
18、Python3 类继承
18.1、基本概念
面向对象三要素之一,继承 Inheritance。
人类和猫类都继承自动物类。个体继承自父母,继承了父母的一部分特征,但也可以有自己的个性。在面向对象的世界中,从父类继承,就可以直接拥有父类的属性和方法,这样可以减少代码、多复用。子类可以定义自己的属性和方法。
看一个不用继承的例子:
class Animal:
def shout(self):
print("Animal shout")
a = Animal()
a.shout()
class Cat:
def shout(self):
print('Cat shout')
c = Cat()
c.shout()上面的 2 个类虽然有关系,但是定义时并没有建立这种关系,而是各自完成定义。
动物类和猫类都有吃,但是它们的吃有区别,所以分别定义。
class Animal:
def __init__(self, name):
self._name = name
def shout(self):
print("{} shouts".format(self.__class__.__name__))
name = property(lambda self: self._name)
a = Animal('monster')
a.shout()
class Cat(Animal):
pass
cat = Cat('garfield')
cat.shout()
print(cat.name)
class Dog(Animal):
pass
dog = Dog('ahung')
dog.shout()
print(dog.name)上例可以看出,通过继承,猫类、狗类不用写代码,直接继承了父类的属性和方法。
继承:
class Cat(Animal) 这种形式就是从父类继承,括号中写上继承的类的列表。
继承可以让子类从父类获取特征(属性和方法)。
父类:
Animal 就是 Cat 的父类,也称为基类、超类。
子类:
Cat 就是 Animal 的子类,也称为派生类。
18.2、定义
格式如下:
class 子类名(基类1[,基类2,...]):
语句块如果类定义时,没有基类列表,等同于继承自 object。在 Python3 中,obiect 类是所有对象的根基类。
class A:
pass
# 等价于
class A(object):
pass注意,上例在 Python2 中,两种写法是不同的。Python 支持多继承,继承也可以多级。查看继承的特殊属性和方法有:
| 特殊属性和方法 | 含义 | 示例 |
|---|---|---|
__base__ |
类的基类 | |
__bases__ |
类的基类元组 | |
__mro__ |
显示方法查找顺序,基类的元组 | |
mro() |
同上 | int.mro() |
__subclasses__() |
类的子类列表 | int.__subclasses__() |
18.3、继承中的访问控制
class Animal:
__COUNT = 100
HEIGHT = 0
def __init__(self, age, weight, height):
self.__COUNT += 1
self.age = age
self.__weight = weight
self.HEIGHT = height
def eat(self):
print('{} eat'.format(self.__class__.__name__))
def __getweight(self):
print(self.__weight)
@classmethod
def showcount1(cls):
print(cls.__COUNT)
@classmethod
def __showcount2(cls):
print(cls.__COUNT)
def showcount3(self):
print(self.__COUNT)
class Cat(Animal):
NAME = 'CAT'
__COUNT = 200
# c = Cat() # TypeError: Animal.__init__() missing 3 required positional arguments: 'age', 'weight', and 'height'
c = Cat(3, 5, 15)
c.eat()
print(c.HEIGHT)
# print(c.__COUNT) # 私有的不可访问
# c.__showweight() # 私有的不可访问
c.showcount1()
# c.__showcount2() # 私有的不可访问
c.showcount3()
print(c.NAME)
print('{}'.format(Animal.__dict__))
print('{}'.format(Cat.__dict__))
print(c.__dict__)
print(c.__class__.mro())从父类继承,自己没有的,就可以到父类中找。
私有的都是不可以访问的,但是本质上依然是改了名称放在这个属性所在类的了 __dict__ 中。知道这个新名称就可以直接找到这个隐藏的变量,这是个黑魔法技巧,慎用。
总结:
继承时,公有的,子类和实例都可以随意访问,私有成员被隐藏,子类和实例不可直接访问,但私有变量所在的类中的方法可以访问这个私有变量。
Python 通过自己一套实现,实现和其它语言一样的面向对象的继承机制。
属性查找顺序:
实例的 __dict__ --> 类__dict__ --> 父类__dict__。
如果搜索这些地方后没有找到就会抛异常,先找到就立即返回了。
18.4、方法重写
class Animal:
def shout(self):
print('Animal shouts')
class Cat(Animal):
# 覆盖了父类方法
def shout(self):
print('miao')
a = Animal()
a.shout()
c = Cat()
c.shout()
print(a.__dict__)
print(c.__dict__)
print(Animal.__dict__)
print(Cat.__dict__)Cat 中能否覆盖自己的方法吗?
class Animal:
def shout(self):
print('Animal shouts')
class Cat(Animal):
# 覆盖了父类方法
def shout(self):
print('miao')
# 覆盖了自身的方法,显式调用了父类的方法
def shout(self):
print(super())
print(super(Cat, self))
super().shout()
super(Cat, self).shout() # 等价于super()
self.__class__.__base__.shout(self) # 不推荐
a = Animal()
a.shout()
c = Cat()
c.shout()
print(a.__dict__)
print(c.__dict__)
print(Animal.__dict__)
print(Cat.__dict__)super() 可以访问到父类的属性,其具体原理后面说。
那对于类方法和静态方法呢?
class Animal:
@classmethod
def class_method(cls):
print('class_method_animal')
@staticmethod
def static_method():
print('static_method_animal')
class Cat(Animal):
@classmethod
def class_method(cls):
print('class_method_cat')
@staticmethod
def static_method():
print('static_method_cat')
c = Cat()
c.class_method()
c.static_method()这些方法都可以覆盖,原理都一样,属性字典的搜索顺序。
18.5、继承中的初始化
先看下面一段代码,有没有问题:
class A:
def __init__(self, a):
self.a = a
class B(A):
def __init__(self, b, c):
self.b = b
self.c = c
def printv(self):
print(self.b)
print(self.a) # 出错吗?
f = B(200, 300)
print(f.__dict__)
print(f.__class__.__bases__)
f.printv()上例代码可知:
如果类 B 定义时声明继承自类 A,则在类 B 中 __bases__ 中是可以看到类 A。
但是这和是否调用类 A 的构造方法是两回事。
如果 B 中调用了 A 的构造方法,就可以拥有父类的属性了。如何理解这一句话呢?
观察 B 的实例 f 的 __dict__ 中的属性。
class A:
def __init__(self, a, d):
self.a = a
self.__d = d
class B(A):
def __init__(self, b, c):
A.__init__(self, b+c, b-c)
self.b = b
self.c = c
def printv(self):
print(self.b)
print(self.a) # 出错吗?
f = B(200, 300)
print(f.__dict__)
print(f.__class__.__bases__)
f.printv()作为好的习惯,如果父类定义了 __init__ 方法,你就该在子类的 __init__ 中调用它。
那子类什么时候自动调用父类的 __init__ 方法呢?
示例1:
class A:
def __init__(self):
self.a1 = 'a1'
self.__a2 = 'a2'
print('A init')
class B(A):
pass
b = B()
print(b.__dict__)B 实例的初始化会自动调用基类 A 的 __init__ 方法。
示例2:
class A:
def __init__(self):
self.a1 = 'a1'
self.__a2 = 'a2'
print('A init')
class B(A):
def __init__(self):
self.b1 = 'b1'
print('B init')
b = B()
print(b.__dict__)B 实例的初始化 __init__ 方法不会自动调用父类的初始化 __init__ 方法,需要手动调用。
class A:
def __init__(self):
self.a1 = 'a1'
self.__a2 = 'a2'
print('A init')
class B(A):
def __init__(self):
self.b1 = 'b1'
print('B init')
A.__init__(self)
b = B()
print(b.__dict__)如何正确初始化:
class Animal:
def __init__(self, age):
print('Animal init')
self.age = age
def show(self):
print(self.age)
class Cat(Animal):
def __init__(self, age, weight):
print('Cat init')
self.age = age + 1
self.weight = weight
c = Cat(10, 5)
c.show()上例我们前面都分析过,不会调用父类的 __init__ 方法的,这就会导致没有实现继承效果。
所以在子类的 __init__ 方法中,应该显式调用父类的 __init__ 方法。
class Animal:
def __init__(self, age):
print('Animal init')
self.age = age
def show(self):
print(self.age)
class Cat(Animal):
def __init__(self, age, weight):
# 调用父类的__init__方法的顺序决定着show方法的结果
super().__init__(age)
print('Cat init')
self.age = age + 1
self.weight = weight
# super().__init__(age)
c = Cat(10, 5)
c.show()注意,调用父类的 __init__ 方法,出现在不同的位置,可能导致出现不同的结果。
那么,直接将上例中所有的实例属性改成私有变量呢?
class Animal:
def __init__(self, age):
print('Animal init')
self.__age = age
def show(self):
print(self.__age)
class Cat(Animal):
def __init__(self, age, weight):
# 调用父类的__init__方法的顺序决定着show方法的结果
super().__init__(age)
print('Cat init')
self.__age = age + 1
self.__weight = weight
# super().__init__(age)
c = Cat(10, 5)
c.show()
print(c.__dict__)上例中打印 10,原因看 __dict__ 就知道了。因为父类 Animal 的 show 方法中 __age 会被解释为 _Animal__age,因此显示的是 10,而不是 11。
这样的设计不好,Cat 的实例 c 应该显示自己的属性值更好。
解决的办法:一个原则,自己的私有属性,就该自己的方法读取和修改,不要借助其他类的方法,即使是父类或者派生类的方法。
18.6、python 不同版本的类
Python 2.2 之前类是没有共同的祖先的,之后,引入 object 类,它是所有类的共同祖先类 object。
Python 2 中为了兼容,分为古典类(旧式类)和新式类。
Python 3 中全部都是新式类。
新式类都是继承自 object 的,新式类可以使用 super。
# 以下代码在python2.x中运行
# 古典类(旧式类)
class A: pass
# 新式类
class B(object): pass
print(dir(A))
print(dir(B))
print(A.__bases__)
print(B.__bases__)
# 古典类
a = A()
print(a.__class__)
print(type(a)) # <type 'instance'>
# 新式类
b = B()
print(b.__class__)
print(type(b))
输出:
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']
(<class 'object'>,)
(<class 'object'>,)
<class '__main__.A'>
<class '__main__.A'>
<class '__main__.B'>
<class '__main__.B'>18.7、多继承
OCP 原则:多用“继承”、少修改。
继承的用途:增强基类、实现多态。
多态:
在面向对象中,父类、子类通过继承联系在一起,如果可以通过一套方法,就可以实现不同表现,就是多态。
一个类继承自多个类就是多继承,它将具有多个类的特征。
18.7.1、多继承弊端
多继承很好的模拟了世界,因为事物很少是单一继承,但是舍弃简单,必然引入复杂性,带来了冲突。
如同一个孩子继承了来自父母双方的特征。那么到底眼睛像爸爸还是妈妈呢?孩子究竟该像谁多一点呢?
多继承的实现会导致编译器设计的复杂度增加,所以现在很多语言也舍弃了类的多继承。
C++ 支持多继承;Java 舍弃了多继承。
Java 中,一个类可以实现多个接口,一个接口也可以继承多个接口。Java 的接口很纯粹,只是方法的声明,继承者必须实现这些方法,就具有了这些能力,就能干什么。
多继承可能会带来二义性,例如,猫和狗都继承自动物类,现在如果一个类多继承了猫和狗类,猫和狗都有 shout 方法,子类究竟继承谁的 shout 呢?
解决方案:实现多继承的语言,要解决二义性,深度优先或者广度优先。
18.7.2、python 多继承实现
class ClassName(基类列表):
类体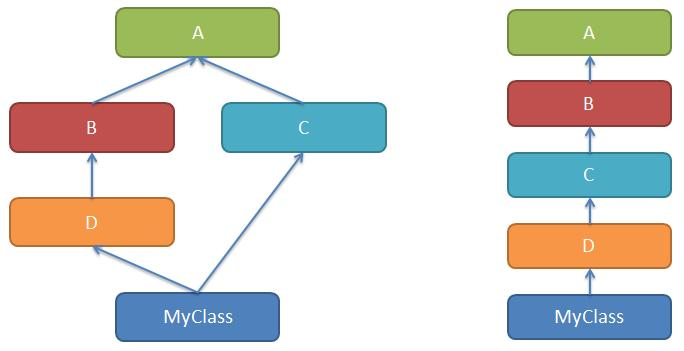
左图是多继承,右图是单一继承。
多继承带来路径选择问题,究竟继承哪个父类的特征呢?
Python 使用 MRO(method resolution order) 解决基类搜索顺序问题。
历史原因,MRO 有三个搜索算法:
-
经典算法,按照定义从左到右,深度优先策略。python 2.2 之前左图的 MRO 是 MyClass,D,B,A,C,A。
-
新式类算法,经典算法的升级,重复的只保留最后一个。python 2.2 左图的 MRO 是 MyClass,D,B,C,A,obiect。
-
C3 算法,在类被创建出来的时候,就计算出一个 MRO 有序列表。python 2.3 之后,Python3 唯一支持的算法。左图中的 MRO 是 MyClass,D,B,C,A,object 的列表。C3 算法解决多继承的二义性。
18.7.3、多继承的缺点
当类很多,继承复杂的情况下,继承路径太多,很难说清什么样的继承路径。
Python 语法是允许多继承,但 Python 代码是解释执行,只有执行到的时候,才发现错误。
团队协作开发,如果引入多继承,那代码将不可控。
不管编程语言是否支持多继承,都应当避免多继承。
Python 的面向对象,我们看到的太灵活了,太开放了,所以要团队守规矩。
18.7.4、Mixin 类
类有下面的继承关系:
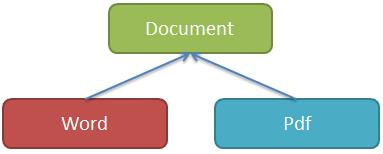
文档 Document 类是其他所有文档类的抽象基类;
Word、Pdf 类是 Document 的子类。
需求:为 Document 子类提供打印能力
思路:
1、在 Document 中提供 print 方法。
class Document:
def __init__(self, content):
self.content = content
def print(self):
raise NotImplementedError()
class Word(Document): pass
class Pdf(Document): pass基类提供的方法不应该具体实现,因为它未必适合子类的打印,子类中需要覆盖重写。
print 算是一种能力(打印功能),不是所有的 Document 的子类都需要的,所以,从这个角度出发,有点问题。
2、需要打印的子类上增加
如果在现有子类上直接增加,违反了 OCP 的原则,所以应该继承后增加。因此有下图:
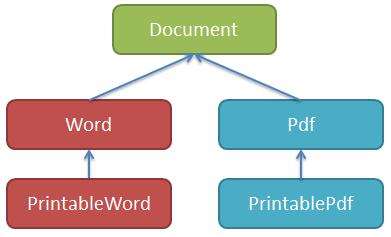
class Printable:
def print(self):
print(self.content)
class Document: # 第三方库,不允许修改
def __init__(self, content):
self.content = content
class Word(Document): pass # 第三方库,不允许修改
class Pdf(Document): pass # 第三方库,不允许修改
class PrintableWord(Printable, Word): pass
print(PrintableWord.__dict__)
print(PrintableWord.mro())
pw = PrintableWord('test string')
pw.print()看似不错,如果需要提供其他能力,如何继承?应用于网络,文档应该具备序列化的能力,类上就应该实现序列化。可序列化还可能分为使用 pickle、json、messagepack 等。
这个时候发现,类可能太多了,单纯使用继承的方式不是很好了。功能太多,A 类需要某几样功能,B 类需要另几样功能,很繁琐。
可以考虑使用下面的多种组合技巧。
3、装饰器
用装饰器增强一个类,把功能给类附加上去,哪个类需要,就装饰它。
def printable(cls):
def _print(self):
print(self.content, "装饰器")
cls.print = _print
return cls
class Document: # 第三方库,不允许修改
def __init__(self, content):
self.content = content
class Word(Document): pass # 第三方库,不允许修改
class Pdf(Document): pass # 第三方库,不允许修改
@printable # 先继承,后装饰
class PrintableWord(Word): pass
print(PrintableWord.__dict__)
print(PrintableWord.mro())
pw = PrintableWord('test string')
pw.print()
@printable
class PrintablePdf(Pdf): pass优点:
简单方便,在需要的地方动态增加,直接使用装饰器。
4、Mixin
先看代码:
class Document: # 第三方库,不允许修改
def __init__(self, content):
self.content = content
class Word(Document): pass # 第三方库,不允许修改
class Pdf(Document): pass # 第三方库,不允许修改
class PrintableMixin:
def print(self):
print(self.content, 'Mixin')
class PrintableWord(PrintableMixin, Word): pass
print(PrintableWord.__dict__)
print(PrintableWord.mro())
def printable(cls):
def _print(self):
print(self.content, "装饰器")
cls.print = _print
return cls
@printable
class PrintablePdf(Word): pass
print(PrintablePdf.__dict__)
print(PrintablePdf.mro())Mixin 就是其它类混合进来,同时带来了类的属性和方法。
这里看来 Mixin 类和装饰器效果一样,也没有什么特别的。但是 Mixin 是类,就可以继承。
class Document: # 第三方库,不允许修改
def __init__(self, content):
self.content = content
class Word(Document): pass # 第三方库,不允许修改
class Pdf(Document): pass # 第三方库,不允许修改
class PrintableMixin:
def print(self):
print(self.content, 'Mixin')
class PrintableWord(PrintableMixin, Word): pass
print(PrintableWord.__dict__)
print(PrintableWord.mro())
pw = PrintableWord('test string')
pw.print()
class SuperPrintableMixin(PrintableMixin):
def print(self):
print('-' * 20)
super().print()
print('-' * 20)
class SuperPrintablePdf(SuperPrintableMixin, Pdf): pass
print(SuperPrintablePdf.__dict__)
print(SuperPrintablePdf.mro())
spp = SuperPrintablePdf('super print pdf')
spp.print()Mixin 本质上就是多继承实现的。
Mixin 体现的是一种组合的设计模式。
在面向对象的设计中,一个复杂的类,往往需要很多功能,而这些功能有来自不同的类提供,这就需要很多的类组合在一起。
从设计模式的角度来说,多组合,少继承。
Mixin 类的使用原则:
-
Mixin 类中不应该显式的出现
__init__初始化方法。 -
Mixin 类通常不能独立工作,因为它是准备混入别的类中的部分功能实现。
-
Mixin 类的祖先类也应该是 Mixin 类。
使用时,Mixin 类通常在继承列表的第一个位置,例如 class PrintableWord(PrintableMixin, Word): pass。
Mixin 类和装饰器:
-
这两种方式都可以使用,看个人喜好。
-
如果还需要继承就得使用 Mixin 类的方式。
18.8、练习
18.8.1、shape 计算
1、Shape 基类,要求所有子类都必须提供面积的计算,子类有三角形、矩形、圆。
import math
class Shape:
@property
def area(self):
raise NotImplementedError('基类未实现')
class Triangle(Shape):
def __init__(self, a, b, c):
self.a = a
self.b = b
self.c = c
@property
def area(self):
p = (self.a + self.b + self.c) / 2
return math.sqrt(p * (p - self.a) * (p - self.b) * (p - self.c))
class Rectangle(Shape):
def __init__(self, width, height):
self.width = width
self.height = height
@property
def area(self):
return self.width * self.height
class Circle(Shape):
def __init__(self, radius):
self.d = radius * 2
@property
def area(self):
return math.pi * self.d * self.d * 0.25
shapes = [Triangle(3, 4, 5), Rectangle(3, 4), Circle(4)]
for shape in shapes:
print('The area of {}={}'.format(shape.__class__.__name__, shape.area))2、圆类的数据可序列化
import math
import json
import msgpack
class Shape:
@property
def area(self):
raise NotImplementedError('基类未实现')
class Triangle(Shape):
def __init__(self, a, b, c):
self.a = a
self.b = b
self.c = c
@property
def area(self):
p = (self.a + self.b + self.c) / 2
return math.sqrt(p * (p - self.a) * (p - self.b) * (p - self.c))
class Rectangle(Shape):
def __init__(self, width, height):
self.width = width
self.height = height
@property
def area(self):
return self.width * self.height
class Circle(Shape):
def __init__(self, radius):
self.d = radius * 2
@property
def area(self):
return math.pi * self.d * self.d * 0.25
shapes = [Triangle(3, 4, 5), Rectangle(3, 4), Circle(4)]
for shape in shapes:
print('The area of {}={}'.format(shape.__class__.__name__, shape.area))
class SerializableMixin:
def dumps(self, t='json'):
if t == 'json':
return json.dumps(self.__dict__)
elif t == 'msgpack':
return msgpack.packb(self.__dict__)
else:
raise NotImplementedError('没有实现的序列化')
class SerializableCircleMixin(SerializableMixin, Circle):
pass
scm = SerializableCircleMixin(4)
print(scm.area)
s = scm.dumps('msgpack')
print(s)18.8.2、实现链表
用面向对象实现 LinkedList 链表。
-
单向链表实现 append、iternodes 方法。
-
双向链表实现 append、pop、insert、remove、 iternodes 方法。
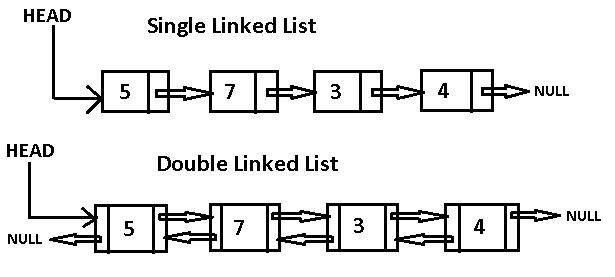
对于链表来说,每一个结点是一个独立的对象,结点自己知道内容是什么,下一跳是什么。
而链表则是一个容器,它内部装着一个个结点对象。
所以,建议设计 2 个类,一个是结点 Node 类,一个是链表 LinkedList 类。
18.8.2.1、单向链表
第一种实现:
class SingleNode: # 节点保存内容和下一跳
def __init__(self, item, next=None):
self.item = item
self.next = next
def __repr__(self):
return repr(self.item)
class LinkedList:
def __init__(self):
self.head = None
self.tail = None # 思考tail属性的作用
def append(self, item):
node = SingleNode(item)
if self.head is None:
self.head = node # 设置开头结点,以后不变
else:
self.tail.next = node # 当前最后一个结点关联下一跳
self.tail = node # 更新结尾结点
return self
def iternode(self):
current = self.head
while current:
yield current
current = current.next
ll = LinkedList()
ll.append('abc')
ll.append(1).append(2)
ll.append('def')
print(ll.head, ll.tail)
for item in ll.iternode():
print(item)第二种,借助列表实现:
class SingleNode: # 节点保存内容和下一跳
def __init__(self, item, next=None):
self.item = item
self.next = next
def __repr__(self):
return repr(self.item)
class LinkedList:
def __init__(self):
self.head = None
self.tail = None # 思考tail属性的作用
self.items = [] # 为什么在单向链表中使用list?
def append(self, item):
node = SingleNode(item)
if self.head is None:
self.head = node # 设置开头结点,以后不变
else:
self.tail.next = node # 当前最后一个结点关联下一跳
self.tail = node # 更新结尾结点
self.items.append(node)
return self
def iternode(self):
current = self.head
while current:
yield current
current = current.next
def getitem(self, index):
return self.items[index]
ll = LinkedList()
ll.append('abc')
ll.append(1).append(2)
ll.append('def')
print(ll.head, ll.tail)
for item in ll.iternode():
print(item)
for i in range(len(ll.items)):
print(ll.getitem(i))为什么在单向链表中使用 list?
因为只有结点自己知道下一跳是谁,想直接访问某一个结点只能遍历。
借助列表就可以方便的随机访问某一个结点了。
18.8.2.2、双向链表
实现单向链表没有实现的 pop、remove、insert 方法。
class SingleNode: # 节点保存内容和下一跳
def __init__(self, item, prev=None, next=None):
self.item = item
self.next = next
self.prev = prev # 增加上一跳
def __repr__(self):
return "({} <== {} ==> {})".format(
self.prev.item if self.prev else None,
self.item,
self.next.item if self.next else None
)
class LinkedList:
def __init__(self):
self.head = None
self.tail = None
self.size = 0 # 以后实现
def append(self, item):
node = SingleNode(item)
if self.head is None:
self.head = node # 设置开关结点,以后不变
else:
self.tail.next = node # 当前最后一个结点关联下一跳
node.prev = self.tail # 前后关联
self.tail = node
return self
def insert(self, index, item):
if index < 0: # 不接受负数
raise IndexError('Not negative index {}'.format(index))
current = None
for i, node in enumerate(self.iternodes()):
if i == index: # 找到了
current = node
break
else: # 没有break,尾部追加
self.append(item)
return
# break,找到了
node = SingleNode(item)
prev = current.prev
next = current
if prev is None: # 首部
self.head = node
else: # 不是首元素
prev.next = node
node.prev = prev
node.next = next
next.prev = node
def pop(self):
if self.tail is None: # 空
raise Exception("Empty")
node = self.tail
item = node.item
prev = node.prev
if prev is None: # only one node
self.head = None
self.tail = None
else:
prev.next = None
self.tail = prev
return item
def remove(self, index):
if self.tail is None: # 空
raise Exception('Empty')
if index < 0: # 不接受负数
raise IndexError('Not negative index {}'.format(index))
current = None
for i, node in enumerate(self.iternodes()):
if i == index:
current = node
break
else: # not found
raise IndexError('Wrong index {}'.format(index))
prev = current.prev
next = current.next
# 4 种情况
if prev is None and next is None: # only one node
self.head = None
self.tail = None
elif prev is None: # 头部
self.head = next
next.prev = None
elif next is None: # 尾部
self.tail = prev
prev.next = None
else: # 在中间
prev.next = next
next.prev = prev
del current
def iternodes(self, reverse=False):
current = self.tail if reverse else self.head
while current:
yield current
current = current.prev if reverse else current.next
ll = LinkedList()
ll.append('abc')
ll.append(1).append(2).append(3).append(4).append(5).append('def')
print(ll.head, ll.tail)
for x in ll.iternodes(True):
print(x)
print('*' * 50)
ll.remove(6)
ll.remove(5)
ll.remove(0)
ll.remove(1)
for x in ll.iternodes():
print(x)
print('*' * 50)
ll.insert(3, 5)
ll.insert(20, 'def')
ll.insert(1, 2)
ll.insert(0, 'abc')
for x in ll.iternodes():
print(x)