第 1 章 大数据入门
关于大数据的专业知识在互联网上是一个热门话题,种类繁多,新概念也层出不穷,多翻几篇有质感的文章也就了解的差不多了。这里只是为了让一个没接触过大数据的人快速进入大数据领域,所以不会过多地去深入一个问题,而是通过一个项目实战,先走通一条删繁就简的道,消除大部分困惑。
大数据最核心的部分叫数据仓库,下面以数据仓库为抓手进行讲解。前面会提一些数据仓库的概念,简单了解一下即可,然后进入实践。
1.1、数据仓库
1.1.1、数据仓库概念
数据仓库( Data Warehouse ),是为企业制定决策,提供数据支持的。可以帮助企业,改进业务流程、提高产品质量等。
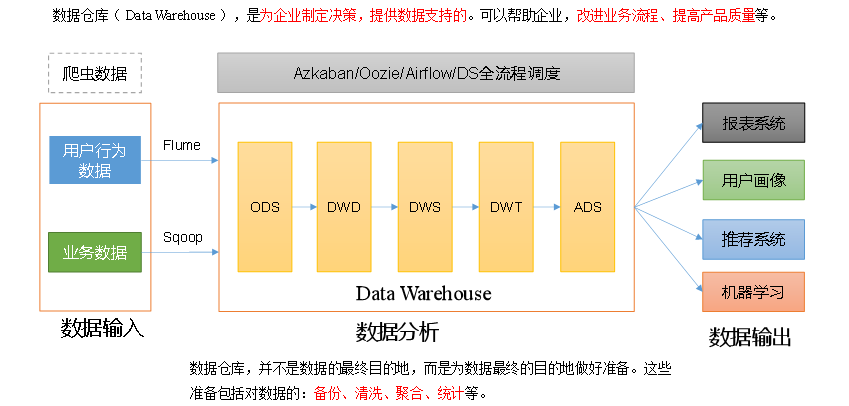
数据输入也就是数据仓库的源数据通常包括:业务数据、用户行为数据和爬虫数据等。
- 业务数据:就是各行业在处理事务过程中产生的数据。比如用户在电商网站中登录、下单、支付等过程中,需要和网站后台数据库进行增删改查交互,产生的数据就是业务数据。业务数据通常存储在 MySQL、Oracle 等数据库中。
- 用户行为数据:用户在使用产品过程中,通过埋点收集与客户端产品交互过程中产生的数据,并发往日志服务器进行保存。比如页面浏览、点击、停留、评论、点赞、收藏等。用户行为数据通常存储在日志文件中。
- 爬虫数据:通常是通过技术手段获取其他公司网站的数据。
数据分析也就是数据仓库的计算过程包括:
- ODS:最好理解,基本上就是数据从源表拉过来,进行 ETL,比如 mysql 映射到 hive,那么到了 hive 里面就是 ods 层。这一层数据不能修改,只能追加,可以充当源数据的备份。
- ODS 全称是 Operational Data Store,操作数据存储 "面向主题的",数据运营层,也叫 ODS 层,是最接近数据源中数据的一层,数据源中的数据,经过抽取、洗净、传输,也就是传说中的 ETL 之后,装入本层。
- DWD:data warehouse details 细节数据层,是业务层与数据仓库的隔离层。主要对 ODS 数据层做一些数据清洗和规范化的操作。
- 数据清洗:去除空值、脏数据、超过极限范围的。
- DWS:data warehouse service 数据服务层,整合汇总成分析某一个主题域的服务数据层,一般是宽表。用于提供后续的业务查询,OLAP 分析,数据分发等。
- 用户行为,轻度聚合。
- 主要对 ODS/DWD 层数据做一些轻度的汇总。
- DWT:data warehouse topic 主题数据层,存储的是客观数据,一般用作中间层,可以认为是大量指标的数据层。
- ADS:ApplicationData Service 应用数据服务,该层主要是提供数据产品和数据分析使用的数据,一般会存储在 ES、mysql 等系统中供线上系统使用。
- 我们通常说的报表数据,或者说那种大宽表,一般就放在这里。
1.1.2、数据仓库特点
- 面向主题:为数据分析提供服务,根据主题将原始数据集合在一起。
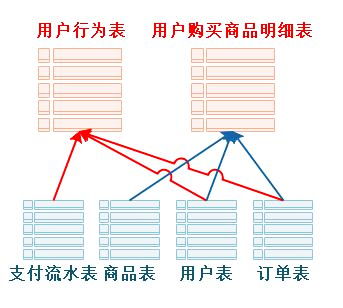
在电商业务系统中,为了记录客户成交订单的信息,会生成下面支付流水表、商品表、用户表和订单表这 4 张数据表,此时只是为了买卖双方就商品达成交易;
一旦将这 4 张表进行了主题计算汇总成 "用户行为表" "用户购买商品明细表",可以带来新的业务增长。比如分析客户喜好,向客户精准推送产品;比如分析消费人群与商品的关联,协助产品开发和产品定位等。也就是说通过数据分析帮助企业拓宽市场,增加收入。
- 集成:原始数据来源于不同数据源,要整合成最终数据,需要经过抽取、清洗、转换的过程。
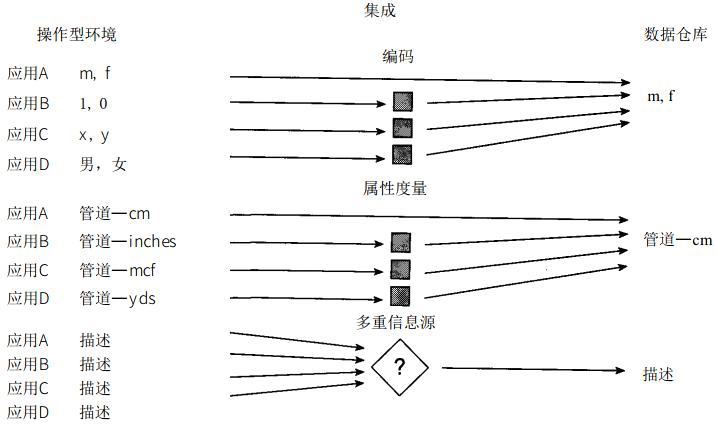
由于大数据平台原始数据来源不同,像我们这个图片展示的一样,源数据格式、单位和描述信息都不一样,需要通过技术手段将这些源数据进行统一编码,统一度量以及信息汇总等,才能存入数据仓库。只有这样,才方便数据的下一步处理。
- 非易失:保存的数据是一系列历史快照,不允许被修改,只允许通过工具进行查询、分析,但是可以追加。
- 时变性:数据仓库会定期接收、集成新的数据,从而反映出数据的最新变化。
1.1.3、数据仓库与数据库区别
数据库面向事务设计,属于 OLTP(在线事务处理)系统,主要操作是随机读写;在设计时尽量避免冗余,常采用符合范式规范来设计。
数据仓库是面向主题设计的,属于 OLAP(在线分析处理)系统,主要操作是批量读写;关注数据整合,以及分析、处理性能;会有意引入冗余,采用反范式方式设计。
| 数据库 | 数据仓库 | |
|---|---|---|
| 面向 | 事务 | 分析 |
| 数据类型 | 细节、业务 | 综合、清洗过的数据 |
| 数据特点 | 当前的、最新的 | 历史的、跨时间维度 |
| 目的 | 日常操作 | 长期信息需求、决策支持 |
| 设计模型 | 基于 ER 模型,面向应用 | 星形/雪花模型,面向主题 |
| 操作 | 读/写 | 大多为读 |
| 数据规模 | GB、TB | >= TB、PB |
1.1.4、建模方法
数仓的建模或者分层,其实都是为了更好地去组织、管理、维护数据,所以当你站在更高的维度去看的话,所有的划分都是为了更好的管理。
- 访问性能:能够快速查询所需的数据,减少数据 I/O。
- 数据成本:减少不必要的数据冗余,实现计算结果数据复用,降低大数据系统中的存储成本和计算成本。
- 使用效率:改善用户应用体验,提高使用数据的效率。
- 数据质量:改善数据统计口径的不一致性,减少数据计算错误的可能性,提供高质量的、一致的数据访问平台。
- 需要注意的是,建模其实是和公司的业务、公司的数据量、公司使用的工具、公司数据的使用方式密不可分的,因为模型是概念上的东西,需要理论落地,至于落地到什么程度,就取决于公司的现状了。
1.1.4.1、OLTP 系统建模方法
OLTP(在线事务处理)系统中,主要操作是随机读写;为了保证数据一致性、减少冗余,常使用关系模型;在关系模型中,使用三范式规则来减少冗余。
1.1.4.2、OLAP 在线联机分析
OLAP 系统,主要操作是复杂分析查询;关注数据整合,以及分析、处理性能。OLAP 根据数据存储的方式不同,又分为 ROLAP、MOLAP、HOLAP。
- ROLAP(Relation OLAP,关系型 OLAP):使用关系模型构建,存储系统一般为 RDBMS。
- MOLAP(Multidimensional OLAP,多维型 OLAP):预先聚合计算,使用多维数组的形式保存数据结果,加快查询分析时间。
- HOLAP(Hybrid OLAP,混合架构的 OLAP):ROLAP 和 MOLAP 两者的集成;如低层是关系型的,高层是多维矩阵型的;查询效率高于 ROLAP,低于MOLAP。
1.1.4.3、维度模型
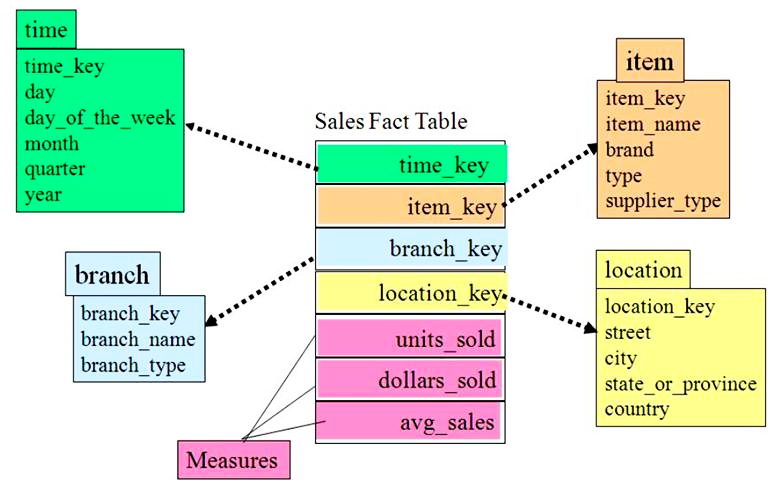
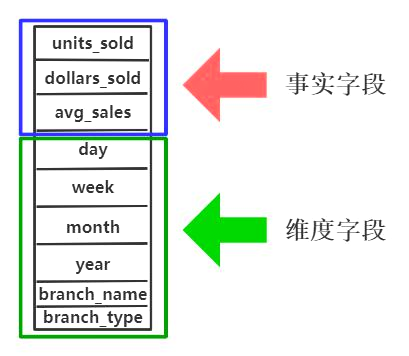
维度模型中,表被分为维度表、事实表,维度是对事实的一种组织,一般包含分类、时间、地域等。
维度模型分为星型模型、雪花模型、星座模型;维度模型建立后,方便对数据进行多维分析。
-
星型模型
标准的星型模型,维度只有一层,分析性能最优。
-
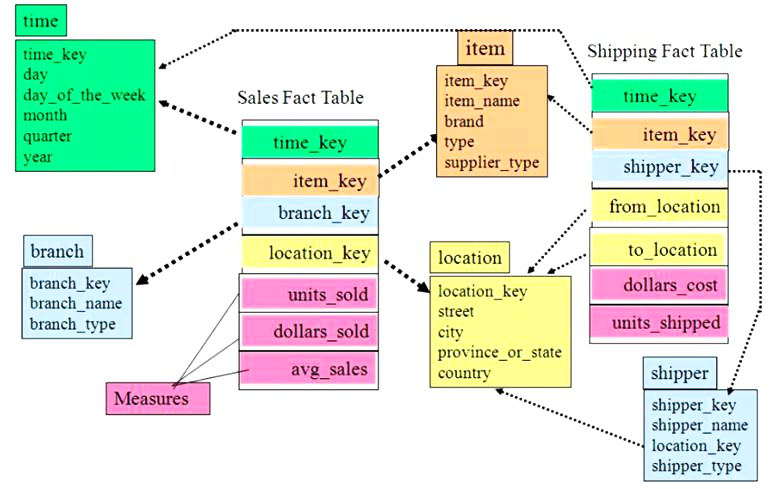
雪花模型
雪花模型具有多层维度,比较接近三范式设计,较为灵活。
![]()
-
星座模型
星座模型基于多个事实表,事实表之间会共享一些维度表。
是大型数据仓库中的常态,是业务增长的结果,与模型设计无关。
-
宽表模型
宽表模型是维度模型的衍生,适合 join 性能不佳的数据仓库产品。
宽表模型将维度冗余到事实表中,形成宽表,以此减少 join 操作。
1.1.5、最佳实践
1.1.5.1、表分类
我们常用的建模方法是维度模型,也就是对数据表进行多维组织,最佳实践中使用以下表类型:
-
事实表
一般是指一个现实存在的业务对象,比如用户,商品,商家,销售员等等
| 用户ID | 姓名 | 生日 | 性别 | 邮箱 | 用户等级 | 创建时间 |
|---|---|---|---|---|---|---|
| 1 | 张三 | 2000-01-03 | 男 | zs@163.com | 3 | 2000-01-03 |
| 2 | 李四 | 2000-01-04 | 男 | ls@163.com | 4 | 2000-01-04 |
| 3 | 王五 | 2000-01-05 | 男 | ww@163.com | 5 | 2000-01-05 |
-
维度表
一般是指对应一些业务状态,代码的解释表。也可以称之为码表。
通常使用维度对事实表中的数据进行统计、聚合运算。
| 订单状态 | 状态名称 | 商品分类编号 | 分类名称 |
|---|---|---|---|
| 1 | 未支付 | 1 | 生活 |
| 2 | 已支付 | 2 | 科技 |
| 3 | 发货中 | 3 | 少儿 |
| 4 | 已发货 | ||
| 5 | 已完成 |
-
事务事实表
随着业务不断产生的数据,一旦产生不会再变化,如交易流水、操作日志、出库入库记录。
| 编号 | 对外业务编号 | 订单编号 | 用户编号 | 支付交易流水编号 | 支付金额 | 交易内容 | 支付类型 | 支付时间 |
|---|---|---|---|---|---|---|---|---|
| 1 | 56123 | 1 | 021 | Qty9o07 | 300.5 | 火锅底料 | alipay | 2020-01-03 |
| 2 | 56124 | 2 | 012 | lQt3Zo0 | 250.1 | 毛肚 | alipay | 2020-01-03 |
| 3 | 56125 | 3 | 102 | Hi36Q9l | 39.7 | 鸭肠 | 2020-01-03 |
-
周期快照事实表
随着业务周期型的推进而变化,完成间隔周期内的度量统计,如年、季度累计。
使用周期 + 状态度量的组合,如年累计订单数,年是周期,订单总数是量度。
| 业务ID | 卖家ID | 年累计下单金额 | 年累计买家数 | 年累计支付金额 | 年累计支付买家数 | ... |
|---|---|---|---|---|---|---|
| 1 | 0001 | 709802 | 1892 | 609210 | 1871 | ... |
| 2 | 0002 | 500870 | 9021 | 490789 | 8829 | ... |
-
累积快照事实表
记录不确定周期的度量统计,完全覆盖一个事实的生命周期,如订单状态表。
通常有多个时间字段,用于记录生命周期中的关键时间点。
只有一条记录,针对此记录不断更新。
| 订单编号 | 订单金额 | 订单状态 | 用户ID | 下单时间 | 支付时间 | 确认收货时间 |
|---|---|---|---|---|---|---|
| 1 | 300.5 | 1 | 021 | 2020-01-03 | null | null |
| 1 | 300.5 | 1 | 021 | 2020-01-03 | 2020-01-03 | null |
| 1 | 300.5 | 1 | 021 | 2020-01-03 | 2020-01-03 | 2020-01-06 |
实现方式一
- 使用日期分区表,全量数据记录,每天的分区存储昨天全量数据和当天增量数据合并的结果。
- 数据量大会导致全量表膨胀,存储大量永远不更新的冷数据,对性能影响较大。
- 适用于数据量少的情况。
实现方式二
- 使用日期分区表,推测数据最长生命周期,存储周期内数据;周期外的冷数据存储到归档表。
- 需要保留多天的分区数据,存储消耗依然很大。
实现方式三
- 使用日期分区表,以业务实体的结束时间分区,每天的分区存放当天结束的数据;设计一个时间非常大的分区,如 9999-12-31,存放截止当前未结束的数据。
- 已结束的数据存放到相应分区,存放未结束数据的分区,数据量也不会很大,ETL 性能好。
- 无存储浪费,数据全局唯一。
- 业务系统可能无法标识业务实体的结束时间,可以使用其它相关业务系统的结束标志作为此业务系统的结束,也可以使用最长生命周期时间或前端系统的数据归档时间。
1.1.5.2、ETL 策略
全量同步:
- 数据初始化装载一定使用全量同步的方式。
- 因为业务、技术原因,使用全量同步的方式做周期数据更新,直接覆盖原有数据即可。
增量同步:
- 传统数据整合方案中,大多采用 merge 方式(update+insert)。
- 主流大数据平台不支持 update 操作,可采用全外连接 + 数据全量覆盖方式。
- 如果担心数据更新出错,可以采用分区方式,每天保存最新的全量版本,保留较短周期。
1.2、项目搭建
项目背景:
- 某电商企业,因数据积存、分析需要,筹划搭建数据仓库,提供数据分析访问接口。
- 项目一期需要完成数仓建设,并完成用户复购率的分析计算,支持业务查询需求。
复购率计算:
- 复购率是指在一段时间间隔内,多次重复购买产品的用户,占全部人数的比率。
- 统计各个一级品类下,品牌月单次复购率,和多次复购率。
| 品牌 | 一级品类 | 品类名称 | 购买人数 | 购买 2+ 次人数 | 单次复购率 | 购买 3+ 次人数 | 多次复购率 |
|---|---|---|---|---|---|---|---|
| A | 1 | A | 100 | 80 | 80% | 50 | 50% |
| B | 20 | B | 200 | 120 | 60% | 40 | 20% |
数据描述:
- 订单表(order_info)
| 字段 | 含义 |
|---|---|
| id | 订单编号 |
| total_amount | 订单金额 |
| order_status | 订单状态 |
| user_id | 用户id |
| payment_way | 支付方式 |
| out_trade_no | 支付流水号 |
| create_time | 创建时间 |
- 订单详情表(order_detail)
| 字段 | 含义 |
|---|---|
| id | 订单编号 |
| order_id | 订单号 |
| user_id | 用户 id |
| sku_id | 商品 id |
| sku_name | 商品名称 |
| order_price | 下单价格 |
| sku_num | 商品数量 |
| create_time | 创建时间 |
- 商品表(sku_info)
| 字段 | 含义 |
|---|---|
| id | skuId |
| spu_id | spuid |
| price | 价格 |
| sku_name | 商品名称 |
| sku_desc | 商品描述 |
| weight | 重量 |
| tm_id | 品牌id |
| category3_id | 品类id |
| create_time | 创建时间 |
- 用户表(user_info)
| 字段 | 含义 |
|---|---|
| id | 用户 id |
| name | 姓名 |
| birthday | 生日 |
| gender | 性别 |
| 邮箱 | |
| user_level | 用户等级 |
| create_time | 创建时间 |
- 支付流水表(payment_info)
| 字段 | 含义 |
|---|---|
| id | 编号 |
| out_trade_no | 对外业务编号 |
| order_id | 订单编号 |
| user_id | 用户编号 |
| alipay_trade_no | 支付宝交易流水编号 |
| total_amount | 支付金额 |
| subject | 交易内容 |
| payment_type | 支付类型 |
| payment_time | 支付时间 |
- 商品一级分类表(base_category1)
| 字段 | 含义 |
|---|---|
| id | id |
| name | 名称 |
- 商品二级分类表(base_category2)
| 字段 | 含义 |
|---|---|
| id | id |
| name | 名称 |
| category1_id | 一级品类id |
- 商品三级分类表(base_category3)
| 字段 | 含义 |
|---|---|
| id | id |
| name | 名称 |
| Category2_id | 二级品类 id |
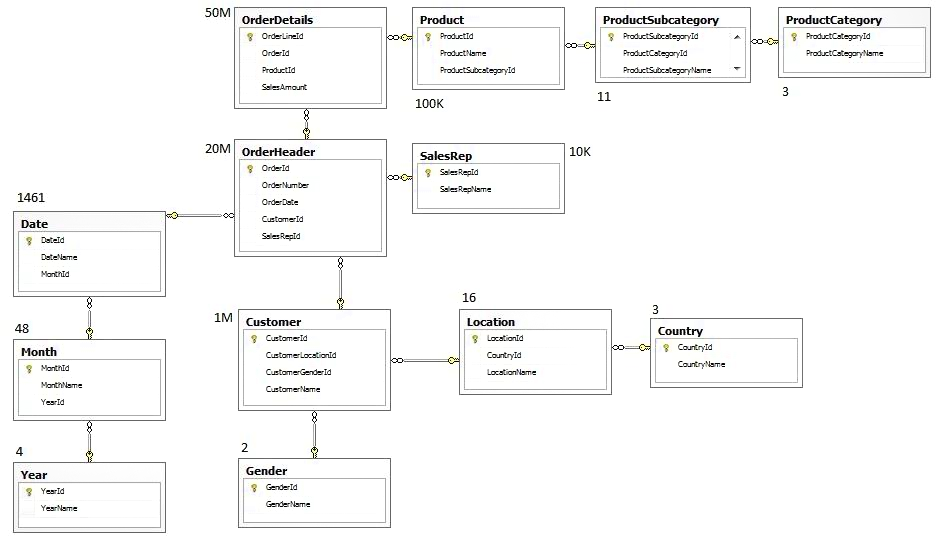
1.2.1、数据仓库架构图
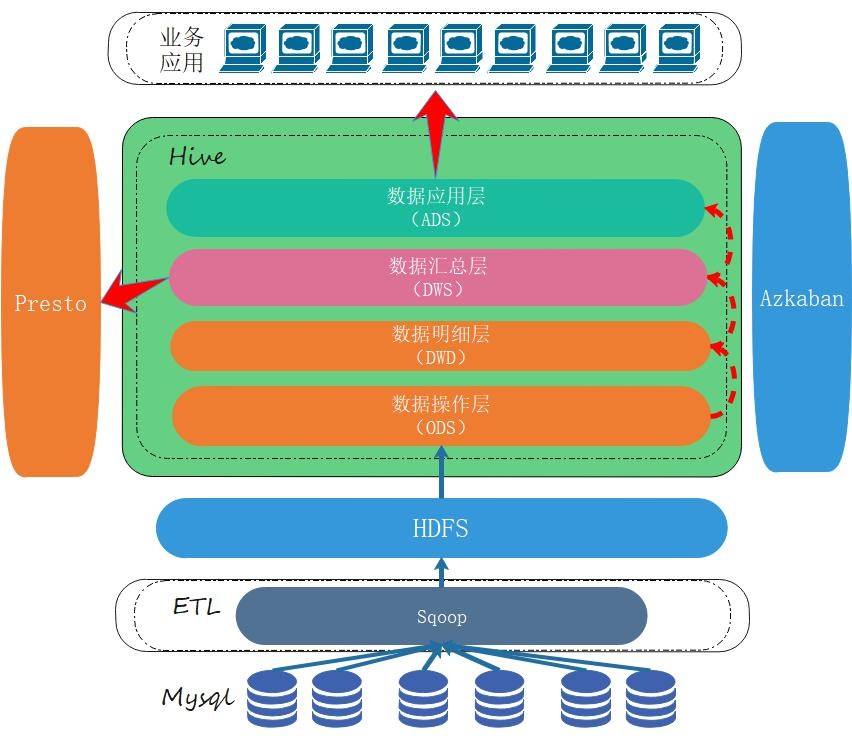
1.2.2、环境说明
操作系统及组件版本:
| CentOS | Hadoop | Hive | Tez | Mysql | Sqoop | Azkaban | Presto | yanagishima | |
|---|---|---|---|---|---|---|---|---|---|
| 版本 | 7.2 | 2.7.7 | 1.2.1 | 0.9.1 | 5.7.28 | 1.4.6 | 2.5.0 | 0.196 | 18.0 |
使用 3 台虚拟机进行搭建,粗体为软件集群主节点:
| Hadoop | Hive&Tez | Mysql | Sqoop | Azkaban | Presto | yanagishima | |
|---|---|---|---|---|---|---|---|
| node01 | yes | no | no | no | yes | yes | no |
| node02 | yes | no | yes | no | yes | yes | no |
| node03 | yes | yes | no | yes | yes | yes | yes |
1.2.3、组件安装
1.2.3.1、环境准备
- 在 windows 上使用 vmware workstation 安装 3 台 CentOS 7.2 虚拟机,配置好静态网络,可以上网;主机名命名为 node01、node02 和 node03;关闭 selinux、NetworkManager 和 firewalld 服务。
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux
yum remove NetworkManager-libnm firewalld -y
reboot- 下载自动化安装脚本 bigdata.git 到虚拟机 node01 中。
[root@node01 ~]# yum install git -y
[root@node01 ~]# git clone git@github.com:arm64v9/bigdata.git
[root@node01 ~]# cd bigdata/
[root@node01 bigdata]#
[root@node01 bigdata]# tree .
.
├── database.conf
├── frames
│ ├── apache-flume-1.7.0-bin.tar.gz
│ ├── apache-hive-1.2.1-bin.tar.gz
│ ├── apache-tez-0.9.1-bin.tar.gz
│ ├── azkaban-executor-server-2.5.0.tar.gz
│ ├── azkaban-sql-script-2.5.0.tar.gz
│ ├── azkaban-web-server-2.5.0.tar.gz
│ ├── hadoop-2.7.7.tar.gz
│ ├── jdk-8u144-linux-x64.tar.gz
│ ├── kafka_2.11-0.11.0.2.tgz
│ ├── lib
│ │ ├── hadoop-lzo-0.4.20.jar
│ │ ├── log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar
│ │ ├── mysql-connector-java-5.1.26-bin.jar
│ │ └── presto-cli-0.196-executable.jar
│ ├── mysql-libs.zip
│ ├── mysql-rpm-pack-5.7.28
│ │ ├── mysql-community-client-5.7.28-1.el7.x86_64.rpm
│ │ ├── mysql-community-common-5.7.28-1.el7.x86_64.rpm
│ │ ├── mysql-community-libs-5.7.28-1.el7.x86_64.rpm
│ │ └── mysql-community-server-5.7.28-1.el7.x86_64.rpm
│ ├── presto-server-0.196.tar.gz
│ ├── sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
│ ├── yanagishima-18.0.zip
│ └── zookeeper-3.4.10.tar.gz
├── frames.conf
├── hadoop
│ ├── azkabancode.sh
│ ├── hadoopcode.sh
│ ├── hivecode.sh
│ ├── mysqlcode.sh
│ ├── prestocode.sh
│ ├── sqoopcode.sh
│ ├── tezcode.sh
│ └── yanagishimacode.sh
├── initAllNodes.sh
├── initdir
│ ├── addClusterIps.sh
│ ├── configureJDK.sh
│ ├── initcode.sh
│ └── sshFreeLogin.sh
├── installAzkaban.sh
├── installHadoop.sh
├── installHive.sh
├── installMysql.sh
├── installPresto.sh
├── installSqoop.sh
├── installYanagishima.sh
├── iphosts.conf
├── mall-job.zip
├── mall-shell.zip
├── mall-sql.zip
├── mall-source.zip
└── README.md
5 directories, 49 files注意,项目整个目录结构如上所示,clone 下来的 frames 目录为空,因为 frames 里面全是软件包,体积过大。克隆好项目后,自行下载安装包放到 frames 下面,下载链接如下:
链接:https://pan.baidu.com/s/1cxBIP48mzUY-3RnwHi8Qcw
提取码:t0dy- 有 3 个配置文件需要修改一下,变成当前匹配的环境。
# 这个文件的作用是根据前面的规划,在哪个节点上安装该软件,或者哪个节点作为该软件集群主节点。
[root@node01 bigdata]# cat frames.conf
# 通用环境
jdk-8u144-linux-x64.tar.gz true
azkaban-sql-script-2.5.0.tar.gz true
# Node01
hadoop-2.7.7.tar.gz true node01
# Node02
mysql-rpm-pack-5.7.28 true node02
azkaban-executor-server-2.5.0.tar.gz true node02
azkaban-web-server-2.5.0.tar.gz true node02
presto-server-0.196.tar.gz true node02
# Node03
apache-hive-1.2.1-bin.tar.gz true node03
apache-tez-0.9.1-bin.tar.gz true node03
sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz true node03
yanagishima-18.0.zip true node03
# Muti
apache-flume-1.7.0-bin.tar.gz true node01,node02,node03
zookeeper-3.4.10.tar.gz true node01,node02,node03
kafka_2.11-0.11.0.2.tgz true node01,node02,node03# 这个文件列出所有节点的ip、主机名、用户名、密码,用作自动化脚本的配置文件
[root@node01 bigdata]# cat iphosts.conf
192.168.50.21 node01 root BigData#2022!
192.168.50.22 node02 root BigData#2022!
192.168.50.23 node03 root BigData#2022!# 数据库相关信息,用作自动化脚本操作数据库时的信息截取
[root@node01 bigdata]# cat database.conf
# Mysql相关配置
mysql-root-password BigData#2022! END
mysql-hive-password BigData#2022! END
mysql-drive mysql-connector-java-5.1.26-bin.jar END
# azkaban相关配置
azkaban-mysql-user root END
azkaban-mysql-password BigData#2022! END
azkaban-keystore-password BigData#2022! END1.2.3.2、初始化各节点
项目搭建过程把 node01 作为跳板机,如果没有特别说明,所有的操作都在 node01 上进行。
[root@node01 bigdata]# bash initAllNodes.sh该脚本的作用:
- 各节点之间可以免密钥登陆。
- 所有节点安装 unzip、expect 等必要工具。
- 所有节点安装 java JDK 环境。
- 分发自动化脚本到所有节点。
1.2.3.3、安装 hadoop
- 直接执行以下脚本,hadoop 会安装在所有节点,并根据前期规划,node01 成为主节点,node02、node03 为从节点。
[root@node01 bigdata]# bash installHadoop.sh- 3 个节点都执行 source 命令,重新加载环境变量。
[root@node01 ~]# source /etc/profile
[root@node02 ~]# source /etc/profile
[root@node03 ~]# source /etc/profile- 在 node01 hadoop 主节点上操作启动 hadoop 集群。
[root@node01 ~]# hdfs namenode -format
[root@node01 ~]# start-all.sh- 3 个节点上验证一下 hadoop 是否如下所示,代表集群启动正常。
[root@node01 ~]# jps
1655 SecondaryNameNode
2199 Jps
1497 DataNode
1371 NameNode
1947 NodeManager
1806 ResourceManager
[root@node02 ~]# jps
1416 Jps
1210 DataNode
1311 NodeManager
[root@node03 ~]# jps
1217 DataNode
1318 NodeManager
1423 Jps1.2.3.4、安装 mysql
直接执行以下脚本,根据前期软件分布设计,mysql 安装在 node02 节点;实际上该脚本在 3 个节点上都会执行一次,只是通过 frames.conf 配置文件进行代码判断,node01、node03 都不是规划的节点,所以略过安装。
[root@node01 bigdata]# bash installMysql.sh-
脚本在安装完 mysql 后,会创建一些后期用到的数据库,比如 azkaban,hive 等,并且创建关联数据库的用户及权限。
-
注意,database.conf 配置文件中的预设密码会被该脚本用来修改 mysql 的默认密码,所以后期访问 mysql 需要使用前期预设的这个密码。
1.2.3.5、安装 hive
- 直接执行以下脚本,根据前期软件分布设计,hive 会安装在 node03 节点,同时也会安装 hive 引擎 tez。
[root@node01 bigdata]# bash installHive.sh
Hive不允许被安装在 node01 节点
Hive不允许被安装在 node02 节点
开始解压hive安装包
hive安装包解压完毕
开始配置Hive Thrift服务
开始安装Tez服务
开始解压tez安装包
tez安装包解压完毕
Tez安装成功
--------------------
| Hive安装成功! |
--------------------
Hive服务启动命令: hive
为Presto开启Hive元数据服务命令: hive --service hiveserver2 &
为Presto开启Hive元数据服务命令: hive --service metastore &
Hive将运行在Tez引擎之上- 在 node03 节点上执行以下操作。
[root@node03 ~]# source /etc/profile
[root@node03 ~]# hive --service hiveserver2 &
[root@node03 ~]# hive --service metastore &1.2.3.6、安装 sqoop
- 直接执行以下脚本,根据前期软件分布设计,sqoop 会安装在 node03 节点
[root@node01 bigdata]# bash installSqoop.sh
Sqoop不允许被安装在 node01 节点
Sqoop不允许被安装在 node02 节点
开始解压sqoop安装包
sqoop安装包解压完毕
--------------------
| Sqoop安装成功! |
--------------------- 在 node03 节点执行以下操作
[root@node03 ~]# source /etc/profile1.2.3.7、安装 presto
Presto 是一种用于大数据的高性能分布式 SQL 查询引擎。其架构允许用户查询各种数据源,如 Hadoop、AWS S3、Alluxio、MySQL、Cassandra、Kafka 和 MongoDB。甚至可以在单个查询中查询来自多个数据源的数据。
- 直接执行以下脚本,根据前期软件分布设计,presto 会安装在 3 个节点上,并且 node02 为主节点。
# 3个节点都安装完成
[root@node01 bigdata]# bash installPresto.sh
开始解压presto安装包
presto安装包解压完毕
--------------------
| Presto安装成功! |
--------------------
Presto服务端口为:8080
开始解压presto安装包
presto安装包解压完毕
--------------------
| Presto安装成功! |
--------------------
Presto服务端口为:8080
开始解压presto安装包
presto安装包解压完毕
--------------------
| Presto安装成功! |
--------------------
Presto服务端口为:8080- 安装 presto 可视化插件 yanagishima,根据前期软件分布设计,yanagishima 安装在 node03 节点。
[root@node01 bigdata]# bash installYanagishima.sh
yanagishima不允许被安装在 node01 节点
yanagishima不允许被安装在 node02 节点
开始解压yanagishima安装包
yanagishima安装包解压完毕
-----------------------
| yanagishima安装成功! |
-----------------------
yanagishima服务端口为:70801.2.3.8、安装 azkaban
Azkaban 是由 Linkedin 开源的一个批量工作流任务调度器。 用于在一个工作流内以一个特定的顺序运行一组工作和流程。 Azkaban 定义了一种 KV 文件格式来建立任务之间的依赖关系,并提供一个易于使用的 web 用户界面维护和跟踪你的工作流。
- 直接执行以下脚本,根据前期软件分布设计,azkaban 会安装在 3 个节点上,并且 node02 为主节点。
[root@node01 bigdata]# bash installAzkaban.sh- 在 3 个节点上执行以下命令。
[root@node01 ~]# source /etc/profile
[root@node02 ~]# source /etc/profile
[root@node03 ~]# source /etc/profile到这里,一个简化的大数据开发平台已经搭建好了,下面要进行大数据开发。
1.3、项目开发
1.3.1、生成数据
在项目搭建之初我们把项目背景、核心数据框架以及通过开发达到想要的目的都已经介绍了一遍,可以回头看看,不再赘述,直接进入源数据生成环节。在 node02 mysql 节点操作。
- 创建数据库 mall。
[root@node02 ~]# export MYSQL_PWD=BigData#2022!
[root@node02 ~]# mysql -uroot -e "create database mall;"
[root@node02 ~]# mysql -uroot -e "show databases;"
+--------------------+
| Database |
+--------------------+
| information_schema |
| azkaban |
| hive |
| mall |
| mysql |
| performance_schema |
| sys |
+--------------------+- 使用预先写好的 sql 脚本进行如下操作,导入数据。
[root@node02 ~]# cd /opt/bigdata/
[root@node02 bigdata]# mkdir dev/warehouse -p
[root@node02 bigdata]# unzip mall-source.zip -d dev/warehouse/
Archive: mall-source.zip
creating: dev/warehouse/mall-source/
inflating: dev/warehouse/mall-source/1建表脚本.sql
inflating: dev/warehouse/mall-source/2商品分类数据插入脚本.sql
inflating: dev/warehouse/mall-source/3函数脚本.sql
inflating: dev/warehouse/mall-source/4存储过程脚本.sql
[root@node02 bigdata]# cd dev/warehouse/mall-source/
[root@node02 mall-source]# export MYSQL_PWD=BigData#2022!
[root@node02 mall-source]# mysql -uroot mall < 1建表脚本.sql
[root@node02 mall-source]# mysql -uroot mall < 2商品分类数据插入脚本.sql
[root@node02 mall-source]# mysql -uroot mall < 3函数脚本.sql
[root@node02 mall-source]# mysql -uroot mall < 4存储过程脚本.sql执行完上面 4 个 sql 语句后,我们来看一下 mall 数据库有哪些表,有哪些数据,便于后面做数据分析:
[root@node02 ~]# export MYSQL_PWD=BigData#2022!
[root@node02 ~]# mysql -uroot
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 50
Server version: 5.7.28 MySQL Community Server (GPL)
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> use mall;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+----------------+
| Tables_in_mall |
+----------------+
| base_category1 |
| base_category2 |
| base_category3 |
| order_detail |
| order_info |
| payment_info |
| sku_info |
| user_info |
+----------------+
8 rows in set (0.00 sec)
mysql> select count(*) from base_category1;
+----------+
| count(*) |
+----------+
| 18 |
+----------+
1 row in set (0.00 sec)
mysql> select * from base_category1 limit 2;
+----+--------------------------------+
| id | name |
+----+--------------------------------+
| 1 | 图书、音像、电子书刊 |
| 2 | 手机 |
+----+--------------------------------+
2 rows in set (0.00 sec)
mysql>- 通过这种查询方式,可以确定目前只有 base_category1、base_category2、base_category3 三张表有数据,其它表都为空。
- 使用预定义好的存储过程批量生成数据。
# 生成日期2022-04-04日数据、订单300个、用户200个、商品sku300个、不删除数据
mysql> use mall;
Database changed
mysql> CALL init_data('2022-04-04',300,200,300,FALSE);
Query OK, 0 rows affected (0.50 sec)
mysql> show tables;
+----------------+
| Tables_in_mall |
+----------------+
| base_category1 |
| base_category2 |
| base_category3 |
| order_detail |
| order_info |
| payment_info |
| sku_info |
| user_info |
+----------------+
8 rows in set (0.00 sec)
mysql> select count(*) from order_detail;
+----------+
| count(*) |
+----------+
| 899 |
+----------+
1 row in set (0.00 sec)
mysql> select * from order_detail limit 2;
+-------+----------+--------+------------+-------------------------------------------------+-------------+---------+
| id | order_id | sku_id | sku_name | img_url | order_price | sku_num |
+-------+----------+--------+------------+-------------------------------------------------+-------------+---------+
| 55750 | 1 | 226 | AnRsnmxBpW | http://KNLolnJrSmFsXIzwJiNofLpqHrLEPlJPVkpQkBeR | 4792.00 | 2 |
| 55751 | 2 | 80 | voiYtYKFVN | http://cYJCHFgPECavbUtjQzcMEJJhOAkzPDyFEieTilDk | 1385.00 | 4 |
+-------+----------+--------+------------+-------------------------------------------------+-------------+---------+
2 rows in set (0.00 sec)
mysql>通过调用过程,刚才为空的所有表都已填充数据,可以使用 select 语句查询了解一下,做到心中有数。
1.3.2、ETL 操作
在项目搭建之初,我放了一张数据仓库架构图,回头去对照看一眼。刚才是在 mysql 中生成数据,这个相当于企业中积压的大量源数据。
接下来按照架构图的规划,需要使用 sqoop 工具进行 ETL 操作,把 mysql 中的源数据经过代码操作(E: Extract抽取,T: Transform转换,L: Load加载),加载到 hadoop 分布式文件系统 HDFS 中。
- sqoop 工具安装在 node03 节点,所以在 node03 节点进行如下操作。
[root@node03 ~]# mkdir -p /home/warehouse/shell
[root@node03 ~]# cd /home/warehouse/shell
[root@node03 shell]#
[root@node03 shell]# vim sqoop_import.sh
#!/bin/bash
#
db_date=$2
echo $db_date
db_name=mall
import_data() {
sqoop import \
--connect jdbc:mysql://node02:3306/$db_name \
--username root \
--password BigData#2022! \
--target-dir /origin_data/$db_name/db/$1/$db_date \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query "$2"' and $CONDITIONS;'
}
import_sku_info() {
import_data "sku_info" "select
id, spu_id, price, sku_name, sku_desc, weight, tm_id,
category3_id, create_time from sku_info where 1=1"
}
import_user_info() {
import_data "user_info" "select id, name,
birthday, gender, email, user_level,
create_time from user_info where 1=1"
}
import_base_category1() {
import_data "base_category1" "select
id, name from base_category1 where 1=1"
}
import_base_category2() {
import_data "base_category2" "select
id, name, category1_id from base_category2 where 1=1"
}
import_base_category3() {
import_data "base_category3" "select
id, name, category2_id from base_category3 where 1=1"
}
import_order_detail() {
import_data "order_detail" "select
od.id, order_id, user_id, sku_id, sku_name, order_price,
sku_num, o.create_time from order_info o, order_detail od
where o.id=od.order_id
and DATE_FORMAT(create_time,'%Y-%m-%d')='$db_date'"
}
import_payment_info() {
import_data "payment_info" "select
id, out_trade_no, order_id, user_id, alipay_trade_no,
total_amount, subject, payment_type, payment_time
from payment_info
where DATE_FORMAT(payment_time,'%Y-%m-%d')='$db_date'"
}
import_order_info() {
import_data "order_info" "select
id, total_amount, order_status, user_id, payment_way,
out_trade_no, create_time, operate_time from order_info
where (DATE_FORMAT(create_time,'%Y-%m-%d')='$db_date'
or DATE_FORMAT(operate_time,'%Y-%m-%d')='$db_date')"
}
case $1 in
"base_category1")
import_base_category1;;
"base_category2")
import_base_category2;;
"base_category3")
import_base_category3;;
"order_info")
import_order_info;;
"order_detail")
import_order_detail;;
"sku_info")
import_sku_info;;
"user_info")
import_user_info;;
"payment_info")
import_payment_info;;
"all")
import_base_category1
import_base_category2
import_base_category3
import_order_info
import_order_detail
import_sku_info
import_user_info
import_payment_info;;
esac
[root@node03 shell]# bash sqoop_import.sh all 2022-04-04经过 sqoop 操作,mysql 中的数据已经抽取到 hdfs 中,可以通过如下方式查看。
-
验证:可以通过 node01 节点 http://192.168.95.21:50070/ 登陆查看 ETL 抽取是否成功。
Utilities --> Browse the file system --> /origin_data/mall/db 可以查看到有 8 张表抽取成功。
1.3.3、ODS 层创建&数据接入
回头对照看看数据仓库架构图的设计,ODS 数据操作层以后的数据处理都是在 hive 中进行的,但是 hive 中现在肯定是空的,需要把 hdfs 层的数据导入进来。我们的 hive 安装在 node03 节点,下面继续在 node03 节点操作。
- 启动 hive 元数据服务
[root@node03 ~]# hive --service hiveserver2 &
[root@node03 ~]# hive --service metastore &- 在 hive 中创建跟业务数据库一致的数据库和表,下面编写 ods_ddl.sql。
[root@node03 ~]# mkdir /home/warehouse/sql/ -p
[root@node03 ~]# cd /home/warehouse/sql/
[root@node03 sql]# vim ods_ddl.sql
-- 创建数据库
create database if not exists mall;
use mall;
-- 创建订单表
drop table if exists ods_order_info;
create table ods_order_info (
`id` string COMMENT '订单编号',
`total_amount` decimal(10,2) COMMENT '订单金额',
`order_status` string COMMENT '订单状态',
`user_id` string COMMENT '用户id' ,
`payment_way` string COMMENT '支付方式',
`out_trade_no` string COMMENT '支付流水号',
`create_time` string COMMENT '创建时间',
`operate_time` string COMMENT '操作时间'
) COMMENT '订单表'
PARTITIONED BY ( `dt` string)
row format delimited fields terminated by '\t'
location '/warehouse/mall/ods/ods_order_info/'
tblproperties ("parquet.compression"="snappy")
;
-- 创建订单详情表
drop table if exists ods_order_detail;
create table ods_order_detail (
`id` string COMMENT '订单编号',
`order_id` string COMMENT '订单号',
`user_id` string COMMENT '用户id' ,
`sku_id` string COMMENT '商品id',
`sku_name` string COMMENT '商品名称',
`order_price` string COMMENT '下单价格',
`sku_num` string COMMENT '商品数量',
`create_time` string COMMENT '创建时间'
) COMMENT '订单明细表'
PARTITIONED BY ( `dt` string)
row format delimited fields terminated by '\t'
location '/warehouse/mall/ods/ods_order_detail/'
tblproperties ("parquet.compression"="snappy")
;
-- 创建商品表
drop table if exists ods_sku_info;
create table ods_sku_info (
`id` string COMMENT 'skuId',
`spu_id` string COMMENT 'spuid',
`price` decimal(10,2) COMMENT '价格' ,
`sku_name` string COMMENT '商品名称',
`sku_desc` string COMMENT '商品描述',
`weight` string COMMENT '重量',
`tm_id` string COMMENT '品牌id',
`category3_id` string COMMENT '品类id',
`create_time` string COMMENT '创建时间'
) COMMENT '商品表'
PARTITIONED BY ( `dt` string)
row format delimited fields terminated by '\t'
location '/warehouse/mall/ods/ods_sku_info/'
tblproperties ("parquet.compression"="snappy")
;
-- 创建用户表
drop table if exists ods_user_info;
create table ods_user_info (
`id` string COMMENT '用户id',
`name` string COMMENT '姓名',
`birthday` string COMMENT '生日' ,
`gender` string COMMENT '性别',
`email` string COMMENT '邮箱',
`user_level` string COMMENT '用户等级',
`create_time` string COMMENT '创建时间'
) COMMENT '用户信息'
PARTITIONED BY ( `dt` string)
row format delimited fields terminated by '\t'
location '/warehouse/mall/ods/ods_user_info/'
tblproperties ("parquet.compression"="snappy")
;
-- 创建商品一级分类表
drop table if exists ods_base_category1;
create table ods_base_category1 (
`id` string COMMENT 'id',
`name` string COMMENT '名称'
) COMMENT '商品一级分类'
PARTITIONED BY ( `dt` string)
row format delimited fields terminated by '\t'
location '/warehouse/mall/ods/ods_base_category1/'
tblproperties ("parquet.compression"="snappy")
;
-- 创建商品二级分类表
drop table if exists ods_base_category2;
create external table ods_base_category2 (
`id` string COMMENT ' id',
`name` string COMMENT '名称',
category1_id string COMMENT '一级品类id'
) COMMENT '商品二级分类'
PARTITIONED BY ( `dt` string)
row format delimited fields terminated by '\t'
location '/warehouse/mall/ods/ods_base_category2/'
tblproperties ("parquet.compression"="snappy")
;
-- 创建商品三级分类表
drop table if exists ods_base_category3;
create table ods_base_category3 (
`id` string COMMENT ' id',
`name` string COMMENT '名称',
category2_id string COMMENT '二级品类id'
) COMMENT '商品三级分类'
PARTITIONED BY ( `dt` string)
row format delimited fields terminated by '\t'
location '/warehouse/mall/ods/ods_base_category3/'
tblproperties ("parquet.compression"="snappy")
;
-- 创建支付流水表
drop table if exists `ods_payment_info`;
create table `ods_payment_info` (
`id` bigint COMMENT '编号',
`out_trade_no` string COMMENT '对外业务编号',
`order_id` string COMMENT '订单编号',
`user_id` string COMMENT '用户编号',
`alipay_trade_no` string COMMENT '支付宝交易流水编号',
`total_amount` decimal(16,2) COMMENT '支付金额',
`subject` string COMMENT '交易内容',
`payment_type` string COMMENT '支付类型',
`payment_time` string COMMENT '支付时间'
) COMMENT '支付流水表'
PARTITIONED BY ( `dt` string)
row format delimited fields terminated by '\t'
location '/warehouse/mall/ods/ods_payment_info/'
tblproperties ("parquet.compression"="snappy")
;- 将 ods_ddl.sql 导入到 Hive 中
[root@node03 sql]# hive -f ods_ddl.sql
# 验证是否倒入成功
[root@node03 sql]# hive
hive> show databases;
OK
default
mall
Time taken: 0.519 seconds, Fetched: 2 row(s)
hive> use mall;
OK
Time taken: 0.037 seconds
hive> show tables;
OK
ods_base_category1
ods_base_category2
ods_base_category3
ods_order_detail
ods_order_info
ods_payment_info
ods_sku_info
ods_user_info
Time taken: 0.031 seconds, Fetched: 8 row(s)
hive>- 上面的 sql 语句只是创建了数据库和表结构,但是并没有导入数据,下面编写 hive 语法脚本,将 hdfs 中的数据导入 hive 数据库表结构中。
# 进入脚本目录,编写脚本
[root@node03 ~]# cd /home/warehouse/shell/
[root@node03 shell]# vim ods_db.sh
#!/bin/bash
#
do_date=$1
APP=mall
hive=hive
sql="
load data inpath '/origin_data/$APP/db/order_info/$do_date' OVERWRITE into table $APP"".ods_order_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/order_detail/$do_date' OVERWRITE into table $APP"".ods_order_detail partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/sku_info/$do_date' OVERWRITE into table $APP"".ods_sku_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/user_info/$do_date' OVERWRITE into table $APP"".ods_user_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/payment_info/$do_date' OVERWRITE into table $APP"".ods_payment_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/base_category1/$do_date' OVERWRITE into table $APP"".ods_base_category1 partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/base_category2/$do_date' OVERWRITE into table $APP"".ods_base_category2 partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/base_category3/$do_date' OVERWRITE into table $APP"".ods_base_category3 partition(dt='$do_date');
"
$hive -e "$sql"
# 执行脚本
[root@node03 shell]# bash ods_db.sh 2022-04-04
# 验证数据是否导入成功
[root@node03 shell]# hive
hive> use mall;
OK
Time taken: 0.449 seconds
hive> select * from ods_sku_info limit 2;
OK
1001 383 4709 DYjaAAcLvVpPebSkwEFo FjdRYqLFVLUrXMRXpHsOQPzfdbXIvg 2.22 54 2584 2022-04-04 23:46:50.0 2022-04-04
1002 654 1507 CPuCBbCHFdBxJaadolmA TTKUraabiLftCJzCoNWukOrsORQFBT 4.15 40 2724 2022-04-04 07:43:53.0 2022-04-04
Time taken: 0.326 seconds, Fetched: 2 row(s)
hive>1.3.4、DWD 层创建&数据接入
再回头对照看一下数据仓库架构图,ODS 再上一层就是 DWD 数据明细层,对 ODS 层数据进行清洗、维度退化。
接下来继续在 node03 上进行操作,操作思路跟 ODS 层类似。
- 在 /home/warehouse/sql 目录下编写 dwd_ddl.sql,创建 DWD 层数据表。
[root@node03 ~]# cd /home/warehouse/sql/
[root@node03 sql]# vim dwd_ddl.sql
-- 进入数据库
use mall;
-- 创建订单表
drop table if exists dwd_order_info;
create external table dwd_order_info (
`id` string COMMENT '',
`total_amount` decimal(10,2) COMMENT '',
`order_status` string COMMENT ' 1 2 3 4 5',
`user_id` string COMMENT 'id' ,
`payment_way` string COMMENT '',
`out_trade_no` string COMMENT '',
`create_time` string COMMENT '',
`operate_time` string COMMENT ''
) COMMENT ''
PARTITIONED BY ( `dt` string)
stored as parquet
location '/warehouse/mall/dwd/dwd_order_info/'
tblproperties ("parquet.compression"="snappy")
;
-- 创建订单详情表
drop table if exists dwd_order_detail;
create external table dwd_order_detail(
`id` string COMMENT '',
`order_id` decimal(10,2) COMMENT '',
`user_id` string COMMENT 'id' ,
`sku_id` string COMMENT 'id',
`sku_name` string COMMENT '',
`order_price` string COMMENT '',
`sku_num` string COMMENT '',
`create_time` string COMMENT ''
) COMMENT ''
PARTITIONED BY ( `dt` string)
stored as parquet
location '/warehouse/mall/dwd/dwd_order_detail/'
tblproperties ("parquet.compression"="snappy")
;
-- 创建用户表
drop table if exists dwd_user_info;
create external table dwd_user_info(
`id` string COMMENT 'id',
`name` string COMMENT '',
`birthday` string COMMENT '' ,
`gender` string COMMENT '',
`email` string COMMENT '',
`user_level` string COMMENT '',
`create_time` string COMMENT ''
) COMMENT ''
PARTITIONED BY ( `dt` string)
stored as parquet
location '/warehouse/mall/dwd/dwd_user_info/'
tblproperties ("parquet.compression"="snappy")
;
-- 创建支付流水表
drop table if exists `dwd_payment_info`;
create external table `dwd_payment_info`(
`id` bigint COMMENT '',
`out_trade_no` string COMMENT '',
`order_id` string COMMENT '',
`user_id` string COMMENT '',
`alipay_trade_no` string COMMENT '',
`total_amount` decimal(16,2) COMMENT '',
`subject` string COMMENT '',
`payment_type` string COMMENT '',
`payment_time` string COMMENT ''
) COMMENT ''
PARTITIONED BY ( `dt` string)
stored as parquet
location '/warehouse/mall/dwd/dwd_payment_info/'
tblproperties ("parquet.compression"="snappy")
;
-- 创建商品表(增加分类)
drop table if exists dwd_sku_info;
create external table dwd_sku_info(
`id` string COMMENT 'skuId',
`spu_id` string COMMENT 'spuid',
`price` decimal(10,2) COMMENT '' ,
`sku_name` string COMMENT '',
`sku_desc` string COMMENT '',
`weight` string COMMENT '',
`tm_id` string COMMENT 'id',
`category3_id` string COMMENT '1id',
`category2_id` string COMMENT '2id',
`category1_id` string COMMENT '3id',
`category3_name` string COMMENT '3',
`category2_name` string COMMENT '2',
`category1_name` string COMMENT '1',
`create_time` string COMMENT ''
) COMMENT ''
PARTITIONED BY ( `dt` string)
stored as parquet
location '/warehouse/mall/dwd/dwd_sku_info/'
tblproperties ("parquet.compression"="snappy")
;- 将 dwd_ddl.sql 导入到 Hive 中。
[root@node03 sql]# hive -f dwd_ddl.sql- 在 /home/warehouse/shell 目录下编写 dwd_db.sh 脚本,完成数据导入操作。
# 进入脚本目录,编写数据处理脚本
[root@node03 ~]# cd /home/warehouse/shell/
[root@node03 shell]# vim dwd_db.sh
#!/bin/bash
# 定义变量方便修改
APP=mall
hive=hive
# 如果是输入的日期,按照输入日期;如果没输入日期,用当前时间的前一天
if [ -n $1 ] ;then
log_date=$1
else
log_date=`date -d "-1 day" +%F`
fi
sql="
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table "$APP".dwd_order_info partition(dt)
select * from "$APP".ods_order_info
where dt='$log_date' and id is not null;
insert overwrite table "$APP".dwd_order_detail partition(dt)
select * from "$APP".ods_order_detail
where dt='$log_date' and id is not null;
insert overwrite table "$APP".dwd_user_info partition(dt)
select * from "$APP".ods_user_info
where dt='$log_date' and id is not null;
insert overwrite table "$APP".dwd_payment_info partition(dt)
select * from "$APP".ods_payment_info
where dt='$log_date' and id is not null;
insert overwrite table "$APP".dwd_sku_info partition(dt)
select
sku.id,
sku.spu_id,
sku.price,
sku.sku_name,
sku.sku_desc,
sku.weight,
sku.tm_id,
sku.category3_id,
c2.id category2_id ,
c1.id category1_id,
c3.name category3_name,
c2.name category2_name,
c1.name category1_name,
sku.create_time,
sku.dt
from
"$APP".ods_sku_info sku
join "$APP".ods_base_category3 c3 on sku.category3_id=c3.id
join "$APP".ods_base_category2 c2 on c3.category2_id=c2.id
join "$APP".ods_base_category1 c1 on c2.category1_id=c1.id
where sku.dt='$log_date' and c2.dt='$log_date'
and c3.dt='$log_date' and c1.dt='$log_date'
and sku.id is not null;
"
$hive -e "$sql"
# 执行脚本
[root@node03 shell]# bash dwd_db.sh 2022-04-04
# 查看数据是否处理成功
[root@node03 shell]# hive
hive> use mall;
OK
Time taken: 0.439 seconds
hive>
> select * from dwd_sku_info where dt='2022-04-04' limit 2;
OK
1007 181 306 NFLQUbxjBfYzExzgjyQH RlEnBSLaTskUUMddkMfruVtjNlSFwu 3.60 25 687 68 12 婴儿床垫 童车童床 母婴 2022-04-04 14:45:05.0 2022-04-04
1012 775 4244 VcxjAaBEtdogSSKXKFVN dcdhCoNXAKXJqLFVMWyBlDfTeNCyLi 3.50 84 958 101 16 座垫 汽车装饰 汽车用品 2022-04-04 16:12:20.0 2022-04-04
Time taken: 0.084 seconds, Fetched: 2 row(s)1.3.5、DWS 层创建&数据接入
到了 DWS 数据服务层,也叫数据汇总层,顾名思义,就是将具有相同分析主题的 DWD 层数据,聚合成宽表模型,便于数据分析与计算。主题的归纳具有通用性,后续也可能会随着分析业务的增加而扩展。
继续在 node03 节点进行操作。
- 在 /home/warehouse/sql 目录下编写 dws_ddl.sql,创建 DWS 层数据表。
[root@node03 ~]# cd /home/warehouse/sql/
[root@node03 sql]# vim dws_ddl.sql
-- 进入数据库
use mall;
-- 创建用户行为宽表
drop table if exists dws_user_action;
create external table dws_user_action
(
user_id string comment '用户 id',
order_count bigint comment '下单次数 ',
order_amount decimal(16,2) comment '下单金额 ',
payment_count bigint comment '支付次数',
payment_amount decimal(16,2) comment '支付金额 '
) COMMENT '每日用户行为宽表'
PARTITIONED BY ( `dt` string)
stored as parquet
location '/warehouse/mall/dws/dws_user_action/'
tblproperties ("parquet.compression"="snappy");
-- 创建用户购买商品明细表
drop table if exists dws_sale_detail_daycount;
create external table dws_sale_detail_daycount
( user_id string comment '用户 id',
sku_id string comment '商品 Id',
user_gender string comment '用户性别',
user_age string comment '用户年龄',
user_level string comment '用户等级',
order_price decimal(10,2) comment '订单价格',
sku_name string comment '商品名称',
sku_tm_id string comment '品牌id',
sku_category3_id string comment '商品三级品类id',
sku_category2_id string comment '商品二级品类id',
sku_category1_id string comment '商品一级品类id',
sku_category3_name string comment '商品三级品类名称',
sku_category2_name string comment '商品二级品类名称',
sku_category1_name string comment '商品一级品类名称',
spu_id string comment '商品 spu',
sku_num int comment '购买个数',
order_count string comment '当日下单单数',
order_amount string comment '当日下单金额'
) COMMENT '用户购买商品明细表'
PARTITIONED BY ( `dt` string)
stored as parquet
location '/warehouse/mall/dws/dws_user_sale_detail_daycount/'
tblproperties ("parquet.compression"="snappy");- 将 dws_ddl.sql 导入到 Hive 中
[root@node03 sql]# hive -f dws_ddl.sql- 在 /home/warehouse/shell 目录下编写 dws_db.sh 脚本,完成数据导入操作。
# 进入脚本目录,编写数据处理脚本
[root@node03 ~]# cd /home/warehouse/shell/
[root@node03 shell]# vim dws_db.sh
#!/bin/bash
# 定义变量方便修改
APP=mall
hive=hive
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n $1 ] ;then
log_date=$1
else
log_date=`date -d "-1 day" +%F`
fi
# 用户行为宽表
function user_actions()
{
# 定义变量
APP=$1
hive=$2
log_date=$3
sql="
with
tmp_order as
(
select
user_id,
sum(oc.total_amount) order_amount,
count(*) order_count
from "$APP".dwd_order_info oc
where date_format(oc.create_time,'yyyy-MM-dd')='$log_date'
group by user_id
),
tmp_payment as
(
select
user_id,
sum(pi.total_amount) payment_amount,
count(*) payment_count
from "$APP".dwd_payment_info pi
where date_format(pi.payment_time,'yyyy-MM-dd')='$log_date'
group by user_id
)
insert overwrite table "$APP".dws_user_action partition(dt='$log_date')
select
user_actions.user_id,
sum(user_actions.order_count),
sum(user_actions.order_amount),
sum(user_actions.payment_count),
sum(user_actions.payment_amount)
from
(
select
user_id,
order_count,
order_amount ,
0 payment_count ,
0 payment_amount
from tmp_order
union all
select
user_id,
0,
0,
payment_count,
payment_amount
from tmp_payment
) user_actions
group by user_id;
"
$hive -e "$sql"
}
function user_sales()
{
# 定义变量
APP=$1
hive=$2
log_date=$3
sql="
set hive.exec.dynamic.partition.mode=nonstrict;
with
tmp_detail as
(
select
user_id,
sku_id,
sum(sku_num) sku_num ,
count(*) order_count ,
sum(od.order_price*sku_num) order_amount
from "$APP".dwd_order_detail od
where od.dt='$log_date' and user_id is not null
group by user_id, sku_id
)
insert overwrite table "$APP".dws_sale_detail_daycount partition(dt='$log_date')
select
tmp_detail.user_id,
tmp_detail.sku_id,
u.gender,
months_between('$log_date', u.birthday)/12 age,
u.user_level,
price,
sku_name,
tm_id,
category3_id ,
category2_id ,
category1_id ,
category3_name ,
category2_name ,
category1_name ,
spu_id,
tmp_detail.sku_num,
tmp_detail.order_count,
tmp_detail.order_amount
from tmp_detail
left join "$APP".dwd_user_info u
on u.id=tmp_detail.user_id and u.dt='$log_date'
left join "$APP".dwd_sku_info s on tmp_detail.sku_id =s.id and s.dt='$log_date';
"
$hive -e "$sql"
}
user_actions $APP $hive $log_date
user_sales $APP $hive $log_date
# 执行脚本
[root@node03 shell]# bash dws_db.sh 2022-04-04
# 验证数据处理结果
[root@node03 shell]# hive
hive> use mall;
OK
Time taken: 0.467 seconds
hive> select * from dws_user_action where dt='2022-04-04' limit 2;
OK
1 2 1274 0 0 2022-04-04
10 2 383 2 383 2022-04-04
Time taken: 0.068 seconds, Fetched: 2 row(s)
hive> select * from dws_sale_detail_daycount where dt='2022-04-04' limit 2;
OK
1 211 NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL 5 1 13140.0 2022-04-04
1 50 NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL 5 1 16365.0 2022-04-04
Time taken: 0.087 seconds, Fetched: 2 row(s)- 发现 dws_sale_detail_daycount 这个宽表很多都是 NULL,哪里有 bug,还没有找出来。
1.3.6、ADS 层创建&数据接入
按照数据仓库架构图设计,最后的 ADS 应用数据服务层,用来为数据产品提供清晰准确的数字依据。我们这个项目是要统计各个一级品类下,品牌月单次复购率,和多次复购率。
继续在 node03 上进行如下操作。
- 在 /home/warehouse/sql 目录下编写 ads_sale_ddl.sql,创建 DWS 层数据表。
[root@node03 ~]# cd /home/warehouse/sql/
[root@node03 sql]# vim ads_sale_ddl.sql
-- 进入数据库
use mall;
-- 创建品牌复购率表
drop table ads_sale_tm_category1_stat_mn;
create table ads_sale_tm_category1_stat_mn
(
tm_id string comment '品牌id ' ,
category1_id string comment '1级品类id ',
category1_name string comment '1级品类名称 ',
buycount bigint comment '购买人数',
buy_twice_last bigint comment '两次以上购买人数',
buy_twice_last_ratio decimal(10,2) comment '单次复购率',
buy_3times_last bigint comment '三次以上购买人数',
buy_3times_last_ratio decimal(10,2) comment '多次复购率' ,
stat_mn string comment '统计月份',
stat_date string comment '统计日期'
) COMMENT '复购率统计'
row format delimited fields terminated by '\t'
location '/warehouse/mall/ads/ads_sale_tm_category1_stat_mn/'
;- 将 ads_sale_ddl.sql 导入到 Hive 中。
[root@node03 sql]# hive -f ads_sale_ddl.sql- 在 /home/warehouse/shell 目录下编写 ads_sale.sh 脚本,完成数据导入操作。
[root@node03 ~]# cd /home/warehouse/shell/
[root@node03 shell]# vim ads_sale.sh
#!/bin/bash
# 定义变量方便修改
APP=mall
hive=hive
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n $1 ] ;then
log_date=$1
else
log_date=`date -d "-1 day" +%F`
fi
sql="
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table "$APP".ads_sale_tm_category1_stat_mn
select
mn.sku_tm_id,
mn.sku_category1_id,
mn.sku_category1_name,
sum(if(mn.order_count>=1,1,0)) buycount,
sum(if(mn.order_count>=2,1,0)) buyTwiceLast,
sum(if(mn.order_count>=2,1,0))/sum( if(mn.order_count>=1,1,0)) buyTwiceLastRatio,
sum(if(mn.order_count>3,1,0)) buy3timeLast ,
sum(if(mn.order_count>=3,1,0))/sum( if(mn.order_count>=1,1,0)) buy3timeLastRatio ,
date_format('$log_date' ,'yyyy-MM') stat_mn,
'$log_date' stat_date
from
(
select od.sku_tm_id,
od.sku_category1_id,
od.sku_category1_name,
user_id ,
sum(order_count) order_count
from "$APP".dws_sale_detail_daycount od
where date_format(dt,'yyyy-MM')<=date_format('$log_date' ,'yyyy-MM')
group by od.sku_tm_id, od.sku_category1_id, od.sku_category1_name, user_id
) mn
group by mn.sku_tm_id, mn.sku_category1_id, mn.sku_category1_name;
"
$hive -e "$sql"
[root@node03 shell]# bash ads_sale.sh 2022-04-04
[root@node03 shell]# hive
hive> use mall;
OK
Time taken: 0.454 seconds
hive> select * from ads_sale_tm_category1_stat_mn limit 2;
OK
NULL NULL NULL 157 138 0.88 98 0.77 2022-04 2022-04-04
Time taken: 0.304 seconds, Fetched: 1 row(s)
hive>1.3.7、ADS 层数据导出
通过上面的步骤 ADS 应用数据服务表 ads_sale_tm_category1_stat_mn 已生成并存在于 hive 中,为了方面查询,下面把 hive 中的 ads_sale_tm_category1_stat_mn 表数据导入到 node02 节点上的 mysql 数据库中。
还是在 node03 节点上操作,远程连接 node02 上的数据库。
- 在 /home/warehouse/sql 目录下编写 mysql_sale_ddl.sql,创建数据表。
[root@node03 ~]# cd /home/warehouse/sql/
[root@node03 sql]# vim mysql_sale_ddl.sql
-- 进入数据库
use mall;
-- 创建复购率表
create table ads_sale_tm_category1_stat_mn
(
tm_id varchar(200) comment '品牌id ' ,
category1_id varchar(200) comment '1级品类id ',
category1_name varchar(200) comment '1级品类名称 ',
buycount varchar(200) comment '购买人数',
buy_twice_last varchar(200) comment '两次以上购买人数',
buy_twice_last_ratio varchar(200) comment '单次复购率',
buy_3times_last varchar(200) comment '三次以上购买人数',
buy_3times_last_ratio varchar(200) comment '多次复购率' ,
stat_mn varchar(200) comment '统计月份',
stat_date varchar(200) comment '统计日期'
)- 在 node03 节点上通过远程连接数据库 node02 节点,导入 mysql_sale_ddl.sql 表结构。
# 安装mysql客户端
[root@node03 sql]# yum install mysql -y
[root@node03 sql]# export MYSQL_PWD=BigData#2022!
[root@node03 sql]# mysql -uroot mall -hnode02 < mysql_sale_ddl.sql
# 验证一下表是否创建
[root@node03 sql]# mysql -hnode02 -uroot
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 103
Server version: 5.7.28 MySQL Community Server (GPL)
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MySQL [(none)]> use mall;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
MySQL [mall]> desc ads_sale_tm_category1_stat_mn;
+-----------------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------------+--------------+------+-----+---------+-------+
| tm_id | varchar(200) | YES | | NULL | |
| category1_id | varchar(200) | YES | | NULL | |
| category1_name | varchar(200) | YES | | NULL | |
| buycount | varchar(200) | YES | | NULL | |
| buy_twice_last | varchar(200) | YES | | NULL | |
| buy_twice_last_ratio | varchar(200) | YES | | NULL | |
| buy_3times_last | varchar(200) | YES | | NULL | |
| buy_3times_last_ratio | varchar(200) | YES | | NULL | |
| stat_mn | varchar(200) | YES | | NULL | |
| stat_date | varchar(200) | YES | | NULL | |
+-----------------------+--------------+------+-----+---------+-------+
10 rows in set (0.00 sec)
MySQL [mall]>- 在 /home/warehouse/shell 目录下编写 sqoop 导出脚本,完成数据转储操作。
[root@node03 ~]# cd /home/warehouse/shell/
[root@node03 shell]# vim sqoop_export.sh
#!/bin/bash
db_name=mall
export_data() {
sqoop export \
--connect "jdbc:mysql://node02:3306/${db_name}?useUnicode=true&characterEncoding=utf-8" \
--username root \
--password BigData#2022! \
--table $1 \
--num-mappers 1 \
--export-dir /warehouse/$db_name/ads/$1 \
--input-fields-terminated-by "\t" \
--update-key "tm_id,category1_id,stat_mn,stat_date" \
--update-mode allowinsert \
--input-null-string '\\N' \
--input-null-non-string '\\N'
}
case $1 in
"ads_sale_tm_category1_stat_mn")
export_data "ads_sale_tm_category1_stat_mn"
;;
"all")
export_data "ads_sale_tm_category1_stat_mn"
;;
esac
[root@node03 shell]# bash sqoop_export.sh all
# 验证一下数据转储是否成功
[root@node03 shell]# mysql -uroot -hnode02
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 109
Server version: 5.7.28 MySQL Community Server (GPL)
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MySQL [(none)]> use mall;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
MySQL [mall]> SELECT * FROM ads_sale_tm_category1_stat_mn;
+-------+--------------+----------------+----------+----------------+----------------------+-----------------+-----------------------+---------+------------+
| tm_id | category1_id | category1_name | buycount | buy_twice_last | buy_twice_last_ratio | buy_3times_last | buy_3times_last_ratio | stat_mn | stat_date |
+-------+--------------+----------------+----------+----------------+----------------------+-----------------+-----------------------+---------+------------+
| NULL | NULL | NULL | 157 | 138 | 0.88 | 98 | 0.77 | 2022-04 | 2022-04-04 |
+-------+--------------+----------------+----------+----------------+----------------------+-----------------+-----------------------+---------+------------+
1 row in set (0.00 sec)
MySQL [mall]>1.3.8、Azkaban 自动化调度
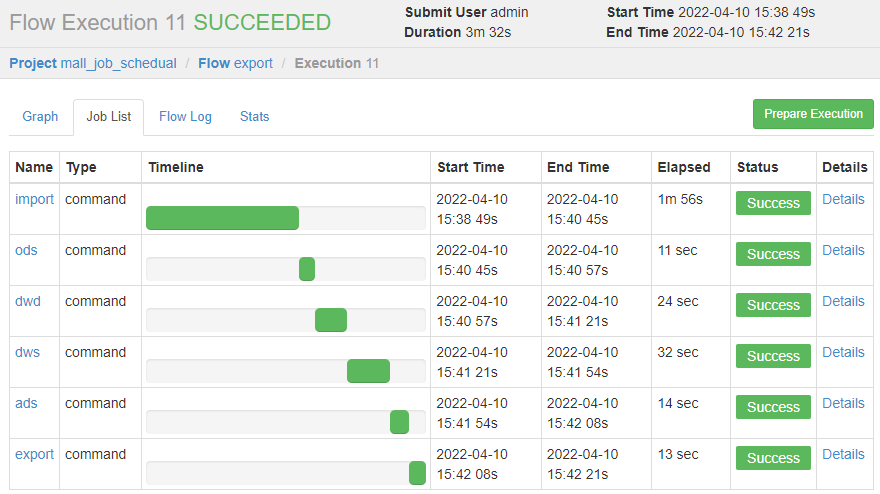
安装 azkaban 的时候,我们介绍了一下它的主要功能,可以回头看看,这里直接使用 azkaban 实现 job 的自动化调度任务。
- 在 node02 mysql 节点执行存储过程调用,生成 2022-04-05 日期的数据,相当于在上面开发过程 2022-04-04 日期的数据基础上进行了企业生产数据新增。
[root@node02 ~]# export MYSQL_PWD=BigData#2022!
[root@node02 ~]# mysql -uroot
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 113
Server version: 5.7.28 MySQL Community Server (GPL)
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> use mall;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> CALL init_data('2022-04-05',300,200,300,FALSE);
Query OK, 0 rows affected (0.52 sec)
mysql>- 编写 azkaban 要运行的 job,并打包成 mall-job.zip 文件。
无论在哪里编写 job 和打包都可以,最终要通过 azkaban web 界面上传,使用本地 windows 编写其实更方便。
[root@node02 ~]# cat import.job
type=command
do_date=${dt}
command=/home/warehouse/shell/sqoop_import.sh all ${do_date}
[root@node02 ~]# cat ods.job
type=command
do_date=${dt}
dependencies=import
command=/home/warehouse/shell/ods_db.sh ${do_date}
[root@node02 ~]# cat dwd.job
type=command
do_date=${dt}
dependencies=ods
command=/home/warehouse/shell/dwd_db.sh ${do_date}
[root@node02 ~]# cat dws.job
type=command
do_date=${dt}
dependencies=dwd
command=/home/warehouse/shell/dws_db.sh ${do_date}
[root@node02 ~]# cat ads.job
type=command
do_date=${dt}
dependencies=dws
command=/home/warehouse/shell/ads_sale.sh ${do_date}
[root@node02 ~]# cat export.job
type=command
do_date=${dt}
dependencies=ads
command=/home/warehouse/shell/sqoop_export.sh all ${do_date}
[root@node02 ~]# zip mall-job.zip *.job
[root@node02 ~]# ls mall-job.zip
mall-job.zip- 在 node01、node02、node03 三个节点上启动 Azkaban executor 服务,executor 是执行 job 的引擎。
[root@node01 ~]# azkaban-executor-start.sh
[root@node02 ~]# azkaban-executor-start.sh
[root@node03 ~]# azkaban-executor-start.sh- 在 node03 上继续启动 azkaban web 服务,其它节点不需要启动,因为 job 中的 command 脚本只有 node03 上有,而且脚本中的 sqoop 命令也只有 node03 节点有。
[root@node03 ~]# azkaban-web-start.sh- 接下来通过 web 界面操作 azkaban。
本地 windows 打开浏览器输入:https://192.168.95.23:8443,默认用户密码 admin/admin,进入 azkaban web 页面。
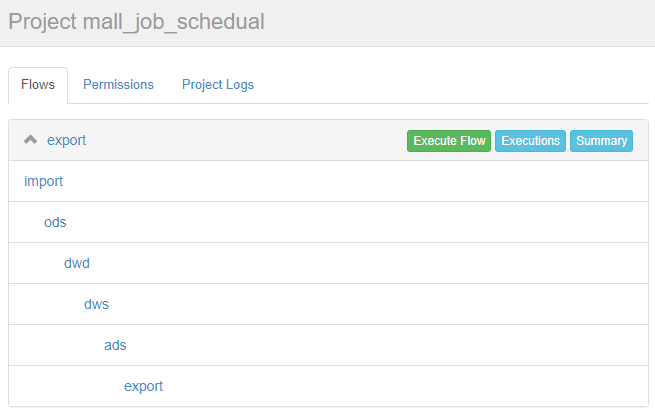
Create Project --> Upload --> 上传刚才创建好的 mall-job.zip 文件 --> Flows,可以看到如下依赖关系展示。
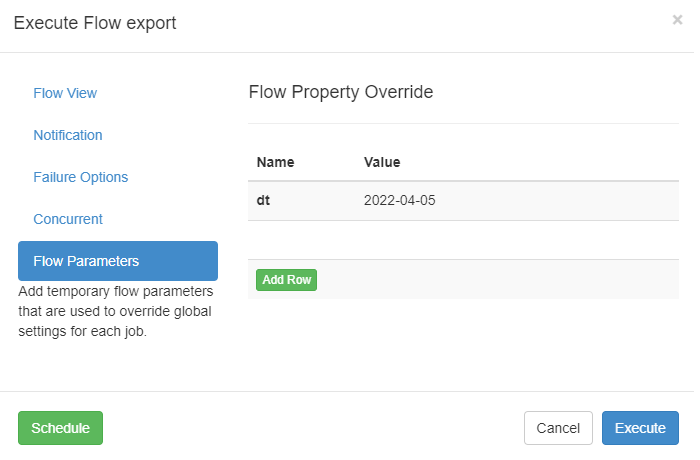
Execute Flow --> Flow Parameters,传两个参数,记得刚才定义 job 的时候,使用了 dt 变量,就在这里定义 KV 对传递给它;
当然 azkaban 还可以加别的参数,比如 useExecutor 指定节点运行 job,但我们这个环境简化了,还做不到,入门后再去深入研究即可。
点击 Execute 执行,如果没有报错,即可以看到如下所有 job 执行成功的过程。