
第 12 章 锁
12.1、概述
锁是计算机协调多个进程或线程 并发访问某一资源 的机制。在程序开发中会存在多线程同步的问题,当多个线程并发访问某个数据的时候,尤其是针对一些敏感的数据(比如订单、金额等),我们就需要保证这个数据在任何时刻 最多只有一个线程 在访问,保证数据的 完整性 和 一致性。
在开发过程中加锁是为了保证数据的一致性,这个思想在数据库领域中同样很重要。
在数据库中,除传统的计算资源(如 CPU、RAM、I/O 等)的争用以外,数据也是一种供许多用户共享的资源。为保证数据的一致性,需要对 并发操作进行控制,因此产生了 锁。同时 锁机制 也为实现 MySQL 的各个隔离级别提供了保证。
锁冲突 也是影响数据库 并发访问性能 的一个重要因素。所以锁对数据库而言显得尤其重要,也更加复杂。
12.2、MySQL 并发事务访问相同记录
并发事务访问相同记录的情况大致可以划分为 3 种,读-读,读-写,写-写。
12.2.1、读-读情况
读-读 情况,即并发事务相继 读取相同的记录。读取操作本身不会对记录有任何影响,并不会引起什么问题,所以允许这种情况的发生。
12.2.2、写-写情况
写-写 情况,即并发事务相继对相同的记录做出改动。
在这种情况下会发生 脏写 的问题,任何一种隔离级别都不允许这种问题的发生。所以在多个未提交事务相继对一条记录做改动时,需要让它们 排队执行,这个排队的过程其实是通过 锁 来实现的。
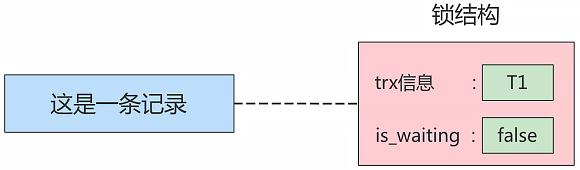
这个所谓的锁其实是一个内存中的结构,在事务执行前本来是没有锁的,也就是说一开始是没有锁结构和记录进行关联的,如图所示:

当一个事务想对这条记录做改动时,首先会看看内存中有没有与这条记录关联的 锁结构,当没有的时候就会在内存中生成一个 锁结构 与之关联。比如,事务 T1 要对这条记录做改动,就需要生成一个 锁结构 与之关联:
在 锁结构 里有很多信息,为了简化理解,只把两个比较重要的属性拿了出来:
trx信息:代表这个锁结构是哪个事务生成的。is_waiting:代表当前事务是否在等待。
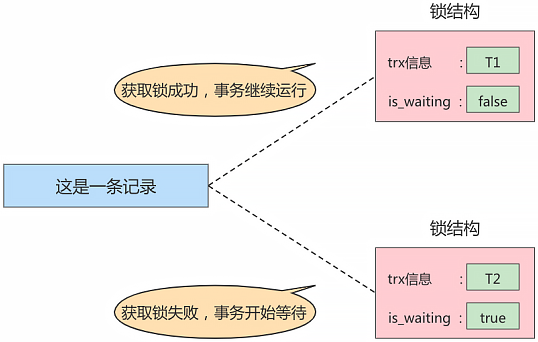
在事务 T1 改动了这条记录后,就生成了一个 锁结构 与该记录关联,因为之前没有别的事务为这条记录加锁,所以 is_waiting 属性就是 false,我们把这个场景就称之为 获取锁成功,或者 加锁成功,然后就可以继续执行操作了。
在事务 T1 提交之前,另一个事务 T2 也想对该记录做改动,那么先看看有没有 锁结构 与这条记录关联,发现有一个 锁结构 与之关联后,然后也生成了一个锁结构与这条记录关联,不过锁结构的 is_waiting 属性值为 true,表示当前事务需要等待,我们把这个场景称之为 获取锁失败,或者 加锁失败,图示:
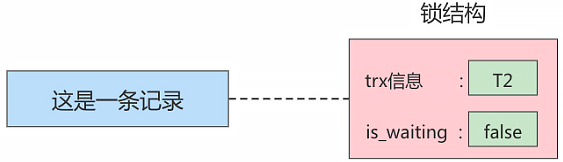
在事务 T1 提交之后,就会把该事务生成的 锁结构释放 掉,然后看看还有没有别的事务在等待获取锁,发现了事务 T2 还在等待获取锁,所以把事务 T2 对应的锁结构的 is_waiting 属性设置为 false,然后把该事务对应的线程唤醒,让它继续执行,此时事务 T2 就算获取到锁了。效果就是这样。
小结几种说法:
-
不加锁
意思就是不需要在内存中生成对应的
锁结构,可以直接执行操作。 -
获取锁成功,或者加锁成功
意思就是在内存中生成了对应的
锁结构,而且锁结构的is_waiting属性为false,也就是事务可以继续执行操作。 -
获取锁失败,或者加锁失败,或者没有获取到锁
意思就是在内存中生成了对应的
锁结构,不过锁结构的is_waiting属性为true,也就是事务需要等待,不可以继续执行操作。
12.2.3、读-写或写-读情况
读-写 或 写-读,即一个事务进行读取操作,另一个进行改动操作。这种情况下可能发生 脏读、不可重复读、幻读 的问题。
各个数据库厂商对 SQL标准 的支持都可能不一样。比如 MySQL 在 REPEATABLE READ 隔离级别上就已经解决了 幻读 问题。
12.2.4、并发问题的解决方案
怎么解决 脏读、不可重复读、幻读 这些问题呢?其实有两种可选的解决方案:
方案一:读操作利用多版本并发控制( MVCC,下章讲解),写操作进行 加锁。
所谓的 MVCC,就是生成一个 ReadView,通过 ReadView 找到符合条件的记录版本(历史版本由 undo 日志构建)。
查询语句只能 读 到在生成 ReadView 之前 已提交事务所做的更改,在生成 ReadView 之前未提交的事务或者之后才开启的事务所做的更改是看不到的。而 写操作 肯定针对的是 最新版本的记录,读记录的历史版本和改动记录的最新版本本身并不冲突,也就是采用 MVCC 时,读-写 操作并不冲突。
普通的 SELECT 语句在 READ COMMITTED 和 REPEATABLE READ 隔离级别下会使用到 MVCC 读取记录。
- 在
READ COMMITTED隔离级别下,一个事务在执行过程中每次执行 SELECT 操作时都会生成一个 ReadView,ReadView 的存在本身就保证了事务不可以读取到未提交的事务所做的更改,也就是避免了脏读现象;- 在
REPEATABLE READ隔离级别下,一个事务在执行过程中只有第一次执行SELECT操作才会生成一个 ReadView,之后的 SELECT 操作都复用这个 ReadView,这样也就避免了不可重复读和幻读的问题。
方案二:读、写操作都采用 加锁 的方式。
如果我们的一些业务场景不允许读取记录的旧版本,而是每次都必须去 读取记录的新版本。比如,在银行存款的事务中,你需要先把账户的余额读出来,然后将其加上本次存款的数额,最后再写到数据库中。
在将账户余额读取出来后,就不想让别的事务再访问该余额,直到本次存款事务执行完成,其他事务才可以访问账户的余额。
这样在读取记录的时候就需要对其进行 加锁 操作,这样也就意味着 读 操作和 写 操作也像 写-写 操作那样 排队 执行。
脏读 的产生是因为当前事务读取了另一个未提交事务写的一条记录,如果另一个事务在写记录的时候就给这条记录加锁,那么当前事务就无法继续读取该记录了,所以也就不会有脏读问题的产生了。
不可重复读 的产生是因为当前事务先读取一条记录,另外一个事务对该记录做了改动并提交之后,当前事务再次读取时会获得不同的值,如果在当前事务读取该记录时就给记录加锁,那么另一个事务就无法修改该记录,自然也不会发生不可重复读了。
幻读 问题的产生是因为当前事务读取了一个范围的记录,然后另外的事务向该范围内插入了新记录,当前事务再次读取该范围的记录时发现了新插入的新记录。采用加锁的方式解决幻读问题就有一些麻烦,因为当前事务在第一次读取记录时幻影记录并不存在,所以读取的时候没法给不存在的记录加锁。
12.2.5、小结
- 采用
MVCC方式的话,读-写操作彼此并不冲突,性能更高。 - 采用
加锁方式的话,读-写操作彼此需要排队执行,影响性能。
一般情况下我们当然愿意采用 MVCC 来解决 读-写 操作并发执行的问题,但是业务在某些特殊情况下,要求必须采用 加锁 的方式执行。下面就讲解下 MySQL 中不同类别的锁。
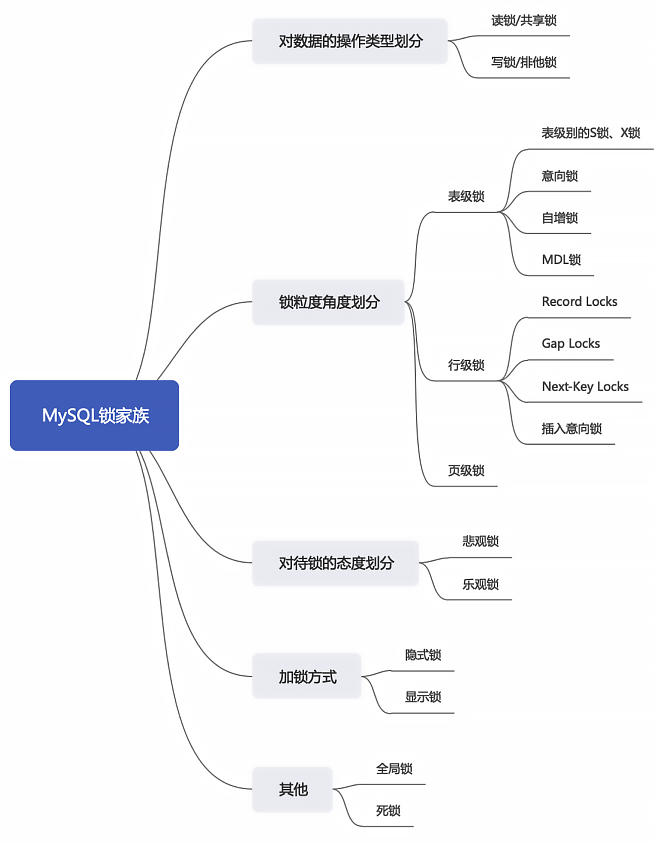
12.3、锁的不同角度分类
锁的分类图,如下:
12.3.1、读锁、写锁
从数据操作的类型划分:读锁、写锁。
对于数据库中并发事务的 读-读 情况并不会引起什么问题。对于 写-写、读-写 或 写-读 这些情况可能会引起一些问题,需要使用 MVCC 或者 加锁 的方式来解决它们。
在使用 加锁 的方式解决问题时,由于既要允许 读-读 情况不受影响,又要使 写-写、读-写 或 写-读 情况中的操作 相互阻塞,所以 MySQL 实现一个由两种类型的锁组成的锁系统来解决。
这两种类型的锁通常被称为 共享锁(Shared Lock, S Lock) 和 排他锁(Exclusive Lock, X Lock),也叫 读锁(readlock) 和 写锁(write lock)。
读锁:也称为共享锁、英文用 S 表示。针对同一份数据,多个事务的读操作可以同时进行而不会互相影响,相互不阻塞的。写锁:也称为排他锁、英文用 X 表示。当前写操作没有完成前,它会阻断其他写锁和读锁。这样就能确保在给定的时间里,只有一个事务能执行写入,并防止其他用户读取正在写入的同一资源。
需要注意的是对于 InnoDB 引擎来说,读锁和写锁可以加在表上,也可以加在行上。
举例(行级读写锁):如果一个事务 T1 已经获得了某个行 r 的读锁,那么此时另外一个事务 T2 是可以去获得这个行 r 的读锁的,因为读取操作并没有改变行 r 的数据;但是,如果某个事务 T3 想获得行 r 的写锁,则它必须等待事务 T1、T2 释放掉行 r 上的读锁才行。
总结:这里的兼容是指对同一张表或记录的锁的兼容性情况。
| X 锁 | S 锁 | |
|---|---|---|
| X 锁 | 不兼容 | 不兼容 |
| S 锁 | 不兼容 | 兼容 |
12.3.1.1、锁定读
在采用加锁方式解决 脏读、不可重复读、幻读 这些问题时,读取一条记录时需要获取该记录的 S锁,其实是不严谨的,有时候需要在读取记录时就获取记录的 X锁,来禁止别的事务读写该记录,为此 MySQL 提出了两种比较特殊的 SELECT 语句格式:
-
对读取的记录加
S锁:SELECT ... LOCK IN SHARE MODE; # 或 SELECT ... FOR SHARE; #(8.0新增语法)在普通的 SELECT 语句后加
LOCK IN SHARE MODE,如果当前事务执行了该语句,那么它会为读取到的记录加S锁,这样允许别的事务继续获取这些记录的S锁(比方说别的事务也使用 SELECT ... LOCK IN SHARE MODE 语句来读取这些记录),但是不能获取这些记录的X锁(比如使用 SELECT ... FOR UPDATE 语句来读取这些记录,或者直接修改这些记录)。如果别的事务想要获取这些记录的
X锁,那么它们会阻塞,直到当前事务提交之后将这些记录上的S锁释放掉。 -
对读取的记录加
X锁:SELECT ... FOR UPDATE;在普通的 SELECT 语句后加
FOR UPDATE,如果当前事务执行了该语句,那么它会为读取到的记录加X锁,这样既不允许别的事务获取这些记录的S锁(比方说别的事务使用 SELECT ... LOCK IN SHARE MODE 语句来读取这些记录),也不允许获取这些记录的X锁(比如使用 SELECT ... FOR UPDATE 语句来读取这些记录,或者直接修改这些记录)。如果别的事务想要获取这些记录的
S锁或者X锁,那么它们会阻塞,直到当前事务提交之后将这些记录上的X锁释放掉。
MySQL8.0 新特性:
在 5.7 及之前的版本,SELECT ... FOR UPDATE,如果获取不到锁,会一直等待,直到 innodb_lock_wait_timeout 超时。在 8.0 版本中,SELECT ... FOR UPDATE,SELECT ... FOR SHARE 添加 NOWAIT、SKIP LOCKED 语法,跳过锁等待,或者跳过锁定。
- 通过添加 NOWAIT、SKIP LOCKED 语法,能够立即返回。如果查询的行已经加锁:
- 那么 NOWAIT 会立即报错返回。
- 而 SKIP LOCKED 也会立即返回,只是返回的结果中不包含被锁定的行。
# session1:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from salaries where emp_no=10002 for update;
+--------+--------+------------+------------+
| emp_no | salary | from_date | to_date |
+--------+--------+------------+------------+
| 10002 | 65828 | 1996-08-03 | 1997-08-03 |
| 10002 | 65909 | 1997-08-03 | 1998-08-03 |
| 10002 | 67534 | 1998-08-03 | 1999-08-03 |
| 10002 | 69366 | 1999-08-03 | 2000-08-02 |
| 10002 | 71963 | 2000-08-02 | 2001-08-02 |
| 10002 | 72527 | 2001-08-02 | 9999-01-01 |
+--------+--------+------------+------------+
6 rows in set (0.00 sec)
# session2:
mysql> select * from salaries where emp_no=10002 for update nowait;
ERROR 3572 (HY000): Statement aborted because lock(s) could not be acquired immediately and NOWAIT is set.
mysql>
mysql> select * from salaries where emp_no=10002 for update skip locked;
Empty set (0.00 sec)12.3.1.2、写操作
平常所用到的写操作无非是 DELETE、UPDATE、INSERT 这三种:
-
DELETE:对一条记录做 DELETE 操作的过程其实是先在B+树中定位到这条记录的位置,然后获取这条记录的X锁,再执行delete mark操作。我们也可以把这个待删除记录在 B+ 树中定位的过程看成是一个获取X锁的锁定读。 -
UPDATE:在对一条记录做 UPDATE 操作时分为三种情况:- 情况 1:未修改该记录的键值,并且被更新的列占用的存储空间在修改前后未发生变化。
先在
B+树中定位到这条记录的位置,然后再获取一下记录的X锁,最后在原记录的位置进行修改操作。我们也可以把这个待修改记录在 B+ 树中定位的过程看成是一个获取X锁的锁定读。- 情况 2:未修改该记录的键值,并且至少有一个被更新的列占用的存储空间在修改前后发生变化。
先在 B+ 树中定位到这条记录的位置,然后获取一下记录的
X锁,将该记录彻底删除掉(就是把记录彻底移入垃圾链表),最后再插入一条新记录。这个定位待修改记录在 B+ 树中位置的过程看成是一个获取X锁的锁定读,新插入的记录由INSERT操作提供的隐式锁进行保护。- 情况 3:修改了该记录的键值,则相当于在原记录上做
DELETE操作之后再来一次INSERT操作,加锁操作就需要按照DELETE和INSERT的规则进行了。
-
INSERT:一般情况下,新插入一条记录的操作并不加锁,通过一种称之为
隐式锁的结构来保护这条新插入的记录在本事务提交前不被别的事务访问。
12.3.2、表级锁、页级锁、行锁
从数据操作的粒度划分:表级锁、页级锁、行锁。
为了尽可能提高数据库的并发度,每次锁定的数据范围越小越好。理论上每次只锁定当前操作的数据会使得并发度最大,但是管理锁是很耗资源的事情(涉及获取、检查、释放锁等动作)。
因此数据库系统需要在 高并发响应 和 系统性能 两方面进行平衡,这样就产生了 锁粒度(Lock granularity)的概念。
对一条记录加锁影响的也只是这条记录而已,我们就说这个锁的粒度比较细;其实一个事务也可以在表级别进行加锁,自然就被称之为 表级锁 或者 表锁,对一个表加锁影响整个表中的记录,我们就说这个锁的粒度比较粗。锁的粒度主要分为表级锁、页级锁和行锁。
12.3.2.1、表锁(Table Lock)
该锁会锁定整张表,它是 MySQL 中最基本的锁策略,并 不依赖于存储引擎(不管你是 MySQL 的什么存储引擎,对于表锁的策略都是一样的),并且表锁是 开销最小 的策略(因为粒度比较大)。
由于表级锁一次会将整个表锁定,所以可以很好的 避免死锁 问题。当然,锁粒度大的负面影响就是出现锁资源争用的概率会很高,导致 并发率大打折扣。
12.3.2.1.1、表级别的 S 锁、X 锁
在对某个表执行 SELECT、INSERT、DELETE、UPDATE 语句时,InnoDB 存储引擎是不会为这个表添加表级别的 S锁 或者 X锁 的。
在对某个表执行一些诸如 ALTER TABLE、DROP TABLE 这类的 DDL 语句时,其他事务对这个表并发执行诸如 SELECT、INSERT、DELETE、UPDATE 的语句会发生阻塞。
同理,某个事务中对某个表执行 SELECT、INSERT、DELETE、UPDATE 语句时,在其他会话中对这个表执行 DDL 语句也会发生阻塞。这个过程其实是通过在 server 层使用一种称之为 元数据锁(英文名:Metadata Locks,简称 MDL)结构来实现的。
一般情况下,不会使用 InnoDB 存储引擎提供的表级别的 S锁 和 X锁。只会在一些特殊情况下,比方说 崩溃恢复 过程中用到。比如,在系统变量 autocommit=0,innodb_table_locks = 1 时,手动获取 InnoDB 存储引擎提供的表 t 的 S锁 或者 X锁 可以这么写:
LOCK TABLES t READ:InnoDB 存储引擎会对表 t 加表级别的S锁。LOCK TABLES t WRITE:InnoDB 存储引擎会对表 t 加表级别的X锁。
不过尽量避免在使用 InnoDB 存储引擎的表上使用 LOCK TABLES 这样的手动锁表语句,它们并不会提供什么额外的保护,只是会降低并发能力而已。InnoDB 的厉害之处还是实现了更细粒度的 行锁,关于 InnoDB 表级别的 S锁 和 X锁 大家了解一下就可以了。
举例:下面我们讲解 MyISAM 引擎下的表锁。
步骤 1:创建表并添加数据。
CREATE TABLE mylock(
id INT NOT NULL PRIMARY KEY auto_increment,
NAME VARCHAR(20)
)ENGINE myisam;
# 插入一条数据
INSERT INTO mylock(NAME) VALUES('a');
# 查询表中所有数据
SELECT * FROM mylock;
+----+------+
| id | Name |
+----+------+
| 1 | a |
+----+------+步骤 2:查看表上加过的锁。
SHOW OPEN TABLES; # 主要关注In_use字段的值
或者
SHOW OPEN TABLES where In_use > 0;mysql> SHOW OPEN TABLES where In_use > 0;
Empty set (0.00 sec)上面的结果表明,当前数据库中没有被锁定的表。
步骤 3:手动增加表锁命令。
LOCK TABLES t READ; # 存储引擎会对表t加表级别的共享锁。共享锁也叫读锁或S锁(Share的缩写)
LOCK TABLES t WRITE; # 存储引擎会对表t加表级别的排他锁。排他锁也叫独占锁、写锁或X锁(exclusive的缩写)比如:
mysql> lock tables mylock read;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW OPEN TABLES where In_use > 0;
+------------+--------+--------+-------------+
| Database | Table | In_use | Name_locked |
+------------+--------+--------+-------------+
| atguigudb1 | mylock | 1 | 0 |
+------------+--------+--------+-------------+
1 row in set (0.00 sec)步骤 4:释放表锁。
UNLOCK TABLES; # 使用此命令解锁当前加锁的表比如:
mysql> unlock tables;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW OPEN TABLES where In_use > 0;
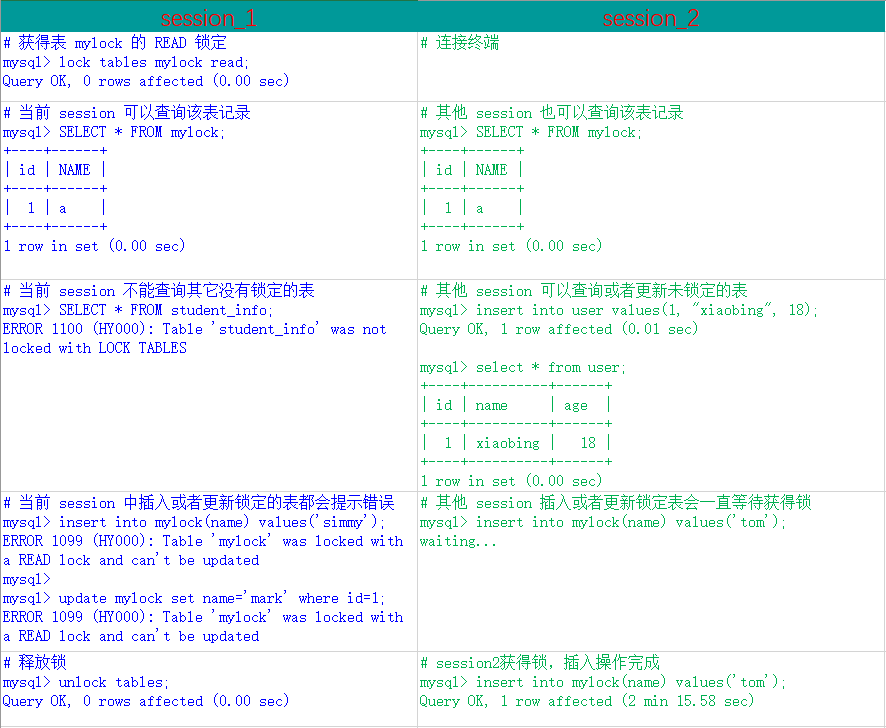
Empty set (0.00 sec)步骤 5:加读锁。
我们为 mylock 表加 read 锁(读阻塞写),观察阻塞的情况,流程如下:
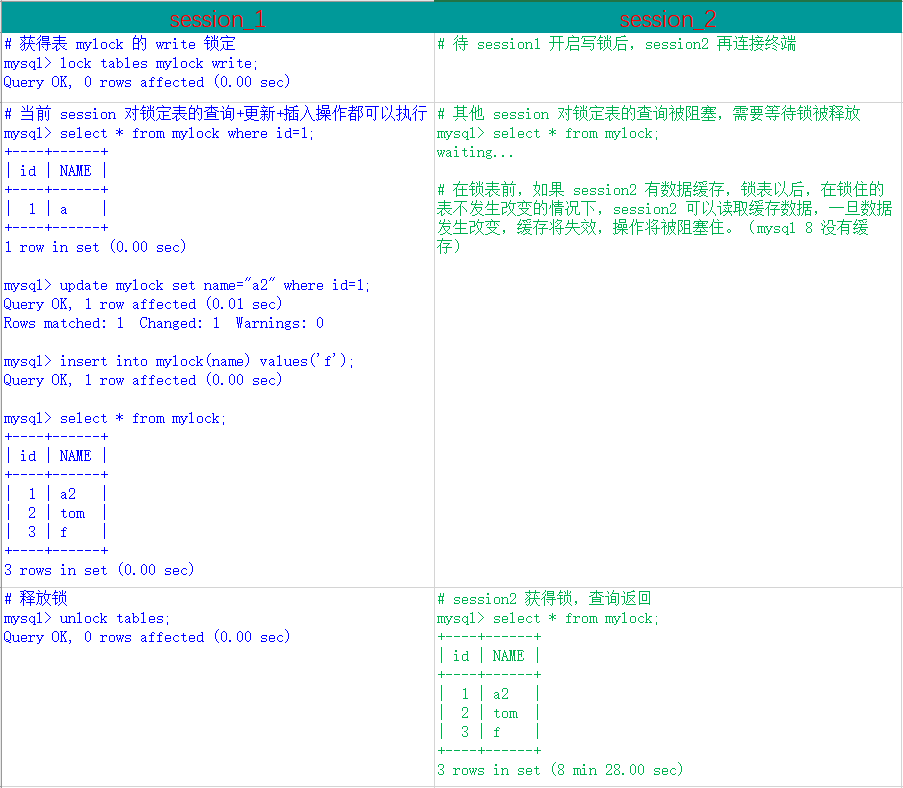
步骤 6:加写锁
为 mylock 表加 write 锁,观察阻塞的情况,流程如下:
总结:
MyISAM 在执行查询语句(SELECT)前,会给涉及的所有表加读锁,在执行增删改操作前,会给涉及的表加写锁。InnoDB 存储引擎是不会为这个表添加表级别的读锁和写锁的。
MySQL 的表级锁有两种模式:(以 MyISAM 表进行操作的演示)
- 表共享读锁(Table Read Lock)
- 表独占写锁(Table Write Lock)
| 锁类型 | 自己可读 | 自己可写 | 自己可操作其它表 | 他人可读 | 他人可写 |
|---|---|---|---|---|---|
| 读锁 | 是 | 否 | 否 | 是 | 否,等 |
| 写锁 | 是 | 是 | 否 | 否,等 | 否,等 |
12.3.2.1.2、意向锁(intention lock)
InnoDB 支持 多粒度锁(multiple granularity locking),它允许 行级锁 与 表级锁 共存,而 意向锁 就是其中的一种 表锁。
- 意向锁的存在是为了协调行锁和表锁的关系,支持多粒度(表锁和行锁)的锁并存。
- 意向锁是一种
不与行级锁冲突的表级锁,这一点非常重要。
意向锁的意义:假设表 t 有 100 万条记录,事务 T1 给表 t 第 100 万行这条记录加上了 X 行锁。事务 T2 也要操作表 t,就必须检查表 t 有哪此行锁,不得不扫描 100 万行记录,效率很低。此时,意向锁就出现了,当 T1 给表 t 加行锁的同时,InnoDB 自动为表 t 加上意向锁 IX,这样的话,T2 发现表 t 有 IX,就知道有人在表 t 的某些记录上加了锁。(这里提前说明了意向锁的意义,对照下面的《意向锁要解决的问题》这段话,加深理解。)
意向锁分为两种:
-
意向共享锁(intention shared lock, IS):事务有意向对表中的某些行加共享锁(S 锁)。
-- 事务要获取某些行的 S 锁,必须先获得表的 IS 锁。 SELECT column FROM table ... LOCK IN SHARE MODE; -
意向排他锁(intention exclusive lock, IX):事务有意向对表中的某些行加排他锁(X 锁)。
-- 事务要获取某些行的 X 锁,必须先获得表的 IX 锁。 SELECT column FROM table ... FOR UPDATE;
即:意向锁是由存储引擎 自己维护的,用户无法手动操作意向锁,在为数据行加共享 / 排他锁之前,InooDB 会先获取该数据行 所在数据表的对应意向锁。
1、意向锁要解决的问题
现在有两个事务,分别是 T1 和 T2,其中 T2 试图在该表级别上应用共享或排它锁,如果没有意向锁存在,那么 T2 就需要去检查各个页或行是否存在锁,这是因为要避免锁冲突,不得不从大粒度锁深入排查到小粒度锁;
如果存在意向锁,那么此时就会受到由 T1 控制的 表级别意向锁的阻塞。T2 在锁定该表前不必检查各个页或行锁,而只需要检查表上的意向锁。这是因为 InnoDB 发现事务 T1 给表加了小粒度的行锁,就会自动给表加一个大粒度的表锁,即意向锁。避免事务 T2 从表锁检查到页锁,再到每一行记录的行锁,严重影响性能。
在数据表的场景中,如果我们给某一行数据加上了排它锁,数据库会自动给更大一级的空间,比如数据页或数据表加上意向锁,告诉其他人这个数据页或数据表已经有人上过排它锁了,这样当其他人想要获取数据表排它锁的时候,只需要了解是否有人已经获取了这个数据表的意向排他锁即可。
- 如果事务想要获得数据表中某些记录的共享锁,就需要在数据表上
添加意向共享锁。 - 如果事务想要获得数据表中某些记录的排他锁,就需要在数据表上
添加意向排他锁。
这时,意向锁会告诉其他事务已经有人锁定了表中的某些记录。
举例:创建表 teacher,插入 6 条数据,事务的隔离级别默认为 Repeatable-Read,如下所示。
CREATE TABLE `teacher` (
`id` int NOT NULL,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `teacher` VALUES
('1', 'zhangsan'),
('2', 'lisi'),
('3', 'wangwu'),
('4', 'zhaoliu'),
('5', 'songhongkang'),
('6', 'leifengyang');mysql> SELECT @@transaction_isolation;
+-------------------------+
| @@transaction_isolation |
+-------------------------+
| REPEATABLE-READ |
+-------------------------+
1 row in set (0.00 sec)假设事务 A 获取了某一行的排他锁,并未提交,语句如下所示:
BEGIN;
SELECT * FROM teacher WHERE id = 6 FOR UPDATE;事务 B 想要获取 teacher 表的表读锁,语句如下:
BEGIN;
LOCK TABLES teacher READ;因为共享锁与排他锁互斥,所以事务 B 在试图对 teacher 表加共享锁的时候,必须保证两个条件。
- 当前没有其他事务持有 teacher 表的排他锁。
- 当前没有其他事务持有 teacher 表中任意一行的排他锁。
为了检测是否满足第二个条件,事务 B 必须在确保 teacher 表不存在任何排他锁的前提下,去检查表中的每一行是否存在排他锁。很明显这是一个效率很差的做法,但是有了意向锁,情况就不一样了。
意向锁是怎么解决这个问题的呢?首先,我们需要知道意向锁之间的兼容互斥性,如下所示。
| 意向共享锁(IS) | 意向排他锁(IX) | |
|---|---|---|
| 意向共享锁(IS) | 兼容 | 兼容 |
| 意向排他锁(IX) | 兼容 | 兼容 |
即意向锁之间是互相兼容的,但它会与普通的排他 / 共享锁互斥。
| 意向共享锁(IS) | 意向排他锁(IX) | |
|---|---|---|
| 共享锁(S) | 兼容 | 互斥 |
| 排他锁(X) | 互斥 | 互斥 |
注意这里的排他 / 共享锁指的都是表锁,意向锁不会与行级别的共享 / 排他锁互斥。回到刚才 teacher 表的例子。
事务 A 获取了某一行的排他锁,并未提交:
BEGIN;
SELECT * FROM teacher WHERE id = 6 FOR UPDATE;此时 teacher 表存在两把锁:teacher 表上的意向排他锁与 id=6 的数据行上的排他锁。事务 B 想要获取 teacher 表的共享锁。
BEGIN;
LOCK TABLES teacher READ;此时事务 B 检测事务 A 持有 teacher 表的意向排他锁,就可以得知事务 A 必须持有该表中某些数据行的排他锁,那么事务 B 对 teacher 表的加锁请求就会被排斥(阻塞),而无需去检测表中的每一行数据是否存在排他锁。
2、意向锁的并发性
意向锁不会与行级的共享 / 排他锁互斥!正因为如此,意向锁并不会影响到多个事务对不同数据行加排他锁时的并发性。(不然我们直接用普通的表锁就行了)
我们扩展一下上面 teacher 表的例子来概括一下意向锁的作用(一条数据从被锁定到被释放的过程中,可能存在多种不同锁,但是这里我们只着重表现意向锁)。
事务 A 先获得了某一行的排他锁,并未提交:
BEGIN;
SELECT * FROM teacher WHERE id = 6 FOR UPDATE;事务 A 获取了 teacher 表上的意向排他锁。事务 A 获取了 id=6 的数据行上的排他锁。之后事务 B 想要获取 teacher 表上的共享锁。
BEGIN;
LOCK TABLES teacher READ;事务 B 检测到事务 A 持有 teacher 表的意向排他锁。事务 B 对 teacher 表的加锁请求被阻塞(排斥)。最后事务 C 也想获取 teacher 表中某一行的排他锁。
BEGIN;
SELECT * FROM teacher WHERE id = 5 FOR UPDATE;事务 C 申请 teacher 表的意向排他锁。事务 C 检测到事务 A 持有 teacher 表的意向排他锁。因为意向锁之间并不互斥,所以事务 C 获取到了 teacher 表的意向排他锁。因为 id=5 的数据行上不存在任何排他锁,最终事务 C 成功获取到了该数据行上的排他锁。
从上面的案例可以得到如下结论:
- InnoDB 支持
多粒度锁,特定场景下,行级锁可以与表级锁共存。 - 意向锁之间互不排斥,但除了 IS 与 S 兼容外,
意向锁会与 共享锁 / 排他锁 互斥。 - IX,IS 是表级锁,不会和行级的 X,S 锁发生冲突。只会和表级的 X,S 发生冲突。
- 意向锁在保证并发性的前提下,实现了
行锁和表锁共存且满足事务隔离性的要求。
12.3.2.1.3、自增锁(AUTO-INC)
在使用 MySQL 过程中,我们可以为表的某个列添加 AUTO_INCREMENT 属性。举例:
CREATE TABLE `teacher` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;由于这个表的 id 字段声明了 AUTO_INCREMENT,意味着在书写插入语句时不需要为其赋值,SQL 语句修改如下所示。
INSERT INTO `teacher` (name) VALUES ('zhangsan'), ('lisi');上边的插入语句并没有为 id 列显式赋值,所以系统会自动为它赋上递增的值,结果如下所示。
mysql> select * from teacher;
+----+----------+
| id | name |
+----+----------+
| 1 | zhangsan |
| 2 | lisi |
+----+----------+
2 rows in set (0.00 sec)上面我们看到的插入数据只是一种简单的插入模式,所有插入数据的方式总共分为三类,分别是 Simple inserts,Bulk inserts 和 Mixed-mode inserts 。
-
Simple inserts(简单插入)
可以
预先确定要插入的行数的语句。包括没有嵌套子查询的单行和多行INSERT...VALUES()和REPLACE语句。比如我们上面举的例子就属于该类插入,已经确定要插入的行数。 -
Bulk inserts(批量插入)
事先不知道要插入的行数的语句。比如INSERT ... SELECT,REPLACE ... SELECT和LOAD DATA语句,但不包括纯 INSERT。InnoDB 会每处理一行记录就为 AUTO_INCREMENT 列分配一个值。 -
Mixed-mode inserts(混合模式插入)
这些是 Simple inserts 语句但是指定部分新行的自动递增值。例如
INSERT INTO teacher (id,name) VALUES (1,'a'), (NULL,'b'), (5,'c'), (NULL,'d');只是指定了部分 id 的值。另一种类型的混合模式插入是INSERT ... ON DUPLICATE KEY UPDATE。
对于上面数据插入的案例,MySQL 中采用了 自增锁 的方式来实现,当我们向含有 AUTO_INCREMENT 列的表中插入数据时,会在表级别上加一把自增锁 AUTO-INC 锁,直到数据插入完毕,AUTO-INC 锁才会释放掉。
一个事务在持有 AUTO-INC 锁的过程中,其他事务的插入语句都要被阻塞,可以保证一个语句中分配的递增值是连续的。
正是因为这样,其并发性能不高,当我们向一个有 AUTO_INCREMENT 的主键列中插入值的时候,每条语句都要对这个表锁进行竞争,这样的并发效率很低下,所以 innodb 通过 innodb_autoinc_lock_mode 的不同取值来提供不同的锁定机制,来显著提高 SQL 语句的可伸缩性和性能。
innodb_autoinc_lock_mode 有三种取值,分别对应与不同锁定模式:
-
innodb_autoinc_lock_mode = 0(传统锁定模式)
在此锁定模式下,所有类型的 insert 语句都会获得一个特殊的表级 AUTO-INC 锁,用于插入具有 AUTO_INCREMENT 列的表。
这种模式其实就如我们上面的例子,即每当执行 insert 的时候,都会得到一个表级锁(AUTO-INC锁),使得语句中生成的 auto_increment 有顺序,且在 binlog 中重放的时候,可以保证 master 与 slave 中数据的 auto_increment 是相同的。因为是表级锁,当在同一时间多个事务中执行 insert 的时候,对于 AUTO-INC 锁的争夺会
限制并发能力。 -
innodb_autoinc_lock_mode = 1(连续锁定模式)
在 MySQL 8.0 之前,连续锁定模式是
默认的。在这个模式下,bulk inserts 仍然使用 AUTO-INC 表级锁,并保持到语句结束。这适用于所有 INSERT ... SELECT,REPLACE ... SELECT 和 LOAD DATA 语句。同一时刻只有一个语句可以持有 AUTO-INC 锁。
对于 Simple inserts(要插入的行数事先已知),则通过在
mutex(轻量锁)的控制下获得所需数量的自动递增值来避免表级 AUTO-INC 锁,它只在分配过程的持续时间内保持,而不是直到语句完成。不使用表级 AUTO-INC 锁,除非 AUTO-INC 锁由另一个事务保持。如果另一个事务保持 AUTO-INC 锁,则 Simple inserts 等待 AUTO-INC 锁,如同它是一个 bulk inserts。
-
innodb_autoinc_lock_mode = 2(交错锁定模式)
从 MySQL 8.0 开始,交错锁模式是
默认设置。在此锁定模式下,自动递增值
保证在所有并发执行的所有类型的 insert 语句中是唯一且单调递增的。但是,由于多个语句可以同时生成数字(即,跨语句交叉编号),为任何给定语句插入的行生成的值可能不是连续的。如果执行的语句是 simple inserts,其中要插入的行数已提前知道,除了 Mixed-mode inserts 之外,为单个语句生成的数字不会有间隙。然后,当执行 bulk inserts 时,在由任何给定语句分配的自动递增值中可能存在间隙。
12.3.2.1.4、元数据锁(MDL 锁)
MySQL5.5 引入了 meta data lock,简称 MDL 锁,属于表锁范畴。MDL 的作用是,保证读写的正确性。
比如,如果一个查询正在遍历一个表中的数据,而执行期间另一个线程对这个 表结构做变更,增加了一 列,那么查询线程拿到的结果跟表结构对不上,肯定是不行的。
因此,当对一个表做增删改查操作的时候,加 MDL 读锁;当要对表做结构变更操作的时候,加 MDL 写锁。
读锁之间不互斥,因此你可以有多个线程同时对一张表增删查改。读写锁之间、写锁之间都是互斥的,用来保证变更表结构操作的安全性,解决了 DML 和 DDL 操作之间的一致性问题。不需要显式使用,在访问一个表的时候会被自动加上。
举例:元数据锁的使用场景模拟
会话 A:从表中查询数据
mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT COUNT(1) FROM teacher;
+----------+
| COUNT(1) |
+----------+
| 2 |
+----------+
1 row int set (7.46 sec)会话 B:修改表结构,增加新列
mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)
mysql> alter table teacher add age int not null;会话 C:查看当前 MySQL 的进程
mysql> show processlist;通过会话 C 可以看出会话 B 被阻塞,这是由于会话 A 拿到了 teacher 表的元数据读锁,会话 B 想申请 teacher 表的元数据写锁,由于读写锁互斥,会话 B 需要等待会话 A 释放元数据锁才能执行。
元数据锁可能带来的问题:
| Session A | Session B | Session C |
|---|---|---|
| begin;select * from teacher; | ||
| alter table teacher add age int; | ||
| select * from teacher; |
我们可以看到 Session A 会对 teacher 表加一个 MDL 读锁,之后 session B 要加 MDL 写锁会被 blocked,因为 Session A 的 MDL 读锁还没有释放,而 Session C 要在表 teacher 上新申请 MDL 读锁的请求也会被 Session B 阻塞。因为申请 MDL 锁的操作会形成一个队列,队列中写锁在前,就会阻塞后面的读锁。
前面我们说了,所有对表的增删改查操作都需要先申请 MDL 读锁,有链式阻塞风险,就是说这个表已经完全不可读写了。如果某个表上的查询语句频繁,而且客户端有重试机制,也就是说超时后会再起一个新 session 再请求的话,这个库的线程很快就会爆满,导致数据库崩掉。
解决办法:
- 避免写大事务,如果不是查询所在的事务太大,也不会导致后面语句获取不到 MDL 写锁。
- 事务中,尽量减少加锁时间。比如从 test 表中获取的数据在事务最后一步才会用到,可以把对 test 的查询放在事务的尾部。减少对 test 加锁时间。
- 对表结构修改的语句注意执行时间,长时间卡住需要先取消掉,避免影响其他线程对表的增删改查操作。
12.3.2.2、InnoDB 中的行锁
行锁(Row Lock)也称为记录锁,顾名思义,就是锁住某一行(某条记录 row)。需要注意的是,MySQL 服务器层并没有实现行锁机制,行级锁只在存储引擎层实现。
优点:锁定力度小,发生 锁冲突概率低,可以实现的 并发度高。
缺点:对于 锁的开销比较大,加锁会比较慢,容易出现 死锁 情况。
InnoDB 与 MyISAM 的最大不同有两点:一是支持事物(TRANSACTION);二是采用了行级锁。
首先我们创建表如下:
CREATE TABLE student (
id INT,
name VARCHAR(20),
class VARCHAR(10),
PRIMARY KEY (id)
) Engine=InnoDB CHARSET=utf8;向这个表里插入几条记录:
INSERT INTO student VALUES
(1, '张三', '一班'),
(3, '李四', '一班'),
(8, '王五', '二班'),
(15, '赵六', '二班'),
(20, '钱七', '三班');mysql> SELECT * FROM student;
+----+--------+--------+
| id | name | class |
+----+--------+--------+
| 1 | 张三 | 一班 |
| 3 | 李四 | 一班 |
| 8 | 王五 | 二班 |
| 15 | 赵六 | 二班 |
| 20 | 钱七 | 三班 |
+----+--------+--------+
5 rows in set (0.00 sec)student 表中的聚簇索引的简图如下所示。
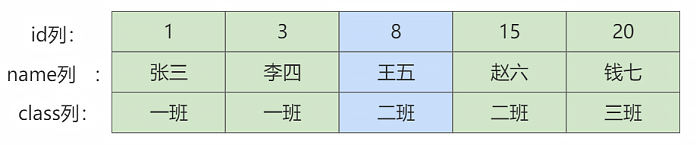
这里把 B+ 树的索引结构做了超级简化,只把索引中的记录给拿了出来,下面看看都有哪些常用的行锁类型。
12.3.2.2.1、记录锁(Record Locks)
记录锁也就是仅仅把一条记录上锁,官方的类型名称为:LOCK_REC_NOT_GAP。比如我们把 id 值为 8 的那条记录加一个记录锁的示意图如下。仅仅是锁住了 id 值为 8 的记录,对周围的数据没有影响。
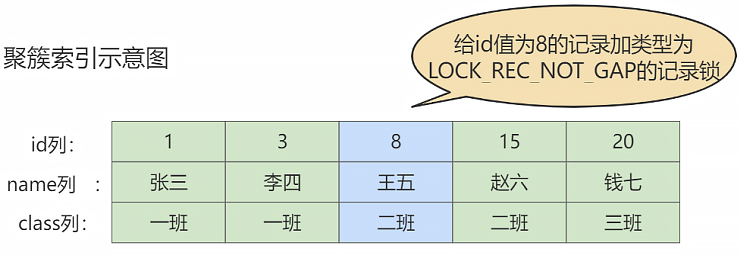
举例如下:

记录锁是有 S 锁和 X 锁之分的,称之为 S型记录锁 和 X型记录锁。
- 当一个事务获取了一条记录的 S 型记录锁后,其他事务也可以继续获取该记录的 S 型记录锁,但不可以继续获取 X 型记录锁;
- 当一个事务获取了一条记录的 X 型记录锁后,其他事务既不可以继续获取该记录的 S 型记录锁,也不可以继续获取 X 型记录锁。
12.3.2.2.2、间隙锁(Gap Locks)
MySQL 在 REPEATABLE READ 隔离级别下是可以解决幻读问题的,解决方案有两种,可以使用 MVCC 方案解决,也可以采用 加锁 方案解决。但是在使用加锁方案解决时有个大问题,就是事务在第一次执行读取操作时,那些幻影记录尚不存在,我们无法给这些 幻影记录 加上 记录锁。
InnoDB 提出了一种称之为 Gap Locks 的锁,官方的类型名称为: LOCK_GAP,我们可以简称为 gap锁。比如,把 id 值为 8 的那条记录加一个 gap 锁的示意图如下。
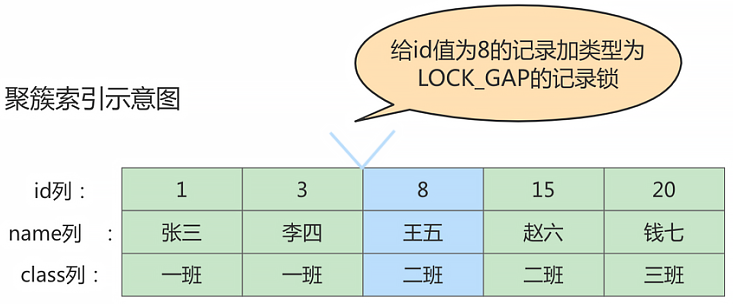
图中 id 值为 8 的记录加了 gap 锁,意味着 不允许别的事务在id值为8的记录前边的间隙插入新记录,其实就是 id 列的值(3, 8)这个区间的新记录是不允许立即插入的。
比如,有另外一个事务再想插入一条 id 值为 4 的新记录,它定位到该条新记录的下一条记录的 id 值为 8,而这条记录上又有一个 gap 锁,所以就会阻塞插入操作,直到拥有这个 gap 锁的事务提交了之后,id 列的值在区间(3, 8)中的新记录才可以被插入。
gap 锁的提出仅仅是为了防止插入幻影记录而提出的。虽然有 共享gap锁 和 独占gap锁 这样的说法,但是它们起到的作用是相同的。而且如果对一条记录加了 gap 锁(不论是共享 gap 锁还是独占 gap 锁),并不会限制其他事务对这条记录加记录锁或者继续加 gap 锁。
举例:
| Session1 | Session2 |
|---|---|
| select * from student where id=5 lock in share mode; | |
| select * from student where id=5 for update; |
这里 session2 并不会被堵住。因为表里并没有 id=5 这条记录,因此 session1 加的是间隙锁(3,8)。而 session2 也是在这个间隙加的间隙锁。它们有共同的目标,即:保护这个间隙锁,不允许插入值。但是它们之间是不冲突的。
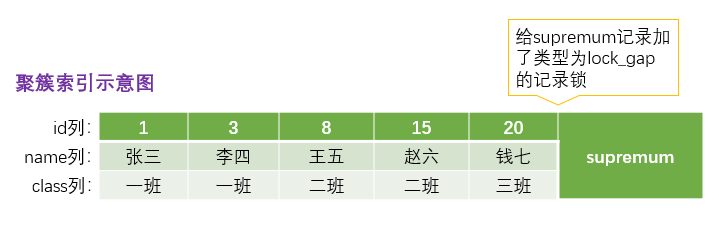
注意:给一条记录加了 gap锁 只是 不允许 其他事务往这条记录前边的间隙 插入新记录,那对于最后一条记录之后的间隙,也就是 student 表中 id 值为 20 的记录之后的间隙该怎么办?也就是说给哪条记录加 gap锁 才能阻止其他事务在 id 为 (20, +∞) 这个区间插入新记录?
这时候我们在讲数据页时介绍的两条伪记录派上用场了:
Infimum记录,表示该页面中最小的记录。Supremum记录,表示该页面中最大的记录。
为了实现阻止其他事务插入 id 值在(20, 正无穷)这个区间的新纪录,我们可以给索引中的最后一条记录,也就是 id 值为 20 的那条记录所在页面的 Supremum 记录加上一个 gap 锁,如图所示。
mysql> begin;
mysql> select * from student where id > 20 lock in share mode;
Empty set (0.01 sec)检测:
mysql> select * from performance_schema.data_locks\G
*************************** 1. row ***************************
ENGINE: INNODB
ENGINE_LOCK_ID: 140439923457240:1114:140439927705280
ENGINE_TRANSACTION_ID: 421914900167896
THREAD_ID: 54
EVENT_ID: 118
OBJECT_SCHEMA: atguigudb1
OBJECT_NAME: student
PARTITION_NAME: NULL
SUBPARTITION_NAME: NULL
INDEX_NAME: NULL
OBJECT_INSTANCE_BEGIN: 140439927705280
LOCK_TYPE: TABLE
LOCK_MODE: IS
LOCK_STATUS: GRANTED
LOCK_DATA: NULL
*************************** 2. row ***************************
ENGINE: INNODB
ENGINE_LOCK_ID: 140439923457240:53:4:1:140439927702224
ENGINE_TRANSACTION_ID: 421914900167896
THREAD_ID: 54
EVENT_ID: 118
OBJECT_SCHEMA: atguigudb1
OBJECT_NAME: student
PARTITION_NAME: NULL
SUBPARTITION_NAME: NULL
INDEX_NAME: PRIMARY
OBJECT_INSTANCE_BEGIN: 140439927702224
LOCK_TYPE: RECORD
LOCK_MODE: S
LOCK_STATUS: GRANTED
LOCK_DATA: supremum pseudo-record
2 rows in set (0.00 sec)这样就可以阻止其他事务插入 id 值在(2, +∞)这个区间的新记录。
间隙锁的引入,可能会导致同样的语句锁住更大的范围,这其实是影响了并发度的。下面的例子会产生 死锁。
| Session 1 | Session 2 |
|---|---|
| begin; select * from student where id=5 for update; |
begin; select * from student where id=5 for update; |
| INSERT INTO student values(5, 'Brinnatt', '一班'); # 阻塞 | |
| INSERT INTO student values(5, 'Brinnatt', '一班'); ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction |
-
session 1 执行 select ... for update 语句,由于 id=5 这一行并不存在,因此会加上间隙锁(3, 8);
-
session 2 执行 select ... for update 语句,同样会加上间隙锁(3, 8),间隙锁之间不会冲突,因此这个语句可以执行成功;
-
session 2 试图插入一行 (5, 'Brinnatt', '一班'),被 session 1 的间隙锁挡住了,只好进入等待;
-
session 1 试图插入一行 (5, 'Brinnatt', '一班'),被 session 2 的间隙锁挡住了,至此,两个 session 进入互相等待状态,形成死锁。当然,InnoDB 的死锁检测马上就发现了这对死锁关系,让 session 1 的 insert 语句报错返回。
12.3.2.2.3、临键锁(Next-Key Locks)
有时候我们既想 锁住某条记录,又想阻止其他事务在该记录前边的间隙插入新记录,所以 InnoDB 就提出了一种称之为 Next-Key Locks 的锁,官方的类型名称为: LOCK_ORDINARY,我们也可以简称为 next-key 锁。
Next-Key Locks 是在存储引擎 innodb、事务级别在可重复读的情况下使用的数据库锁,innodb 默认的锁就是 Next-Key locks。比如,我们把 id 值为 8 的那条记录加一个 next-key 锁的示意图如下:

next-key锁 的本质就是一个 记录锁 和一个 gap锁 的合体,它既能保护该条记录,又能阻止别的事务将新记录插入被保护记录前边的 间隙。
begin;
select * from student where id <=8 and id > 3 for update;我们说一个事务在插入一条记录时需要判断一下插入位置是不是被别的事务加了 gap锁(next-key锁 也包含 gap锁),如果有的话,插入操作需要等待,直到拥有 gap锁 的那个事务提交。
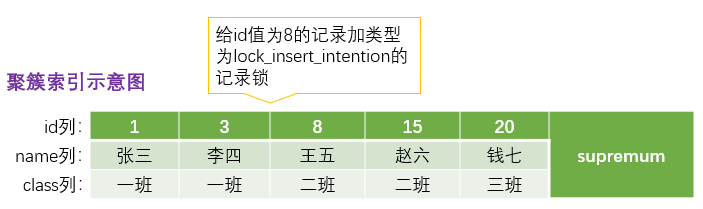
但是 InnoDB 规定事务在等待的时候也需要在内存中生成一个锁结构,表明有事务想在某个 间隙 中插入新记录,但是现在在等待。InnoDB 就把这种类型的锁命名为 Insert Intention Locks,官方的类型名称为:LOCK_INSERT_INTENTION,我们称为 插入意向锁。插入意向锁是一种 gap锁,不是意向锁,在 insert 操作时产生。
插入意向锁是在插入一条记录前,由 INSERT 操作产生的一种间隙锁。该锁用以表示插入意向,当多个事务在同一区间(gap)插入位置不同的多条数据时,事务之间不需要互相等待。
假设存在两条值分别为 4 和 7 的记录,两个不同的事务分别试图插入值为 5 和 6 的两条记录,每个事务在获取插入行上独占的(排他)锁前,都会获取(4,7)之间的间隙锁,但是因为数据行之间并不冲突,所以两个事务之间并不会产生冲突(阻塞等待)。
总结来说,插入意向锁的特性可以分为两部分:
- 插入意向锁是一种
特殊的间隙锁,间隙锁可以锁定开区间内的部分记录。 - 插入意向锁之间
互不排斥,所以即使多个事务在同一区间插入多条记录,只要记录本身(主键、唯一索引)不冲突,那么事务之间就不会出现冲突等待。
注意,虽然插入意向锁中含有意向锁三个字,但是它并不属于意向锁而属于间隙锁,因为意向锁是表锁而插入意向锁是 行锁。
比如,把 id 值为 8 的那条记录加一个插入意向锁的示意图如下:
比如,现在 T1 给 id 值为 8 的记录加了一个 gap 锁,然后 T2 和 T3 分别想向 student 表中插入 id 值分别为 4、5 的两条记录,所以现在给 id 值为 8 的记录加的锁的示意图就如下所示:
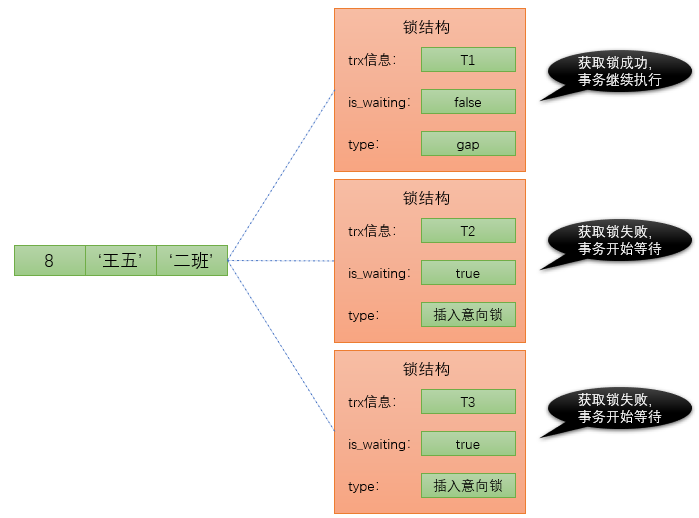
从图中可以看到,由于 T1 持有 gap 锁,所以 T2 和 T3 需要生成一个插入意向锁的锁结构并且处于等待状态。当 T1 提交后会把它获取到的锁都释放掉,这样 T2 和 T3 就能获取到对应的插入意向锁了。(本质上就是把插入意向锁对应锁结构的 is_waiting 属性改为 false)
T2 和 T3 之间也并不会相互阻塞,它们可以同时获取到 id 值为 8 的插入意向锁,然后执行插入操作。事实上插入意向锁并不会阻止别的事务继续获取该记录上任何类型的锁。
12.3.2.3、页锁
页锁就是在 页的粒度 上进行锁定,锁定的数据资源比行锁要多,因为一个页中可以有多个行记录。当我们使用页锁的时候,会出现数据浪费的现象,但这样的浪费最多也就是一个页上的数据行。页锁的开销介于表锁和行锁之间,会出现死锁。锁定粒度介于表锁和行锁之间,并发度一般。
每个层级的锁数量是有限制的,因为锁会占用内存空间,锁空间的大小是有限的。当某个层级的锁数量超过了这个层级的阈值时,就会进行 锁升级。锁升级就是用更大粒度的锁替代多个更小粒度的锁,比如 InnoDB 中行锁升级为表锁,这样做的好处是占用的锁空间降低了,但同时数据的并发度也下降了。
12.3.3、乐观锁、悲观锁
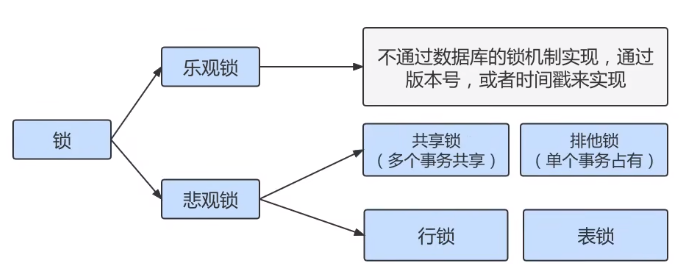
从对待锁的态度来看锁的话,可以将锁分成乐观锁和悲观锁,从名字中也可以看出这两种锁是两种看待 数据并发的思维方式。需要注意的是,乐观锁和悲观锁并不是锁,而是锁的 设计思想。
12.3.3.1、悲观锁(Pessimistic Locking)
悲观锁是一种思想,顾名思义,就是很悲观,对数据被其他事务的修改持保守态度,会通过数据库自身的锁机制来实现,从而保证数据操作的排它性。
悲观锁总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会 阻塞 直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。
比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁,当其他线程想要访问数据时,都需要阻塞挂起。Java 中 synchronized 和 ReentrantLock 等独占锁就是悲观锁思想的实现。
秒杀案例 1:
商品秒杀过程中,库存数量的减少,避免出现 超卖 的情况。比如,商品表中有一个字段为 quantity 表示当前该商品的库存量。假设商品为华为 mate40,id 为 1001,quantity=100 个。如果不使用锁的情况下,操作方法如下所示:
# 第1步:查出商品库存
select quantity from items where id=1001;
# 第2步:如果库存大于0,则根据商品信息生成订单
insert into orders(item_id) values(1001);
# 第3步:修改商品的库存,num表示购买数量
update items set quantity=quantity-num where id=1001;这样写的话,在并发量小的公司没有大的问题,但是如果在 高并发环境 下可能出现以下问题:
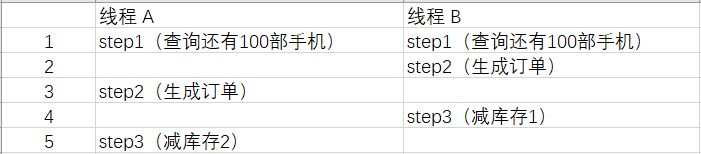
其中线程 B 此时已经下单并且减完库存,这个时候线程 A 依然去执行 step3,就造成了超卖。
这们使用悲观锁可以解决这个问题,商品信息从查询出来到修改,中间有一个生成订单的过程,使用悲观锁的原理就是,当我们在查询 items 信息后就把当前的数据锁定,直到我们修改完毕后再解锁。
那么整个过程中,因为数据被锁定了,就不会出现有第三者来对其进行修改了。而这样做的前提是把要执行的 SQL 语句放在同一个事务中,否则达不到锁定数据行的目的。
修改如下:
# 第1步:查出商品库存
select quantity from items where id=1001 for update;
# 第2步:如果库存大于0,则根据商品信息生产订单
insert into orders(item_id) values(1001);
# 第3步:修改商品的库存,num表示购买数量
update items set quantity=quantity-num where id=1001;select ... for update; 是 MySQL 中悲观锁。此时在 items 表中,id 为 1001 的那条数据就被我们锁定了,其他的要执行 select quantity from items where id=1001 for update; 语句的事务必须等本次事务提交之后才能执行。这样我们可以保证当前的数据不会被其他事务修改。
注意,当执行 select quantity from items where id=1001 for update; 语句之后,如果在其他事务中执行 select quantity from items where id=1001; 语句,并不会受第一个事务的影响,仍然可以正常查询出数据。
注意:select ... for update 语句执行过程中所有扫描的行都会被锁上,因此在 MySQL 中用悲观锁必须确定使用了索引,而不是全表扫描,否则将会把整个表锁住。
悲观锁不适用的场景较多,它存在一些不足,因为悲观锁大多数情况下依靠数据库的锁机制来实现,以保证程序的并发访问性,同时这样对数据库性能开销影响也很大,特别是 长事务 而言,这样的 开销往往无法承受,这时就需要乐观锁。
12.3.3.2、乐观锁(Optimistic Locking)
乐观锁认为对同一数据的并发操作不会总发生,属于小概率事件,不用每次都对数据上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,也就是不采用数据库自身的锁机制,而是通过程序来实现。
在程序上,我们可以采用 版本号机制 或者 CAS机制 实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量。在 Java 中 java.util.concurrent.atomic 包下的原子变量类就是使用了乐观锁的一种实现方式:CAS 实现的。
12.3.3.2.1、乐观锁的版本号机制
在表中设计一个 版本字段 version,第一次读的时候,会获取 version 字段的取值。然后对数据进行更新或删除操作时,会执行 UPDATE ... SET version=version+1 WHERE version=version。此时如果已经有事务对这条数据进行了更改,修改就不会成功。
这种方式类似我们熟悉的 SVN、CVS 版本管理系统,当我们修改了代码进行提交时,首先会检查当前版本号与服务器上的版本号是否一致,如果一致就可以直接提交,如果不一致就需要更新服务器上的最新代码,然后再进行提交。
12.3.3.2.2、乐观锁的时间戳机制
时间戳和版本号机制一样,也是在更新提交的时候,将当前数据的时间戳和更新之前取得的时间戳进行比较,如果两者一致则更新成功,否则就是版本冲突。
你能看到乐观锁就是程序员自己控制数据并发操作的权限,基本是通过给数据行增加一个戳(版本号或者时间戳),从而证明当前拿到的数据是否最新。
秒杀案例 2:
依然使用上面秒杀的案例,执行流程如下:
# 第1步:查出商品库存
select quantity from items where id=1001;
# 第2步:如果库存大于0,则根据商品信息生产订单
insert into orders(item_id) values(1001);
# 第3步:修改商品的库存,num表示购买数量
update items set quantity=quantity-num, version=version+1 where id=1001 and version=${version};注意,如果数据表是 读写分离 的表,当 master 表中写入的数据没有及时同步到 slave 表中时,会造成更新一直失败的问题。此时需要 强制读取master表 中的数据(即将 select 语句放到事务中即可,这时候查询的就是 master 主库了。)
如果我们对同一条数据进行 频繁的修改 的话,那么就会出现这么一种场景,每次修改都只有一个事务能更新成功,在业务感知上面就有大量的失败操作。我们把代码修改如下:
# 第1步:查出商品库存
select quantity from items where id=1001;
# 第2步:如果库存大于0,则根据商品信息生产订单
insert into orders(item_id) values(1001);
# 第3步:修改商品的库存,num表示购买数量
update items set quantity=quantity-num where id=1001 and quantity-num>0;这样就会使每次修改都能成功,而且不会出现超卖的现象。
12.3.3.2.3、两种锁的适用场景
从这两种锁的设计思想中,我们总结一下乐观锁和悲观锁的适用场景:
乐观锁适合读操作多的场景,相对来说写的操作比较少。它的优点在于程序实现,不存在死锁问题,不过适用场景也会相对乐观,因为它阻止不了除了程序以外的数据库操作。悲观锁适合写操作多的场景,因为写的操作具有排它性。采用悲观锁的方式,可以在数据库层面阻止其他事务对该数据的操作权限,防止读 - 写和写 - 写的冲突。
我们把乐观锁和悲观锁总结如下图所示:
12.3.4、显式锁、隐式锁
12.3.4.1、隐式锁
一个事务在执行 INSERT 操作时,如果即将插入的间隙已经被其他事务加了 gap 锁,那么本次 INSERT 操作会阻塞,并且当前事务会在该间隙上加一个 插入意向锁,否则一般情况下 INSERT 操作是不加锁的。
那如果一个事务首先插入了一条记录(此时并没有在内存生产与该记录关联的锁结构),然后另一个事务:
-
立即使用
SELECT ... LOCK IN SHARE MODE语句读取这条记录,也就是要获取这条记录的S锁,或者使用SELECT ... FOR UPDATE语句读取这条记录,也就是要获取这条记录的X锁,怎么办?如果允许这种情况的发生,那么可能产生
脏读问题。 -
立即修改这条记录,也就是要获取这条记录的
X锁,怎么办?如果允许这种情况的发生,那么可能产生
脏写问题。
这时候我们前面提过的 事务 id 又要起作用了。我们把聚簇索引和二级索引中的记录分开看一下:
-
情景一:对于聚簇索引记录来说,有一个
trx_id隐藏列,该隐藏列记录着最后改动该记录的事务 id。那么如果在当前事务中新插入一条聚簇索引记录后,该记录的 trx_id 隐藏列代表的的就是当前事务的事务 id。如果其他事务此时想对该记录添加
S锁或者X锁时,首先会看一下该记录的 trx_id 隐藏列代表的事务是否是当前的活跃事务,如果是的话,那么就帮助当前事务创建一个X 锁(也就是为当前事务创建一个锁结构,is_waiting 属性是 false),然后自己进入等待状态(也就是为自己也创建一个锁结构,is_waiting 属性是 true)。 -
情景二:对于二级索引记录来说,本身并没有 trx_id 隐藏列,但是在二级索引页面的 Page Header 部分有一个
PAGE_MAX_TRX_ID属性,该属性代表对该页面做改动的最大的事务id,如果 PAGE_MAX_TRX_ID 属性值小于当前最小的活跃事务 id,那么说明对该页面做修改的事务都已经提交了,否则就需要在页面中定位到对应的二级索引记录,然后回表找到它对应的聚簇索引记录,然后再重复情景一的做法。
即:一个事务对新插入的记录可以不显式的加锁(生成一个锁结构),但是由于 事务id 的存在,相当于加了一个 隐式锁。别的事务在对这条记录加 S锁 或者 X锁 时,由于 隐式锁 的存在,会先帮助当前事务生成一个锁结构,然后自己再生成一个锁结构后进行等待状态。隐式锁是一种 延迟加锁 的机制,从而来减少加锁的数量。
隐式锁在实际内存对象中并不含有这个锁信息。只有当产生锁等待时,隐式锁转化为显式锁。
InnoDB 的 insert 操作,对插入的记录不加锁,但是此时如果另一个线程进行当前读,类似以下的用例,session 2 会锁等待 session 1,那么这是如何实现的呢?
session 1:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> insert INTO student VALUES(34,"周八","二班");
Query OK, 1 row affected (0.00 sec)session 2:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from student lock in share mode; # 执行完,当前事务被阻塞执行下述语句,输出结果:
mysql> SELECT * FROM performance_schema.data_lock_waits\G;
*************************** 1. row ***************************
ENGINE: INNODB
REQUESTING_ENGINE_LOCK_ID: 140562531358232:7:4:9:140562535668584
REQUESTING_ENGINE_TRANSACTION_ID: 422037508068888
REQUESTING_THREAD_ID: 64
REQUESTING_EVENT_ID: 6
REQUESTING_OBJECT_INSTANCE_BEGIN: 140562535668584
BLOCKING_ENGINE_LOCK_ID: 140562531351768:7:4:9:140562535619104
BLOCKING_ENGINE_TRANSACTION_ID: 15902
BLOCKING_THREAD_ID: 64
BLOCKING_EVENT_ID: 6
BLOCKING_OBJECT_INSTANCE_BEGIN: 140562535619104
1 row in set (0.00 sec)隐式锁的逻辑过程如下:
-
InnoDB 的每条记录中都有一个隐含的 trx_id 字段,这个字段存在于聚簇索引的 B+Tree 中。
-
在操作一条记录前,首先根据记录中的 trx_id 检查该事务是否是活动的事务(未提交或回滚)。如果是活动的事务,首先将
隐式锁转换为显式锁(就是为该事务添加一个锁)。 -
检查是否有锁冲突,如果有冲突,创建锁,并设置为 waiting 状态。如果没有冲突不加锁,跳到第 5 步。
-
等待加锁成功,被唤醒,或者超时。
-
写数据,并将自己的 trx_id 写入 trx_id 字段。
12.3.4.2、显式锁
通过特定的语句进行加锁,我们一般称之为显示加锁,例如:
显示加共享锁:
select .... lock in share mode显示加排它锁:
select .... for update12.3.5、全局锁
全局锁就是对 整个数据库实例 加锁。当你需要让整个库处于 只读状态 的时候,可以使用这个命令,之后其他线程的以下语句会被阻塞:数据更新语句(数据的增删改)、数据定义语句(包括建表、修改表结构等)和更新类事务的提交语句。全局锁的典型使用 场景 是:做 全库逻辑备份。
全局锁的命令:
Flush tables with read lock12.3.6、死锁
12.3.6.1、概念
两个事务都持有对方需要的锁,并且在等待对方释放,并且双方都不会释放自己的锁。
举例 1:
| 事务 1 | 事务 2 | |
|---|---|---|
| 1 | begin; update account set money=10 where id=1; |
begin; |
| 2 | update account set money=10 where id=2; | |
| 3 | update account set money=20 where id=2; | |
| 4 | update account set money=20 where id=1; |
举例 2:
用户 A 给用户 B 转账 100,在此同时,用户 B 也给用户 A 转账 100。这个过程,可能导致死锁。
# 事务1
update account set balance=balance-100 where name="A"; # 操作1
update account set balance=balance+100 where name="B"; # 操作3
# 事务2
update account set balance=balance-100 where name="B"; # 操作2
update account set balance=balance+100 where name="A"; # 操作412.3.6.2、产生死锁的必要条件
- 两个或者两个以上事务。
- 每个事务都已经持有锁并且申请新的锁。
- 锁资源同时只能被同一个事务持有或者不兼容。
- 事务之间因为持有锁和申请锁导致彼此循环等待。
死锁的关键在于:两个(或以上)的 Session 加锁的顺序不一致。
12.3.6.3、如何处理死锁
方式 1:等待,直到超时(innodb_lock_wait_timeout=50s)
当两个事务互相等待时,其中一个事务等待时间超过设定的阈值时,就会回滚,另一个事务继续进行。这种方法简单有效,在 innodb 中,参数 innodb_lock_wait_timeout 用来设置超时时间。
缺点:对于在线服务来说,这个等待时间往往是无法接受的。
那将此值修改短一些,比如 1s,0.1s 是否合适?不合适,容易误伤到普通的锁等待。
方式 2:使用死锁检测处理死锁程序
方式 1 检测死锁太过被动,innodb 还提供了 wait-for graph算法 来主动进行死锁检测,每当加锁请求无法立即满足而进入等待时,wait-for graph 算法都会被触发。
这是一种较为 主动的死锁检测机制,要求数据库保存 锁的信息链表 和 事物等待链表 两部分信息。
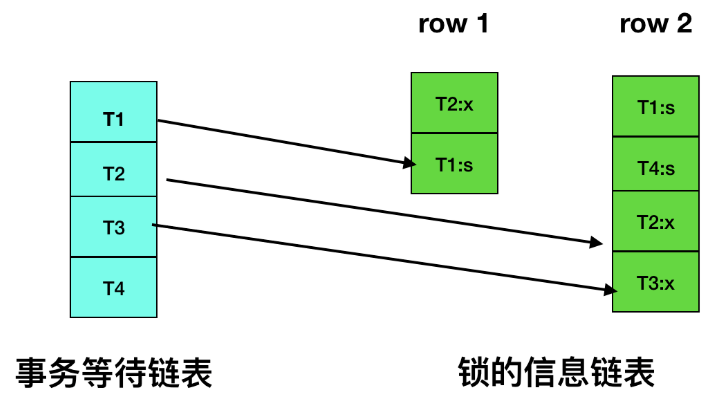
基于这两个信息,可以绘制 wait-for graph(等待图)
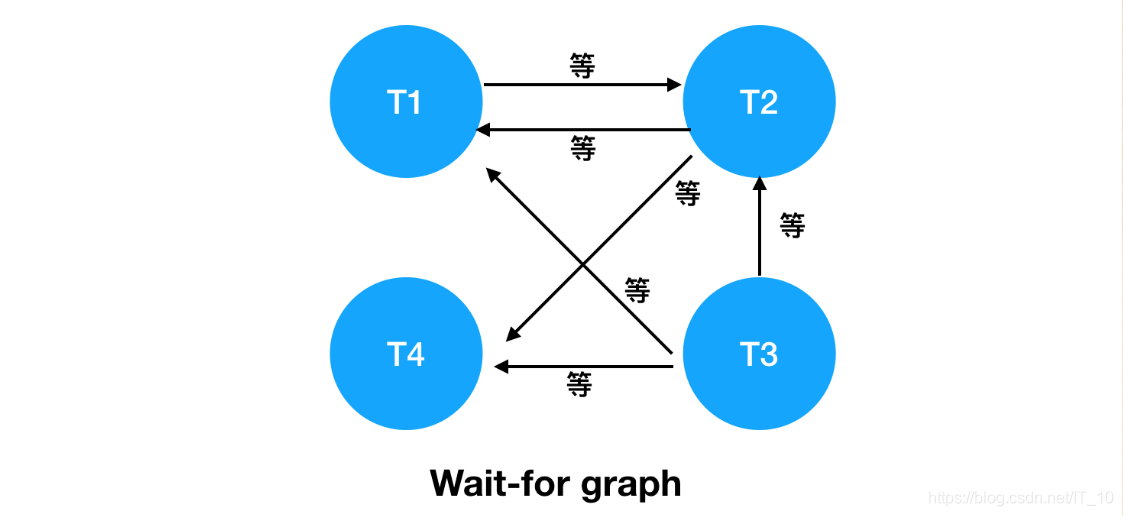
死锁检测的原理是构建一个以事务为顶点,锁为边的有向图,判断有向图是否存在环,存在既有死锁。
一旦检测到回路、有死锁,这时候 InnoDB 存储引擎会选择 回滚undo量最小的事务,让其他事务继续执行(innodb_deadlock_detect=on表示开启这个逻辑)。
缺点:每个新的被阻塞的线程,都要判断是不是由于自己的加入导致了死锁,这个操作时间复杂度是O(n)。如果 100 个并发线程同时更新同一行,意味着要检测 100*100=1万次,1 万个线程就会有 1 千万次检测。
如何解决?
- 方式 1:关闭死锁检测,但意味着可能会出现大量的超时,会导致业务有损。
- 方式 2:控制并发访问的数量。比如在中间件中实现对于相同行的更新,在进入引擎之前排队,这样在 InnoDB 内部就不会有大量的死锁检测工作。
进一步的思路:
可以考虑通过将一行改成逻辑上的多行来减少锁冲突。比如,连锁超市账户总额的记录,可以考虑放到多条记录上。账户总额等于这多个记录的值的总和。
12.3.6.4、如何避免死锁
- 合理设计索引,使业务 SQL 尽可能通过索引定位更少的行,减少锁竞争。
- 调整业务逻辑 SQL 执行顺序,避免 update/delete 长时间持有锁的 SQL 在事务前面。
- 避免大事务,尽量将大事务拆成多个小事务来处理,小事务缩短锁定资源的时间,发生锁冲突的几率也更小。
- 在并发比较高的系统中,不要显式加锁,特别是在事务里显式加锁。如
select ... for update语句,如果是在事务里运行了 start transaction 或设置了 autocommit 等于 0,那么就会锁定所查找到的记录。 - 降低隔离级别。如果业务允许,将隔离级别调低也是较好的选择,比如将隔离级别从 RR 调整为 RC,可以避免掉很多因为 gap 锁造成的死锁。
12.4、锁的内部结构
我们前边说对一条记录加锁的本质就是在内存中创建一个 锁结构 与之关联,那么是不是一个事务对多条记录加锁,就要创建多个 锁结构 呢?比如:
# 事务T1
SELECT * FROM user LOCK IN SHARE MODE;理论上创建多个 锁结构 没问题,但是如果一个事务要获取 10000 条记录的锁,生成 10000 个锁结构也太崩溃了!所以决定在对不同记录加锁时,如果符合下边这些条件的记录会放在一个 锁结构 中。
- 在同一个事务中进行加锁操作。
- 被加锁的记录在同一个页面中。
- 加锁的类型是一样的。
- 等待状态是一样的。
InnoDB 存储引擎中的 锁结构 如下:
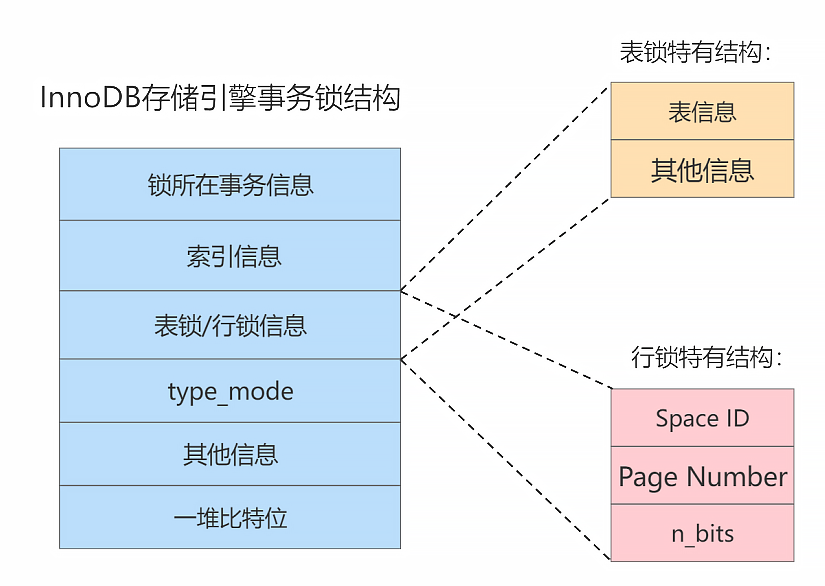
结构解析:
-
锁所在的事务信息:
不论是
表锁还是行锁,都是在事务执行过程中生成的,哪个事务生成了这个锁结构,这里就记录这个事务的信息。此
锁所在的事务信息在内存结构中只是一个指针,通过指针可以找到内存中关于该事务的更多信息,比方说事务 id 等。 -
索引信息:
对于
行锁来说,需要记录一下加锁的记录是属于哪个索引的。这里也是一个指针。 -
表锁/行锁信息:
表锁结构和行锁结构在这个位置的内容是不同的:-
表锁:
记载着是对哪个表加的锁,还有其他的一些信息。
-
行锁:
记载了三个重要的信息:
-
Space ID:记录所在表空间。 -
Page Number:记录所在页号。 -
n_bits:对于行锁来说,一条记录就对应着一个比特位,一个页面中包含很多记录,用不同的比特位来区分到底是哪一条记录加了锁。为此在行锁结构的末尾放置了一堆比特位,这个n_bis属性代表使用了多少比特位。
n_bits 的值一般都比页面中记录条数多一些。主要是为了之后在页面中插入了新记录后也不至于重新分配锁结构。
-
-
-
type_mode:
这是一个 32 位的数,被分成了
lock_mode、lock_type和rec_lock_type三个部分,如图所示: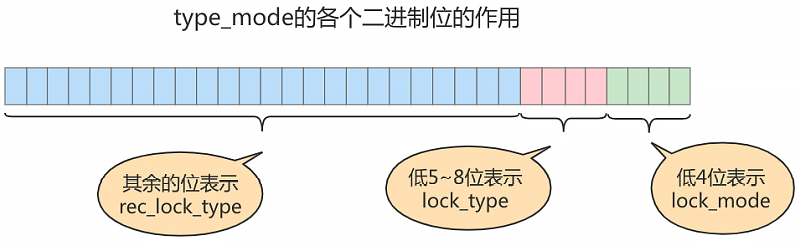
-
锁的模式(
lock_mode),占用低 4 位,可选的值如下:LOCK_IS(十进制的 0):表示共享意向锁,也就是IS锁。LOCK_IX(十进制的 1):表示独占意向锁,也就是IX锁。LOCK_S(十进制的 2):表示共享锁,也就是S锁。LOCK_X(十进制的 3):表示独占锁,也就是X锁。LOCK_AUTO_INC(十进制的 4):表示AUTO-INC锁。
在 InnoDB 存储引擎中,LOCK_IS,LOCK_IX,LOCK_AUTO_INC 都算是表级锁的模式,LOCK_S 和 LOCK_X 既可以算是表级锁的模式,也可以是行级锁的模式。
-
锁的类型(
lock_type),占用第5~8位,不过现阶段只有第 5 位和第 6 位被使用:LOCK_TABLE(十进制的 16),也就是当第 5 个比特位置为 1 时,表示表级锁。LOCK_REC(十进制的 32),也就是当第 6 个比特位置为 1 时,表示行级锁。
-
行锁的具体类型(
rec_lock_type),使用其余的位来表示。只有在lock_type的值为LOCK_REC时,也就是只有在该锁为行级锁时,才会被细分为更多的类型:LOCK_ORDINARY(十进制的 0):表示next-key锁。LOCK_GAP(十进制的 512):也就是当第 10 个比特位置为 1 时,表示gap锁。LOCK_REC_NOT_GAP(十进制的 1024):也就是当第 11 个比特位置为 1 时,表示正经记录锁。LOCK_INSERT_INTENTION(十进制的 2048):也就是当第 12 个比特位置为 1 时,表示插入意向锁。其他的类型:还有一些不常用的类型我们就不多说了。
-
is_waiting属性呢?基于内存空间的节省,所以把is_waiting属性放到了type_mode这个 32 位的数字中:LOCK_WAIT(十进制的 256):当第 9 个比特位置为 1 时,表示is_waiting为true,也就是当前事务尚未获取到锁,处在等待状态;当这个比特位为 0 时,表示is_waiting为false,也就是当前事务获取锁成功。
-
-
其他信息:
为了更好的管理系统运行过程中生成的各种锁结构而设计了各种哈希表和链表。
-
一堆比特位:
如果是
行锁结构的话,在该结构末尾还放置了一堆比特位,比特位的数量是由上边提到的n_bits属性表示的。InnoDB 数据页中的每条记录在
记录头信息中都包含一个heap_no属性,伪记录Infimum的heap_no值为 0,Supremum的heap_no值为 1,之后每插入一条记录,heap_no值就增 1。锁结构最后的一堆比特位就对应着一个页面中的记录,一个比特位映射一个
heap_no,即一个比特位映射到页内的一条记录。
12.5、锁监控
关于 MySQL 锁的监控,我们一般可以通过检查 InnoDB_row_lock 等状态变量来分析系统上的行锁的争夺情况。
mysql> show status like 'innodb_row_lock%';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| Innodb_row_lock_current_waits | 0 |
| Innodb_row_lock_time | 9903 |
| Innodb_row_lock_time_avg | 4951 |
| Innodb_row_lock_time_max | 9901 |
| Innodb_row_lock_waits | 2 |
+-------------------------------+-------+
5 rows in set (0.01 sec)对各个状态量的说明如下:
Innodb_row_lock_current_waits:当前正在等待锁定的数量;Innodb_row_lock_time:从系统启动到现在锁定总时间长度;(等待总时长)Innodb_row_lock_time_avg:每次等待所花平均时间;(等待平均时长)Innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花的时间;Innodb_row_lock_waits:系统启动后到现在总共等待的次数;(等待总次数)
尤其是当等待次数很高,而且每次等待时长也不小的时候,我们就需要分析系统中为什么会有如此多的等待,然后根据分析结果着手指定优化计划。
其他监控方法:
MySQL 把事务和锁的信息记录在了 information_schema 库中,涉及到的三张表分别是 INNODB_TRX、INNODB_LOCKS 和 INNODB_LOCK_WAITS。
MySQL5.7及之前,可以通过 information_schema.INNODB_LOCKS 查看事务的锁情况,但只能看到阻塞事务的锁;如果事务并未被阻塞,则在该表中看不到该事务的锁情况。
MySQL8.0 删除了 information_schema.INNODB_LOCKS,添加了 performance_schema.data_locks,可以通过 performance_schema.data_locks 查看事务的锁情况,和 MySQL5.7 及之前不同,performance_schema.data_locks 不但可以看到阻塞该事务的锁,还可以看到该事务所持有的锁。
同时,information_schema.INNODB_LOCK_WAITS 也被 performance_schema.data_lock_waits 所代替。
我们模拟一个锁等待的场景,以下是从这三张表收集的信息。
锁等待场景,我们依然使用前面记录锁中的案例,当事务 2 进行等待时,查询情况如下:
1、查询正在被锁阻塞的 sql 语句。
mysql> SELECT * FROM information_schema.INNODB_TRX\G;
*************************** 1. row ***************************
trx_id: 99660
trx_state: LOCK WAIT
trx_started: 2022-11-26 21:53:02
trx_requested_lock_id: 140439923457240:53:4:8:140439927703600
trx_wait_started: 2022-11-26 22:08:21
trx_weight: 4
trx_mysql_thread_id: 16
trx_query: update student set name="张三1" where id=1
trx_operation_state: starting index read
......
*************************** 2. row ***************************
trx_id: 99659
trx_state: RUNNING
trx_started: 2022-11-26 21:52:17
trx_requested_lock_id: NULL
......重要属性代表含义已在上述中标注。
2、查询锁等待情况
mysql> SELECT * FROM performance_schema.data_lock_waits\G
*************************** 1. row ***************************
ENGINE: INNODB
REQUESTING_ENGINE_LOCK_ID: 140439923457240:53:4:8:140439927703600
REQUESTING_ENGINE_TRANSACTION_ID: 99660
REQUESTING_THREAD_ID: 56
REQUESTING_EVENT_ID: 33
REQUESTING_OBJECT_INSTANCE_BEGIN: 140439927703600
BLOCKING_ENGINE_LOCK_ID: 140439923458048:53:4:8:140439927708256
BLOCKING_ENGINE_TRANSACTION_ID: 99659
BLOCKING_THREAD_ID: 57
BLOCKING_EVENT_ID: 24
BLOCKING_OBJECT_INSTANCE_BEGIN: 140439927708256
1 row in set (0.00 sec)3、查询锁的情况
mysql> SELECT * from performance_schema.data_locks\G;
*************************** 1. row ***************************
ENGINE: INNODB
ENGINE_LOCK_ID: 140439923457240:1114:140439927705280
ENGINE_TRANSACTION_ID: 99660
THREAD_ID: 56
EVENT_ID: 29
OBJECT_SCHEMA: atguigudb1
OBJECT_NAME: student
PARTITION_NAME: NULL
SUBPARTITION_NAME: NULL
INDEX_NAME: NULL
OBJECT_INSTANCE_BEGIN: 140439927705280
LOCK_TYPE: TABLE
LOCK_MODE: IX
LOCK_STATUS: GRANTED
LOCK_DATA: NULL
*************************** 2. row ***************************
ENGINE: INNODB
ENGINE_LOCK_ID: 140439923457240:53:4:9:140439927702224
ENGINE_TRANSACTION_ID: 99660
THREAD_ID: 56
EVENT_ID: 29
OBJECT_SCHEMA: atguigudb1
OBJECT_NAME: student
PARTITION_NAME: NULL
SUBPARTITION_NAME: NULL
INDEX_NAME: PRIMARY
OBJECT_INSTANCE_BEGIN: 140439927702224
LOCK_TYPE: RECORD
LOCK_MODE: X,REC_NOT_GAP
LOCK_STATUS: GRANTED
LOCK_DATA: 3
*************************** 3. row ***************************
ENGINE: INNODB
ENGINE_LOCK_ID: 140439923457240:53:4:8:140439927703600
ENGINE_TRANSACTION_ID: 99660
THREAD_ID: 56
EVENT_ID: 33
OBJECT_SCHEMA: atguigudb1
OBJECT_NAME: student
PARTITION_NAME: NULL
SUBPARTITION_NAME: NULL
INDEX_NAME: PRIMARY
OBJECT_INSTANCE_BEGIN: 140439927703600
LOCK_TYPE: RECORD
LOCK_MODE: X,REC_NOT_GAP
LOCK_STATUS: WAITING
LOCK_DATA: 1
*************************** 4. row ***************************
ENGINE: INNODB
ENGINE_LOCK_ID: 140439923458048:1114:140439927711360
ENGINE_TRANSACTION_ID: 99659
THREAD_ID: 57
EVENT_ID: 24
OBJECT_SCHEMA: atguigudb1
OBJECT_NAME: student
PARTITION_NAME: NULL
SUBPARTITION_NAME: NULL
INDEX_NAME: NULL
OBJECT_INSTANCE_BEGIN: 140439927711360
LOCK_TYPE: TABLE
LOCK_MODE: IX
LOCK_STATUS: GRANTED
LOCK_DATA: NULL
*************************** 5. row ***************************
ENGINE: INNODB
ENGINE_LOCK_ID: 140439923458048:53:4:8:140439927708256
ENGINE_TRANSACTION_ID: 99659
THREAD_ID: 57
EVENT_ID: 24
OBJECT_SCHEMA: atguigudb1
OBJECT_NAME: student
PARTITION_NAME: NULL
SUBPARTITION_NAME: NULL
INDEX_NAME: PRIMARY
OBJECT_INSTANCE_BEGIN: 140439927708256
LOCK_TYPE: RECORD
LOCK_MODE: X,REC_NOT_GAP
LOCK_STATUS: GRANTED
LOCK_DATA: 1
5 rows in set (0.00 sec)从锁的情况可以看出来,两个事务分别获取了 IX 锁,我们从意向锁章节可以知道,IX 锁互相是兼容的。所以这里不会等待,但是事务 1 同样持有 X 锁,此时事务 2 也要去同一行记录获取 X 锁,他们之间不兼容,导致等待的情况发生。