
第 9 章 Linux 进程和信号
9.1、进程概念
进程是一个复杂而且比较抽象的概念,涉及的内容也非常多。对于开发者来说,比较关心的问题是自己写得程序运行效率是否高效,那就必须对进程的理解要足够到位。程序设计使用进程还是轻量级线程,设计的思想是使用同步还是异步,阻塞还是非阻塞,这些都对程序的性能有不同程度的影响。
对于运维者来说,涉及到某个特定的项目,一定是整合了大量的程序,来适应不同层次不同角度的客户需求。这个时候我们需要对这个正在运行的程序进行监控收集,调优排错,这都是比较高级的技能,如果对进程的运行不够了解,是很难下手的,也决不能轻易下手。
所以无论是开发人员还是运维人员,只要是对程序的性能有要求,那是逃不过对进程的深入学习的,本章节会涉及到很多概念,好比武侠小说里面的内功心法一样,内力纯厚,也就不在乎使用什么工具招式,飞沙走石亦是剑。
9.1.1、进程和程序
程序是二进制文件,是静态存放在磁盘上的,不会占用系统运行资源(cpu/内存)。
进程是用户执行程序或者触发程序的结果,可以认为进程是程序的一个运行实例。进程是动态的,会申请和使用系统资源,并与操作系统内核进行交互。在后文中,不少状态统计工具的结果中显示的是 system 类的状态,其实 system 状态的同义词就是内核状态。
9.1.2、多任务和 CPU 时间片
现在所有的操作系统都能 "同时" 运行多个进程,也就是多任务或者说是并行执行。但实际上这是人类的错觉,一颗单核物理 cpu 在同一时刻只能运行一个进程,只有多颗或多核心物理 cpu 才能真正意义上实现多任务。
人类会产生错觉,以为操作系统能并行做几件事情,这是通过在极短时间内进行进程间切换实现的,因为时间极短,前一刻执行的是进程 A,下一刻切换到进程 B,不断的在多个进程间进行切换,使得人类以为在同时处理多件事情。
不过,cpu 如何选择下一个要执行的进程,这是一件非常复杂的事情。在 Linux 上,决定下一个要运行的进程是通过 "调度类"(调度程序) 来实现的。程序何时运行,由进程的优先级决定,但要注意,优先级值越低,优先级就越高,就越快被调度类选中。
除此之外,优先级还影响分配给进程的时间片长短。在 Linux 中,改变进程的 nice 值,可以影响某类进程的优先级值。
有些进程比较重要,要让其尽快完成,有些进程则比较次要,早点或晚点完成不会有太大影响,所以操作系统要能够知道哪些进程比较重要,哪些进程比较次要。比较重要的进程,应该多给它分配一些 cpu 的执行时间,让其尽快完成。下图是 cpu 时间片的概念。
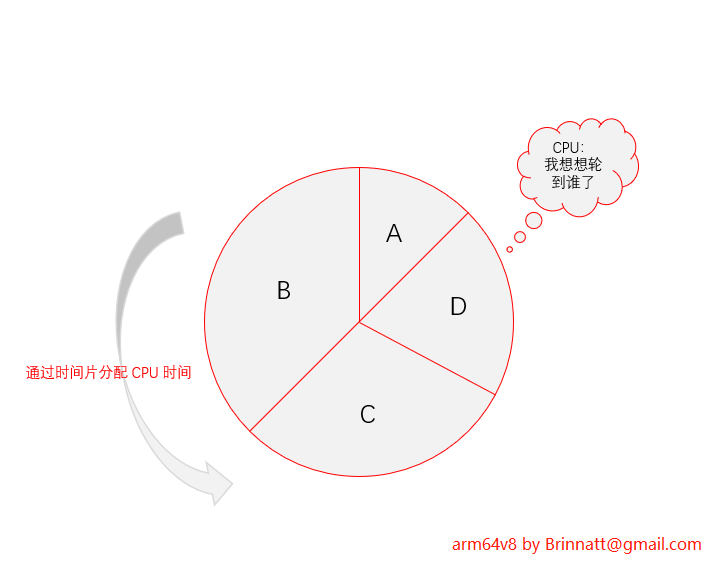
由此可以知道,所有的进程都有机会运行,但重要的进程总是会获得更多的 cpu 时间,这种方式是 "抢占式多任务处理":内核可以强制在时间片耗尽的情况下收回 cpu 使用权,并将 cpu 交给调度类选中的进程,此外,在某些情况下也可以直接抢占当前运行的进程。
进程进行到某个阶段时,有可能会发起 IO 请求,到磁盘上拿数据,这个过程相对 CPU 来说很漫长,该进程暂时进入睡眠状态等待数据完成复制,然后被唤醒。这个过程中会把 CPU 时间片让出来给别的进程使用。这只是其中一种情况,让不让别的进程插进来,都是由调度器算法实现的。
但因为前面的进程还没有完成,在未来某个时候调度类还是会选中它,所以内核应该将每个进程临时停止时的运行时环境(寄存器中的内容和页表)保存下来(保存位置为内核占用的内存),这称为保护现场,在下次进程恢复运行时,将原来的运行时环境加载到 cpu 上,这称为恢复现场,这样 cpu 可以在当初的运行时环境下继续执行。
调度类选中了下一个要执行的进程后,要进行底层的任务切换,也就是上下文切换,这一过程需要和 cpu 进程紧密的交互。进程切换不应太频繁,也不应太慢。切换太频繁将导致 cpu 闲置在保护和恢复现场的时间过长,保护和恢复现场对人类或者进程来说是没有产生生产力的(因为它没有在执行程序)。切换太慢将导致进程调度切换慢,很可能下一个进程要等待很久才能轮到它执行,直白的说,如果你发出一个 ls 命令,你可能要等半天,这显然是不允许的。
至此,也就知道了cpu 的衡量单位是时间,就像内存的衡量单位是空间大小一样。进程占用的 cpu 时间长,说明 cpu 运行在它身上的时间就长。注意,cpu 的百分比值不是其工作强度或频率高低,而是 "进程占用 cpu 时间 / cpu 总时间",这个衡量概念一定不要搞错。
9.1.3、父子进程及创建进程的方式
根据执行程序的用户 UID 以及其他标准,会为每一个进程分配一个唯一的 PID。
父子进程的概念,简单来说,在某进程(父进程)的环境下执行或调用程序,这个程序触发的进程就是子进程,而进程的 PPID 表示的是该进程的父进程的 PID。由此也知道了,子进程总是由父进程创建。
在 Linux,父子进程以树型结构的方式存在,父进程创建出来的多个子进程之间称为兄弟进程。CentOS 6 上,init 进程是所有进程的父进程,CentOS 7 systemd 进程是所有进程的父进程。
Linux 上创建子进程的方式有三种(极其重要的概念):一种是 fork 出来的进程,一种是 exec 出来的进程,一种是 clone 出来的进程。
- fork 是复制进程,它会复制当前进程的副本(不考虑写时复制的模式),以适当的方式将这些资源交给子进程。所以子进程掌握的资源和父进程是一样的,包括内存中的内容,所以也包括环境变量和变量。但父子进程是完全独立的,它们是一个程序的两个实例。
- 实际上,fork 通过 写时复制(copy-on-write, COW) 技术来避免复制进程的所有内存内容。换句话说,fork 并不立刻复制父进程的所有资源,只有在父子进程分别修改某个内存页时,才会复制该内存页。因此,写时复制使得 fork 更加高效。
- exec 是加载另一个应用程序,替代当前运行的进程,也就是说在不创建新进程的情况下加载一个新程序。实际上,exec 会直接用新的程序替换掉当前进程的内容,所以执行完新程序后,原有的进程(即调用 exec 的进程)会完全消失。
- 所以为了保证进程安全,若要形成新的且独立的子进程,都会先 fork 一份当前进程,然后在 fork 出来的子进程上调用 exec 来加载新程序替代该子进程。
- 例如在 bash 下执行 cp 命令,会先 fork 出一个 bash,然后再 exec 加载 cp 程序覆盖子 bash 进程变成 cp 进程。但要注意,fork 进程时会复制所有内存页,但使用 exec 加载新程序时会初始化地址空间,意味着复制动作完全是多余的操作,当然,有了写时复制技术不用过多考虑这个问题。
- clone 是用来创建新进程或线程的系统调用。与 fork 类似,clone 创建的进程可以与父进程共享某些资源,如内存、文件描述符等。通过适当设置,clone 可以用于实现轻量级的线程(比 fork 更高效),使得线程可以共享父进程的某些资源,减少了进程之间的内存开销。
9.1.4、进程的状态
进程有几种状态,不同的状态之间可以实现状态切换。下图是进程状态描述图。
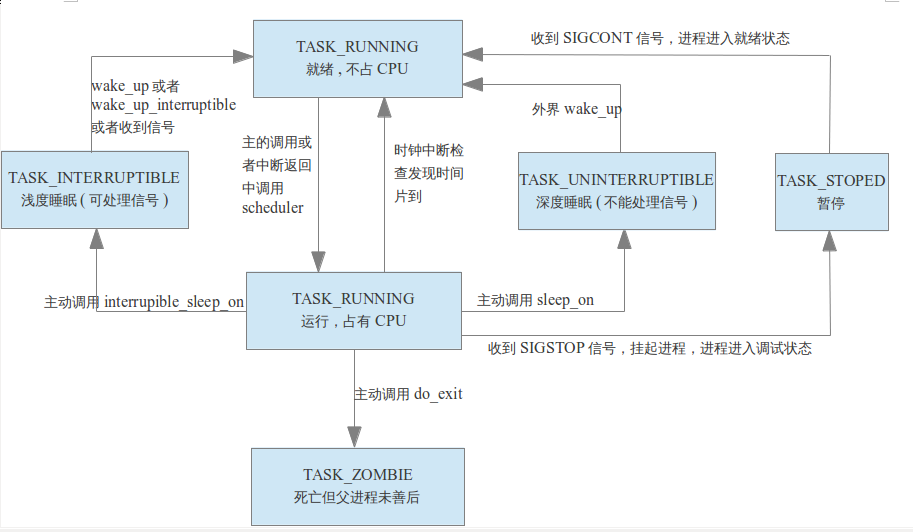
下面解释一下进程的这些状态是什么意思:
TASK_RUNNING:就绪态或者运行态,进程就绪可以运行,但是不一定正在占有CPU,对应进程状态的 R
TASK_INTERRUPTIBLE:睡眠态,但是进程处于浅度睡眠,可以响应信号,一般是进程主动sleep进入的状态,对应进程状态 S
#include <stdio.h>
#include <unistd.h>
#include <signal.h>
#include <stdlib.h>
volatile sig_atomic_t signal_received = 0;
void signal_handler(int signo) {
if (signo == SIGINT) {
printf("Received SIGINT signal, waking up...\n");
signal_received = 1; // 标记信号已接收到
}
}
int main() {
if (signal(SIGINT, signal_handler) == SIG_ERR) {
perror("signal");
exit(1);
}
printf("Process going to sleep for 10 seconds...\n");
// 进程进入浅度睡眠状态(TASK_INTERRUPTIBLE),等待 10 秒或信号
sleep(10); // 如果收到信号,sleep 会提前返回
if (signal_received) {
printf("Process was woken up by signal.\n");
} else {
printf("Process woke up after sleep timeout.\n");
}
return 0;
}
sleep 和信号中断:
当进程调用 sleep(10) 时,它会进入一个 等待状态,也就是 TASK_INTERRUPTIBLE(浅度睡眠)。在此状态下,进程会停止执行,等待直到指定的时间过去或接收到某个信号。具体来说,sleep 会进入一个等待事件(时间到期或者信号)的状态。
如果没有接收到任何信号,进程会一直等待,直到指定的时间(比如 10 秒)到期,然后继续执行。
如果接收到信号,例如 SIGINT(由 Ctrl+C 发送),进程会被信号中断并立即唤醒,从 sleep 状态中返回。这时,sleep 会结束并返回。这意味着 sleep(10) 并不会必定等到 10 秒才结束,信号到来时它会提前退出。
为什么 sleep 可以提前退出:
sleep 是一个阻塞的系统调用,它会让进程处于 TASK_INTERRUPTIBLE 状态,等待一定的时间或某个事件(如信号)。如果在等待期间,进程接收到信号,内核会根据信号处理机制打断 sleep,使进程从 sleep 返回,而不会继续等待剩余的时间。TASK_UNINTERRUPTIBLE:睡眠态,深度睡眠,不响应信号,典型场景是进程获取信号量阻塞,对应进程状态 D
TASK_UNINTERRUPTIBLE 是进程进入深度睡眠的状态,通常是由于进程在等待一些资源(如获取信号量、锁或某些 I/O 操作)而导致的。在此状态下,进程不会响应信号,直到资源可用。
代码示例:TASK_UNINTERRUPTIBLE(进程进入深度睡眠并不响应信号)
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#include <stdlib.h>
// 共享资源和锁
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
// 线程函数:模拟进程进入深度睡眠
void* thread_function(void* arg) {
printf("Thread trying to acquire lock...\n");
// 获取锁,这会导致线程进入阻塞状态(TASK_UNINTERRUPTIBLE)
pthread_mutex_lock(&lock);
printf("Thread acquired lock!\n");
// 模拟线程工作
sleep(2);
pthread_mutex_unlock(&lock);
return NULL;
}
int main() {
pthread_t thread;
// 创建并启动线程
if (pthread_create(&thread, NULL, thread_function, NULL)) {
perror("pthread_create");
exit(1);
}
// 主线程尝试获取锁,这会导致主线程阻塞,进入 TASK_UNINTERRUPTIBLE 状态
printf("Main thread trying to acquire lock...\n");
pthread_mutex_lock(&lock); // 此时主线程进入 TASK_UNINTERRUPTIBLE 状态,无法响应信号
printf("Main thread acquired lock!\n");
pthread_mutex_unlock(&lock);
// 等待子线程结束
pthread_join(thread, NULL);
return 0;
}
线程阻塞:在 thread_function 中,子线程通过 pthread_mutex_lock 获取锁。主线程在尝试获取相同的锁时,会被阻塞,进入 TASK_UNINTERRUPTIBLE 状态,直到子线程释放锁。
进程进入深度睡眠:在 pthread_mutex_lock 获取锁时,主线程进入深度睡眠(TASK_UNINTERRUPTIBLE),此时即使收到信号,主线程也不会响应信号,只有当锁被释放时,主线程才会继续执行。TASK_ZOMBIE:僵尸态,进程已退出或者结束,但是父进程还不知道,没有回收时的状态,对应进程状态 Z
TASK_STOPED:停止,调试状态,对应进程状态 T
9.1.5、进程状态转换过程
进程间状态的转换情况可能很复杂,这里举一个例子,以在 bash 下执行 cp 命令为例,尽可能详细地描述它们。
-
在当前 bash 环境下,当执行 cp 命令时,bash 首先通过 fork 系统调用创建一个子进程,该子进程继承了父进程的上下文。随后,子进程通过 exec 系统调用加载并执行 cp 程序,替换其自身的进程映像,从而变成一个全新的 cp 进程。
-
在 cp 进程执行的过程中,父进程 bash 会调用 wait 系统调用,进入睡眠状态以等待子进程完成任务。父进程的睡眠状态并不是因为 CPU 核心数量的限制,而是因为 wait 系统调用的本质。此时,bash 无法响应用户输入,直到子进程完成并通过 exit 系统调用返回状态。
-
当 cp 命令执行完成后,子进程将退出状态码返回给父进程。bash 被 wait 唤醒后,通过系统调用获取子进程的退出状态码,并继续执行后续任务。此时,cp 进程的资源会被内核清理,进程表中的条目被删除。
-
如果 cp 命令处理的任务较大,比如复制一个大文件,在一个 CPU 时间片内无法完成任务时,cp 进程会被操作系统的调度器移出运行队列,进入等待队列(阻塞态或就绪态),以便其他进程能获得 CPU 时间片继续执行。当再次获得时间片时,cp 会重新进入运行状态。
在 cp 执行过程中,如果遇到目标位置已经存在同名文件,且未指定覆盖选项,cp 会输出提示,等待用户输入 yes 或 no 的指令。这时,cp 进程会进入可中断睡眠状态(S 状态)。当用户输入指令后,cp 进程会被唤醒,进入就绪状态,并等待调度器重新选中它执行。
在 cp 需要与磁盘进行 I/O 操作的过程中,进程会进入不可中断睡眠状态(D 状态),等待硬件操作完成。此状态通常是短暂的,但在硬件响应延迟时可能会持续较长时间。
如果 cp 进程在执行时异常结束,而父进程 bash 没有调用 wait 或 waitpid 系统调用来获取其退出状态,则该进程会变为僵尸进程。这种情况在本例中通常不会发生,因为交互式 shell 会自动调用 wait 回收子进程。
9.1.6、进程结构和子 shell
前台进程
- 一般命令(如 cp 命令)在执行时会通过 fork 创建子进程来执行。父进程会等待子进程执行完毕再继续运行,这种情况称为“前台进程”。
- 在执行前台进程时,父进程通常会等待子进程结束后才恢复执行,这与 CPU 核心数无关。即使有多个 CPU,父进程在等待子进程时仍然处于睡眠状态。要实现真正的多任务并行执行,应使用多线程或多进程技术。
后台进程
- 当命令末尾加上
&符号时,命令会在后台执行。 - 将命令放入后台时,父进程会立即返回,并显示该后台进程的作业 ID 和进程 ID(PID)。因此,父进程不会进入睡眠状态。
- 当后台进程出现错误或执行完毕后,父进程会收到一个信号。
- 通过在命令后加
&,并在&后继续执行另一个命令,能够实现“伪并行”执行。例如:cp /etc/fstab /tmp & cat /etc/fstab。
bash 内置命令
- Bash 内置命令非常特殊,执行这些命令时父进程不会创建新的子进程,而是直接在当前 Bash 进程中执行。
- 如果将内置命令放在管道中执行,内置命令会与管道左边的进程共享一个进程组,这时会创建子进程,但不一定是子 shell。
echo "Hello" | read var在这个例子中,
echo "Hello"是一个外部命令,它会创建一个进程,并将字符串"Hello"传输到管道中。然后,read var是一个Bash内置命令,它会读取管道中的数据并将其存入变量var。由于read是内置命令,它本身不会创建新的 shell,但为了在管道中执行,它实际上会创建一个新的子进程,这个子进程与管道左边的进程(即echo命令)共享同一个进程组。
下面解释下子 shell,这个特殊的子进程。
- 一般 fork 出来的子进程会继承父进程的环境和变量,执行 cp 命令时,子进程会继承父进程的变量。然而,cp 命令本身是在哪个进程中执行的呢?
- cp 命令是在子 shell 中执行的。执行命令时,当前 Bash 进程会 fork 出一个子 Bash 进程,然后通过 exec 加载 cp 程序来替代该子 Bash 进程。
- 不必纠结子 Bash 和子 shell 的概念,它们在很多情况下可以视为同一种东西。
- 通过这些例子来理解子 shell 的执行情况:
- 执行 Bash 内置命令
Bash 内置命令是在当前 Bash 进程中直接执行的,不会创建子进程。如果内置命令放在管道后,它会与管道前的进程在同一进程组中,虽然此时会创建子进程,但仍不一定是子 shell。 - 执行 Bash 命令
- 执行 Bash 命令时,通常会进入一个子 shell 环境,加载父 shell 的配置文件并继承环境变量。尽管 bash 命令的子进程会继承父进程的环境,但它会加载新的环境配置,因此一些变量会被覆盖。
- 执行 bash 命令后,通过变量
$BASH_SUBSHELL可以看到其值为 0,表示没有进入嵌套的子 shell。而$BASHPID的值会与父进程不同,说明它是一个独立的子进程。 - 执行 Bash 命令时,应该理解为进入了一个新的、独立的 shell 环境,而不是仅仅进入子 shell。
- 执行 Shell 脚本
- Shell 脚本的执行通常使用
#!/bin/bash或通过直接执行bash xyz.sh,这与执行 bash 命令相同,都是进入子 shell 环境。 - 脚本执行时,虽然有环境配置的加载,但只有父 shell 的命令路径会被继承。
- 执行完脚本后,子 shell 会自动退出。
- Shell 脚本的执行通常使用
- 执行非 Bash 内置命令
例如执行 cp 或 grep 等命令时,Shell 会 fork 出一个新的 Bash 进程,并通过 exec 加载所需程序替代子进程。这样子进程继承了父 Bash 的环境,但程序启动后会丢失大部分 Bash 环境。 - 命令替换中的子 shell
- 在命令行中包含命令替换(例如
$(command))时,会启动一个子 shell 来执行替换内容,然后将执行结果返回给当前命令。这个子 shell 会继承父 shell 的环境变量。 - 例如
$(echo $$)返回的是当前 Bash 的进程 ID,而不是子 shell 的 ID,因为命令替换使用了子 shell 环境。
- 在命令行中包含命令替换(例如
- 使用括号 () 组合命令
在括号内执行的命令会在一个子 shell 中运行,类似于命令替换的情况。例如:(ls;date;echo hello)。
- 执行 Bash 内置命令
最后,子 shell 的环境变化不会影响父 shell。例如,子 shell 中设置的变量不会回传到父 shell。
两种特殊的脚本调用方式:
-
exec
- exec 是通过加载程序来替换当前进程,执行命令或脚本时不会创建子 shell,而是直接在当前 shell 中执行命令。执行完后,所在的 shell 退出。
- 例如,执行 cp 命令时,cp 执行完后会自动退出其所在的子 shell。
-
source
- source 命令通常用于加载环境配置脚本。它不会创建子 shell,而是直接在当前 shell 中执行脚本,执行完毕后不会退出当前 shell。
- 使用 source 加载的脚本会继承当前 shell 的环境,并且脚本中设置的环境变量会保持在当前 shell 中生效。
9.1.7 Daemon 类进程
当一个进程脱离了 Shell 环境后,它就可以被称为后台服务类进程,即 Daemon 类守护进程,显然 Daemon 类进程的 PPID=1(通常是 init 或 systemd 进程)。当某进程脱离 Shell 的控制,也意味着它脱离了终端;当终端断开连接时,不会影响这些进程。
需特别关注的是创建 Daemon 类进程的流程:首先有一个父进程,父进程在某个时间点 fork() 出一个子进程继续运行代码逻辑。父进程立即终止,该子进程成为孤儿进程,最终由 init 进程收养,通常被称为 Daemon 类进程。
当然,要创建一个完善的 Daemon 类进程还需考虑其他一些事情,比如要独立一个会话和进程组,要关闭 stdin/stdout/stderr,要 chdir() 到 / 目录以防止文件系统错误导致进程异常,等等。不过最关键的特性仍然是其脱离 Shell、脱离终端。
为什么要 fork 一个子进程作为 Daemon 进程?为什么父进程要立即退出?
- 所有的 Daemon 类进程都需要脱离 Shell 和终端,才能不受终端、用户或控制台影响,从而保持长久运行。
- 在代码层面上,脱离 Shell 和终端是通过 setsid() 创建一个独立的会话(Session)来实现的。进程组的首进程(pg leader)不允许创建新的会话(Session),因此只有进程组中的非首进程(比如进程组首进程的子进程)才能调用 setsid() 来脱离原会话,从而创建新的会话。
- Shell 命令行下运行的命令总是会创建一个新的进程组并成为 leader 进程,因此如果要让该程序成为长期运行的 Daemon 进程,必须通过 fork() 创建一个新的子进程,并在子进程中调用 setsid() 来创建新的会话,从而脱离当前的 Shell。
- 父进程立即退出的原因通常是为了将终端控制权交还给当前的 Shell 进程,并避免父进程占用终端。虽然这不是强制性的要求,理论上父进程也可以继续运行并占用终端,但这样做不推荐,因为这会导致代码设计不友好,且可能干扰终端的正常使用。
总之,当用户运行一个 Daemon 类程序时,总是会有一个瞬间消失的父进程。
举例:为了更接近实际环境,这里用 Nginx 来论证这个现象。默认配置下,Nginx 以 Daemon 方式运行,所以 Nginx 启动时会有一个瞬间消失的父进程,之后它成为一个独立运行的 Daemon 进程。
[root@arm64v8 ~]# ps -o pid,ppid,comm; nginx; ps -o pid,ppid,comm $(pgrep nginx)
PID PPID COMMAND
16849 16844 bash
17026 16849 ps
PID PPID COMMAND
17028 1 nginx
17029 17028 nginx
17030 17028 nginx
17031 17028 nginx
17032 17028 nginx
17033 17028 nginx
17035 17028 nginx
17036 17028 nginx
17037 17028 nginx
17038 17028 nginx
17039 17028 nginx
17040 17028 nginx
17041 17028 nginx
17042 17028 nginx
17043 17028 nginx
17044 17028 nginx
17045 17028 nginx
[root@arm64v8 ~]# - 第一个 ps 命令查看到当前分配到的 PID 值为 17026,下一个进程的 PID 应该分配为 17027,但是第二个 ps 查看到 nginx 的 main 进程 PID 为 17028,中间消失的就是 nginx main 进程的父进程。
可以修改配置文件使得 nginx 以非 daemon 方式运行,即在前台运行,这样 nginx 将占用终端,且没有中间的父进程,占用终端的进程就是 main 进程。
[root@arm64v8 ~]# ps -o pid,ppid,comm; nginx -g 'daemon off;' &
PID PPID COMMAND
16849 16844 bash
17087 16849 ps
[1] 17088
[root@arm64v8 ~]#
[root@arm64v8 ~]# ps -o pid,ppid,comm $(pgrep nginx)
PID PPID COMMAND
17088 16849 nginx
17089 17088 nginx
17090 17088 nginx
17091 17088 nginx
17092 17088 nginx
17093 17088 nginx
17094 17088 nginx
17095 17088 nginx
17096 17088 nginx
17097 17088 nginx
17098 17088 nginx
17099 17088 nginx
17100 17088 nginx
17101 17088 nginx
17102 17088 nginx
17103 17088 nginx
17104 17088 nginx
[root@arm64v8 ~]#最后需要区分后台进程和 Daemon 类进程,它们都在后台运行。但普通的后台进程仍然受 shell 进程的监督和管理,用户可以将其从后台调度到前台运行,即让其再次获得终端控制权。而 Daemon 类进程脱离了终端、脱离了 Shell,它们不再受 Shell 的监督和管理,而是接受 pid=1 的 systemd 进程的管理。
9.2、job 任务
大部分进程都能将其放入后台,这时它就是一个后台任务,所以常称为 job,每个开启的 shell 会维护一个 job table,后台中的每个 job 都在 job table 中对应一个 Job 项。
手动将命令或脚本放入后台运行的方式是在命令行后加上 "&" 符号。例如:
[root@computer1 ~]# cp /etc/fstab /tmp/ &
[1] 403913
[1]+ 已完成 cp -i /etc/fstab /tmp/
[root@computer1 ~]#- 将进程放入后台后,会立即返回其父进程,一般对于手动放入后台的进程都是在 bash 下进行的,所以立即返回 bash 环境。
- 在返回父进程的同时,还会返回给父进程其 job id 和 pid。
- 未来要引用 job id,都应该在 job id前加上百分号 "%",其中 "%%" 表示当前 job,例如 "kill -9 %1" 表示杀掉 job id 为 1 的后台进程,如果不加百分号,完了,把 Init 进程给杀了(但该进程特殊,不会受影响)。
通过 jobs 命令可以查看后台 job 信息。
jobs [-lrs] [job id]
选项说明:
-l:jobs默认不会列出后台工作的PID,加上-l会列出进程的PID
-r:显示后台工作处于run状态的jobs
-s:显示后台工作处于stopped状态的jobs通过 "&" 放入后台的任务,在后台中仍会处于运行中。当然,对于那种交互式如 vim 类的命令,将转入暂停运行状态。
[root@computer1 ~]# sleep 10 &
[1] 412776
[root@computer1 ~]# jobs
[1]+ 运行中 sleep 10 &
[root@computer1 ~]#一定要注意,此处看到的是 "运行中" 和 ps 或 top 显示的 R 状态,它们并不总是表示正在运行,处于等待队列的进程也属于 "运行中"。它们都属于 task_running 标识。
另一种手动加入后台的方式是按下 CTRL+Z 键,这可以将正在运行中的进程加入到后台,但这样加入后台的进程会在后台暂停运行。
[root@computer1 ~]# sleep 10
^Z
[1]+ 已停止 sleep 10
[root@computer1 ~]# jobs
[1]+ 已停止 sleep 10
[root@computer1 ~]#从 jobs 信息也看到了在每个 job id 的后面有个 + 号,还有 -,或者不带符号。
[root@computer1 ~]# sleep 30 & vim /etc/my.cnf & sleep 50 &
[1] 437387
[2] 437388
[3] 437390
[root@computer1 ~]# jobs
[1] 运行中 sleep 30 &
[2]+ 已停止 vim /etc/my.cnf
[3]- 运行中 sleep 50 &
[root@computer1 ~]#- 发现 vim 的进程后是加号,
+表示最近进入后台的作业,也称为当前作业,-表示倒数第二个进入后台的作业。 - 如果后进入后台的作业先执行完成了,则
+和-所代表的作业顺位前移。 - 如果只有一个后台作业,则
+和-都代表这个作业。 - 所以,使用
%+和%%可以代表最后一个作业的 job id,使用%-可以代表倒数第二个 job 的 job id。
回归正题。既然能手动将进程放入后台,那肯定能调回到前台,调到前台查看了下执行进度,又想调入后台,这肯定也得有方法,总不能使用 CTRL+Z 以暂停方式加到后台吧。
fg 和 bg 命令分别是 foreground 和 background 的缩写,也就是放入前台和放入后台,严格的说,是以运行状态放入前台和后台,即使原来任务是 stopped 状态的。
操作方式也很简单,直接在命令后加上 job id 即可(即[fg|bg] [%jobid]),不给定 job id 时操作的将是当前任务,即带有 + 的任务项。
[root@computer1 ~]# sleep 100
^Z # 按下CTRL+Z进入暂停并放入后台
[1]+ 已停止 sleep 100
[root@computer1 ~]# jobs
[1]+ 已停止 sleep 100 # 此时为stopped状态
[root@computer1 ~]#
[root@computer1 ~]# bg %1 # 使用 bg 可以让暂停状态的进程变会运行态
[1]+ sleep 100 &
[root@computer1 ~]#
[root@computer1 ~]# fg %1 # 使用 fg 可以将后台任务调回至前台并处于运行状态
sleep 100
^Z
[1]+ 已停止 sleep 100
[root@computer1 ~]#disown 命令可以从 job table 中直接移除一个 job,仅仅只是移出 job table,并非是结束任务。而且移出 job table 后,作业将脱离 shell 管理,不再依赖于终端,当终端断开会立即挂在 init/systemd 进程之下。所以, disown 命令提供了让进程脱离终端的另一种方式。
disown [-ar] [-h] [%jobid ...]
选项说明:
-h:给定该选项,将不从job table中移除job,而是将其设置为不接受shell发送的sighup信号。具体说明见"信号"小节。
-a:如果没有给定jobid,该选项表示针对Job table中的所有job进行操作。
-r:如果没有给定jobid,该选项严格限定为只对running状态的job进行操作如果不给定任何选项,该 shell 中所有的 job 都会被移除,移除是 disown 的默认操作,如果也没给定 job id,而且也没给定 -a 或 -r,则表示只针对当前任务即带有 "+" 号的任务项。
[root@computer1 ~]# sleep 30 & sleep 40 &
[1] 517131
[2] 517132
[root@computer1 ~]# jobs
[1]- 运行中 sleep 30 &
[2]+ 运行中 sleep 40 &
[root@computer1 ~]#
[root@computer1 ~]# jobs
[1]- 运行中 sleep 30 &
[2]+ 运行中 sleep 40 &
[root@computer1 ~]#
[root@computer1 ~]# disown %2
[root@computer1 ~]# jobs # 已经移除一个
[1]+ 已完成 sleep 30
[root@computer1 ~]#9.3、终端和进程的关系
使用 pstree 命令查看下当前的进程,不难发现在某个终端执行的进程其父进程或上几个级别的父进程总是会是终端的连接程序。
例如下面筛选出了两个终端下的父子进程关系,第一个行是 tty 终端(即直接在虚拟机中)中执行的进程情况,第二行和第三行是 ssh 连接到 Linux 上执行的进程。
[root@computer1 ~]# pstree -c | grep bash
|-login---bash---bash---vim
|-sshd-+-sshd---bash
| `-sshd---bash-+-grep正常情况下杀死父进程会导致子进程变为孤儿进程,即其 PPID 改变,但是杀掉终端这种特殊的进程,会导致该终端上的所有进程都被杀掉。
这在很多执行长时间任务的时候是很不方便的。比如要下班了,但是你连接的终端上还在执行数据库备份脚本,这可能会花掉很长时间,如果直接退出终端,备份就终止了。所以应该保证一种安全的退出方法。
一般的方法也是最简单的方法是使用 nohup 命令带上要执行的命令或脚本放入后台,这样任务就脱离了终端的关联。当终端退出时,该任务将自动挂到 init(或systemd) 进程下执行。如:
[root@computer1 ~]# nohup tar rf a.tar.gz /tmp/*.txt &另一种方法是使用 screen 这个工具,该工具可以模拟多个物理终端,虽然模拟后 screen 进程仍然挂在其所在的终端上的,但同 nohup 一样,当其所在终端退出后将自动挂到 init/systemd 进程下继续存在,只要 screen 进程仍存在,其所模拟的物理终端就会一直存在,这样就保证了模拟终端中的进程继续执行。
它的实现方式其实和 nohup 差不多,只不过它花样更多,管理方式也更多。一般对于简单的后台持续运行进程,使用 nohup 足以。
另外,在子 shell 中的后台进程在终端被关闭时也会脱离终端,因此也不受 shell 和终端的控制。例如 shell 脚本中的后台进程,再如"(sleep 10 &)"。
可能你已经发现了,很多进程是和终端无关的,也就是不依赖于终端,这类进程一般是内核类进程/线程以及 daemon 类进程,若它们也依赖于终端,则终端一被终止,这类进程也立即被终止,这是绝对不允许的。
9.4、信号
信号在操作系统中控制着进程的绝大多数动作,信号可以让进程知道某个事件发生了,也指示着进程下一步要做出什么动作。
信号的来源可以是硬件信号(如按下键盘或其他硬件故障),也可以是软件信号(如kill信号,还有内核发送的信号)。不过,很多可以感受到的信号都是从进程所在的控制终端发送出去的。
9.4.1、常见信号
Linux 中支持非常多种信号,它们都以 SIG 字符串开头,SIG 字符串后的才是真正的信号名称,信号还有对应的数值,其实数值才是操作系统真正认识的信号。
但由于不少信号在不同架构的计算机上数值不同(例如 CTRL+Z 发送的 SIGSTP 信号就有三种值 18,20,24),所以在不确定信号数值是否唯一的时候,最好指定其字符名称。
Signal Value Comment
─────────────────────────────
SIGHUP 1 终端退出时,此终端内的进程都将被终止
SIGINT 2 中断进程,可被捕捉和忽略,几乎等同于sigterm,所以也会尽可能的释放执行clean-up,释放资源,保存状态等(CTRL+C)
SIGQUIT 3 从键盘发出杀死(终止)进程的信号
SIGKILL 9 强制杀死进程,该信号不可被捕捉和忽略,进程收到该信号后不会执行任何clean-up行为,所以资源不会释放,状态不会保存
SIGTERM 15 杀死(终止)进程,可被捕捉和忽略,几乎等同于sigint信号,会尽可能的释放执行clean-up,释放资源,保存状态等
SIGCHLD 17 当子进程中断或退出时,发送该信号告知父进程自己已完成,父进程收到信号将告知内核清理进程列表。所以该信号可以解除僵尸进
程,也可以让非正常退出的进程工作得以正常的clean-up,释放资源,保存状态等。
SIGSTOP 19 该信号是不可被捕捉和忽略的进程停止信息,收到信号后会进入stopped状态
SIGTSTP 20 该信号是可被忽略的进程停止信号(CTRL+Z)
SIGCONT 18 发送此信号使得stopped进程进入running,该信号主要用于jobs,例如bg & fg 都会发送该信号。
可以直接发送此信号给stopped进程使其运行起来
SIGUSR1 10 用户自定义信号1
SIGUSR2 12 用户自定义信号2 除了这些信号外,还需要知道一个特殊信号,代码为 0 的信号。此信号为 EXIT 信号,表示直接退出。
- 如果 kill 发送的信号是 0(即 kill -0) 则表示不做任何处理直接退出,但执行错误检查,当检查发现给定的 pid 进程存在,则返回 0,否则返回 1。也就是说,0 信号可以用来检测进程是否存在,可以代替
ps aux | grep proc_name。
以上所列的信号中,只有 SIGKILL 和 SIGSTOP 这两个信号是不可被捕捉且不可被忽略的信号,其他所有信号都可以通过 trap 或其他编程手段捕捉到或忽略掉。
此外,经常看到有些服务程序(如 httpd/nginx) 的启动脚本中使用 WINCH 和 USR1 这两个信号,发送这两个信号时它们分别表示 graceful stop 和 graceful restart。
-
所谓的 graceful,译为优雅,不过使用这两个字去描述这种环境实在有点不伦不类。它对于后台服务程序而言,传达了几个意思
- 当前已经运行的进程不再接受新请求
- 给当前正在运行的进程足够多的时间去完成正在处理的事情
- 允许启动新进程接受新请求
- 可能还有日志文件是否应该滚动、pid 文件是否修改的可能,这要看服务程序对信号的具体实现
-
再来说说,为什么后台服务程序可以使用这两个信号。以 httpd 的为例,在其头文件 mpm_common.h 中有如下几行代码
/* Signal used to gracefully restart */ #define AP_SIG_GRACEFUL SIGUSR1 /* Signal used to gracefully stop */ #define AP_SIG_GRACEFUL_STOP SIGWINCH- 这说明注册了对应信号的处理函数,它们分别表示将接收到信号时,执行对应的 GRACEFUL 函数。
-
注意,SIGWINCH 是窗口程序的尺寸改变时发送该信号,如 vim 的窗口改变了就会发送该信号。但是对于后台服务程序,它们根本就没有窗口,所以 WINCH 信号对它们来说是没有任何作用的。
-
因此,大概是约定俗成的,大家都喜欢用它来作为后台服务程序的 GRACEFUL 信号。
-
但注意,WINCH 信号对前台程序可能是有影响的,不要乱发这种信号。同理,USR1 和 USR2 也是一样的,如果源代码中明确为这两个信号注册了对应函数,那么发送这两个信号就可以实现对应的功能,反之,如果没有注册,则这两个信号对进程来说是错误信号。
9.4.2、SIGHUP
-
当控制终端退出时,会向该终端中的进程发送 sighup 信号,因此该终端上运行的 shell 进程、其他普通进程以及任务都会收到 sighup 而导致进程终止。
多种方式可以改变因终端中断发送 sighup 而导致子进程也被结束的行为,这里仅介绍比较常见的三种:
- 使用 nohup 命令启动进程,它会忽略所有的 sighup 信号,使得该进程不会随着终端退出而结束;
- 将待执行命令放入子 shell 中并放入后台运行,例如"(sleep 10 &)";
- 使用 disown,将任务列表中的任务移除出 job table 或者直接使用 disown -h 的功能设置其不接收终端发送的 sighup 信号。但不管是何种实现方式,终端退出后未被终止的进程将只能挂靠在 init/systemd 下。
-
对于 daemon 类的程序(即服务性进程),这类程序不依赖于终端(它们的父进程都是 init 或 systemd),它们收到 sighup 信号时会重读配置文件并重新打开日志文件,使得服务程序可以不用重启就可以加载配置文件。
9.4.3、僵尸进程和 SIGCHLD
一个编程完善的程序,在子进程终止、退出的时候,内核会发送 SIGCHLD 信号给其父进程,父进程收到信号就会对该子进程进行善后(接收子进程的退出状态、释放未关闭的资源),同时内核也会进行一些善后操作(比如清理进程表项、关闭打开的文件等)。
在子进程死亡的那一刹那,子进程的状态就是僵尸进程,但因为发出了 SIGCHLD 信号给父进程,父进程只要收到该信号,子进程就会被清理也就不再是僵尸进程。所以正常情况下,所有终止的进程都会有一小段时间处于僵尸态(发送 SIGCHLD 信号到父进程收到该信号之间),只不过这种僵尸进程存在时间极短,几乎是不可被 ps 或 top 这类的程序捕捉到的。
如果在特殊情况下,子进程终止了,但父进程没收到 SIGCHLD 信号,没收到这信号的原因可能是多种的,不管如何,此时子进程已经成了永存的僵尸,能轻易的被 ps 或 top 捕捉到。
- 僵尸爸爸并不知道它儿子已经变成了僵尸,因为有僵尸爸爸的掩护,内核见不到小僵尸,所以也没法收尸。
- 悲催的是,人类能力不足,直接发送信号(如 kill) 给僵尸进程是无效的,因为僵尸进程本就是终结了的进程,它收不到信号。
- 只有内核从进程列表中将僵尸进程表项移除才算完成收尸。
要解决掉永存的僵尸有几种方法:
- 杀死僵尸进程的父进程。没有了僵尸爸爸的掩护,小僵尸就暴露给了 init/systemd,init/systemd 会定期清理它下面的各种僵尸进程。所以这种方法有点不讲道理,僵尸爸爸是正常的啊,不过如果僵尸爸爸下面有很多僵尸儿子,这僵尸爸爸肯定是有问题的,比如编程不完善,杀掉是应该的。
- 手动发送 SIGCHLD 信号给僵尸进程的父进程,主动通知僵尸爸爸,让僵尸爸爸知道自己的儿子死而不僵,然后通知内核来收尸。
- 手动发送 SIGCHLD 信号的方法要求父进程能收到信号,而 SIGCHLD 信号默认是被忽略的,所以应该显式地在程序中加上获取信号的代码。
- 也就是人类主动通知僵尸爸爸的时候,默认僵尸爸爸是不搭理人类的,所以要强制让僵尸爸爸收到通知。不过一般 daemon 类的程序在编程上都是很完善的,发送 SIGCHLD 总是会收到,不用担心。
9.4.4、手动发送信号
使用 kill 命令可以手动发送信号给指定的进程。
kill [-s signal] pid...
kill [-signal] pid...
kill -l使用 kill -l 可以列出 Linux 中支持的信号,有 64 种之多,但绝大多数非编程人员都用不上。
使用 -s 或 -signal 都可以发送信号,不给定发送的信号时,默认为 TREM 信号,即 kill -15。
shell> kill -9 pid1 pid2...
shell> kill -TREM pid1 pid2...
shell> kill -s TREM pid1 pid2...9.4.5、pkill 和 killall
这两个命令都可以直接指定进程名来发送信号,不指定信号时,默认信号都是 TERM。
9.4.5.1 pkill 命令
pkill 和 pgrep 命令是同族命令,都是先通过给定的匹配模式搜索到指定的进程,然后发送信号(pkill) 或列出匹配的进程(pgrep),pgrep 就不介绍了。
pkill 能够指定模式匹配,所以可以使用进程名来删除,想要删除指定 pid 的进程,反而还要使用 "-s" 选项来指定。默认发送的信号是 SIGTERM 即数值为 15 的信号。
pkill [-signal] [-v] [-P ppid,...] [-s pid,...][-U uid,...] [-t term,...] [pattern]
选项说明:
-P ppid,... :匹配PPID为指定值的进程
-s pid,... :匹配PID为指定值的进程
-U uid,... :匹配UID为指定值的进程,可以使用数值UID,也可以使用用户名称
-t term,... :匹配给定终端,终端名称不能带上"/dev/"前缀,其实"w"命令获得终端名就满足此处条件了,所以pkill可以直接杀掉整个终端
-v :反向匹配
-signal :指定发送的信号,可以是数值也可以是字符代表的信号
-f :默认情况下,pgrep/pkill只会匹配进程名。使用-f将匹配命令行在 CentOS 7 上,还有两个好用的新功能选项。
-F, --pidfile file:匹配进程时,读取进程的pid文件从中获取进程的pid值。这样就不用去写获取进程pid命令的匹配模式
-L, --logpidfile :如果"-F"选项读取的pid文件未加锁,则pkill或pgrep将匹配失败。例如:
[root@computer1 ~]# ps x | grep ssh[d]
2477 ? Ss 0:00 /usr/sbin/sshd -D
402315 ? Ss 0:00 sshd: root [priv]
402714 ? S 0:00 sshd: root@pts/12
750267 ? Ss 0:00 sshd: root [priv]
750282 ? S 0:00 sshd: root@pts/13
750385 ? Ss 0:00 sshd: root [priv]
750405 ? S 0:00 sshd: root@pts/16
750478 ? Ss 0:00 sshd: root [priv]
750492 ? S 0:00 sshd: root@pts/17
750539 ? Ss 0:00 sshd: root [priv]
750586 ? S 0:00 sshd: root@pts/18
750661 ? Ss 0:00 sshd: root [priv]
750674 ? S 0:00 sshd: root@pts/19
[root@computer1 ~]#现在想匹配/usr/sbin/sshd。
[root@computer1 ~]# pgrep bin/sshd
[root@computer1 ~]#
[root@computer1 ~]# pgrep -f bin/sshd
2477
[root@computer1 ~]# - 可以看到第一个什么也不返回。因为不加 -f 选项时,pgrep 只能匹配进程名,而进程名指的是 sshd,而非 /usr/sbin/sshd,所以匹配失败。
- 加上 -f 后,就能匹配成功。所以,当 pgrep 或 pkill 匹配不到进程时,考虑加上 -f 选项。
踢出终端:
[root@computer1 ~]# pkill -t pts/189.4.5.2、killall 命令
killall 主要用于杀死一批进程,例如杀死整个进程组。其强大之处还体现在可以通过指定文件来搜索哪个进程打开了该文件,然后对该进程发送信号,在这一点上,fuser 和 lsof 命令也一样能实现。
killall [-r,--regexp] [-s,--signal signal] [-u,--user user] [-v,--verbose] [-w,--wait] [-I,--ignore-case] [--] name ...
选项说明:
-I :匹配时不区分大小写
-r :使用扩展正则表达式进行模式匹配
-s, --signal :发送信号的方式可以是-HUP或-SIGHUP,或数值的"-1",或使用"-s"选项指定信号
-u, --user :匹配该用户的进程
-v, :给出详细信息
-w, --wait :等待直到该杀的进程完全死透了才返回。默认killall每秒检查一次该杀的进程是否还存在,只有不存在了才会给出退出状态码。
如果一个进程忽略了发送的信号、信号未产生效果、或者是僵尸进程将永久等待下去9.5 fuser 和 lsof
fuser 可以查看文件或目录所属进程的pid,即由此知道该文件或目录被哪个进程使用。例如,umount 的时候提示 the device busy 可以判断出来哪个进程在使用。
而 lsof 则反过来,它是通过进程来查看进程打开了哪些文件,但要注意的是,一切皆文件,包括普通文件、目录、链接文件、块设备、字符设备、套接字文件、管道文件,所以 lsof 出来的结果可能会非常多。
9.5.1、fuser 命令
fuser [-ki] [-signal] file/dir
-k:找出文件或目录的pid,并试图kill掉该pid。发送的信号是SIGKILL
-i:一般和-k一起使用,指的是在kill掉pid之前询问。
-signal:发送信号,如-1 -15,如果不写,默认-9,即kill -9
不加选项:直接显示出文件或目录的pid- 在不加选项时,显示结果中文件或目录的pid后会带上一个修饰符:
- c: 在当前目录下
- e: 可被执行的
- f: 是一个被开启的文件或目录
- F: 被打开且正在写入的文件或目录
- r: 代表 root directory
[root@computer1 ~]# fuser /usr/sbin/crond
/usr/sbin/crond: 2483e
[root@computer1 ~]#-
表示 /usr/sbin/crond 被 2483 这个进程打开了,后面的修饰符 e 表示该文件是一个可执行文件。
[root@computer1 ~]# ps aux | grep 248[3] root 2483 0.0 0.0 216128 4544 ? Ss 4月27 0:11 /usr/sbin/crond -n root 26562 0.0 0.0 24832 14976 ? Ss 4月29 3:14 /usr/lib/systemd/systemd --user root 354023 1.1 0.0 30784 24832 ? Sl 4月29 1484:43 /var/lib/zstack/kvm/collectd_exporter -collectd.listen-address :25826 [root@computer1 ~]#
9.5.2、lsof 命令
[root@computer1 ~]# lsof -u root | grep bash
sh 354022 root txt REG 8,4 1280832 27396695 /usr/bin/bash
sh 354059 root txt REG 8,4 1280832 27396695 /usr/bin/bash
sh 354120 root txt REG 8,4 1280832 27396695 /usr/bin/bash
bash 402717 root cwd DIR 8,4 4096 41811969 /root
bash 402717 root rtd DIR 8,4 4096 2 /
bash 402717 root txt REG 8,4 1280832 27396695 /usr/bin/bash
bash 402717 root mem REG 8,4 131494 27396655 /usr/share/locale/zh_CN/LC_MESSAGES/libc.mo
bash 402717 root mem REG 8,4 159999 27396743 /usr/share/locale/zh_CN/LC_MESSAGES/bash.mo
......- 输出信息中各列意义:
- COMMAND:进程的名称
- PID:进程标识符
- USER:进程所有者
- FD:文件描述符,应用程序通过文件描述符识别该文件。如 cwd、txt 等
- TYPE:文件类型,如 DIR、REG 等
- DEVICE:指定磁盘的名称
- SIZE/OFF:文件的大小或文件的偏移量(单位kb)(size and offset)
- NODE:索引节点(文件在磁盘上的标识)
- NAME:打开文件的确切名称
lsof 的各种用法:
lsof [options] filename
lsof /path/to/somefile:显示打开指定文件的所有进程之列表
lsof -c string:显示其COMMAND列中包含指定字符(string)的进程所有打开的文件;此选项可以重复使用,以指定多个模式;
lsof -p PID:查看该进程打开了哪些文件;进程号前可以使用脱字符“^”取反;
lsof -U:列出套接字类型的文件。一般和其他条件一起使用。如lsof -u root -a -U
lsof -u USERNAME:显示指定用户的进程打开的文件;用户名前可以使用脱字符“^”取反,如“lsof -u ^root”则用于显示非root用户打开的所有文件;
lsof -g GID:显示归属gid的进程情况
lsof +d /DIR/:显示指定目录下被进程打开的文件
lsof +D /DIR/:基本功能同上,但lsof会对指定目录进行递归查找,注意这个参数要比grep版本慢:
lsof -a:按“与”组合多个条件,如lsof -a -c apache -u apache
lsof -N:列出所有NFS(网络文件系统)文件
lsof -d FD:显示指定文件描述符的相关进程;也可以为描述符指定一个范围,如0-2表示0,1,2三个文件描述符;另外,-d还支持其它很多特殊值,如:
mem: 列出所有内存映射文件;
mmap:显示所有内存映射设备;
txt:列出所有加载在内存中并正在执行的进程,包含code和data;
cwd:正在访问当前目录的进程列表;
lsof -n:不反解IP至HOSTNAME
lsof -i:用以显示符合条件的进程情况
lsof -i[46] [protocol][@hostname|hostaddr][:service|port]
46:IPv4或IPv6
protocol:TCP or UDP
hostname:Internet host name
hostaddr:IPv4地址
service:/etc/service中的服务名称(可以不只一个)
port:端口号 (可以不只一个)大概 "-i" 是使用最多的了,而 "-i" 中使用最多的又是服务名或端口了。
[root@computer1 ~]# lsof -i :22
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
sshd 2477 root 3u IPv4 2599 0t0 TCP *:ssh (LISTEN)
sshd 2477 root 4u IPv6 2601 0t0 TCP *:ssh (LISTEN)
sshd 402315 root 3u IPv4 520997541 0t0 TCP computer1:ssh->172.16.10.254:54407 (ESTABLISHED)
sshd 402714 root 3u IPv4 520997541 0t0 TCP computer1:ssh->172.16.10.254:54407 (ESTABLISHED)
sshd 750267 root 3u IPv4 521729693 0t0 TCP computer1:ssh->172.16.10.254:58305 (ESTABLISHED)
sshd 750282 root 3u IPv4 521729693 0t0 TCP computer1:ssh->172.16.10.254:58305 (ESTABLISHED)
sshd 750385 root 3u IPv4 521729700 0t0 TCP computer1:ssh->172.16.10.254:58307 (ESTABLISHED)
sshd 750405 root 3u IPv4 521729700 0t0 TCP computer1:ssh->172.16.10.254:58307 (ESTABLISHED)
sshd 750478 root 3u IPv4 521729707 0t0 TCP computer1:ssh->172.16.10.254:58308 (ESTABLISHED)
sshd 750492 root 3u IPv4 521729707 0t0 TCP computer1:ssh->172.16.10.254:58308 (ESTABLISHED)
[root@computer1 ~]#