
22、Python3 多进程vs日志
22.1、多进程
由于 Python 的 GIL,多线程未必是 CPU 密集型程序的好选择。
多进程可以完全独立的在进程环境中运行程序,可以充分地利用多处理器。
但是进程本身的隔离带来的数据不共享也是一个问题。而且线程比进程轻量级。
22.1.1、Process 类
Process 类遵循了 Thread 类的 API,减少了学习难度。
先看一个例子,前面介绍的单线程、多线程比较的例子,改成多进程版本:
import multiprocessing
import datetime
def calc(i):
total = 0
for _ in range(1000000000):
total += 1
print(i, total)
if __name__ == '__main__':
start = datetime.datetime.now()
ps = []
for i in range(5):
p = multiprocessing.Process(target=calc, args=(i,), name="calc-{}".format(i))
ps.append(p)
p.start()
for p in ps:
p.join()
delta = (datetime.datetime.now() - start).total_seconds()
print(delta)
print('====================end===================')单线程、多线程都跑了 4 分钟多,而多进程用了 1 分半,这是真并行。可以看出,几乎没有什么学习难度。
注意:__name__ == '__main__' 多进程代码一定要放在这下面执行。
| 名称 | 说明 |
|---|---|
| pid | 进程id |
| exitcode | 进程的退出状态码 |
| terminate() | 终止指定的进程 |
22.1.2、进程间同步
进程间同步提供了和线程同步一样的类,使用的方法一样,使用的效果也类似。
不过,进程间代价要高于线程间,而且底层实现是不同的,只不过 Python 屏蔽了这些不同之处,让用户简单使用多进程。
multiprocessing 还提供共享内存,让进程间共享数据;还提供了 Queue 队列、Pipe 管道用于进程间通信。
通信方式不同:
-
多进程就是启动多个解释器进程,进程间通信必须序列化、反序列化。
-
数据的线程安全性问题,由于每个进程中没有实现多线程,GIL 可以说没什么用了。
22.1.3、进程池举例
multiprocessing.Pool 是进程池类。
| 名称 | 说明 |
|---|---|
| apply(self, func, args=(), kwds={}) | 阻塞执行,导致主进程执行其他子进程就像一个个执行。 |
| apply_async(self, func, args=(), kwds={}, callback=None, error_callback=None) | 与 apply 方法用法一致,非阻塞执行,得到结果后会执行回调。 |
| close() | 关闭池,池不能再接受新的任务。 |
| terminate() | 结束工作进程,不再处理未处理的任务。 |
| join() | 主进程阻塞等待子进程的退出,join 方法要在 close 或 terminate 之后使用。 |
import logging
import datetime
import multiprocessing
# 日志打印进程id、进程名、线程id、线程名
logging.basicConfig(level=logging.INFO, format="%(process)d %(processName)s %(thread)d %(message)s")
# 计算
def calc(arg):
total = 0
for _ in range(1000): # 增在值观察
total += 1
logging.info('{} in function, total: {}'.format(arg, total))
return total # 进程要 return,callback 才可以拿到这个结果
if __name__ == '__main__':
start = datetime.datetime.now()
pool = multiprocessing.Pool(5)
for i in range(5):
# 回调函数必须接受一个参数
pool.apply_async(calc, args=(i,), callback=lambda x: logging.info('{} in callback'.format(x)))
pool.close()
pool.join()
delta = (datetime.datetime.now() - start).total_seconds()
print(delta)
print('==============end=============')22.1.4、多进程、多线程的选择
1、CPU 密集型
CPython 中使用到了 GIL,多线程的时候锁相互竞争,且多核优势不能发挥,Python 多进程效率更高。
2、IO 密集型适合用多线程,可以减少多进程间 IO 的序列化开销。且在 IO 等待的时候,切换到其他线程继续执行,效率不错。
应用:
请求/应答模型:WEB 应用中常见的处理模型。
master 启动多个 worker 工作进程,一般和 CPU 数目相同。发挥多核优势。
worker 工作进程中,往往需要操作网络 IO 和磁盘 IO,启动多线程,提高并发处理能力。
worker 处理用户的请求,往往需要等待数据,处理完请求还要通过网络 IO 返回响应。
这就是 nginx 工作模式。
22.2、concurrent 包
22.2.1、concurrent.futures
3.2 版本引入的模块。
异步并行任务编程模块,提供一个高级的异步可执行的便利接口。
提供了 2 个池执行器:
ThreadPoolExecutor 异步调用的线程池的 Executor。
ProcessPoolExecutor 异步调用的进程池的 Executor。
22.2.2、ThreadPoolExecutor 对象
首先需要定义一个池的执行器对象,Executor 类子类对象。
| 方法 | 含义 |
|---|---|
| ThreadPoolExecutor(max_workers=1) | 池中至多创建 max_workers 个线程来同时异步执行,返回 Executor 实例 |
submit(fn, *args, **kwargs) |
提交执行的函数及其参数,返回 Future 实例 |
| shutdown(wait=True) | 清理池 |
Future 类
| 方法 | 含义 |
|---|---|
| done() | 如果调用被成功的取消或者执行完成,返回 True |
| cancelled() | 如果调用被成功的取消,返回 True |
| running() | 如果正在运行且不能被取消,返回 True |
| cancel() | 尝试取消调用。如果已经执行且不能取消返回 False,否则返回 True |
| result(timeout=None) | 取返回的结果,timeout 为 None,一直等待返回;timeout 设置到期,抛出 concurrent.futures.TimeoutError 异常 |
| exception(timeout=None) | 取返回的异常,timeout 为 None,一直等待返回;timeout 设置到期,抛出 concurrent.futures.TimeoutError 异常 |
# ThreadPoolExecutor 例子
import threading
from concurrent import futures
import logging
import time
# 输出格式定义
FORMAT = '%(asctime)-15s\t [%(processName)s:%(threadName)s, %(process)d:%(thread)8d] %(message)s'
logging.basicConfig(level=logging.INFO, format=FORMAT)
def worker(n):
logging.info('begin to work {}'.format(n))
time.sleep(5)
logging.info('finished {}'.format(n))
# 创建线程池,池的容量为3
executor = futures.ThreadPoolExecutor(max_workers=3)
fs = []
for i in range(3):
future = executor.submit(worker, i)
fs.append(future)
for i in range(3, 6):
future = executor.submit(worker, i)
fs.append(future)
while True:
time.sleep(2)
logging.info(threading.enumerate())
flag = True
for f in fs: # 判断是否还有未完成的任务
logging.info(f.done())
flag = flag and f.done()
print('-' * 30)
if flag:
executor.shutdown()
logging.info(threading.enumerate())
break
# 线程池一旦创建了线程,就不需要频繁清除22.2.3、ProcessPoolExecutor 对象
方法一样。就是使用多进程完成。
# ThreadPoolExecutor 例子
import threading
from concurrent import futures
import logging
import time
# 输出格式定义
FORMAT = '%(asctime)-15s\t [%(processName)s:%(threadName)s, %(process)d:%(thread)8d] %(message)s'
logging.basicConfig(level=logging.INFO, format=FORMAT)
def worker(n):
logging.info('begin to work {}'.format(n))
time.sleep(5)
logging.info('finished {}'.format(n))
if __name__ == '__main__':
# 创建进程池,池的容量为3
executor = futures.ProcessPoolExecutor(max_workers=3)
fs = []
for i in range(3):
future = executor.submit(worker, i)
fs.append(future)
for i in range(3, 6):
future = executor.submit(worker, i)
fs.append(future)
while True:
time.sleep(2)
logging.info(threading.enumerate())
flag = True
for f in fs: # 判断是否还有未完成的任务
logging.info(f.done())
flag = flag and f.done()
print("-" * 30)
if flag:
executor.shutdown() # 清理池。除非不用,不要频繁清理池
logging.info(threading.enumerate()) # 多进程时看主线程已没有必要了
break22.2.4、支持上下文管理
concurrent.futures.ProcessPoolExecutor 继承自 concurrent.futures._base.Executor,而父类有 __enter__、__exit__ 方法,支持上下文管理。可以使用 with 语句。
__exit__ 方法本质还是调用的 shutdown(wait=True),就是一直阻塞到所有运行的任务完成。
使用方法:
with futures.ThreadPoolExecutor(max_workers=1) as executor:
future = executor.submit(pow, 323, 123)
print(future.result())使用上下文改造上面的例子,增加返回计算的结果:
# ThreadPoolExecutor 例子
import threading
from concurrent import futures
import logging
import time
# 输出格式定义
FORMAT = '%(asctime)-15s\t [%(processName)s:%(threadName)s, %(process)d:%(thread)8d] %(message)s'
logging.basicConfig(level=logging.INFO, format=FORMAT)
def worker(n):
logging.info('begin to work {}'.format(n))
time.sleep(5)
logging.info('finished {}'.format(n))
return n + 100 # 返回结果
if __name__ == '__main__':
# 创建进程池,池的容量为3
executor = futures.ProcessPoolExecutor(max_workers=3)
with executor: # 上下文
fs = []
for i in range(3):
future = executor.submit(worker, i)
fs.append(future)
for i in range(3, 6):
future = executor.submit(worker, i)
fs.append(future)
while True:
time.sleep(2)
logging.info(threading.enumerate())
flag = True
for f in fs: # 判断是否还有未完成的任务
logging.info(f.done())
flag = flag and f.done()
if f.done():
logging.info('result={}'.format(f.result()))
print("-" * 30)
if flag: break该库统一了线程池、进程池调用,简化了编程。是 Python 简单的思想哲学的体现。
唯一的缺点:无法设置线程名称。但这都不值一提。
22.3、logging 模块
22.3.1、日志级别
| 日志级别 Level | 数值 |
|---|---|
| CRITICAL | 50 |
| ERROR | 40 |
| WARNING | 30,默认级别 |
| INFO | 20 |
| DEBUG | 10 |
| NOTSET | 0 |
日志级别指的是产生日志事件的严重程度。设置一个级别后,严重程度低于设置值的日志消息将被忽略。
debug()、 info()、 warning()、 error() 和 critical() 方法。
22.3.2、格式字符串
| Attribute name | Format | Description |
|---|---|---|
| args | You shouldn’t need to format this yourself. | The tuple of arguments merged into msg to produce message, or a dict whose values are used for the merge (when there is only one argument, and it is a dictionary). |
| asctime | %(asctime)s |
Human-readable time when the LogRecord was created. By default this is of the form ‘2003-07-08 16:49:45,896’ (the numbers after the comma are millisecond portion of the time). |
| created | %(created)f |
Time when the LogRecord was created (as returned by time.time()). |
| exc_info | You shouldn’t need to format this yourself. | Exception tuple (à la sys.exc_info) or, if no exception has occurred, None. |
| filename | %(filename)s |
Filename portion of pathname. |
| funcName | %(funcName)s |
Name of function containing the logging call. |
| levelname | %(levelname)s |
Text logging level for the message ('DEBUG', 'INFO', 'WARNING', 'ERROR', 'CRITICAL'). |
| levelno | %(levelno)s |
Numeric logging level for the message (DEBUG, INFO, WARNING, ERROR, CRITICAL). |
| lineno | %(lineno)d |
Source line number where the logging call was issued (if available). |
| message | %(message)s |
The logged message, computed as msg % args. This is set when Formatter.format() is invoked. |
| module | %(module)s |
Module (name portion of filename). |
| msecs | %(msecs)d |
Millisecond portion of the time when the LogRecord was created. |
| msg | You shouldn’t need to format this yourself. | The format string passed in the original logging call. Merged with args to produce message, or an arbitrary object (see Using arbitrary objects as messages). |
| name | %(name)s |
Name of the logger used to log the call. |
| pathname | %(pathname)s |
Full pathname of the source file where the logging call was issued (if available). |
| process | %(process)d |
Process ID (if available). |
| processName | %(processName)s |
Process name (if available). |
| relativeCreated | %(relativeCreated)d |
Time in milliseconds when the LogRecord was created, relative to the time the logging module was loaded. |
| stack_info | You shouldn’t need to format this yourself. | Stack frame information (where available) from the bottom of the stack in the current thread, up to and including the stack frame of the logging call which resulted in the creation of this record. |
| thread | %(thread)d |
Thread ID (if available). |
| threadName | %(threadName)s |
Thread name (if available). |
22.3.3、操作理解
22.3.3.1、默认级别
import logging
FORMAT = '%(asctime)-15s\tThread info: %(thread)d %(threadName)s %(message)s'
logging.basicConfig(format=FORMAT)
logging.info('I am {}'.format(20)) # info 不显示
logging.warning('I am {}'.format(20)) # warning 默认级别22.3.3.2、构建消息
import logging
FORMAT = '%(asctime)-15s\tThread info: %(thread)d %(threadName)s %(message)s'
logging.basicConfig(format=FORMAT, level=logging.INFO)
logging.info('I am {}'.format(20)) # info 不显示
logging.info('I am %d %s', 20, 'years old.') # c 风格上例是基本的使用方法,大多数时候,使用的是 info,正常运行信息的输出。
日志级别和格式字符串扩展的例子:
import logging
FORMAT = '%(asctime)-15s\tThread info: %(thread)d %(threadName)s %(message)s %(school)s'
logging.basicConfig(format=FORMAT, level=logging.WARNING)
d = {'school': 'www.brinnatt.com'}
logging.info('I am %s %s', 20, 'years old.', extra=d)
logging.warning('I am %s %s', 20, 'years old.', extra=d)22.3.3.3、修改日期格式
import logging
logging.basicConfig(format='%(asctime)s %(message)s', datefmt='%Y/%m/%d %I:%M:%S')
logging.warning('this event was logged.')22.3.3.4、输出到文件
import logging
logging.basicConfig(format='%(asctime)s %(message)s', filename='e:/test.log')
for _ in range(5):
logging.warning('this event was logged.')22.3.4、Logger 类
logging 模块加载的时候,会创建一个 root logger。根 Logger 对象的默认级别是 WARNING。
调用 logging.basicConfig 来调整级别,就是对这个根 Logger 的级别进行修改。
......
root = RootLogger(WARNING)
Logger.root = root
Logger.manager = Manager(Logger.root)
......22.3.4.1、构造
logging.getLogger([name=None])
使用工厂方法返回一个 Logger 实例。指定 name,返回一个名称为 name 的 Logger 实例。未指定 name,返回根 Logger 实例。
import logging
log1 = logging.getLogger('mylog')
log2 = logging.getLogger('mylog')
print(1, '-->', id(log1))
print(2, '-->', id(log2))
log3 = logging.getLogger('mylog1')
print(3, '-->', id(log3))
print(4, '-->', id(log3.root), id(log2.root))
输出:
1 --> 1223430221504
2 --> 1223430221504
3 --> 1223430540736
4 --> 1223431733056 122343173305622.3.4.2、层次结构
Logger 是有层次结构的,使用 . 点号分割,如 a、a.b 或 a.b.c.d,a 是 a.b 的父 parent,a.b 是 a 的子 child。对于 foo 来说,名字为 foo.bar、foo.bar.baz、foo.bam 都是 foo 的后代。
import logging
# 父子层次关系
root = logging.getLogger() # 根logger
print(root.name, type(root), root.parent, id(root)) # 根logger没有父
logger = logging.getLogger(__name__) # 模块级logger
print(logger.name, type(logger), id(logger.parent), id(logger))
loggerchild = logging.getLogger(__name__ + '.child') # 模块名.child 这是子logger
print(loggerchild.name, type(loggerchild), id(loggerchild.parent), id(loggerchild))22.3.4.3、Level 级别设置
import logging
FORMAT = '%(asctime)-15s\tThread info: %(thread)d %(threadName)s %(message)s'
logging.basicConfig(format=FORMAT, level=logging.INFO)
logger = logging.getLogger(__name__) # 创建一个新的logger, 未设定级别
print(1, '-->', logger.name, type(logger))
print(2, '-->', logger.getEffectiveLevel())
logger.info('I want you')
logger.setLevel(28) # 重新修改 level
print(3, '-->', logger.getEffectiveLevel())
logger.info('I want you again') # 被拦截
logger.warning('I want you in another way')
root = logging.getLogger() # 根logger
root.info("I want you from root") # 输出成功每一个 logger 创建后,都有一个等效的 level。logger 对象可以在创建后动态的修改自己的 level。
22.3.4.4、Handler 设置
Handler 控制日志信息的输出目的地,可以是控制台、文件。
-
可以单独设置 level
-
可以单独设置格式
-
可以设置过滤器
Handler 类继承:
- Handler
- StreamHandler 不指定使用 sys.stderr
- FileHandler 文件
- _StderrHandler 标准输出
- NullHandler 什么都不做
日志输出其实是 Handler 做的,也就是真正干活的是 Handler。
在 logging.basicConfig 中,如下:
if handlers is None:
filename = kwargs.pop("filename", None)
mode = kwargs.pop("filemode", 'a')
if filename:
if 'b' in mode:
errors = None
else:
encoding = io.text_encoding(encoding)
h = FileHandler(filename, mode,
encoding=encoding, errors=errors)
else:
stream = kwargs.pop("stream", None)
h = StreamHandler(stream)
handlers = [h]如果设置文件名,则为根 logger 加一个输出到文件的 Handler;如果没有设置文件名,则为根 logger 加一个 StreamHandler,默认输出到 sys.stderr。也就是说,根 logger 一定会至少有一个 handler。
思考:创建的 Handler 的初始的 level 是什么?
import logging
FORMAT = '%(asctime)s %(name)s %(message)s'
logging.basicConfig(format=FORMAT, level=logging.INFO)
logger = logging.getLogger('web')
print(logger.name, type(logger))
logger.info('line 1')
handler = logging.FileHandler('e:/web.log', 'w') # 创建 handler
logger.addHandler(handler) # 给logger对象绑定一个handler
# 注意看控制台,再看web.log文件,对比差异
# 思考这是怎么打印的
logger.info('line 2')Handler 初始的 level 是什么?是 0
22.3.4.5、level 的继承
import logging
FORMAT = '%(asctime)s %(name)s %(message)s'
logging.basicConfig(format=FORMAT, level=logging.INFO)
root = logging.getLogger()
log1 = logging.getLogger('web')
log1.setLevel(logging.INFO) # 分别取 INFO、WARNING、ERROR 试一试
# 没有设置任何的 handler、level
# log2 有效级别就是log1的ERROR
log2 = logging.getLogger('web.nginx')
log2.warning('log2 warning')
print(1, '-->', log2.parent, log2.parent.parent)logger 实例,如果设置了 level,就用它和信息的级别比较,否则,继承最近的祖先的 level。
22.3.4.6、继承关系及信息传递
每一个 Logger 实例的 level 如同入口,让水流进来,如果这个门槛太高,信息就进不来。例如 log3.warning('Attention!'),如果 log3 定义的级别高,就不会有信息通过 log3。
如果 level 没有设置,就用父 logger 的,如果父 logger 的 level 没有设置,继续找父的父的,最终可以找到 root 上,如果 root 设置了就用它的,如果 root 没有设置,root 的默认值是 WARNING。
消息传递流程:
-
如果消息在某一个 logger 对象上产生,这个 logger 就是当前 logger,首先消息 level 要和当前 logger 的 EffectiveLevel 比较,如果低于当前 logger 的 EffectiveLevel,则流程结束,否则生成 log 记录。
-
日志记录会交给当前 logger 的所有 handler 处理,记录还要和每一个 handler 的级别分别比较,低的不处理,否则按照 handler 输出日志记录。
-
当前 logger 的所有 handler 处理完后,就要看自己的 propagate 属性,如果是 True 表示向父 logger 传递这个日志记录,否则到此流程结束。
-
如果日志记录传递到了父 logger,不需要和 logger 的 level 比较,而是直接交给父的所有 handler,父 logger 成为当前 logger。重复 2、3 步骤,直到当前 logger 的父 logger 是 None 退出,也就是说当前 logger 最后一般是 root logger(是否能到 root logger 要看中间的 logger 是否允许 propagate)。
logger 实例初始的 propagate 属性为 True,即允许向父 logger 传递消息。
logging.basicConfig():
-
如果 root 没有 handler,就默认创建一个 StreamHandler,如果设置了 filename,就创建一个 FileHandler。
-
如果设置了 format 参数,就会用它生成一个 formatter 对象,并把这个 formatter 加入到刚才创建的 handler 上,然后把这些 handler 加入到 root.handlers 列表上。
-
level 是设置给 root logger 的。
-
如果 root.handlers 列表不为空,logging.basicConfig 的调用什么都不做。
官方日志流转图:
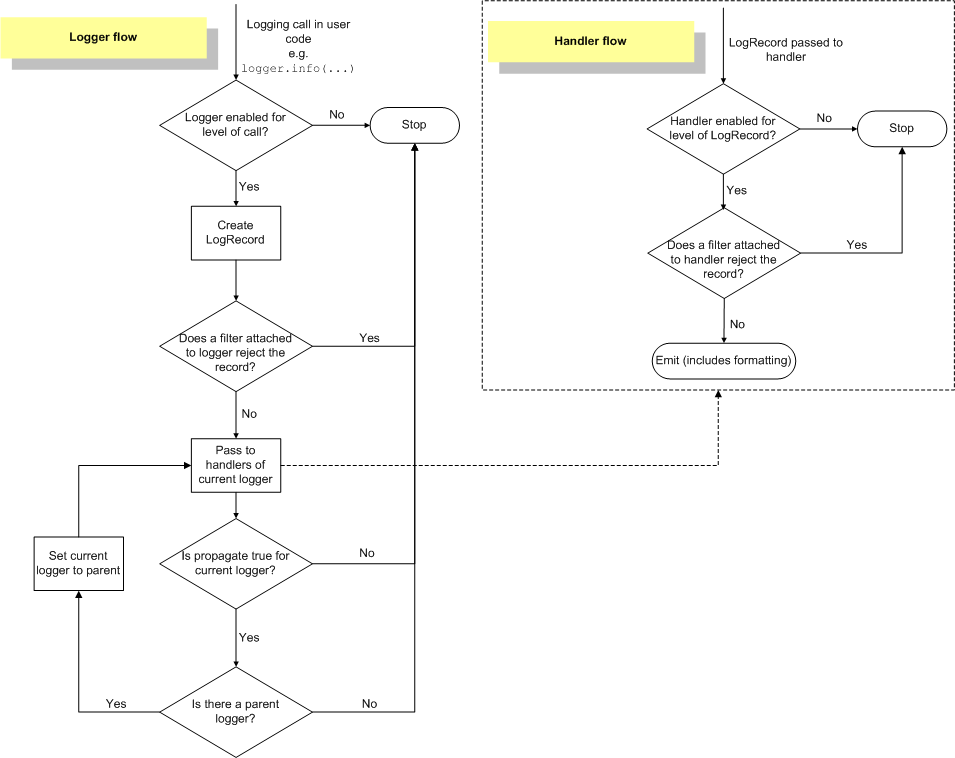
参考 logging.Logger 类的 callHandlers 方法。
import logging
logging.basicConfig(format='%(name)s %(asctime)s %(message)s', level=logging.INFO)
root = logging.getLogger()
root.setLevel(logging.ERROR)
print(1, '-->', 'root', root.handlers)
h0 = logging.StreamHandler()
h0.setLevel(logging.WARNING)
root.addHandler(h0)
print(2, '-->', 'root', root.handlers)
for h in root.handlers:
print(3, '-->', 'root handler = {}, formatter = {}'.format(h, h.formatter))
log1 = logging.getLogger('web')
log1.setLevel(logging.ERROR)
h1 = logging.FileHandler('e:/test.log')
h1.setLevel(logging.WARNING)
log1.addHandler(h1)
print(4, '-->', 'log1', log1.handlers)
log2 = logging.getLogger('web.nginx')
log2.setLevel(logging.CRITICAL)
h2 = logging.FileHandler('e:/test.log')
h2.setLevel(logging.WARNING)
log2.addHandler(h2)
print(5, '-->', 'log2', log2.handlers)
log3 = logging.getLogger('web.nginx.backend')
log3.setLevel(logging.INFO)
print(6, '-->', 'log3', log3.getEffectiveLevel())
log3.warning('log3')
print(7, '-->', 'log3', log3.handlers)22.3.4.7、Formatter
logging 的 Formatter 类,它允许指定某个格式的字符串。如果提供 None,那么 %(message)s 将会作为默认值。
修改上面的例子,让它看的更加明显。
import logging
logging.basicConfig(format='%(name)s %(asctime)s %(message)s', level=logging.INFO)
root = logging.getLogger()
root.setLevel(logging.ERROR)
print(1, '-->', 'root', root.handlers)
h0 = logging.StreamHandler()
h0.setLevel(logging.WARNING)
root.addHandler(h0)
print(2, '-->', 'root', root.handlers)
for h in root.handlers:
print(3, '-->', 'root handler = {}, formatter = {}'.format(h, h.formatter))
log1 = logging.getLogger('web')
log1.setLevel(logging.ERROR)
h1 = logging.FileHandler('e:/test.log')
h1.setLevel(logging.WARNING)
print(4, '-->', 'log1 formatter', h1.formatter) # 没有设置formatter使用缺省值'%(message)s'
log1.addHandler(h1)
print(4.1, '-->', 'log1', log1.handlers)
log2 = logging.getLogger('web.nginx')
log2.setLevel(logging.CRITICAL)
h2 = logging.FileHandler('e:/test.log')
h2.setLevel(logging.WARNING)
print(5, '-->', 'log2 formatter', h2.formatter)
# handler 默认无Formatter
f2 = logging.Formatter("log2 %(name)s %(asctime)s %(message)s")
h2.setFormatter(f2)
print(5.1, '-->', 'log2 formatter', h2.formatter)
log2.addHandler(h2)
print(5.2, '-->', 'log2', log2.handlers)
log3 = logging.getLogger('web.nginx.backend')
log3.setLevel(logging.INFO)
print(6, '-->', 'log3', log3.getEffectiveLevel())
log3.warning('log3')
print(7, '-->', 'log3', log3.handlers)22.3.4.8、Filter
可以为 handler 增加过滤器,所以这种过滤器只影响某一个 handler,不会影响整个处理流程。但是,如果过滤器增加到 logger 上,就会影响流程。
import logging
FORMAT = '%(asctime)-15s\tThread info: %(thread)d %(threadName)s %(message)s'
logging.basicConfig(format=FORMAT, level=logging.INFO)
root = logging.getLogger()
h0 = logging.StreamHandler() # root默认就有一个handler,level=0
h0.setLevel(logging.WARNING) # 设置成ERROR试一试
root.addHandler(h0)
log1 = logging.getLogger('s')
log1.setLevel(logging.WARNING) # ERROR试一试
h1 = logging.StreamHandler()
h1.setLevel(logging.INFO)
fmt1 = logging.Formatter('log1-h1 %(message)s')
h1.setFormatter(fmt1)
log1.addHandler(h1)
log2 = logging.getLogger('s.s1')
# log2.setLevel(logging.CRITICAL)
print(1, '-->', log2.getEffectiveLevel()) # 继承父的level,WARNING
h2 = logging.StreamHandler()
h2.setLevel(logging.INFO)
fmt2 = logging.Formatter('log2-h2 %(message)s')
h2.setFormatter(fmt2)
f2 = logging.Filter('s') # 过滤器 s s.s1 s.s2
h2.addFilter(f2)
log2.addHandler(h2)
log2.warning('log2 warning')log2 的名字是 s.s1,因此过滤器名字设置为 s 或 s.s1,消息就可以通过,但是如果是其他就不能通过,不设置过滤器名字,所有消息通过。
过滤器核心就这一句,在 logging.Filter 类的 filter 方法中
record.name.find(self.name,0,self.nlen) != 0
本质上就是等价于 record.name.startswith(filter.name)