
第 17 章 数据库中间件 Mycat2
17.1、Mycat2 概述
如今随着互联网的发展,数据的量级也是成指数的增长,从 GB 到 TB 到 PB。对数据的各种操作也是愈加的困难,传统的关系型数据库已经无法满足快速查询与插入数据的需求。
这个时候 NoSQL 的出现暂时解决了这一危机。它通过降低数据的安全性,减少对事务的支持,减少对复杂查询的支持,来获取性能上的提升。
但是,在有些场合 NoSQL 一些折衷是无法满足使用场景的,就比如有些使用场景是绝对要有事务与安全指标的。这个时候 NoSQL 肯定是无法满足的,所以还是需要使用关系型数据库。
如何使用关系型数据库解决海量存储的问题呢?此时就需要做数据库集群,为了提高查询性能将一个数据库的数据分散到不同的数据库中存储。
17.1.1、基本介绍
Mycat2 官网:http://www.mycat.org.cn/
Mycat2 Github:https://github.com/MyCATApache/Mycat2
Mycat2 是 数据库分库分表 中间件。
所谓中间件,是一类连接软件组件的中间桥梁,以便于软件各部件之间的沟通。例如 Tomcat 是常用的 web 中间件。Mycat 就是当下流行的数据库中间件,除此之外,还有下面这些数据库中间件:
Cobar:属于阿里 B2B 事业群,始于 2008 年,在阿里服役 3 年多,接管 3000+ 个 MySQL 数据库的 schema,集群日处理在线 SQL 请求 50 亿次以上。由于 Cobar 发起人的离职,Cobar 停止维护。
Mycat:是开源社区在阿里 cobar 基础上进行二次开发,解决了 cobar 存在的问题,并且加入了许多新的功能在其中。青出于蓝而胜于蓝。
OneProxy:基于 MySQL 官方的 proxy 思想利用 c 语言进行开发的,OneProxy 是一款商业收费的中间件。舍弃了一些功能,专注在性能和稳定性上。
kingshard:由小团队用 go 语言开发,还需要发展,需要不断完善。
Vitess:是 Youtube 生产在使用,架构很复杂。不支持 MySQL 原生协议,使用需要大量改造成本。
Atlas:是 360 团队基于 mysql proxy 改写,功能还需完善,高并发下不稳定。
MaxScale:是 mariadb(MySQL 原作者维护的一个版本)研发的中间件。
MySQLRoute:是 MySQL 官方 Oracle 公司发布的中间件。
17.1.2、Mycat2 作用
-
读写分离
-
数据分片
垂直拆分(分库)、水平拆分(分表)、垂直+水平拆分(分库分表)
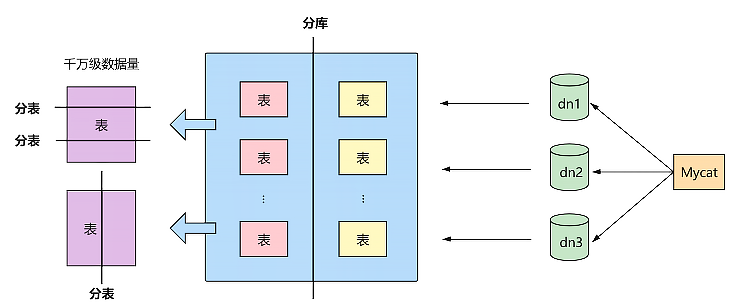
-
多数据源整合
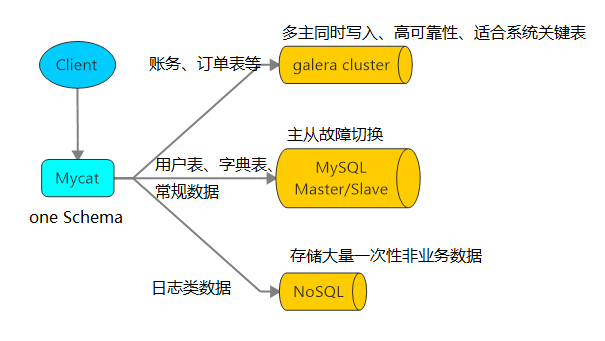
Mycat 支持的数据库:

17.1.3、原理
Mycat2 的原理中最重要的一个动词是 拦截,它拦截了用户发送过来的 SQL 语句,首先对 SQL 语句做了一些特定的分析:如 分片分析、路由分析、读写分离分析、缓存分析 等,然后将此 SQL 发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
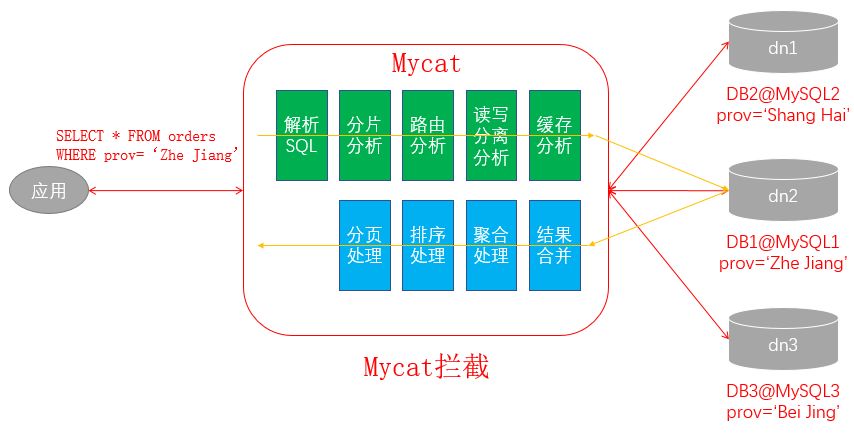
这种方式把数据库的分布式从代码中解耦出来,程序员察觉不出来后台使用 Mycat2 还是 MySQL。
整体过程可以概括为:拦截 --> 分发 --> 响应
17.2、环境准备
- 准备 5 台 CentOS 虚拟机。
- 4 台虚拟机上需要安装好 MySQL(这里用的是 MySQL v8.0.31),1 台安装 mycat2。
说明:前面我们讲过如何克隆一台 CentOS。大家可以在一台 CentOS 上安装好 MySQL,进而通过克隆的方式复制出 1 台包含 MySQL 的虚拟机。
注意:克隆的方式需要修改新克隆出来主机的。
MAC 地址IP 地址hostnameUUID
此外,克隆的方式生成的虚拟机(包含 MySQL Server),则克隆的虚拟机 MySQL Server 的 UUID 相同,必须修改,否则在有些场景会报错。比如:show slave status\G,报如下的错误:
Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have
equal MySQL server UUIDs; these UUIDs must be different for replication to work.修改 MySQL Server 的 UUID 方式:
vim /var/lib/mysql/auto.cnf
systemctl restart mysqld17.3、安装启动
17.3.1、安装
安装 mycat2 之前要安装 java jdk 运行环境,mycat2 是基于 java 1.8 开发的,如下安装:
[root@master1 mycat]# yum install java-1.8.0-openjdk -y先下载一个运行环境框架包:
[root@master1 ~]# wget http://dl.mycat.org.cn/2.0/install-template/mycat2-install-template-1.20.zip然后可以下载 MyCat2 的运行包:
[root@master1 ~]# wget http://dl.mycat.org.cn/2.0/1.21-release/mycat2-1.21-release-jar-with-dependencies-2022-5-9.jar下载下来后,运行框架包解压,将 MyCat2 的运行包移到 mycat/lib 目录下:
[root@master1 ~]# unzip mycat2-install-template-1.20.zip
[root@master1 ~]# mv mycat2-1.21-release-jar-with-dependencies-2022-5-9.jar mycat/lib/把整合好的文件夹拷贝到 linux 下 /usr/local/:
[root@master1 ~]# mv mycat /usr/local/
[root@master1 ~]# ll /usr/local/mycat/
total 8
drwxr-xr-x 2 root root 4096 Mar 5 2021 bin
drwxr-xr-x 9 root root 275 Mar 5 2021 conf
drwxr-xr-x 2 root root 4096 Dec 29 06:12 lib
drwxr-xr-x 2 root root 6 Mar 5 2021 logs将 bin 目录下的可执行文件增加执行权限:
[root@master1 ~]# chmod +x /usr/local/mycat/bin/*
[root@master1 ~]# ll /usr/local/mycat/bin/*
-rwxr-xr-x 1 root root 15666 Mar 5 2021 /usr/local/mycat/bin/mycat
-rwxr-xr-x 1 root root 3916 Mar 5 2021 /usr/local/mycat/bin/mycat.bat
-rwxr-xr-x 1 root root 281540 Mar 5 2021 /usr/local/mycat/bin/wrapper-aix-ppc-32
-rwxr-xr-x 1 root root 319397 Mar 5 2021 /usr/local/mycat/bin/wrapper-aix-ppc-64
-rwxr-xr-x 1 root root 253808 Mar 5 2021 /usr/local/mycat/bin/wrapper-hpux-parisc-64
-rwxr-xr-x 1 root root 140198 Mar 5 2021 /usr/local/mycat/bin/wrapper-linux-ppc-64
-rwxr-xr-x 1 root root 99401 Mar 5 2021 /usr/local/mycat/bin/wrapper-linux-x86-32
-rwxr-xr-x 1 root root 111027 Mar 5 2021 /usr/local/mycat/bin/wrapper-linux-x86-64
-rwxr-xr-x 1 root root 114052 Mar 5 2021 /usr/local/mycat/bin/wrapper-macosx-ppc-32
-rwxr-xr-x 1 root root 233604 Mar 5 2021 /usr/local/mycat/bin/wrapper-macosx-universal-32
-rwxr-xr-x 1 root root 253432 Mar 5 2021 /usr/local/mycat/bin/wrapper-macosx-universal-64
-rwxr-xr-x 1 root root 112536 Mar 5 2021 /usr/local/mycat/bin/wrapper-solaris-sparc-32
-rwxr-xr-x 1 root root 148512 Mar 5 2021 /usr/local/mycat/bin/wrapper-solaris-sparc-64
-rwxr-xr-x 1 root root 110992 Mar 5 2021 /usr/local/mycat/bin/wrapper-solaris-x86-32
-rwxr-xr-x 1 root root 204800 Mar 5 2021 /usr/local/mycat/bin/wrapper-windows-x86-32.exe
-rwxr-xr-x 1 root root 220672 Mar 5 2021 /usr/local/mycat/bin/wrapper-windows-x86-64.exe17.3.2、启动
-
在 mycat 连接的 mysql 数据库里添加用户,用户名为 mycat,密码为 WelC0me168!,赋相应权限,如下:
mysql> CREATE USER 'mycat'@'%' IDENTIFIED BY 'WelC0me168!'; Query OK, 0 rows affected (0.01 sec) --必须要赋的权限mysql8才有的 mysql> GRANT XA_RECOVER_ADMIN ON *.* TO 'root'@'%'; Query OK, 0 rows affected (0.00 sec) --视情况赋权限 mysql> GRANT ALL PRIVILEGES ON *.* TO 'mycat'@'%'; Query OK, 0 rows affected (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec) -
修改 mycat 的 prototype 元数据信息。
这是 MyCat 运行所需要的基本信息。配置文件在 config/datasource/prototypeDs.datasource.json。
主要是通过 url,user,password 三个属性指向一个 MySQL 服务。如果指向的 MySQL 服务无法连接,那么 MyCat2 在启动阶段就会报错。
[root@master1 ~]# cat /usr/local/mycat/conf/datasources/prototypeDs.datasource.json { "dbType":"mysql", "idleTimeout":60000, "initSqls":[], "initSqlsGetConnection":true, "instanceType":"READ_WRITE", "maxCon":1000, "maxConnectTimeout":3000, "maxRetryCount":5, "minCon":1, "name":"prototypeDs", "password":"WelC0me168!", "type":"JDBC", "url":"jdbc:mysql://localhost:3306/mysql?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8", "user":"mycat", "weight":0 } -
验证物理数据库访问情况
Mycat 作为数据库中间件要和物理数据库部署在不同机器上,所以要验证远程访问情况。
[root@master1 ~]# mysql -umycat -pWelC0me168! -h 192.168.95.101 -P 3306 mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 16 Server version: 8.0.31 MySQL Community Server - GPL Copyright (c) 2000, 2022, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>如果拒绝访问,请参考网上的一些资料解决 mysql8.0 的远程访问问题。
-
启动 mycat
[root@master1 mycat]# bin/mycat start Starting mycat2... [root@master1 mycat]# bin/mycat status mycat2 is running (3197). -
登录数据窗口
[root@master1 mycat]# mysql -uroot -P 8066 -p123456 -h127.0.0.1 mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 Server version: 5.7.33-mycat-2.0 MySQL Community Server - GPL Copyright (c) 2000, 2022, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> show databases;
注意:show databases;指令看到的是 MyCat2 服务当中的逻辑库,跟之前 prototypeDs.datasource.json 配置文件中指定的数据库中的 databases 会有不同。
17.4、Mycat2 相关概念
17.4.1、概念描述
-
分库分表
按照一定规则把数据库中的表拆分为多个带有数据库实例,物理库,物理表访问路径的分表。
分库:一个电商项目,分为用户库、订单库等等。
分表:一张订单表数据量超百万,达到 MySQL 单表瓶颈,分到多个数据库中的多张表。
-
逻辑库
数据库代理中的数据库,它可以包含多个逻辑表。
Mycat 里定义的库,在逻辑上存在,物理上在 MySQL 里并不存在。有可能是多个 MySQL 数据库共同组成一个逻辑库。类似多个小孩叠罗汉穿上外套,扮演一个大人。
-
逻辑表
数据库代理中的表,它可以映射代理连接的数据库中的表(物理表)。
Mycat 里定义的表,在逻辑上存在,可以映射真实的 MySQL 数据库的表。可以一对一,也可以一对多。
-
物理库
数据库代理连接的数据库中的库,MySQL 真实的数据库。
-
物理表
数据库代理连接的数据库中的表,MySQL 真实的数据库中的真实数据表。
-
拆分键
即分片键,描述拆分逻辑表的数据规则的字段,比如订单表可以按照归属的用户 id 拆分,用户 id 就是拆分键。
-
物理分表
指已经进行数据拆分的,在数据库上面的物理表,是分片表的一个分区。
多个物理分表里的数据汇总就是逻辑表的全部数据。
-
物理分库
一般指包含多个物理分表的库,参与数据分片的实际数据库。
-
分库
一般指通过多个数据库拆分分片表,每个数据库一个物理分表,物理分库名字相同。
解读:分库是个动作,需要多个数据库参与。就像多个数据库是多个盘子,分库就是把一串数据葡萄,分到各个盘子里,而查询数据时,所有盘子的葡萄又通过 Mycat2 组成了完整的一串葡萄。
-
分片表,水平分片表
按照一定规则把数据拆分成多个分区的表,在分库分表语境下,它属于逻辑表的一种。
-
单表
没有分片,没有数据冗余的表,没有拆分数据,也没有复制数据到别的库的表。
-
全局表,广播表
每个数据库实例都冗余全量数据的逻辑表。它通过表数据冗余,使分片表的分区与该表的数据在同一个数据库实例里,达到 join 运算能够直接在该数据库实例里执行。它的数据一致性一般是通过数据库代理分发 SQL 实现,也有基于集群日志实现。
例如系统中翻译字段的字典表,每个分片表都需要完整的字典数据翻译字段。
-
ER 表
狭义指父子表中的子表,它的分片键指向父表的分片键,而且两表的分片算法相同;广义指具有相同数据分布的一组表。
关联别的表的子表,例如:订单详情表就是订单表的 ER 表。
-
集群
多个数据节点组成的逻辑节点在 mycat2 里,它是把对多个数据源地址视为一个数据源地址(名称),并提供自动故障恢复、转移,即实现高可用,负载均衡的组件。
集群就是高可用、负载均衡的代名词。
-
数据源
连接后端数据库的组件,它是数据库代理中连接后端数据库的客户端。
Mycat 通过数据源连接 MySQL 数据库。
-
原型库(prototype)
原型库是 Mycat2 后面的数据库,比如 mysql 库。
原型库就是存储数据的真实数据库,配置数据源时必须指定原型库。
17.4.2、配置文件
MyCat2 定位是一个数据库中间件,他并不存储数据。MyCat2 所有的功能都可以理解为通过一系列配置文件定制一系列业务规则,通过与其他数据库(目前主要是MySQL)协作,提供具体的业务功能。所以,目前 MyCat2 的所有功能都体现在他的配置文件当中。
我们先来了解一下 MyCat2 的主要配置文件。
[root@master1 mycat]# ll conf/
total 32
drwxr-xr-x 2 root root 36 Jun 28 2021 clusters # 逻辑集群配置
drwxr-xr-x 2 root root 41 Dec 29 07:20 datasources # 数据源配置
-rw-r--r-- 1 root root 3338 Mar 5 2021 dbseq.sql
-rw-r--r-- 1 root root 316 Nov 2 2021 logback.xml
-rw-r--r-- 1 root root 0 Mar 5 2021 mycat.lock
drwxr-xr-x 2 root root 31 Jun 28 2021 schemas # 逻辑库配置
drwxr-xr-x 2 root root 6 Jun 28 2021 sequences
-rw-r--r-- 1 root root 776 Dec 28 2021 server.json
-rw-r--r-- 1 root root 1643 Mar 5 2021 simplelogger.properties
drwxr-xr-x 2 root root 233 Jun 28 2021 sql
drwxr-xr-x 2 root root 6 Jun 28 2021 sqlcaches
-rw-r--r-- 1 root root 49 Mar 5 2021 state.json
drwxr-xr-x 2 root root 28 Dec 29 07:49 users # mycat2用户配置
-rw-r--r-- 1 root root 211 Mar 5 2021 version.txt
-rw-r--r-- 1 root root 4165 Jan 13 2022 wrapper.conf1、用户 users
目录:mycat/conf/users
命名规则:{用户名}.user.json
主要配置内容:
[root@master1 mycat]# cat conf/users/root.user.json
{
"dialect":"mysql",
"ip":null,
"password":"123456",
"transactionType":"xa",
"username":"root"
}主要字段含义:
-
ip:客户端访问 ip,建议为空,填写后会对客户端的 ip 进行限制。
-
username:MyCat2 登录的用户名。
-
password:MyCat2 登录的密码。
-
dialect:数据库类型。目前就 MySQL。
-
transactionType:事务类型。
-
proxy:本地事务,兼容性最好,但是分布式场景事务控制不严格。
-
XA:分布式事务,需要后端数据库能够支持 XA。
# 可以通过语句查询 mysql> select @@transaction_policy; +----------------------+ | @@transaction_policy | +----------------------+ | xa | +----------------------+ 1 row in set (0.01 sec) # 这是在mycat里面,可以通过语句实现切换 # set transaction_policy = 'xa' # set transaction_policy = 'proxy' -
2、数据源 datasource
目录:mycat/conf/datasources
命名规则:{数据源名字}.datasource.json
主要配置内容:
[root@master1 mycat]# cat conf/datasources/prototypeDs.datasource.json
{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ_WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"prototypeDs",
"password":"WelC0me168!",
"type":"JDBC",
"url":"jdbc:mysql://localhost:3306/mysql?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8",
"user":"mycat",
"weight":0
}主要字段含义:
-
dbType:数据库类型 mysql。
-
name:在 MyCat2 中定义的数据源名字。
-
user,password,url:实际数据库的 JDBC 属性。
-
instanceType:配置实例只读还是读写。可选值有 READ_WRITE、READ、WRITE。
-
type:数据源类型,默认 JDBC。
-
weight:负载均衡权重。
-
idleTimeout:空闲连接超时时间。
-
initSqls:初始化sql。
-
initSqlsGetConnection:对于 jdbc 每次获取连接是否都执行 initSqls。
3、集群 clusters
目录:mycat/conf/clusters
命名规则:{集群名字}.cluster.json
主要配置内容:
[root@master1 mycat]# cat conf/clusters/prototype.cluster.json
{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetry":3,
"minSwitchTimeInterval":300,
"slaveThreshold":0
},
"masters":[
"prototypeDs"
],
"maxCon":200,
"name":"prototype",
"readBalanceType":"BALANCE_ALL",
"switchType":"SWITCH"
}主要字段含义:
-
clusterType:集群类型。
- SINGLE_NODE:单一节点;
- MASTER_SLAVE:普通主从;
- 另外针对高可用集群还支持 MHA 和 MGR。
-
readBalanceType:查询负载均衡策略,可选值:
- BALANCE_ALL(默认值):获取集群中所有数据源;
- BALANCE_ALL_READ:获取集群中允许读的数据源;
- BALANCE_READ_WRITE:获取集群中允许读写的数据源,但允许读的数据源优先;
- BALANCE_NONE:获取集群中允许写数据源,即主节点中选择。
-
switchType:切换类型。
- NOT_SWITCH:不进行主从切换;
- SWITCH:进行主从切换。
-
masters:主从集群中的主库名字。从库用 replicas 配置。
4、逻辑库 schema
目录:mycat/conf/schemas
命名规则:{库名}.schema.json
主要配置内容:
[root@master1 mycat]# cat conf/schemas/mysql.schema.json
{
"customTables":{},
"globalTables":{},
"normalProcedures":{},
"normalTables":{},
"schemaName":"wrdb",
"shardingTables":{},
"targetName":"",
"views":{}
}主要字段含义:
- schema:逻辑库名。
- targetName:目的真实数据源或集群。
- normalTables:常规表。如果物理表已经存在或者在每次启动服务时需要加载表定义,就可以写在这里。
17.5、实现读写分离
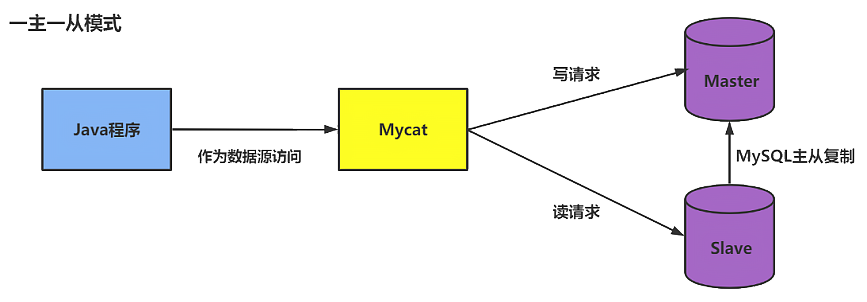
我们通过 Mycat 和 MySQL 的主从复制配合搭建数据库的读写分离,实现 MySQL 的高可用性。我们将搭建:一主一从、双主双从两种读写分离模式。
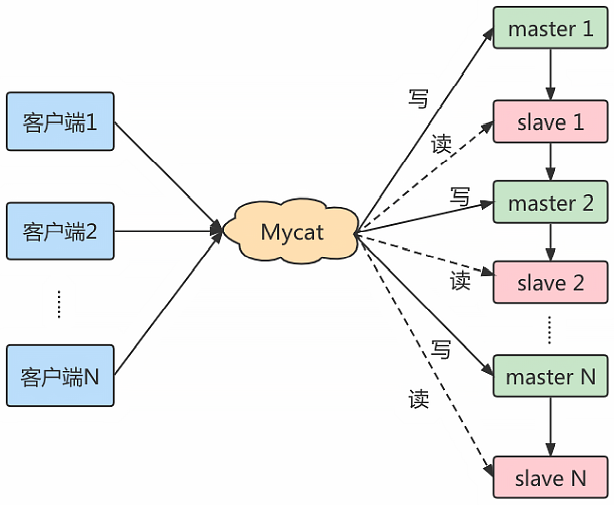
读写分离的基本原理是 MyCat2 将 Update、Delete、Insert 这一类写数据的请求转发到 MySQL 集群中的主节点,然后将 Select 类的读数据的请求转发到 MySQL 集群中的从节点。而 MySQL 的主节点与从节点之间,通常会使用 MySQL 的主从同步机制来进行数据同步,从而保证读请求能够读取到最新的数据结果。
17.5.1、搭建一主一从
一个主机用于处理所有写请求,一台从机负责所有读请求,架构图如下:
| 编号 | 角色 | IP 地址 | 机器名 |
|---|---|---|---|
| 1 | Master1 | 192.168.95.101 | master1 |
| 2 | Slave1 | 192.168.95.201 | slave1 |
搭建过程这里不再赘述,参见第 15 章。
17.5.2、配置 mycat2 一主一从读写分离
17.5.2.1、配置真实数据源
登录 MyCat2 后,可以使用 MyCat2 提供的注解方式配置真实数据源。
# 创建数据源
# 创建dbw写库,指向集群中的master服务
/*+ mycat:createDataSource{"name":"dbW","url":"jdbc:mysql://192.168.95.101:3306/mysql?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true","user":"root", "password":"WelC0me168!" } */;
# 创建dbR读库,指向集群中的slave服务。如果有多个从库,依次继续创建
/*+ mycat:createDataSource{ "name":"dbR","url":"jdbc:mysql://192.168.95.201:3306/mysql?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true","user":"root", "password":"WelC0me168!" } */;
# 查询配置数据源结果
/*+ mycat:showDataSources{} */\G1、真实数据源也就是实际存储数据的数据源,例如之前在 prototypeDs.datasource.json 文件中配置的 prototypeDs 也是一个真实数据源。
2、创建了两个数据库后,进入 MyCat 的部署目录,在 conf/datasource 目录下,可以看到对应的数据库配置文件 dbR.datasource.json 和
dbW.datasource.json。这是 MyCat2 自动创建的配置文件,里面有关于这个数据源的详细配置信息。
17.5.2.2、配置 MySQL 集群
接下来需要在 MyCat2 中配置一个包含真实数据源的 MySQL 集群,通过集群来实现读写分离。
# 更新集群信息
/*! mycat:createCluster{"name":"WRSplitCluster","masters":["dbW"],"replicas":["dbR"]} */;
# 查看集群配置信息
/*+ mycat:showClusters{} */;1、这样就创建一个名为 WRSplitCluster 的集群,masters 指定主库,replicas 指定从库。其中,replicas 从库可以配置多个,表示有多个从库。masters 也可以配置多个,第一个表示主库,后面的表示备用库。
2、配置集群后,MyCat2 会在 conf/cluster 目录下创建对应的集群配置文件,WRSplitCluster.cluster.json。里面包含了关于这个集群的详细配置信息。另外,也可以看到,MyCat2 默认情况下也提供了一个名为 prototype 的集群。
17.5.2.3、配置逻辑库
有了集群后,还需要在 MyCat2 中配置一个逻辑库,指向这个集群。这样,客户端就只需要操作这个逻辑库,由 MyCat2 去完成真实的读写分离逻辑。
-- 1、在mycat2的服务中声明一个逻辑库。
create database wrdb;
-- 2、在mycat2的部署目录下,找到对应的配置文件 conf/schema/wrdb.schema.json。在其中增加targetName:WRSplitCluster属性。指向真实的集群。
{
"customTables":{},
"globalTables":{},
"normalProcedures":{},
"normalTables":{},
"schemaName":"wrdb",
"targetName":"WRSplitCluster",
"shardingTables":{},
"views":{}
}
-- 3、手动修改配置文件之后,需要重启MyCat2服务,让配置文件生效。1、逻辑库即客户端直接操作的库。后续在库中建表,建视图、存储过程等,最终都会体现在对应的 schema.json 中。
2、Mycat2 可以有很多集群,每个集群对应不同的物理数据源和读写逻辑,所以逻辑库文件 conf/schema/xxx.schema.json 的 targetName 属性指向哪个集群变得至关重要,因为客户端只在乎如何操作逻辑库,不关心背后复杂的物理数据库。
重启 mycat2:
[root@master1 mycat]# bin/mycat restart
Stopping mycat2...
Stopped mycat2.
Starting mycat2...注意:如果 mycat2 配置完成后不能重启服务,请检查 mysql 数据源的用户名和密码以及是否可远程连接,特别是 mysql8.0 以后的版本。
17.5.2.4、读写分离测试
这样就完成了 MyCat2 的读写分离配置。接下来在 MySQL 主从集群的基础上测试 MyCat2 的读写分离。
# 在mycat2上操作
mysql> USE wrdb;
mysql> CREATE TABLE t1(id int, name VARCHAR(10));
mysql> insert into t1 values(1,"Darry");
# 因为主从会同步,为了演示效果,手动在从节点插入一条数据
mysql> insert into t1 values(2,"Tom");
# 在mycat2上查询,有Tom的是从节点
mysql> select * from t1;
+------+-------+
| id | name |
+------+-------+
| 1 | Darry |
+------+-------+
1 row in set (0.00 sec)
mysql> select * from t1;
+------+-------+
| id | name |
+------+-------+
| 1 | Darry |
+------+-------+
1 row in set (0.00 sec)
mysql> select * from t1;
+------+-------+
| id | name |
+------+-------+
| 1 | Darry |
| 2 | Tom |
+------+-------+
2 rows in set (0.00 sec)当前使用的集群配置
readBalanceType":"BALANCE_ALL,效果如上所示,可以修改成别的选项继续测试。
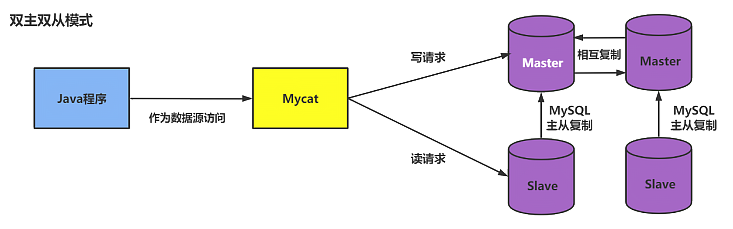
17.5.3、搭建双主双从
一个主机 m1 用于处理所有写请求,它的从机 s1 和另一台主机 m2 还有它的从机 s2 负责所有读请求。当 m1 主机宕机后,m2 主机负责写请求,m1、m2 互为备机。架构图如下:
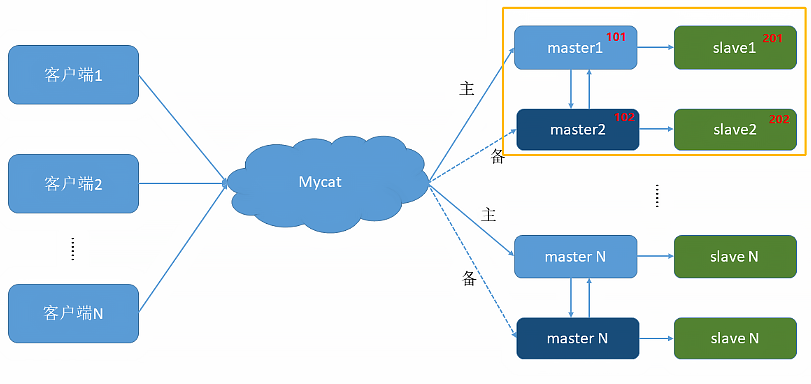
| 编号 | 角色 | IP 地址 | 机器名 |
|---|---|---|---|
| 1 | Master1 | 192.168.95.101 | master1 |
| 2 | Slave1 | 192.168.95.201 | slave1 |
| 3 | Master2 | 192.168.95.102 | master2 |
| 4 | Slave2 | 192.168.95.202 | slave2 |
| 5 | mycat | 192.168.95.88 | guest |
搭建过程这里不再赘述,参见第 15 章。
17.5.4、配置 mycat2 多主多从读写分离
17.5.4.1、配置真实数据源
登录 MyCat2 后,可以使用 MyCat2 提供的注解方式配置真实数据源。注意,这里只是添加数据源,读写分离逻辑在后面的集群配置中体现。
# 创建数据源
# 创建dbW1写库,指向集群中的master1服务
/*+ mycat:createDataSource{"name":"dbW1","url":"jdbc:mysql://192.168.95.101:3306/mysql?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true","user":"root", "password":"WelC0me168!" } */;
# 创建dbW2写库,指向集群中的master2服务
/*+ mycat:createDataSource{"name":"dbW2","url":"jdbc:mysql://192.168.95.102:3306/mysql?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true","user":"root", "password":"WelC0me168!" } */;
# 创建dbR1读库,指向集群中的slave1服务。如果有多个从库,依次继续创建。
/*+ mycat:createDataSource{ "name":"dbR1","url":"jdbc:mysql://192.168.95.201:3306/mysql?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true","user":"root", "password":"WelC0me168!" } */;
# 创建dbR2读库,指向集群中的slave2服务。
/*+ mycat:createDataSource{ "name":"dbR2","url":"jdbc:mysql://192.168.95.202:3306/mysql?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true","user":"root", "password":"WelC0me168!" } */;
# 查询配置数据源结果
/*+ mycat:showDataSources{} */\G17.5.4.2、配置 MySQL 集群
接下来需要在 MyCat2 中配置一个包含真实数据源的 MySQL 集群,通过集群来实现读写分离。
# 更新集群信息
/*! mycat:createCluster{"name":"WRSplitCluster","masters":["dbW1","dbW2"],"replicas":["dbR1","dbR2","dbW2"]} */;
# 查看集群配置信息
/*+ mycat:showClusters{} */;我们看一眼自动生成的集群配置文件,注意我们上面的每一步都是通过注解命令的方式执行的,mycat2 根据这些命令自动生成集群配置文件。如果在生产环境下,想要在已有集群的基础上增加数据源的话,可以手动修改配置文件。
[root@guest mycat]# cat conf/clusters/WRSplitCluster.cluster.json
{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"dbW1",
"dbW2"
],
"maxCon":2000,
"name":"WRSplitCluster",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"dbR1",
"dbR2",
"dbW2"
],
"switchType":"SWITCH"
}17.5.4.3、配置逻辑库
有了集群后,还需要在 MyCat2 中配置一个逻辑库,指向这个集群。这样,客户端就只需要操作这个逻辑库,由 MyCat2 去完成真实的读写分离逻辑。
-- 1、在mycat2的服务中声明一个逻辑库。
create database wrdb;
-- 2、在mycat2的部署目录下,找到对应的配置文件 conf/schema/wrdb.schema.json。在其中增加targetName:WRSplitCluster属性。指向真实的集群。
{
"customTables":{},
"globalTables":{},
"normalProcedures":{},
"normalTables":{},
"schemaName":"wrdb",
"targetName":"WRSplitCluster",
"shardingTables":{},
"views":{}
}
-- 3、手动修改配置文件之后,需要重启MyCat2服务,让配置文件生效。重启 mycat2,重启之前确保所有 mysql 都可以远程登陆:
mysql> use mysql;
mysql> update user set host='%' where user='root';
mysql> flush privileges;
[root@guest mycat]# bin/mycat restart
Stopping mycat2...
Stopped mycat2.
Starting mycat2...重启失败,报错:
Caused by: com.mysql.cj.exceptions.UnableToConnectException: Public Key Retrieval is not allowed解决方法:
# 手动给物理数据源的url加allowPublicKeyRetrieval=true参数,如下所有的数据源都加。
[root@guest mycat]# grep "allowPublicKeyRetrieval=true" conf/datasources/db*
conf/datasources/dbR1.datasource.json: "url":"jdbc:mysql://192.168.95.201:3306/mysql?useJDBCCompliantTimezoneShift=true&useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&allowPublicKeyRetrieval=true",
conf/datasources/dbR2.datasource.json: "url":"jdbc:mysql://192.168.95.202:3306/mysql?useJDBCCompliantTimezoneShift=true&useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&allowPublicKeyRetrieval=true",
conf/datasources/dbW1.datasource.json: "url":"jdbc:mysql://192.168.95.101:3306/mysql?useJDBCCompliantTimezoneShift=true&useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&allowPublicKeyRetrieval=true",
conf/datasources/dbW2.datasource.json: "url":"jdbc:mysql://192.168.95.102:3306/mysql?useJDBCCompliantTimezoneShift=true&useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&allowPublicKeyRetrieval=true",17.5.4.4、读写分离测试
这样就完成了 MyCat2 的读写分离配置。接下来在 MySQL 双主双从集群的基础上测试 MyCat2 的读写分离。
# 在mycat2上操作
mysql> USE wrdb;
Database changed
mysql> CREATE TABLE t1(id int, name VARCHAR(10));
Query OK, 0 rows affected (0.49 sec)
# 因为我们的mysql服务器binlog格式都是ROW格式,所以@@hostname都会变现成master1,主从数据一致
mysql> INSERT INTO t1 VALUES (1, @@hostname);
Query OK, 1 row affected (1.68 sec)
# 下面我们把binlog格式改成STATEMENT,@@hostname不会变现,仅仅记录完整SQL语句,主从数据不一致,
mysql> SET GLOBAL binlog_format='STATEMENT';
!!!换成STATEMENT实验失败经过实验,双主双从与mycat2,binlog_format 只能是 ROW 或 MIXED 格式,STATEMENT 格式主从数据根本就不会复制,数据错乱,主从服务崩溃。
# 手动在双主双从上插入@@hostname,只是为了实验,看到效果而已
mysql> SELECT * FROM t1;
+------+---------+
| id | name |
+------+---------+
| 1 | master2 |
| 1 | master1 |
+------+---------+
2 rows in set (0.02 sec)
mysql> SELECT * FROM t1;
+------+---------+
| id | name |
+------+---------+
| 1 | slave1 |
| 1 | master1 |
| 1 | master2 |
+------+---------+
3 rows in set (0.01 sec)
mysql> SELECT * FROM t1;
+------+---------+
| id | name |
+------+---------+
| 1 | slave2 |
| 1 | master2 |
| 1 | master1 |
+------+---------+
3 rows in set (0.00 sec)当前使用的集群配置
readBalanceType":"BALANCE_ALL,效果如上所示,可以修改成别的选项继续测试。
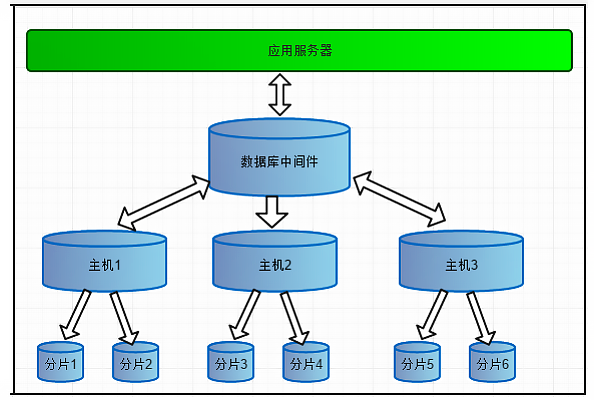
17.6、分库分表
前面无论是一主一从还是双主双从,都演示的是读写分离,根据集群配置的负载算法进行读写。接下来要讲的分库分表是对数据进行切片,分散到多个集群当中去,所以我们实验用两个独立的一主一从集群。
| 编号 | 角色 | IP 地址 | 机器名 |
|---|---|---|---|
| 1 | Master1 | 192.168.95.101 | master1 |
| 2 | Slave1 | 192.168.95.201 | slave1 |
| 3 | Master2 | 192.168.95.102 | master2 |
| 4 | Slave2 | 192.168.95.202 | slave2 |
| 5 | mycat | 192.168.95.88 | guest |
搭建过程这里不再赘述,参见第 15 章。
一个数据库由很多表构成,每个表对应着不同的业务,垂直切分是指按照业务不同将表进行分类,分散到不同的数据库上面,这样也就将数据或者说压力分担到不同的数据库上面,如下图:
17.6.1、如何分库
分库原则:有紧密关联关系的表应该在一个库里,没有关联关系的表可以分到不同的库里。
# 客户表rows:20万
CREATE TABLE customer(
id INT AUTO_INCREMENT,
NAME VARCHAR(200),
PRIMARY KEY(id)
);
# 订单表rows:600万
CREATE TABLE orders(
id INT AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
# 订单详细表rows:600万
CREATE TABLE orders_detail(
id INT AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
);
# 订单状态字典表rows:20
CREATE TABLE dict_order_type(
id INT AUTO_INCREMENT,
order_type VARCHAR(200),
PRIMARY KEY(id)
);以上四个表如何分库?客户表分在一个数据库,另外三张都需要关联查询,分在另外一个数据库。
17.6.2、如何分表
-
选择要拆分的表
MySQL 单表存储数据条数是有瓶颈的,单表达到 1000 万条数据就达到了瓶颈,会影响查询效率,需要进行水平拆分(分表)进行优化。
例如:例子中的 orders、orders_detail 都已经达到 600 万行数据,需要进行分表优化。
-
分表字段
以 orders 表为例,可以根据不同字段进行分表。
编号 分表字段 效果 1 id(主键、或创建时间) 查询订单注重时效,历史订单被查询的次数少,如此分片会造成一个节点访问多,一个访问少,不平均。 2 customer_id(客户 id) 根据客户 id 去分,两个节点访问平均,一个客户的所有订单都在同一个节点。
17.6.3、实现分库分表
Mycat2 的一大优势就是可以在终端直接创建数据源、集群、库表,并在创建时指定分库、分表。与 1.6 版本比大大简化了分库分表的操作。
17.6.3.1、配置数据源
很多网上的资料都没有加 url 参数,我实验时经常遇到各种参数问题,所以我在做实验的时候,加上了这些参数,避免报错:
# 第一个写库
/*+ mycat:createDataSource{"name":"dw0","url":"jdbc:mysql://192.168.95.101:3306/mysql?useJDBCCompliantTimezoneShift=true&useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&allowPublicKeyRetrieval=true","user":"root","password":"WelC0me168!"} */;
# 第一个读库
/*+ mycat:createDataSource{"name":"dr0","url":"jdbc:mysql://192.168.95.201:3306/mysql?useJDBCCompliantTimezoneShift=true&useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&allowPublicKeyRetrieval=true","user":"root","password":"WelC0me168!"} */;
# 第二个写库
/*+ mycat:createDataSource{"name":"dw1","url":"jdbc:mysql://192.168.95.102:3306/mysql?useJDBCCompliantTimezoneShift=true&useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&allowPublicKeyRetrieval=true","user":"root","password":"WelC0me168!"} */;
# 第二个读库
/*+ mycat:createDataSource{"name":"dr1","url":"jdbc:mysql://192.168.95.202:3306/mysql?useJDBCCompliantTimezoneShift=true&useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&allowPublicKeyRetrieval=true","user":"root","password":"WelC0me168!"} */;生成下面 4 个数据源文件:
[root@guest mycat]# ll conf/datasources/d*
-rw-r--r-- 1 root root 519 Dec 31 04:09 conf/datasources/dr0.datasource.json
-rw-r--r-- 1 root root 519 Dec 31 04:09 conf/datasources/dr1.datasource.json
-rw-r--r-- 1 root root 519 Dec 31 04:08 conf/datasources/dw0.datasource.json
-rw-r--r-- 1 root root 519 Dec 31 04:09 conf/datasources/dw1.datasource.json17.6.3.2、配置集群
# 在mycat2终端输入
# 配置第一组集群
/*! mycat:createCluster{"name":"c0","masters":["dw0"],"replicas":["dr0"]}*/;
# 配置第二组集群
/*! mycat:createCluster{"name":"c1","masters":["dw1"],"replicas":["dr1"]}*/;生成下面 2 个集群文件:
[root@guest mycat]# ll conf/clusters/c*
-rw-r--r-- 1 root root 312 Dec 31 04:23 conf/clusters/c0.cluster.json
-rw-r--r-- 1 root root 312 Dec 31 04:23 conf/clusters/c1.cluster.json这里集群名 c0,c1 是 MyCat2 默认支持的分片集群名字。不建议修改集群名字。按照使用习惯,接下来要配置逻辑库,然后逻辑库文件 xxx.schema.json 中指定目标集群。但是 mycat2 为了简化配置,在实现分库分表时,直接创建逻辑库和表的时候,指定规则,最终逻辑库文件会自动找到 c0、c1、...... 集群进行配置。
17.6.3.3、配置全局表
全局表表示在所有数据分片上都相同的表。比如字典表。
# 添加数据库db1
CREATE DATABASE db1;
# 在建表语句中加上关键字 BROADCAST(广播,即为全局表)
CREATE TABLE db1.`travelrecord` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_id` varchar(100) DEFAULT NULL,
`traveldate` date DEFAULT NULL,
`fee` decimal(10,0) DEFAULT NULL,
`days` int DEFAULT NULL,
`blob` longblob,
PRIMARY KEY (`id`),
KEY `id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 BROADCAST;配置完成后的全局表会写入到 mycat/conf/schemas/db1.schema.json 文件中。这样下次启动服务时就能够初始化表结构。
[root@guest mycat]# cat conf/schemas/db1.schema.json
{
"customTables":{},
"globalTables":{
"travelrecord":{
"broadcast":[
{
"targetName":"c0"
},
{
"targetName":"c1"
}
],
"createTableSQL":"CREATE TABLE db1.`travelrecord` (\n\t`id` bigint NOT NULL AUTO_INCREMENT,\n\t`user_id` varchar(100) DEFAULT NULL,\n\t`traveldate` date DEFAULT NULL,\n\t`fee` decimal(10, 0) DEFAULT NULL,\n\t`days` int DEFAULT NULL,\n\t`blob` longblob,\n\tPRIMARY KEY (`id`),\n\tKEY `id` (`id`)\n) BROADCAST ENGINE = InnoDB CHARSET = utf8"
}
},
"normalProcedures":{},
"normalTables":{},
"schemaName":"db1",
"shardingTables":{},
"views":{}
}然后可以插入几条数据进行测试:
INSERT INTO db1.`travelrecord` VALUES (1, "202212310001", CURDATE(),10,10,'ABC');
INSERT INTO db1.`travelrecord` VALUES (2, "202212310002", CURDATE(),10,10,'ABC');
INSERT INTO db1.`travelrecord` VALUES (3, "202212310003", CURDATE(),10,10,'ABC');
INSERT INTO db1.`travelrecord` VALUES (4, "202212310004", CURDATE(),10,10,'ABC');
INSERT INTO db1.`travelrecord` VALUES (5, "202212310005", CURDATE(),10,10,'ABC');
INSERT INTO db1.`travelrecord` VALUES (6, "202212310006", CURDATE(),10,10,'ABC');经测试,2 套一主一从集群中,每个 mysql 服务都有 db1.travelrecord 表,并且有完整的 6 条测试数据。
17.6.3.4、创建分片表(分库分表)
分片表表示逻辑表中的数据会分散保存到多个数据分片中。
# 在 Mycat 终端直接运行建表语句进行数据分片。
# 数据库分片规则,表分片规则,以及各分多少片。
# 核心就是后面的分片规则。 dbpartition表示分库规则,tbpartition表示分表规则。而mod_hash表示按照customer_id字段取模进行分片。
# 意思是切2份到两个数据库集群,每个数据库集群切1份表(当然也可以切成多张表)
CREATE TABLE db1.orders(
id BIGINT NOT NULL AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id),
KEY `id` (`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8 dbpartition BY mod_hash(customer_id) tbpartition BY mod_hash(customer_id) tbpartitions 1 dbpartitions 2;接下来可以往测试表中插入部分测试数据进行验证。
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (1,101,100,100100);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (2,101,100,100300);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (3,101,101,120000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (4,101,101,103000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (5,102,101,100400);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (6,102,100,100020);
mysql> SELECT * FROM orders;
+----+------------+-------------+-----------+
| id | order_type | customer_id | amount |
+----+------------+-------------+-----------+
| 1 | 101 | 100 | 100100.00 |
| 2 | 101 | 100 | 100300.00 |
| 6 | 102 | 100 | 100020.00 |
| 3 | 101 | 101 | 120000.00 |
| 4 | 101 | 101 | 103000.00 |
| 5 | 102 | 101 | 100400.00 |
+----+------------+-------------+-----------+
6 rows in set (0.09 sec)此时,可以看一下自动生成的 schema 信息:
[root@guest mycat]# cat conf/schemas/db1.schema.json
{
"customTables":{},
"globalTables":{
"travelrecord":{
"broadcast":[
{
"targetName":"c0"
},
{
"targetName":"c1"
}
],
"createTableSQL":"CREATE TABLE db1.`travelrecord` (\n\t`id` bigint NOT NULL AUTO_INCREMENT,\n\t`user_id` varchar(100) DEFAULT NULL,\n\t`traveldate` date DEFAULT NULL,\n\t`fee` decimal(10, 0) DEFAULT NULL,\n\t`days` int DEFAULT NULL,\n\t`blob` longblob,\n\tPRIMARY KEY (`id`),\n\tKEY `id` (`id`)\n) BROADCAST ENGINE = InnoDB CHARSET = utf8"
}
},
"normalProcedures":{},
"normalTables":{},
"schemaName":"db1",
"shardingTables":{
"orders":{
"createTableSQL":"CREATE TABLE db1.orders (\n\tid BIGINT NOT NULL AUTO_INCREMENT,\n\torder_type INT,\n\tcustomer_id INT,\n\tamount DECIMAL(10, 2),\n\tPRIMARY KEY (id),\n\tKEY `id` (`id`)\n) ENGINE = INNODB CHARSET = utf8\nDBPARTITION BY mod_hash(customer_id) DBPARTITIONS 2\nTBPARTITION BY mod_hash(customer_id) TBPARTITIONS 1",
"function":{
"properties":{
"dbNum":"2",
"mappingFormat":"c${targetIndex}/db1_${dbIndex}/orders_${index}",
"tableNum":"1",
"tableMethod":"mod_hash(customer_id)",
"storeNum":2,
"dbMethod":"mod_hash(customer_id)"
}
},
"shardingIndexTables":{}
}
},
"views":{}
}最后查看一下切分的结果:
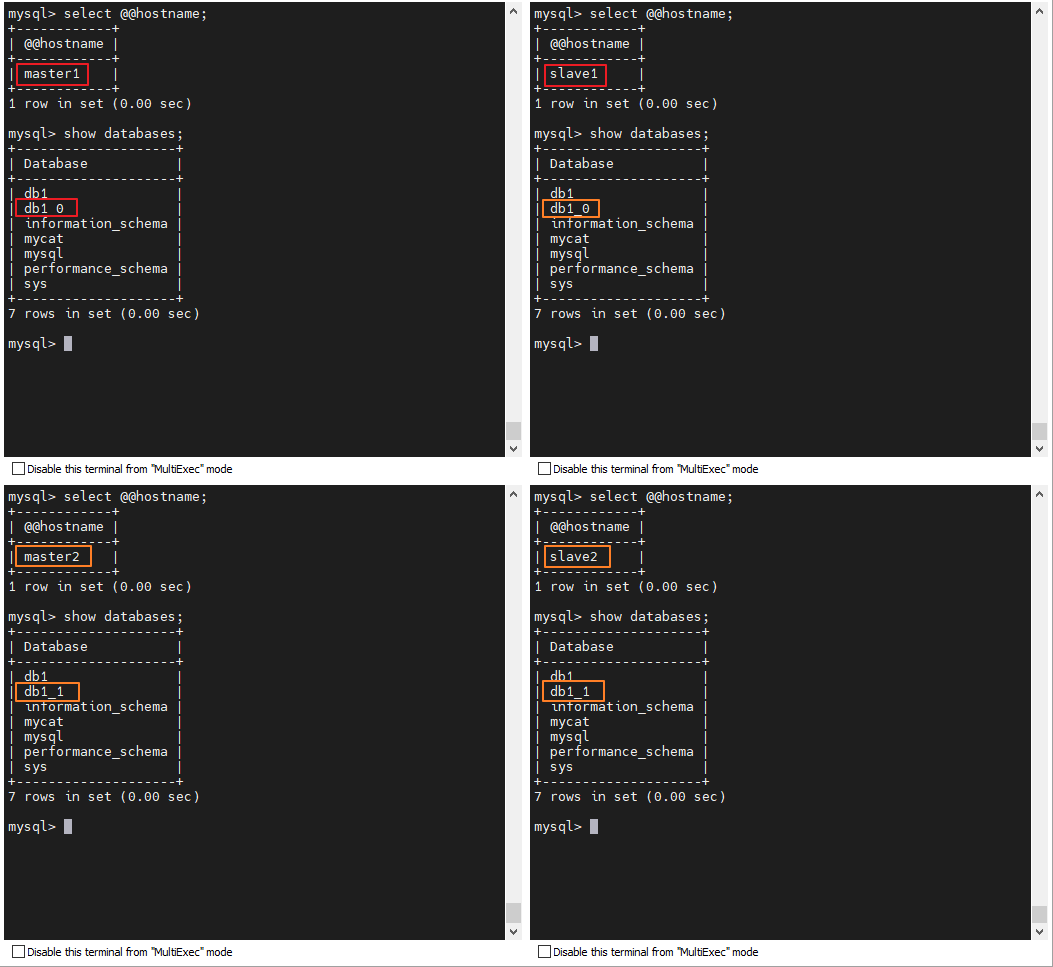
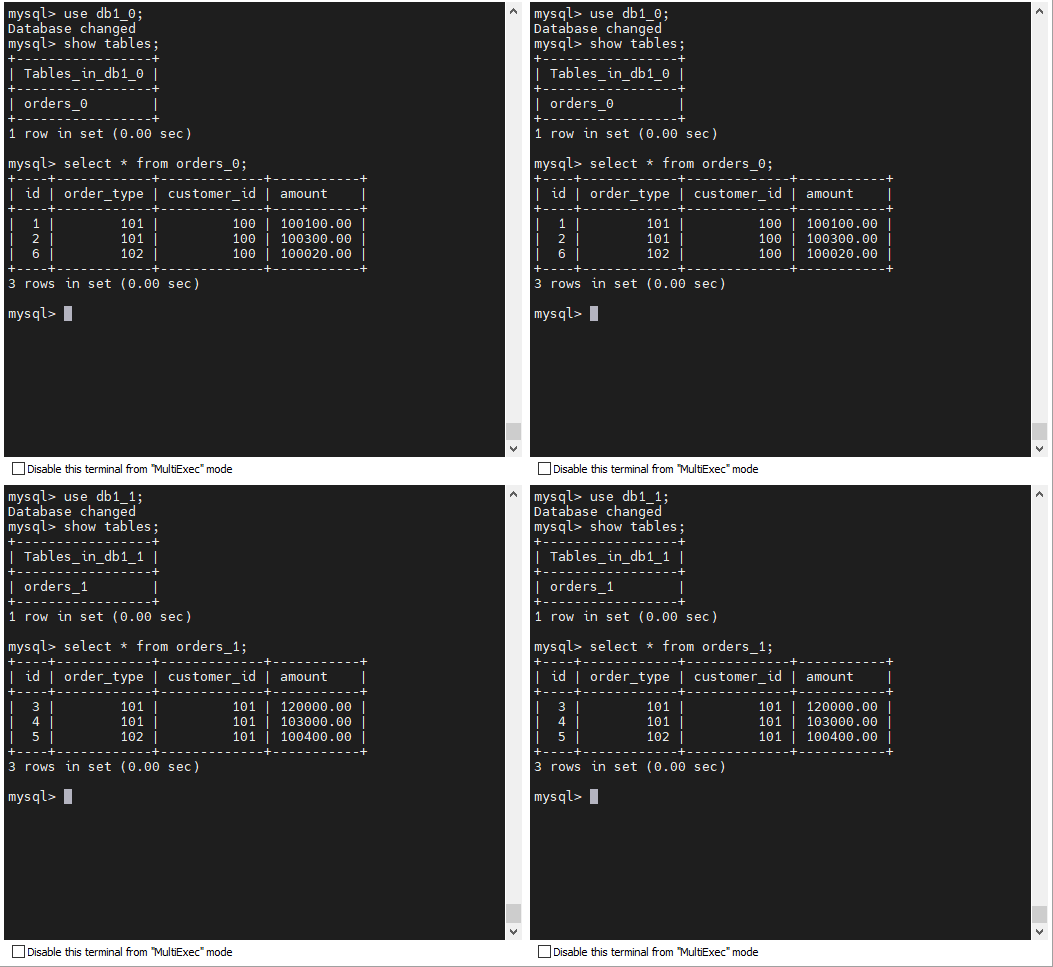
17.6.3.5、创建 ER 表
关联表也称为绑定表或者 ER 表。表示数据逻辑上有关联性的两个或多个表,例如订单和订单详情表。对于关联表,通常希望他们能够有相同的分片规则,这样在进行关联查询时,能够快速定位到同一个数据分片中。
# 在 Mycat 终端直接运行建表语句进行数据分片
CREATE TABLE orders_detail(
id BIGINT NOT NULL AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
)ENGINE=INNODB DEFAULT CHARSET=utf8 dbpartition BY mod_hash(order_id) tbpartition BY mod_hash(order_id) tbpartitions 1 dbpartitions 2;
INSERT INTO orders_detail(id,detail,order_id) VALUES(1,'detail1',1);
INSERT INTO orders_detail(id,detail,order_id) VALUES(2,'detail1',2);
INSERT INTO orders_detail(id,detail,order_id) VALUES(3,'detail1',3);
INSERT INTO orders_detail(id,detail,order_id) VALUES(4,'detail1',4);
INSERT INTO orders_detail(id,detail,order_id) VALUES(5,'detail1',5);
INSERT INTO orders_detail(id,detail,order_id) VALUES(6,'detail1',6);对比一下数据,会发现由于我们分片字段不同,导致 ER 分片表条目不对应:
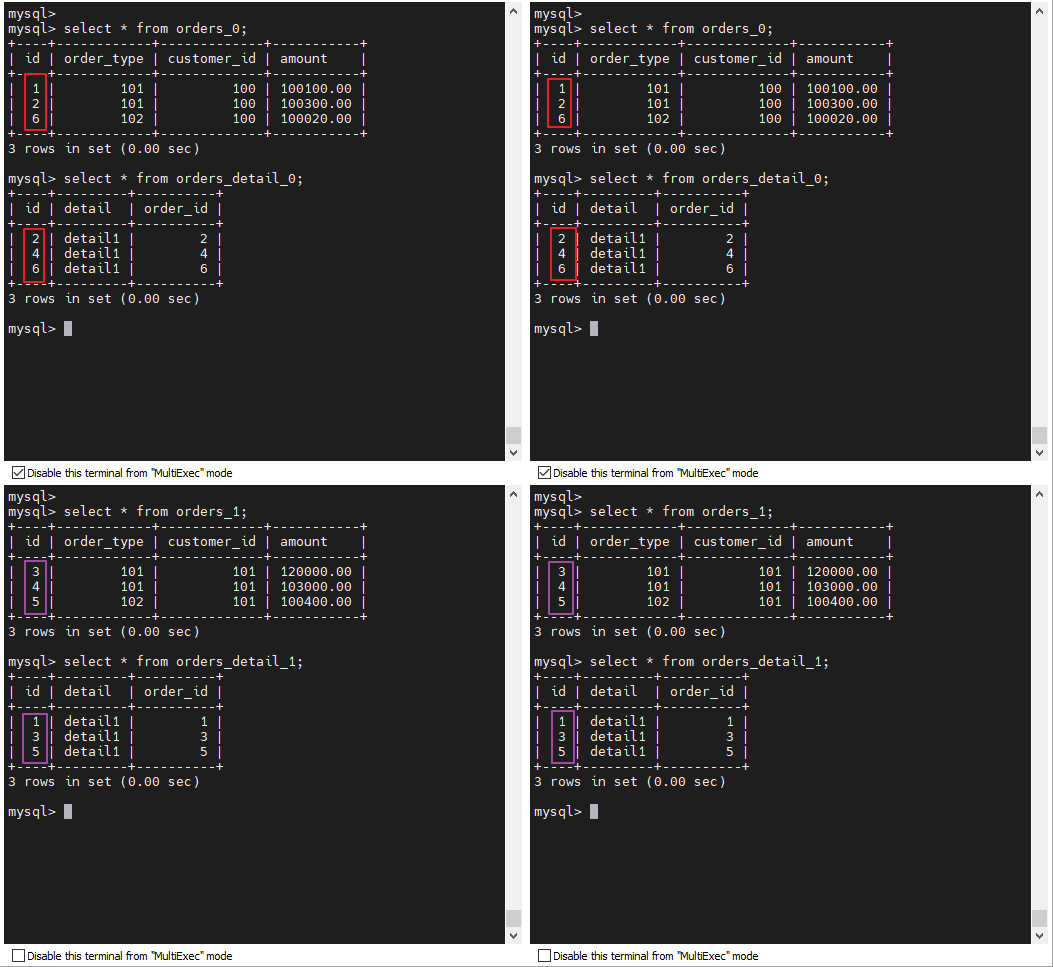
上述两表具有相同的分片算法,但是分片字段不相同,mycat2 在涉及这两个表的 join 分片字段等价关系的时候可以完成 join 的下推。mycat2 无需指定 ER 表,是自动识别的,具体看分片算法的接口。
查看配置的表是否具有 ER 关系,使用:
mysql> /*+ mycat:showErGroup{}*/;
+---------+------------+---------------+
| groupId | schemaName | tableName |
+---------+------------+---------------+
| 0 | db1 | orders |
| 0 | db1 | orders_detail |
+---------+------------+---------------+
2 rows in set (0.00 sec)group_id 表示相同的组,该组中的表具有相同的存储分布,ER 关系暂时不检查分区的目标是否相同,仅使用分片算法判断是否满足 ER 关系。
mysql> SELECT * FROM orders o INNER JOIN orders_detail od ON od.order_id=o.id;
+----+------------+-------------+-----------+-----+---------+----------+
| id | order_type | customer_id | amount | id0 | detail | order_id |
+----+------------+-------------+-----------+-----+---------+----------+
| 1 | 101 | 100 | 100100.00 | 1 | detail1 | 1 |
| 2 | 101 | 100 | 100300.00 | 2 | detail1 | 2 |
| 3 | 101 | 101 | 120000.00 | 3 | detail1 | 3 |
| 4 | 101 | 101 | 103000.00 | 4 | detail1 | 4 |
| 5 | 102 | 101 | 100400.00 | 5 | detail1 | 5 |
| 6 | 102 | 100 | 100020.00 | 6 | detail1 | 6 |
+----+------------+-------------+-----------+-----+---------+----------+
6 rows in set (0.08 sec)17.6.4、小结
学到这里,基本上算是入门了 mycat2 中间件,应对大型的数据库架构设计奠定了一个很好的基础,不过,数据库的性能调优,分库分表都是一个很专业的话题,DBA 的修炼也不是一朝一夕,真到了分库分表的时候,最好多参考官方的一些示例说明,虽然官方文档相当杂乱,但也好过自己手无寸铁。