.1152444630.1691818953; Hm_lpvt_a411c4d1664dd70048ee98afe7b28f0b=1691818953
Host: www.oschina.net
sec-ch-ua: "Chromium";v="110", "Not A(Brand";v="24", "Google Chrome";v="110"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: none
Sec-Fetch-User: ?1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36很明显,多了 cookie 头,这是因为服务器 set-cookie 的结果,并且从浏览器反应来看,不会再显示登陆界面,而是直接跳到首页面,这是 cookie 中的 oscid 起了关键性作用。这个 oscid 是后端服务器用来计算作为认证信息的依据。
我们打算将登陆后的 Request cookie 插入到登陆前的 Request header 中,访问 https://my.oschina.net/,看能不能获得个人用户信息。
import requests
url = 'https://my.oschina.net'
headers = {
# 未登录oschina前,F12抓取HTTP请求头如下:
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'www.oschina.net',
'sec-ch-ua': '"Chromium";v="110", "Not A(Brand";v="24", "Google Chrome";v="110"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': "Windows",
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'Cookie': '_user_behavior_=e673d52f-6c29-454a-8b31-ce7b7bdb55ef; BEC=1d65dbeb925202b251ae4d21a70a56af; yp_riddler_id=932915b1-dce4-43f8-bfe0-b556b5e2d4a4; _reg_key_=gjXbyfCp3j5pEoQbU7AR; Hm_lvt_a411c4d1664dd70048ee98afe7b28f0b=1691816615,1691816695,1691816928,1691818600; oscid=mCOSUQvcQzty9lz37EExXg9gK3%2FAXkfhgeU2UU6izJzKuuLmm2SxrHBC%2FULZ3ibP4eYPm0opK16WQQA6SFPncdhUGGrofFqaE%2FOMtDUh9zWghgnVG3cgC3a3SWGa0PqnP9jzn5Z%2BxErrCMvUVOA7Rw%3D%3D; _ga_TK89C9ZD80=GS1.1.1691818953.1.0.1691818953.0.0.0; _ga=GA1.1.1152444630.1691818953; Hm_lpvt_a411c4d1664dd70048ee98afe7b28f0b=1691818953',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
}
response = requests.request("GET", url, headers=headers)
with response:
with open('profile.html', 'w', encoding='utf-8') as f:
text = response.text
f.write(text)
print(text) # 搜索 user-info
print(response.status_code, '~~~~~~~~~~~~~~~~~~~~')很明显,返回的是已登陆的页面,如果这个 cookie 中不包含 oscid,返回的页面是需要登陆注册的页面。
新浪微博等都一样,只要允许记住用户登录,就可以通过上述方法登录后爬取内容。
3.5、多线程爬取博客园
博客园的新闻分页地址 https://news.cnblogs.com/n/page/10/,多线程批量爬取新闻的标题和链接。
https://news.cnblogs.com/n/page/2/,这个 url 中变化的是最后的数字,它是页码。
from concurrent.futures import ThreadPoolExecutor
import requests
import logging
from queue import Queue
import threading
from bs4 import BeautifulSoup
import time
FORMAT = "%(asctime)s %(threadName)s %(thread)d %(message)s"
logging.basicConfig(format=FORMAT, level=logging.INFO)
# 'https://news.cnblogs.com/n/page/10/'
BASE_URL = 'https://news.cnblogs.com'
NEWS_PAGE = '/n/page/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/5.0 Chrome/55.0.2883.75 Safari/537.36',
}
# 使用池,以后可以使用第三方消息队列完成
urls = Queue() # url的队列
htmls = Queue() # 响应数据队列
outputs = Queue() # 结果输出队列
event = threading.Event()
# 创建博客园的新闻urls,每页30条新闻
def create_urls(start, end, step=1):
for i in range(start, end + 1, step):
urls.put(f'{BASE_URL}{NEWS_PAGE}{i}')
print('url创建完毕')
def crawler():
while not event.is_set():
try:
url = urls.get(True, 1)
with requests.get(url, headers=headers) as response:
html = response.text
htmls.put(html)
print(url)
except:
pass
# 解析线程函数
def parser():
while not event.is_set():
try:
html = htmls.get(True, 1)
soup = BeautifulSoup(html, 'lxml')
titles = soup.select('h2.news_entry a')
for title in titles:
# <a href="/n/747250/" target="_blank">新能源价格战在美开打:Lucid官宣限时降价,最高降2.9万美元</a>
val = title.text, BASE_URL + title.get('href')
outputs.put(val)
print(val)
except:
pass
# 持久化线程函数
def save(path):
with open(path, 'a+') as f:
while not event.is_set():
try:
text, url = outputs.get(True, 1)
print(text, url, '~~~~~~~~~~~~~~~~')
f.write(f'{text} {url}\n')
f.flush()
except:
pass
# 线程池
executor = ThreadPoolExecutor(10)
executor.submit(create_urls, 1, 10)
executor.submit(parser)
executor.submit(save, 'news.txt')
for i in range(7):
executor.submit(crawler)
while True:
inp = input('>>>')
if inp.strip() == 'quit':
event.set()
print('closing ......')
time.sleep(4)
break