
13、python3 文件应用
13.1、open() 方法
Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意: 使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
open(file, mode='r')完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener:
mode 参数有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
默认为文本模式,如果要以二进制模式打开,加上 b 。
13.2、file 对象
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
| 序号 | 方法及描述 |
|---|---|
| 1 | file.close() 关闭文件。关闭后文件不能再进行读写操作。 |
| 2 | file.flush() 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| 3 | file.fileno() 返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| 4 | file.isatty() 如果文件连接到一个终端设备返回 True,否则返回 False。 |
| 5 | file.next() Python 3 中的 File 对象不支持 next() 方法。 返回文件下一行。 |
| 6 | file.read([size]) 从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| 7 | file.readline([size]) 读取整行,包括 "\n" 字符。 |
| 8 | file.readlines([sizeint]) 读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| 9 | file.seek(offset[, whence]) 设置文件当前位置 |
| 10 | file.tell() 返回文件当前位置。 |
| 11 | file.truncate([size]) 从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 Widnows 系统下的换行代表2个字符大小。 |
| 12 | file.write(str) 将字符串写入文件,返回的是写入的字符长度。 |
| 13 | file.writelines(sequence) 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
13.3、实践理解
f = open("test.txt",mode="w+")
# Windows <_io.TextIOWrapper name='test.txt' mode='w+' encoding='cp936'>
# Linux <_io.TextIOWrapper name='test.txt' mode='w+' encoding='UTF-8'>
print(f.read()) # 读文件
f.close() # 关闭文件文件访问的模式有两种,文本模式和二进制模式,不同模式下,操作函数不尽相同,表现的结果也不一样
13.3.1、open 的参数
13.3.1.1、mode 模式
>>> f = open("test.txt")
>>> f.write("abc")
>>> f.close()
-----------------------------------------------
UnsupportedOperation Traceback (most recent call last)
<ipython-input-10-a73b6e0cc61d> in <module>
1 f = open("test.txt")
----> 2 f.write("abc")
UnsupportedOperation: not writable
>>> f = open("test.txt",mode="r")
>>> f.write("abc")
>>> f.close()
-----------------------------------------------
UnsupportedOperation Traceback (most recent call last)
<ipython-input-12-c61d84458398> in <module>
1 f = open("test.txt",mode="r")
----> 2 f.write("abc")
3 f.close()
UnsupportedOperation: not writable
>>> f = open("test.txt",mode="w")
>>> f.write("abc")
>>> f.close()
>>> cat test.txt
-----------------------------------------------
# 查看不到内容,跟指针有关- open 默认以 r 模式打开已经存在的文件
- r 以只读的方式打开文件,如果 write,会抛异常;如果文件不存在,抛出 FileNotFoundError 异常
- w 表示只写方式打开,如果读取则抛出异常;如果文件不存在,则直接创建文件;如果文件存在则清空文件内容
>>> f = open("test1",mode="x")
>>> # f.read()
>>> f.write("abc")
>>> f.close()
>>> f = open("test1",mode="x")
-----------------------------------------------
FileExistsError: [Errno 17] File exists: 'test1'- x 文件不存在,创建文件,并只写方式打开;如果文件存在,则抛出 FileExistsError
>>> f = open("test2",mode="a")
>>> # f.read()
>>> f.write("abcd")
>>> f.close()- 文件存在,只写打开,追加内容;文件不存在,则创建后,只写打开,追加内容
r 是只读,wxa 都是只写;wxa 都可以产生新文件,w 不管文件存在与否,都会生成全新内容的文件;a 不管文件是否存在,都能在打开的文件尾部追加;x 必需要求文件事先不存在,自己创建一个新文件
>>> f = open("test3","rb") # 二进制只读
>>> s = f.read()
>>> print(type(s)) # bytes
>>> print(s)
>>> f.close()
>>> f = open("test3",'wb') # IO对象
>>> s = f.write("自学成才".encode())
>>> print(s)
>>> f.close()
-------------------------------------------------
<class 'bytes'>
b''
12- 文本模式 t,字符流,将文件的字节按照某种字符编码理解,按照字符操作;open 的默认 mode 就是 rt。
- 二进制模式 b,字节流,将文件就按照字节理解,与字符编码无关;二进制模式操作时,字节操作使用 bytes 类型。
>>> # f = open("test3","rw") 报错
>>> f = open("test3","r+")
>>> f.write("come on")
>>> print(f.read()) # 没有显示,为什么
>>> f.close()
>>> f = open("test3","w+")
>>> f.read()
>>> f.close()
>>> f = open("test3","a+")
>>> f.write("you")
>>> f.read()
>>> f.close()
>>> f = open("test4","x+")
>>> f.write("python")
>>> f.read()
>>> f.close()- + 为 r w a x 提供缺失的读写功能,但是,获取文件对象依旧按照 r w a x 自己的特征
- + 不能单独使用,可以认为它是为前面的模式字符做增强功能的
13.3.1.2、文件指针
mode=r,指针起始在0
mode=a,指针起始在EOF
tell() 显示指针当前位置
seek(offset[,whence]) 移动文件指针位置,offset 偏移多少字节,whence 从哪里开始
文本模式下
whence 0 缺省值,表示从头开始,offset 只能正整数
whence 1 表示从当前位置,offset 只接受 0
whence 2 表示从 EOF 开始,offset 只接受 0
# 文本模式
f = open("test4","r+")
print(1,"-->",f.tell()) # 起始
print(2,"-->",f.read())
print(3,"-->",f.tell()) # EOF
print(4,"-->",f.seek(0)) # 起始
print(5,"-->",f.read())
print(6,"-->",f.seek(2,0))
print(7,"-->",f.read())
# print(8,"-->",f.seek(2,1)) # UnsupportedOperation: can't do nonzero cur-relative seeks
# print(9,"-->",f.seek(2,2)) # UnsupportedOperation: can't do nonzero cur-relative seeks
f.close()
# 中文
f = open("test4","w+")
print(11,"-->",f.write("自学成才")) # 这个地方要注意一下,windows 的编码是 gbk
print(12,"-->",f.tell())
f.close()
f = open("test4","r+")
print(31,"-->",f.read(3))
print(32,"-->",f.seek(1))
print(33,"-->",f.tell())
# print(34,"-->",f.read()) # 报错,因为一个汉字用 gbk 编码,至少是 2 个字节
print(35,"-->",f.seek(2))
print(36,"-->",f.read())
f.close()
输出结果:
1 --> 0
2 --> 自学成才
3 --> 8
4 --> 0
5 --> 自学成才
6 --> 2
7 --> 学成才
11 --> 4
12 --> 8
31 --> 自学成
32 --> 1
33 --> 1
35 --> 2
36 --> 学成才- 文本模式支持从开头向后偏移的方式
- whence 为 1 表示从当前位置开始偏移,但是只支持偏移 0,相当于原地不动,所以没什么用
- whence 为 2 表示从 EOF 开始,只支持偏移 0,相当于移动文件指针到 EOF
- seek 是按照字节偏移的
二进制模式下
whence 0 缺省值,表示从头开始,offset 只能正整数
whence 1 表示从当前位置,offset 可正可负
whence 2 表示从 EOF 开始,offset 可正可负
# 二进制模式
f = open("test4","rb+")
print(1,"-->",f.tell())
print(2,"-->",f.read())
print(3,"-->",f.tell()) # EOF
print(4,"-->",f.write(b"abc"))
print(5,"-->",f.seek(0)) # 起始
print(6,"-->",f.seek(2,1)) # 从当前指针开始,向后 2
print(7,"-->",f.read())
print(8,"-->",f.seek(-2,1)) # 从当前指针开始,向前 2
print(9,"-->",f.seek(2,2)) # 从 EOF 开始,向后2
print(10,"-->",f.seek(0))
print(11,"-->",f.seek(-2,2)) # 从 EOF 开始,向前 2
print(12,"-->",f.read())
# print(13,"-->",f.seek(-20,2)) # OSError
f.close()
输出结果:
1 --> 0
2 --> b'\xd7\xd4\xd1\xa7\xb3\xc9\xb2\xc5abc'
3 --> 11
4 --> 3
5 --> 0
6 --> 2
7 --> b'\xd1\xa7\xb3\xc9\xb2\xc5abcabc'
8 --> 12
9 --> 16
10 --> 0
11 --> 12
12 --> b'bc'- 二进制模式支持任意起点的偏移,从头,从尾,从中间位置开始
- 向后 seek 可以超界,向是向前 seek 的时候,不能超界,否则抛异常
13.3.1.3、buffering 缓冲区
-1 表示使用缺省大小的 buffer,如果是二进制模式,使用 io.DEFAULT_BUFFER_SIZE 值,默认是 4096 或者 8192;如果是文本模式,如果是终端设备,是行缓存方式,如果不是,则使用二进制模式的策略
- 0 只在二进制模式使用,表示关 buffer
- 1 只在文本模式使用,表示使用行缓冲,意思就是见到换行符就 flush
- 大于 1 用于指定 buffer 的大小
buffer 缓冲区,缓冲区是一段内存空间,一般来说是一个 FIFO 队列,到缓冲区满了或者达到阈值,数据才会 flush 到磁盘
flush() 将缓冲区数据写入磁盘
close() 关闭前会调用 flush()
io.DEFAULT_BUFFER_SIZE 缺省缓冲区大小,字节
二进制模式
import io
f = open("test4","w+b")
print(io.DEFAULT_BUFFER_SIZE)
f.write("ccyunchina.com".encode())
!cat test4 # 没有输出
f.seek(0)
!cat test4 # 有输出,动了指针,f.read()也会刷新
f.write("www.ccyunchina.com".encode())
f.flush()
!cat test4 # 有输出
f.close()
输出结果:
8192
ccyunchina.com
www.ccyunchina.com
# 不调用 f.read()、f.seek(),也不手动刷新,直观感受撑满缓冲,自动刷新
f = open("test4","w+b",4)
f.write(b"yul")
!cat test4 # 没有输出
f.write(b"l")
!cat test4 # 没有输出,这里刚好满4个字节
f.write(b"!")
!cat test4 # 缓存已满,自动刷入磁盘
f.close()
输出结果:
yull # "!" 号为什么没有出来,"!" 号将刚满的4个字节刷到磁盘,自己留在缓冲区文本模式
# buffer=1, 使用行缓冲
f = open("test4","w+",1)
f.write("ccyun")
!cat test4
f.write("ccyunchian"*4)
!cat test4 # 到这里还是不会有输出
f.write("\n")
!cat test4 # 有输出
f.write("Hello\nPython")
!cat test4
f.close()
输出结果:
ccyunccyunchianccyunchianccyunchianccyunchian
ccyunccyunchianccyunchianccyunchianccyunchian
Hello
Python
# buffering>1, 使用指定大小的缓冲区
f = open("test4","w+",15)
f.write("ccyun")
!cat test4
f.write("china")
!cat test4
f.write("Hello\n")
!cat test4 # 没有输出
f.write("\nPython")
!cat test4 # 没有输出
f.close() # 由此可见,在文本模式下,设置大于1的数值没有多大作用
-------------------------------------------------------------
无输出
import io
f = open("test4","w+")
f.write("a" * (io.DEFAULT_BUFFER_SIZE - 20))
!cat test4 # 没有输出
f.write("a" * 20)
!cat test4 # 没有输出
f.write("a")
!cat test4 # 刚好输出
f.close()buffering = 0
这是一种特殊的二进制模式,不需要内存的 buffer,可以看作是一个 FIFO 的文件
f = open("test4","wb+",0)
f.write(b"m")
!cat test4
f.write(b"a")
!cat test4
f.write(b"g")
!cat test4
f.write(b"magedu"*4)
!cat test4
f.write(b"\n")
!cat test4
f.write(b"Hello\nPython")
!cat test4
f.close()
输出结果:
m
ma
mag
magmagedumagedumagedumagedu
magmagedumagedumagedumagedu
magmagedumagedumagedumagedu
Hello
Python| buffering | 说明 |
|---|---|
| buffering = -1 | t 和 b,都是io.DEFAULT_BUFFER_SIZE |
| buffering = 0 | b 关闭缓冲区 t 不支持 |
| buffering = 1 | b 就 1 个字节 t 行缓冲,遇到换行符才 flush |
| buffering > 1 | b 模式表示行缓冲大小。缓冲区的值可以超过 io.DEFAULT_BUFFER_SIZE,直到设定的值超出后才把缓冲区 flush t 模式,是 io.DEFAULT_BUFFER_SIZE,flush 完后把当前字符串也写入磁盘 |
似乎看起来比较麻烦,一般来说,只需要记得:
- 文本模式,一般都用默认缓冲区大小
- 二进制模式,是一个个字节的操作,可以指定 buffer 的大小
- 一般来说,默认缓冲区的大小是个比较好的选择,除非明确知道,否则不调整它
- 一般编程中,明确知道需要写磁盘了,都会手动调用一次 flush,而不是等到自动 flush 或者 close 的时候
13.3.1.4、encoding(仅文本模式使用)
None 表示使用缺省编码,依赖操作系统。 windows、linux 下测试如下代码
f = open("test1","w")
f.write("啊")
f.close()windows 下缺省 GBK( 0xB0A1 ),Linux 下缺省 UTF-8( 0xE5 95 8A )
13.3.1.5、其它参数
13.3.1.5.1、errors
-
什么样的编码错误将被捕获
-
None 和 strict 表示有编码错误将抛出 valueError 异常;ignore 表示忽略
13.3.1.5.2、newline
- 文本模式中,换行的转换,可以为 None、""空串、"\r"、"\n"、"\r\n"
- 读时,None 表示 "\r"、"\n"、"\r\n" 都被转换为"\n";""表示不会自动转换通用换行符;其它合法字符表示换行符就是指定字符,就会按照指定字符换行
- 写时,None 表示 "\n" 都会被替换为系统缺省行分隔符 os.linesep;"\n" 或 "" 表示 "\n" 不替换;其它合法字符表示 "\n" 会被替换为指定的字符
f = open("d:/test","w")
f.write("python\rwww.python.org\nwww.ccyunchina.com\r\npython3")
f.close()
newlines = [None,"","\n","\r\n"]
for nl in newlines:
f = open("d:/test","r+",newline=nl)
print(f.readlines())
f.close()
输出结果:
['python\n', 'www.python.org\n', 'www.ccyunchina.com\n', '\n', 'python3']
['python\r', 'www.python.org\r\n', 'www.ccyunchina.com\r', '\r\n', 'python3']
['python\rwww.python.org\r\n', 'www.ccyunchina.com\r\r\n', 'python3']
['python\rwww.python.org\r\n', 'www.ccyunchina.com\r\r\n', 'python3']
cat d:/test
python \r
www.python.org \r\n
www.ccyunchina.com \r
\r\n
python3- 注意文件在写入时也按照上述规则进行了转换,对照着文件对比规则
13.3.1.5.3、closefd
- 关闭文件描述符,True 表示关闭它。False 会在文件关闭后保持这个描述符。fileobj.fileno() 查看
13.3.2、行读写
13.3.2.1、read(size=-1)
- read(size=-1)
- size 表示读取的多少个字符或者字节;负数或 None 表示读取到 EOF
f = open("d:/test4","r+")
f.write("ccyunchina")
f.write("\n")
f.write("马哥教育")
f.seek(0)
print(f.read(12))
f.close()
print("~~~~~~~~~~~~~~~~~~~~~~~~~")
f = open("d:/test4","rb+")
print(f.read(7))
print(f.read(1))
f.close()
输出结果:
ccyunchina
马
~~~~~~~~~~~~~~~~~~~~~~~~~
b'ccyunch'
b'i'</code></pre>
<h4>13.3.3.2、readline(size=-1)</h4>
<p>一行行读取文件内容。size 设置一次能读取行内几个字符或字节。</p>
<p>f.readline() 会从文件中读取单独的一行。换行符为 '\n'。f.readline() 如果返回一个空字符串, 说明已经已经读取到最后一行。</p>
<pre><code class="language-bash">#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "r")
str = f.readline()
print(str)
# 关闭打开的文件
f.close()</code></pre>
<p>执行以上程序,输出结果为:</p>
<pre><code class="language-bash">Python 是一个非常好的语言。</code></pre>
<h4>13.3.3.3、readlines(hint=-1)</h4>
<p>读取所有行的列表。指定 hint 则返回指定的行数。</p>
<p>f.readlines() 将返回该文件中包含的所有行。</p>
<p>如果设置可选参数 sizehint, 则读取指定长度的字节, 并且将这些字节按行分割。</p>
<pre><code class="language-bash">#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "r")
str = f.readlines()
print(str)
# 关闭打开的文件
f.close()</code></pre>
<p>执行以上程序,输出结果为:</p>
<pre><code class="language-bash">['Python 是一个非常好的语言。\n', '是的,的确非常好!!\n']</code></pre>
<p>另一种方式是迭代一个文件对象然后读取每行:</p>
<pre><code class="language-bash">#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "r")
for line in f:
print(line, end='')
# 关闭打开的文件
f.close()</code></pre>
<p>执行以上程序,输出结果为:</p>
<pre><code class="language-bash">Python 是一个非常好的语言。
是的,的确非常好!!</code></pre>
<p>这个方法很简单, 但是并没有提供一个很好的控制。 因为两者的处理机制不同, 最好不要混用。</p>
<h4>13.3.3.4、write(s)</h4>
<p>把字符串 s 写入文件中并返回字符的个数。</p>
<p>f.write(string) 将 string 写入到文件中, 然后返回写入的字符数。</p>
<pre><code class="language-bash">#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "w")
num = f.write( "Python 是一个非常好的语言。\n是的,的确非常好!!\n" )
print(num)
# 关闭打开的文件
f.close()</code></pre>
<p>执行以上程序,输出结果为:</p>
<pre><code class="language-bash">29</code></pre>
<p>如果要写入一些不是字符串的东西, 那么将需要先进行转换:</p>
<pre><code class="language-bash">#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo1.txt", "w")
value = ('www.runoob.com', 14)
s = str(value)
f.write(s)
# 关闭打开的文件
f.close()</code></pre>
<p>执行以上程序,打开 foo1.txt 文件:</p>
<pre><code class="language-bash">$ cat /tmp/foo1.txt
('www.runoob.com', 14)</code></pre>
<h4>13.3.3.5、writelines(lines)</h4>
<ul>
<li>把字符串列表写入文件</li>
</ul>
<pre><code class="language-bash">f = open("test","w+")
lines = ["abc","123\n","ccyunchina"] # 提供换行符
f.writelines(lines)
f.seek(0)
print(f.read())
f.close()
输出结果:
abc123
ccyunchina</code></pre>
<h4>13.3.3.6、close</h4>
<ul>
<li>flush 并关闭文件对象</li>
<li>文件已经关闭,再关闭没有任何效果</li>
</ul>
<h4>13.3.3.7、其它</h4>
<pre><code class="language-bash">f = open("test","w+")
print(1,"-->",f.seekable())
print(2,"-->",f.readable())
print(3,"-->",f.writable())
print(4,"-->",f.closed)
f.close()
输出结果:
1 --> True
2 --> True
3 --> True
4 --> False</code></pre>
<h3>13.3.3、上下文管理</h3>
<p>问题的引出:在 linux 中,如下执行?</p>
<pre><code class="language-bash">lst = []
for _ in range(2000):
lst.append(open("test","w")) # OSError: [Errno 24] Too many open files: 'test'
print(len(lst))</code></pre>
<ul>
<li>lsof -p 1281 | grep test | wc -l 查看同时打开了多少个 test 文件</li>
<li>ulimit -a 查看所有限制。其中 open files 就是打开文件数的限制,默认 1024</li>
</ul>
<pre><code class="language-bash">for x in lst:
x.close()</code></pre>
<ul>
<li>将文件一次关闭,然后就可以继续打开了。再看一次 lsof。</li>
</ul>
<p>1、异常处理</p>
<p>当出现异常的时候,拦截异常。但是,因为很多代码都可能出现 OSError 异常,还不好判断异常就是因为资源限制产生的。</p>
<pre><code class="language-bash">f = open("test")
try:
f.write("abc") # 文件只读,写入失败
finally:
f.close() # 这样才行</code></pre>
<ul>
<li>使用 finally 可以保证打开的文件被关闭</li>
</ul>
<p>2、上下文管理</p>
<p>一种特殊的语法,交给解释器去释放文件对象</p>
<pre><code class="language-bash">del f
with open("test") as f:
f.write("abc") # 文件只读,写入失败
# 测试 f 是否关闭
f.closed # f的作用域</code></pre>
<h2>13.4、练习</h2>
<p>1、指定一个源文件,实现 copy 到目标目录</p>
<pre><code class="language-bash">filename1 = "/tmp/test.txt"
filename2 = "/tmp/test1.txt"
f = open(filename1,"w+")
lines = ["abc","123","ccyunchina"]
f.writelines("\n".join(lines))
f.seek(0)
print(f.read())
f.close()
def copy(src,dest):
with open(src) as f1:
with open(dest,"w") as f2:
f2.write(f1.read())
copy(filename1,filename2)
print("~~~~~~~~~~~~~~~~~~")
!cat /tmp/test1.txt
输出结果:
abc
123
ccyunchina
~~~~~~~~~~~~~~~~~~
abc
123
ccyunchina2、有一个文件,对其进行单词统计,不区分大小写,并显示单词重复最多的10个单词
d = {}
with open ("/tmp/sample.txt",encoding="utf8") as f:
for line in f:
words = line.split()
for word in map(str.lower,words):
d[word] = d.get(word,0) + 1
print(sorted(d.items(),key=lambda item: item[1],reverse=True)[:10])
输出结果:
[('the', 136), ('is', 60), ('a', 54), ('path', 52), ('if', 42), ('and', 39), ('to', 34), ('of', 33), ('on', 32), ('return', 30)]这种代码只能解决空格分割的字符串,如果像 "os.path.exists(path)" 这种字符串被认为含有 2 个 path,怎么改进
def makekey(s:str):
chars = set(r"""!"'#./\()[],*-""")
key = s.lower()
ret = []
for i,c in enumerate(key):
if c in chars:
ret.append(" ")
else:
ret.append(c)
return "".join(ret).split()
d = {}
with open ("/tmp/sample.txt",encoding="utf8") as f:
for line in f:
words = line.split()
for wordlist in map(makekey,words):
for word in wordlist:
d[word] = d.get(word,0) + 1
print(sorted(d.items(),key=lambda item: item[1],reverse=True)[:10])
输出结果:
[('path', 138), ('the', 136), ('is', 60), ('a', 59), ('os', 49), ('if', 43), ('and', 40), ('to', 34), ('on', 33), ('of', 33)]# 分割 key 的另一种思路
def makekey(s:str):
chars = set(r"""!'"#./\()[],*-""")
key = s.lower()
ret = []
start = 0
length = len(key)
for i, c in enumerate(key):
if c in chars:
if start == i:
start += 1
continue
ret.append(key[start:i])
start = i + 1
else:
if start < len(key):
ret.append(key[start:])
return ret
print(makekey("os.path.-exists(path))"))
输出结果:
['os', 'path', 'exists', 'path']13.5、StringIO 和 BytesIO
13.5.1、StringIO
- io 模块中的类
- from io import StringIO
- 内存中,开辟的一个文本模式的 buffer,可以像文件对象一样操作它
- 当 close 方法被调用的时候,这个 buffer 会被释放
getvalue() 获取全部内容。跟文件指针没有关系
from io import StringIO
sio = StringIO() # 内存中构建,像文件对象一样操作
print(sio.readable(),sio.writable(),sio.seekable())
sio.write("magedu\nPython")
sio.seek(0)
print(sio.readline())
print(sio.getvalue()) # 无视指针,输出全部内容
sio.close()
输出结果:
True True True
magedu
magedu
Python- 一般来说,磁盘的操作比内存的操作要慢得多,内存足够情况下,一般的优化思路是少落地,减少磁盘IO的过程,可以大大提高程序的运行效率
13.5.2、BytesIO
- io 模块中的类
- from io import BytesIO
- 内存中,开辟的一个二进制模式的 buffer,可以像文件对象一样操作它
- 当 close 方法被调用的时候,这个 buffer 会被释放
from io import BytesIO
bio = BytesIO()
print(bio.readable(),bio.writable(),bio.seekable())
bio.write(b"ccyunchina\nPython")
bio.seek(0)
print(bio.readline())
print(bio.getvalue()) # 无视指针,输出全部内容
bio.close()
输出结果:
True True True
b'ccyunchina\n'
b'ccyunchina\nPython'13.5.3、file-like 对象
- 类文件对象,可以像文件对象一样操作
- socket 对象、输入输出对象(stdin、stdout)都是类文件对象
from sys import stdout
f = stdout
print(type(f))
f.write("ccyunchina.com")
输出结果:
<class 'ipykernel.iostream.OutStream'>
ccyunchina.com13.6、路径操作
13.6.1、os.path
Python3.4 版本之前,路径操作模块是 os.path
from os import path
p = path.join("/etc","sysconfig","network")
print(1,"-->",type(p),p)
print(2,"-->",path.exists(p))
print(3,"-->",path.split(p)) # (head,tail)
print(4,"-->",path.abspath("."))
print(5,"-->",path.dirname(p))
print(6,"-->",path.basename(p))
print(7,"-->",path.splitdrive(p))
print("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~")
p1 = path.abspath(p)
print(p1,path.basename(p1))
while p1 != path.dirname(p1):
p1 = path.dirname(p1)
print(p1,path.basename(p1))
------------------------------------------------------------------
1 --> <class 'str'> /etc/sysconfig/network
2 --> True
3 --> ('/etc/sysconfig', 'network')
4 --> /root
5 --> /etc/sysconfig
6 --> network
7 --> ('', '/etc/sysconfig/network')
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
/etc/sysconfig/network network
/etc/sysconfig sysconfig
/etc etc
/Python3.4 版本之后,建议使用 pathlib 模块,提供 Path 对象来操作。包括目录和文件。
13.6.2、pathlib 模块
13.6.2.1、目录操作
初始化
from pathlib import Path
p = Path() # 当前目录
p = Path("a","b","c/d") # 当前目录下的 a/b/c/d
p = Path("/etc") # 根下的 etc 目录路径拼接和分解
操作符 /
- Path 对象 / Path 对象
- Path 对象 / 字符串或者字符串 / Path 对象
分解
- parts 属性,可以返回路径中的每一个部分
joinpath
- joinpath(*other) 连接多个字符串到 Path 对象中
from pathlib import Path
p = Path()
print(1,"-->",type(p))
print(2,"-->",p)
p = p / "a"
p1 = "b" / p
print(3,"-->",p1)
p2 = Path("c")
print(4,"-->",p2)
p3 = p2 / p1
print(5,"-->",p3)
print(6,"-->",p3.parts)
print(7,"-->",p3.joinpath("etc","init.d",Path("httpd")))
----------------------------------------------------------------
1 --> <class 'pathlib.PosixPath'>
2 --> .
3 --> b/a
4 --> c
5 --> c/b/a
6 --> ('c', 'b', 'a')
7 --> c/b/a/etc/init.d/httpd获取路径
- str 获取路径字符串
- bytes 获取路径字符串的 bytes
from pathlib import Path
p = Path("/etc")
print(str(p),bytes(p))
-----------------------------------------------------------------
/etc b'/etc'父目录
- parent 目录的逻辑父目录
- parents 父目录序列,索引 0 是直接的父
from pathlib import Path
p = Path("/a/b/c/d")
print(p.parent.parent)
for x in p.parents:
print(x)
print(p.parents[len(p.parents)-1])
-----------------------------------------------------------------
/a/b
/a/b/c
/a/b
/a
/
/name、stem、suffix、suffixes、with_suffix(suffix)、with_name(name)
- name 目录的最后一个部分
- suffix 目录中最后一个部分的扩展名
- stem 目录最后一个部分,没有后缀
- suffixes 返回多个扩展名列表
- with_suffix(suffix) 补充扩展名到路径尾部,返回新的路径,扩展名存在则无效
- with_name(name) 替换目录最后一个部分并返回一个新的路径
from pathlib import Path
p = Path("/magedu/mysqlinstall/mysql.tar.gz")
print(1,"-->",p.name)
print(2,"-->",p.suffix)
print(3,"-->",p.stem)
print(4,"-->",p.with_name("mysql-5.tgz"))
p = Path("README")
print(11,"-->",p.with_suffix(".txt"))
--------------------------------------------------------------------
1 --> mysql.tar.gz
2 --> .gz
3 --> mysql.tar
4 --> /magedu/mysqlinstall/mysql-5.tgz
11 --> README.txtfrom pathlib import Path
p = Path("/magedu/mysqlinstall/mysql.tar.gz")
print(1,"-->",p.cwd()) # 返回当前工作目录
print(2,"-->",p.home()) # 返回当前家目录
print(3,"-->",p.is_dir()) # 是否是目录
print(4,"-->",p.is_file()) # 是否是普通文件
print(5,"-->",p.is_symlink()) # 是否是软链接
print(6,"-->",p.is_socket()) # 是否是 socket 文件
print(7,"-->",p.is_block_device()) # 是否是块设备
print(8,"-->",p.is_char_device()) # 是否是字符设备
print(9,"-->",p.is_absolute()) # 是否是绝对路径
print(10,"-->",p.resolve()) # 返回一个新的路径,这个新路径就是当前 Path 对象的绝对路径,如果是软链接则直接被解析
print(11,"-->",p.absolute()) # 也可以获取绝对路径,但是推荐使用 resolve()
print(12,"-->",p.exists()) # 目录或文件是否存在
print(13,"-->",p.rmdir()) # 删除空目录。没有提供判断目录为空的方法
print(14,"-->",p.touch(mode=0o666,exist_ok=True)) # 创建一个文件
print(15,"-->",p.as_uri()) # 将路径返回成 URI,例如 "file:///etc/passwd"
print(16,"-->",p.mkdir(mode=0o777,parents=True,exist_ok=True))
# parents,是否创建父目录,True 等同于 mkdir -p;False时,父目录不存在,抛出 FileNotFoundError
# exist_ok 参数,在 3.5 版本加入。 False时,路径存在,抛出 FileExistsError;True时,FileExistsError被忽略
迭代当前目录
from pathlib import Path
p = Path()
p /= "a/b/c/d"
print(p.exists())
for x in p.parents[len(p.parents)-1].iterdir():
print(x,end="\t")
if x.is_dir():
flag = False
for _ in x.iterdir():
flag = True
break
print("dir","Not Empty" if flag else "Empty",sep="\t")
elif x.is_file():
print("file")
else:
print("other file")
--------------------------------------------------------------------
True
.bash_logout file
.bash_profile file
.bashrc file
.cshrc file
.tcshrc file
original-ks.cfg file
anaconda-ks.cfg file
.bash_history file
.cache dir Not Empty
.ipython dir Not Empty
test.txt file通配符 --> 返回一个生成器
- glob(pattern) 通配给定的模式
- rglob(pattern) 通配给定的模式,递归目录
from pathlib import Path
p = Path()
p1 = list(p.glob(".*")) # 返回当前目录下以 . 开头的文件
p2 = list(p.glob("**/*.py")) # 递归所有目录,等同 rglob
print(p2)
g = p.rglob("*.py") # 生成器
print(1,"-->",next(g))
print(2,"-->",next(g))
--------------------------------------------------------
[PosixPath('a/b/c/d/1.py'), PosixPath('a/b/c/d/2.py'), PosixPath('a/b/c/d/3.py')]
1 --> a/b/c/d/1.py
2 --> a/b/c/d/2.py模式匹配 --> 返回 True/False
- match(pattern)
from pathlib import Path
print(1,"-->",Path('a/b.py').match("*.py"))
print(2,"-->",Path('a/b/c.py').match('b/*.py'))
print(3,"-->",Path("/a/b/c.py").match("a/*.py"))
print(4,"-->",Path("/a/b/c.py").match('a/*/*.py'))
print(5,"-->",Path('/a/b/c.py').match('a/**/*.py'))
print(6,"-->",Path('/a/b/c.py').match('**/*.py'))
-----------------------------------------------------------
1 --> True
2 --> True
3 --> False
4 --> True
5 --> True
6 --> True显示文件信息
- stat() 相当于 stat 命令
- lstat() 同 stat(),但如果是符号链接,则显示符号链接本身的文件信息
[root@lytest1 ~]# ln -sv test t
‘t’ -> ‘test’
from pathlib import Path
p = Path("test")
print(1,"-->",p.stat())
print()
p1 = Path('t')
print(2,"-->",p1.stat())
print()
print(3,"-->",p1.lstat())
---------------------------------------------------------------
1 --> os.stat_result(st_mode=33188, st_ino=100735060, st_dev=64768, st_nlink=1, st_uid=0, st_gid=0, st_size=0, st_atime=1587271470, st_mtime=1587272239, st_ctime=1587272239)
2 --> os.stat_result(st_mode=33188, st_ino=100735060, st_dev=64768, st_nlink=1, st_uid=0, st_gid=0, st_size=0, st_atime=1587271470, st_mtime=1587272239, st_ctime=1587272239)
3 --> os.stat_result(st_mode=41471, st_ino=101232439, st_dev=64768, st_nlink=1, st_uid=0, st_gid=0, st_size=4, st_atime=1587340972, st_mtime=1587340956, st_ctime=1587340956)13.6.2.2、文件操作
open(mode='r',buffering=-1,encoding=None,errors=None,newline=None) --> 返回一个文件对象
- 使用方法类似内建函数 open
- read_bytes(),以 'rb' 读取路径对应文件,并返回二进制流。看源码
- read_text(encoding=None,errors=None),以 'rt' 方式读取路径对应文件,返回文本
- Path.write_bytes(data),以 'wb' 方式写入数据到路径对应文件
- write_text(data,encoding=None,errors=None),以 'wt' 方式写入字符串到路径对应文件
from pathlib import Path
p = Path("my_binary_file")
p.write_bytes(b"Binary file contents\n")
print(1,"-->",p.read_bytes())
p = Path("my_text_file")
p.write_text("Text file contents\n")
print(2,"-->",p.read_text())
p = Path("test.py")
p.write_text("hello python")
print(3,"-->",p.read_text())
with p.open() as f:
print(1,"-->",f.read(7))
------------------------------------------------------------------------
1 --> b'Binary file contents\n'
2 --> Text file contents
3 --> hello python
1 --> hello p13.7、OS 模块
操作系统平台
| 属性或方法 | 结果 |
|---|---|
| os.name | windows 是 nt,linux 是 posix |
| os.uname() | *nix 支持 |
| sys.platform | windows 显示 win32,linux 显示 linux |
os.listdir("d:") --> 返回目录内容列表
os 也有 open、read、write 等方法,但是太低级,建议使用内建函数 open、read、write,使用方法相似
[root@lytest1 ~]# ln -sv test t1
‘t1’ -> ‘test’os.stat(path,*,dir_fd=None,follow_symlinks=True),本质上调用 linux 系统的 stat
- path,路径的 string 或者 bytes,或者 fd 文件描述符
- follow_symlinks True,返回文件本身信息,False 且如果是软链接则显示软链接本身
import os,sys
print(1,"-->",os.stat("test"))
print(2,"-->",os.stat("t1",follow_symlinks=True))
print(3,"-->",os.stat("t1",follow_symlinks=False))
-----------------------------------------------------------------
1 --> os.stat_result(st_mode=33188, st_ino=100735060, st_dev=64768, st_nlink=1, st_uid=0, st_gid=0, st_size=0, st_atime=1587271470, st_mtime=1587272239, st_ctime=1587272239)
2 --> os.stat_result(st_mode=33188, st_ino=100735060, st_dev=64768, st_nlink=1, st_uid=0, st_gid=0, st_size=0, st_atime=1587271470, st_mtime=1587272239, st_ctime=1587272239)
3 --> os.stat_result(st_mode=41471, st_ino=101232445, st_dev=64768, st_nlink=1, st_uid=0, st_gid=0, st_size=4, st_atime=1587387215, st_mtime=1587386620, st_ctime=1587386620)os.chmod(path,mode,*,dir_fd=None,follow_symlinks=True)
os.chmod("test",0o777)
os.chown(path,uid,gid),改变文件的属主、属组,但需要足够的权限
13.7.1、shutil 模块
拷贝文件时,如果只是将内容进行拷贝,那很容易丢失信息,像 stat 数据信息、权限等;Python 提供了一个方便的库 shutil(高级文件操作)
13.7.2、copy 复制
copyfileobj(fsrc,fdst[,length])
- 文件对象的复制,fsrc 和 fdst 是 open 打开的文件对象,复制内容。fdst 要求可写
- length 指定了表示 buffer 的大小
import shutil
with open("test","r+") as f1:
f1.write("abcd\n1234")
f1.flush()
with open("test1","w+") as f2:
shutil.copyfileobj(f1,f2)
!cat test1 # 为什么会是空的呢
# 看一下源码
def copyfileobj(fsrc, fdst, length=16*1024):
"""copy data from file-like object fsrc to file-like object fdst"""
while 1:
buf = fsrc.read(length)
if not buf:
break
fdst.write(buf)
# f1 flush() 后内容写到 test,但是指针在哪里?
# 指针在末尾,所以源码中 read 再 write 是空
改成:
import shutil
with open("test","r+") as f1:
f1.write("abcd\n1234")
f1.flush()
f1.seek(0)
with open("test1","w+") as f2:
shutil.copyfileobj(f1,f2)
!cat test1copyfile(src,dst,*,follow_symlinks=True)
- 复制文件内容,不含元数据。src、dst 为文件的路径字符串,本质上调用的就是 copyfileobj,所以不带元数据二进制内容复制。
copymode(src,dst,*,follow_symlinks=True)
- 仅仅复制权限。
import shutil,os
shutil.copyfile("test","test1")
print(1,"-->",os.stat("test"))
print(2,"-->",os.stat("test1"))
!chmod -x test
!ls -l test test1
print()
shutil.copymode("test","test1")
print(1,"-->",os.stat("test"))
print(2,"-->",os.stat("test1"))
!ls -l test test1
-----------------------------------------------------------------------------
1 --> os.stat_result(st_mode=33261, st_ino=100735060, st_dev=64768, st_nlink=1, st_uid=0, st_gid=0, st_size=0, st_atime=1587728047, st_mtime=1587272239, st_ctime=1587728029)
2 --> os.stat_result(st_mode=33261, st_ino=101232444, st_dev=64768, st_nlink=1, st_uid=0, st_gid=0, st_size=0, st_atime=1587388696, st_mtime=1587728047, st_ctime=1587728047)
-rw-r--r-- 1 root root 0 Apr 19 12:57 test
-rwxr-xr-x 1 root root 0 Apr 24 19:34 test1
1 --> os.stat_result(st_mode=33188, st_ino=100735060, st_dev=64768, st_nlink=1, st_uid=0, st_gid=0, st_size=0, st_atime=1587728047, st_mtime=1587272239, st_ctime=1587728047)
2 --> os.stat_result(st_mode=33188, st_ino=101232444, st_dev=64768, st_nlink=1, st_uid=0, st_gid=0, st_size=0, st_atime=1587388696, st_mtime=1587728047, st_ctime=1587728048)
-rw-r--r-- 1 root root 0 Apr 19 12:57 test
-rw-r--r-- 1 root root 0 Apr 24 19:34 test1copystat(src, dst, *, follow_symlinks=True)
- 复制元数据,stat 包含权限
import shutil,os
!stat test test1
shutil.copystat("test","test1")
!stat test test1
------------------------------------------------------------------------------
File: ‘test’
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: fd00h/64768d Inode: 100735060 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2020-04-24 19:34:07.783686437 +0800
Modify: 2020-04-19 12:57:19.418985610 +0800
Change: 2020-04-24 19:34:07.799686559 +0800
Birth: -
File: ‘test1’
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: fd00h/64768d Inode: 101232444 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2020-04-20 21:18:16.915399593 +0800
Modify: 2020-04-24 19:34:07.783686437 +0800
Change: 2020-04-24 19:34:08.035688370 +0800
Birth: -
File: ‘test’
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: fd00h/64768d Inode: 100735060 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2020-04-24 19:34:07.783686437 +0800
Modify: 2020-04-19 12:57:19.418985610 +0800
Change: 2020-04-24 19:34:07.799686559 +0800
Birth: -
File: ‘test1’
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: fd00h/64768d Inode: 101232444 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2020-04-24 19:34:07.783686437 +0800
Modify: 2020-04-19 12:57:19.418985610 +0800
Change: 2020-04-24 19:40:28.879436570 +0800
Birth: -copy(src, dst, *, follow_symlinks=True)
- 复制文件内容、权限和部分元数据,不包括创建时间和修改时间
- 本质上调用的是
- copyfile(src, dst, follow_symlinks=follow_symlinks)
- copymode(src, dst, follow_symlinks=follow_symlinks)
copy2 比 copy 多了复制全部元数据,但需要平台支持
- 本质上调用的是
- copyfile(src, dst, follow_symlinks=follow_symlinks)
- copystat(src, dst, follow_symlinks=follow_symlinks)
copytree(src, dst, symlinks=False, ignore=None, copy_function=copy2, ignore_dangling_symlinks=False)
- 递归复制目录。默认使用 copy2,也就是带更多的元数据复制
- src、dst 必须是目录,src 必须存在,dst 必须不存在
- ignore = func,提供一个 callable(src, names) -> ignored_names。提供一个函数,它会被调用。src 是源目录,names 是 os.listdir(src) 的结果,就是列出 src 中的文件名,返回值是要被过滤的文件名的 set 类型数据
# d:/temp 下有 a、b 目录
# 要结合源码看
def ignore(src,names):
ig = filter(lambda x: x.startswith("a"),names) # 返回以a开头为true的迭代器
return set(ig) # 返回集合,去重
import shutil
shutil.copytree("d:/temp","d:/tt/o",ignore=ignore)13.7.3、rm 删除
shutil.rmtree(path, ignore_errors=False, onerror=None)
- 递归删除,如同 rm -rf 一样危险,慎用
- 它不是原子操作,有可能删除错误,就会中断,已经删除的就删除了
- ignore_errors 为 true,忽略错误,当为 False 或者 omitted 时 onerror 生效
- onerror 为 callable,接受函数 function、path 和 execinfo
shutil.rmtree("d:/temp") # 类似 rm -rf13.7.4、move 移动
move(src, dst, copy_function=copy2)
- 递归移动文件、目录到目标,返回目标
- 本身使用的是 os.rename 方法
- 如果不支持 rename,如果是目录则想 copytree 再删除源目录
- 默认使用 copy2 方法
os.rename("d:/t.txt","d:/temp/t")
os.rename("test3","/tmp/py/test300")shutil 还有打包功能,生成 tar 并压缩,支持 zip、gz、bz、xz
13.8、文件高级用法
13.8.1、CSV 文件简介
csv 文件的基本要义:
-
逗号分隔值 Comma-Separated Values
-
csv 是一个被行分割符、列分割符划分成行和列的文本文件
-
csv 不指定字符编码
-
行分隔符为 \r\n,最后一行可以没有换行符
-
列分隔符常为逗号或者制表符
-
每一行称为一条记录 record
-
字段可以使用双引号括起来,也可以不使用;如果字段中出现了双引号、逗号、换行符必须使用双引号括起来;如果字段的值是双引号,使用两个双引号表示一个转义
-
表头可选,和字段列对齐就行了
13.8.1.1、手动生成 csv 文件
from pathlib import Path
p = Path('d:/tmp/mycsv/test.csv')
parent = p.parent
if not parent.exists():
parent.mkdir(parents=True)
csv_body = '''\
id,name,age,comment
1,zs,18,"I'm 18"
2,ls,20,"this is a ""test"" string."
3,ww,23,"你好
计算机
"
'''
p.write_text(csv_body)13.8.1.2、csv 模块
csv.reader(csvfile, dialect='excel', **fmtparams)- 这是 python 帮助文档里面的指示,源码很简陋,容易误导
- 返回 DictReader 对象,是一个行迭代器
通过帮助文档,可得简单的使用方法
import csv
with open('eggs.csv', newline='') as csvfile:
spamreader = csv.reader(csvfile, delimiter=' ', quotechar='|')
for row in spamreader:
print(', '.join(row))
Spam, Spam, Spam, Spam, Spam, Baked Beans
Spam, Lovely Spam, Wonderful Spamimport csv
p = Path("d:/tmp/mycsv/test.csv")
with open(str(p)) as f:
reader = csv.reader(f)
for i in reader:
print(i)
-----------------------------------------------------
['id', 'name', 'age', 'comment']
['1', 'zs', '18', "I'm 18"]
['2', 'ls', '20', 'this is a "test" string.']
['3', 'ww', '23', '你好\n\n计算机\n']import csv
p = Path("d:/tmp/mycsv/test.csv")
with open(str(p)) as f:
reader = csv.reader(f)
print(1,"-->",next(reader))
print(2,"-->",next(reader))
rows = [
[4,'tom',22,'tom'],
(5,'jerry',24,'jerry'),
(6,'justin',22,'just\t"in'),
"abcdefghi",
((1,),(2,))
]
row = rows[0]
p = Path("d:/tmp/mycsv/test.csv")
with open(str(p),'a+') as f:
writer = csv.writer(f)
writer.writerow(row)
writer.writerows(rows)
------------------------------------------------------------
1 --> ['id', 'name', 'age', 'comment']
2 --> ['1', 'zs', '18', "I'm 18"]13.8.2、ini 文件处理
作为配置文件,ini 文件格式很流行
[DEFAULT]
a = test
[mysql]
default-character-set=utf8
[mysqld]
datadir=/dbserver/data
port=33060
character-set-server=utf8
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES- 括号里面的部分称为 section,译作节、区、段
- 每一个 section 内,都有 key=value 形成的键值对,key 称为 option 选项
- 注意这里的 DEFAULT 是缺省 section 的名字,必须大写
13.8.3、configparser 模块
configparser 模块的 ConfigParser 类就是用来操作。
可以将 section 当作 key,section 存储着键值对组成的字典,可以把 ini 配置文件当作一个嵌套的字典。默认使用的是有序字典。
-
read(filenames, encoding=None)
读取 ini 文件,可以是单个文件,也可以是文件列表。可以指定文件编码。
-
sections()
返回 section 列表。缺省 section 不包括在内。
-
add_section(section_name)
增加一个 section。
-
has_section(section_name)
判断 section 是否存在。
-
options(section)
返回 section 的所有 option,会追加缺省 section 的 option。
-
has_option(section, option)
判断 section 是否存在这个 option。
-
get(section, option, *, raw=False, vars=None[, fallback])
从指定的段的选项上取值,如果找到就返回值,如果没有找到就去找 DEFAULT 段有没有。
getint(section, option, *, raw=False, vars=None[, fallback])。
getfloat(section, option, *, raw=False, vars=None[, fallback])。
getboolean(section, option, *, raw=False, vars=None[, fallback])。
上面 3 个方法和 get 一样,返回指定类型数据。
-
items(raw=False, vars=None),items(section, raw=False, vars=None)
没有 section,则返回所有 section 名字及其对象;
如果指定 section,则返回这个指定 section 的键值对组成二元组。
-
set(section, option, value)
section 存在的情况下,写入 option=value,要求 option、value 必须是字符串。
-
remove_section(section)
移除 section 及其所有 option。
-
remove_option(section, option)
移除 section 下的 option。
-
write(fileobject, space_around_delimiters=True)
将当前 config 的所有内容写入 fileobject 中,一般 open 函数使用 w 模式。
from configparser import ConfigParser
ini_body="""\
[DEFAULT]
a = test
[mysql]
default-character-set=utf8
[mysqld]
datadir=/dbserver/data
port=33060
character-set-server=utf8
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
"""
with open("test.ini","w+") as f:
f.write(ini_body)
f.seek(0)
print("- - -")
print(f.read())
filename = "test.ini"
newfilename = "mysql.ini"
cfg = ConfigParser()
cfg.read(filename)
print("- - -")
print(1,"-->",cfg.sections())
print(2,"-->",cfg.has_section("client"))
print(3,"-->",cfg.items("mysqld"))
conter = 0
for k,v in cfg.items():
print(conter,"-->",k,type(v))
print(conter,"-->",k,cfg.items(k))
conter += 1
tmp = cfg.get("mysqld","port")
print(11,"-->",type(tmp),tmp)
print(12,"-->",cfg.get("mysqld","a"))
# print(13,"-->",cfg.get("mysqld","ccyunchina"))
print(14,"-->",cfg.get("mysqld","ccyunchina",fallback="python"))
tmp = cfg.getint("mysqld","port")
print(21,"-->",type(tmp),tmp)
if cfg.has_section("test"):
cfg.remove_section("test")
cfg.add_section("test")
cfg.set("test","test1","1")
cfg.set("test","test2","2")
with open(newfilename,"w") as f:
cfg.write(f)
print(31,"-->",cfg.getint("test","test2"))
cfg.remove_option("test","test2")
-----------------------------------------------------------------------------------
- - -
[DEFAULT]
a = test
[mysql]
default-character-set=utf8
[mysqld]
datadir=/dbserver/data
port=33060
character-set-server=utf8
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
- - -
1 --> ['mysql', 'mysqld']
2 --> False
3 --> [('a', 'test'), ('datadir', '/dbserver/data'), ('port', '33060'), ('character-set-server', 'utf8'), ('sql_mode', 'NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES')]
0 --> DEFAULT <class 'configparser.SectionProxy'>
0 --> DEFAULT [('a', 'test')]
1 --> mysql <class 'configparser.SectionProxy'>
1 --> mysql [('a', 'test'), ('default-character-set', 'utf8')]
2 --> mysqld <class 'configparser.SectionProxy'>
2 --> mysqld [('a', 'test'), ('datadir', '/dbserver/data'), ('port', '33060'), ('character-set-server', 'utf8'), ('sql_mode', 'NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES')]
11 --> <class 'str'> 33060
12 --> test
14 --> python
21 --> <class 'int'> 33060
31 --> 2
True字典操作更简单
from configparser import ConfigParser
ini_body="""\
[DEFAULT]
a = test
[mysql]
default-character-set=utf8
[mysqld]
datadir=/dbserver/data
port=33060
character-set-server=utf8
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
"""
with open("test.ini","w+") as f:
f.write(ini_body)
f.seek(0)
print("- - -")
print(f.read())
filename = "test.ini"
newfilename = "mysql.ini"
cfg = ConfigParser()
cfg.read(filename)
print("- - -")
print(1,"-->",cfg.sections())
print(2,"-->",cfg.has_section("client"))
if cfg.has_section("test"):
cfg.remove_section("test")
cfg.add_section("test")
cfg.set("test","test1","1")
cfg.set("test","test2","2")
with open(newfilename,"w") as f:
cfg.write(f)
cfg["test"]["x"] = "100" # key 不存在
cfg["test2"] = {"test2": "1000"} # section 不存在
print(11,"-->","x" in cfg["test"])
print(12,"-->","x" in cfg["test2"])
print(21,"-->",cfg._dict) # 返回默认字典类型,内部使用有序字典
with open(newfilename,'w') as f:
cfg.write(f)
print("- - -")
with open(newfilename) as f:
print(f.read())
----------------------------------------------------------------------
- - -
[DEFAULT]
a = test
[mysql]
default-character-set=utf8
[mysqld]
datadir=/dbserver/data
port=33060
character-set-server=utf8
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
- - -
1 --> ['mysql', 'mysqld']
2 --> False
11 --> True
12 --> False
21 --> <class 'collections.OrderedDict'>
- - -
[DEFAULT]
a = test
[mysql]
default-character-set = utf8
[mysqld]
datadir = /dbserver/data
port = 33060
character-set-server = utf8
sql_mode = NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
[test]
test1 = 1
test2 = 2
x = 100
[test2]
test2 = 100013.9、序列化和反序列化
为什么要序列化?
- 内存中的字典、列表、集合以及各种对象,如何保存到一个文件中?
- 如果是自己定义的类的实例,如何保存到一个文件中?
- 如何从文件中读取数据,并让他们在内存中再次变成自己对应的类的实例?
- 要设计一套协议,按照某种规则,把内存中数据保存到文件中。文件是一个字节序列,所以必须把数据转换成字节序列,输出到文件。这就是序列化。反之,从文件的字节序列恢复到内存,就是反序列化。
定义:
- serialization
- 序列化,将内存中对象存储下来,把它变成一个个字节 --> 二进制
- deserialization
- 反序列化,将文件的一个个字节恢复成内存中对象 <-- 二进制
- 序列化保存到文件就是持久化
- 可以将数据序列化后持久化,或者网络传输;也可以将从文件中或者网络接收到的字节序列反序列化
13.9.1、pickle 库
pickle 是 python 中的序列化、反序列化模块
- dumps 对象序列化为 bytes 对象
- dump 对象序列化到文件对象,就是存入文件
- loads 从 bytes 对象反序列化
- load 对象反序列化,从文件读取数据
import pickle
filename = "d:/tmp/ser"
d = {"a":1,"b":"abc","c":[1,2,3]}
l = list("123")
i = 99
with open(filename,"wb") as f:
pickle.dump(d,f)
pickle.dump(l,f)
pickle.dump(i,f)
with open(filename,"rb") as f:
print(f.read(),f.seek(0))
for _ in range(3):
x = pickle.load(f)
print(type(x),x)
-----------------------------------------------------------
b'\x80\x03}q\x00(X\x01\x00\x00\x00aq\x01K\x01X\x01\x00\x00\x00bq\x02X\x03\x00\x00\x00abcq\x03X\x01\x00\x00\x00cq\x04]q\x05(K\x01K\x02K\x03eu.\x80\x03]q\x00(X\x01\x00\x00\x001q\x01X\x01\x00\x00\x002q\x02X\x01\x00\x00\x003q\x03e.\x80\x03Kc.' 0
<class 'dict'> {'a': 1, 'b': 'abc', 'c': [1, 2, 3]}
<class 'list'> ['1', '2', '3']
<class 'int'> 99import pickle
# 对象序列化
class AA:
tttt = "ABC"
def show(self):
print("abc")
a1 = AA()
sr = pickle.dumps(a1)
print("sr={}".format(sr)) # AA
a2 = pickle.loads(sr)
print(a2.tttt)
a2.show()
---------------------------------------------------------------
sr=b'\x80\x03c__main__\nAA\nq\x00)\x81q\x01.'
ABC
abc- 这个例子中,其实就保存了一个类名,因为所有其他的东西都是类定义的东西,是不变的,所以只序列化一个 AA 类名
- 反序列化时找到类就可以恢复一个对象
import pickle
# 定义类
class AAA:
def __init__(self):
self.tttt = "abc"
# 创建AAA类的实例
a1 = AAA()
# 序列化
ser = pickle.dumps(a1)
print(1,"-->","ser={}".format(ser))
# 反序列化
a2 = pickle.loads(ser)
print(2,"-->",a2,type(a2))
print(3,"-->",a2.tttt)
print(4,"-->",id(a1),id(a2))
-------------------------------------------------------------------
1 --> ser=b'\x80\x03c__main__\nAAA\nq\x00)\x81q\x01}q\x02X\x04\x00\x00\x00ttttq\x03X\x03\x00\x00\x00abcq\x04sb.'
2 --> <__main__.AAA object at 0x0000029774F75548> <class '__main__.AAA'>
3 --> abc
4 --> 2849520006280 2849525683528- 可以看出这回除了必须保存的AAA,还序列化了 tttt 和 abc,因为这是每一个对象自己的属性,每一个对象不一样的,所以这些数据需要序列化。
13.9.2、序列化、反序列化实验
定义类 AAA,并序列化到文件
import pickle
class AAA:
def __init__(self):
self.tttt = "abc"
aaa = AAA()
sr = pickle.dumps(aaa)
print(len(sr),sr)
file = "d:/tmp/ser"
with open(file, "wb") as f:
pickle.dump(aaa, f)
-----------------------------------------------------------------------
49 b'\x80\x03c__main__\nAAA\nq\x00)\x81q\x01}q\x02X\x04\x00\x00\x00ttttq\x03X\x03\x00\x00\x00abcq\x04sb.'将产生的序列化文件发送到其它节点上
增加一个 x.py 文件,内容如下。最后执行这个脚本。
import pickle
with open("ser","rb") as f:
a = pickle.load(f)- 会抛出异常 AttributeError: Can't get attribute 'AAA' on <module 'main' from 'x.py'>
- 这个异常实际上是找不到 AAA 类的定义,增加类定义即可解决
- 反序列化的时候要找到 AAA 类的定义,才能成功。否则就会抛出异常。
- 可以这样理解:反序列化的时候,类是模子,二进制序列就是铁水
import pickle
class AAA:
def show(self):
print("xyz")
with open("ser","rb") as f:
a = pickle.load(f)
print(a)
a.show()
-----------------------------------------------------------------------
<__main__.AAA object at 0x7f2ffe2e0908>
xyz- 这里定义了类 AAA,并且上面的代码也能成功的执行。
- 注意!!!这里的 AAA 定义和原来完全不同了。
- 因此,序列化、反序列化必须保证使用同一套类的定义,否则会带来不可预料的结果。
13.9.3、序列化应用
- 一般来说,本地序列化的情况,应用较少。大多数场景都应用在网络传输中。
- 将数据序列化后通过网络传输到远程节点,远程服务器接收到数据反序列化后,就可以使用了。
- 但是,要注意一点,远程接收端,反序列化时必须有对应的数据类型,否则就会报错。尤其是自定义类,必须远程得有一致的定义。
- 现在,大多数项目,都不是单机的,也不是单服务的,需要通过网络将数据传送到其他节点上去,这就需要大量的序列化、反序列化过程。
- 但是,问题是,Python 程序之间还可以都是用 pickle 解决序列化、反序列化,如果是跨平台、跨语言、跨协议,pickle 就不太合适了,就需要公共的协议。例如 XML、Json、Protocol Buffer 等。
- 不同的协议,效率不同、学习曲线不同,适用场景不同,要根据不同的情况分析选型。
13.10、Json
13.10.1、Json 概念
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。 易于人阅读和编写。同时也易于机器解析和生成。 它基于JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999 的一个子集。
JSON 采用完全独立于语言的文本格式,但是也使用了类似于 C 语言家族的习惯(包括 C, C++, C#, Java, JavaScript, Perl, Python 等)。这些特性使 JSON 成为理想的数据交换语言。
JSON 建构于两种结构:
名称/值对的集合(A collection of name/value pairs)。不同的语言中,它被理解为对象(object),纪录(record),结构(struct),字典(dictionary),哈希表(hash table),有键列表(keyed list),或者关联数组 (associative array)。- 值的有序列表(An ordered list of values)。在大部分语言中,它被理解为数组(array)。
这些都是常见的数据结构。事实上大部分现代计算机语言都以某种形式支持它们。这使得一种数据格式在同样基于这些结构的编程语言之间交换成为可能。
JSON 具有以下这些形式:
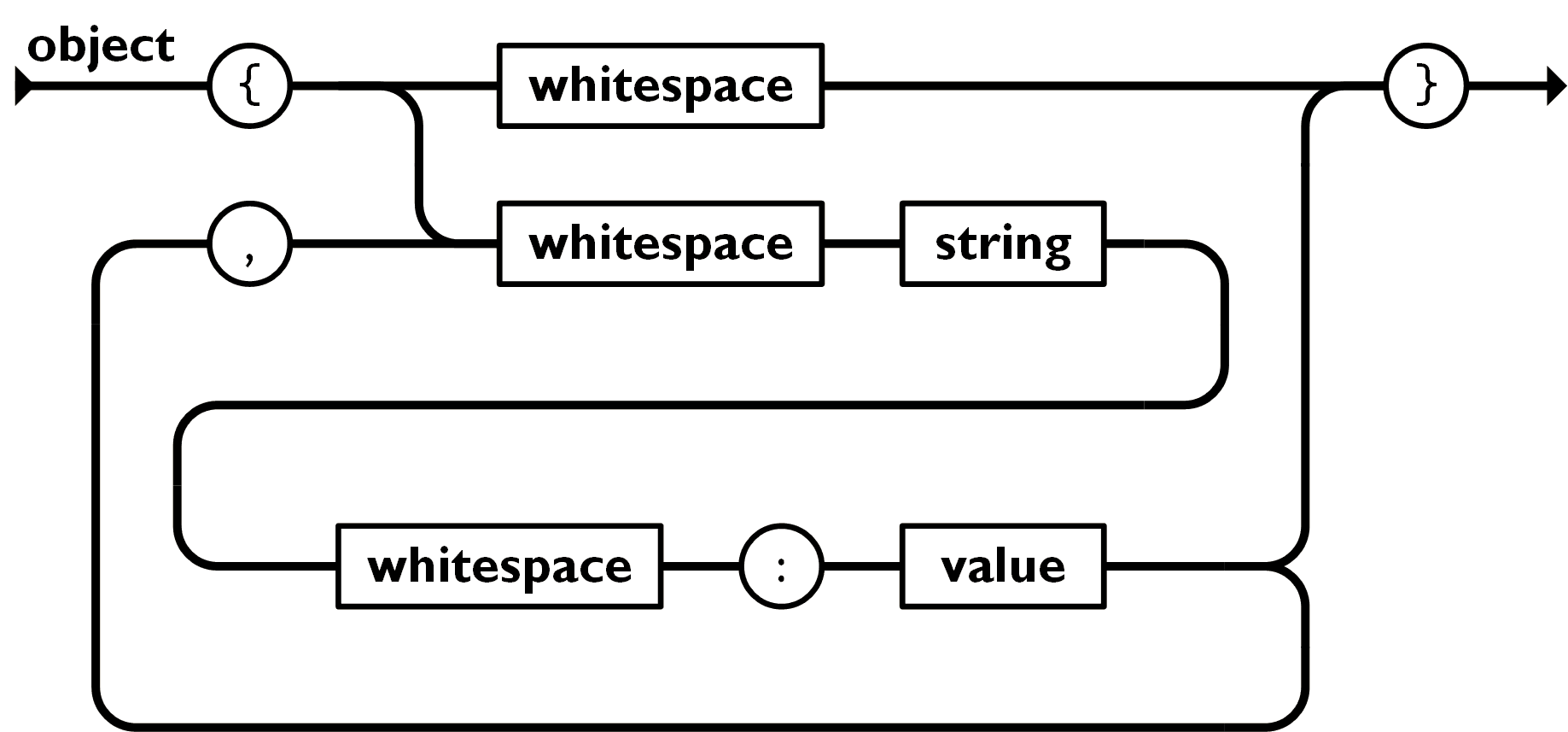
对象是一个无序的 名称/值 集合。一个对象以 { 左括号开始,} 右括号结束。每个 名称 后跟一个 : 冒号;名称/值 之间使用 , 逗号分隔。
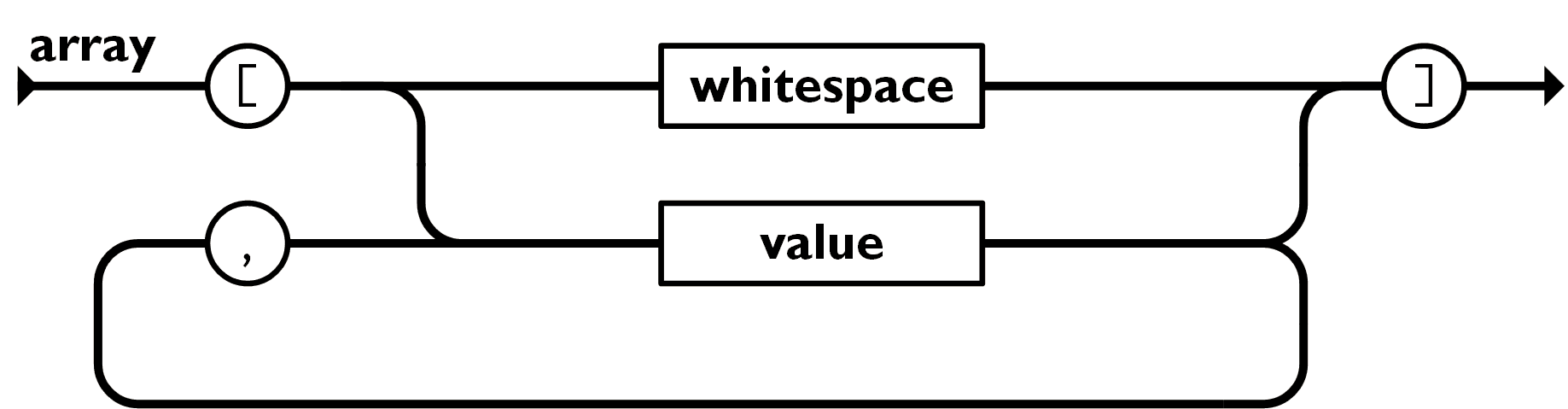
数组是值(value)的有序集合。一个数组以 [左中括号 开始, ]右中括号 结束。值之间使用 ,逗号 分隔。
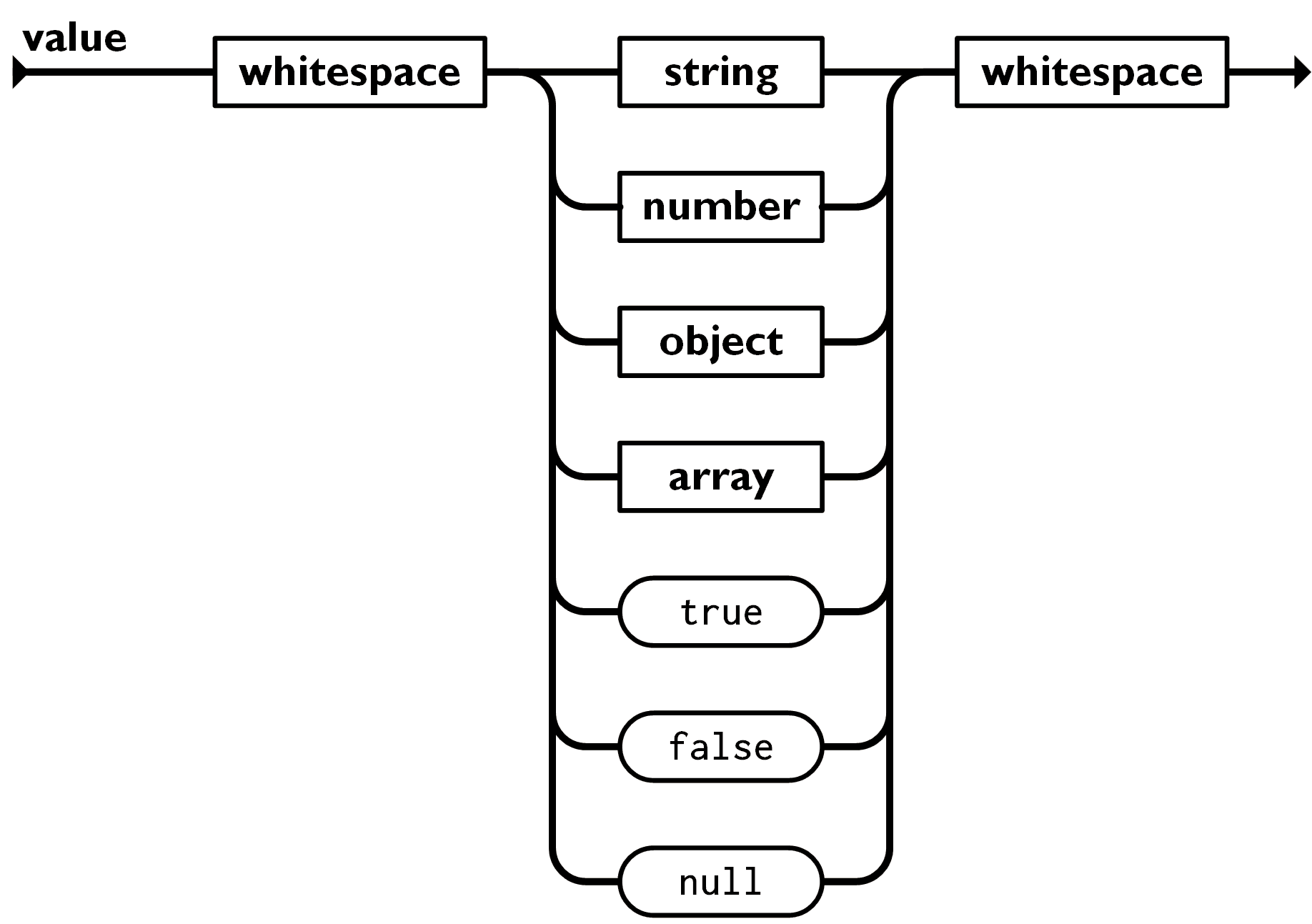
值(value)可以是双引号括起来的字符串(string)、数值(number)、true、false、 null、对象(object)或者数组(array)。这些结构可以嵌套。
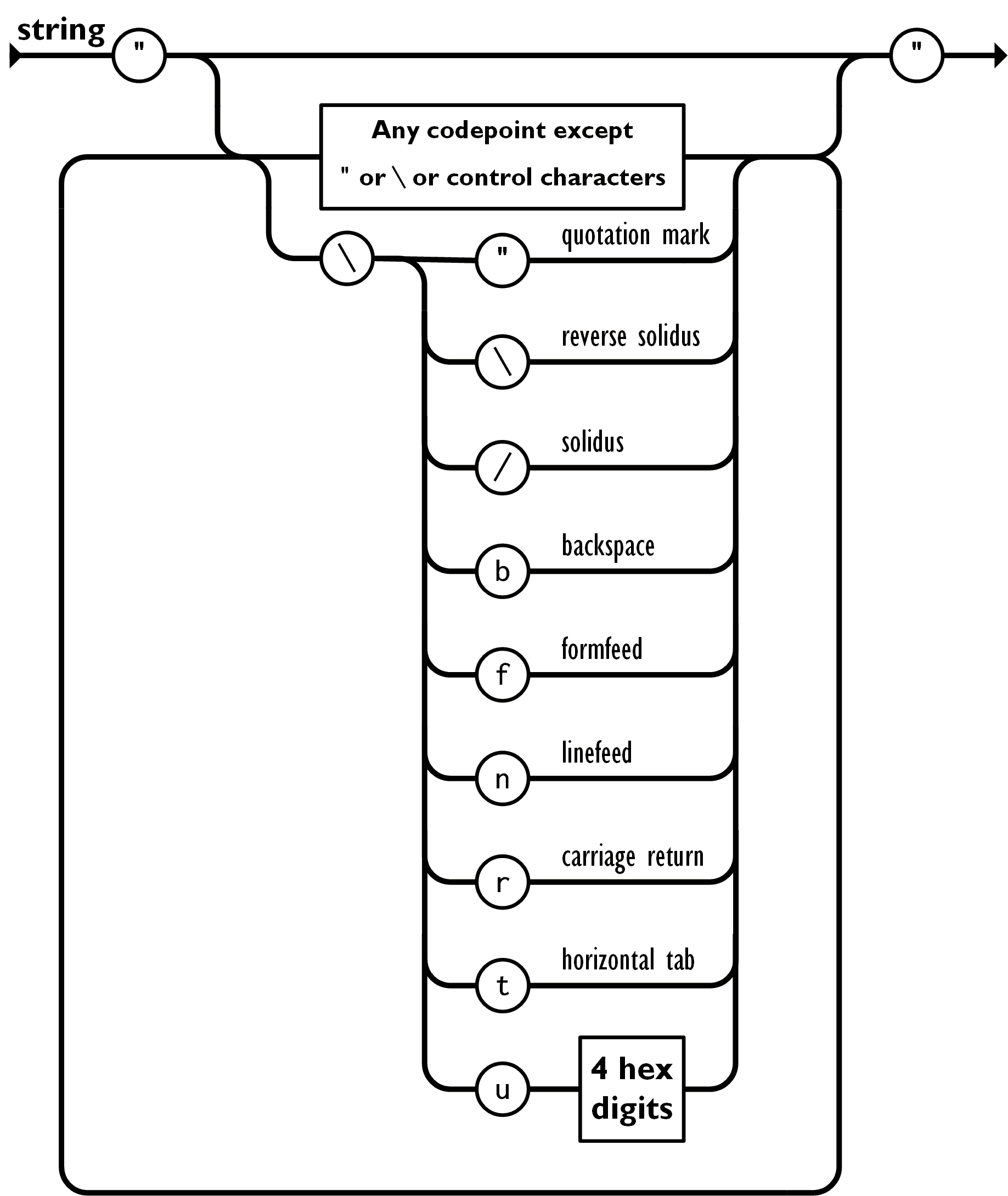
字符串(string)是由双引号包围的任意数量Unicode字符的集合,使用反斜线转义。一个字符(character)即一个单独的字符串(character string)。
字符串(string)与C或者Java的字符串非常相似。
数值(number)也与C或者Java的数值非常相似。除去未曾使用的八进制与十六进制格式。除去一些编码细节。
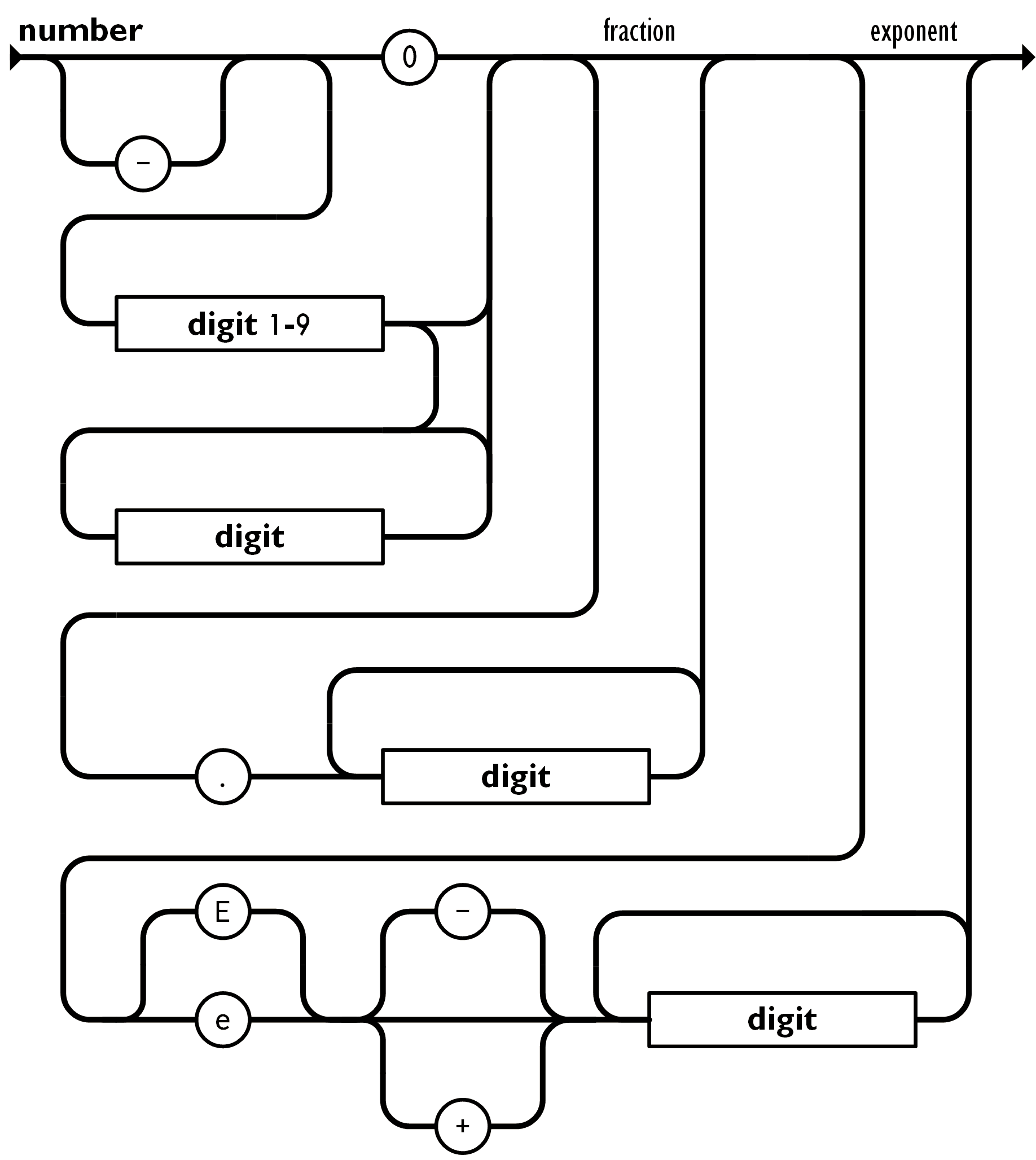
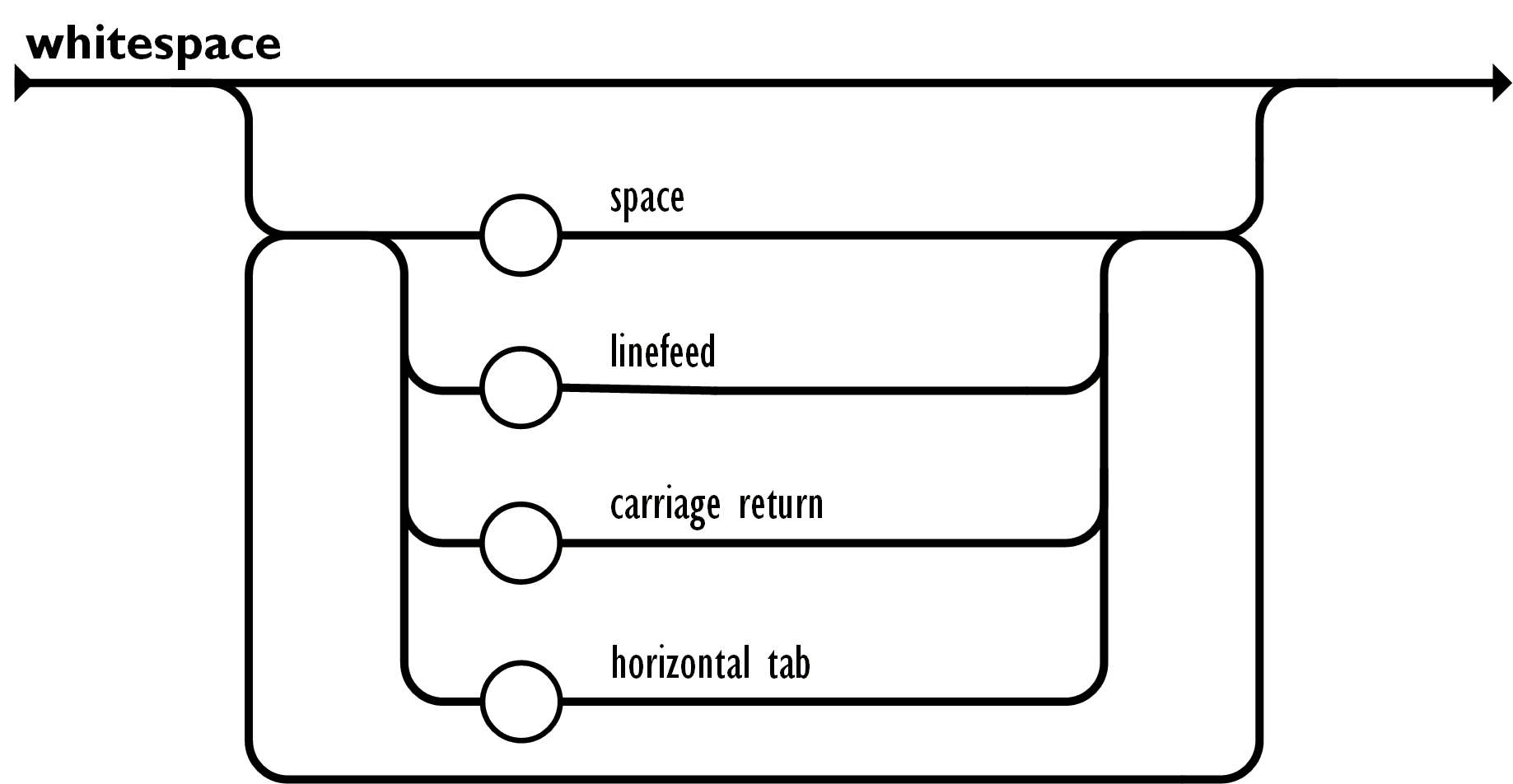
空白可以加入到任何符号之间。 以下描述了完整的语言。
实例:
{
"person": [
{
"name": "tom",
"age": 18
},
{
"name": "jerry",
"age": 16
}
],
"total": 2
}13.10.2、Json 模块
13.10.2.1、Python 与 Json
Python 支持少量内建数据类型到 Json 类型的转换。
| Python 类型 | Json 类型 |
|---|---|
| True | true |
| False | false |
| None | null |
| str | string |
| int | integer |
| float | float |
| list | array |
| dict | object |
13.10.2.2、常用方法
| Python 类型 | Json 类型 |
|---|---|
| dumps | json编码 |
| dump | json编码并存入文件 |
| loads | json解码 |
| load | json解码,从文件读取数据 |
import json
d = {'name': 'Tom', 'age': 20, 'interest': ['music', 'movie']}
j = json.dumps(d)
print(j) # 请注意引号的变化
d1 = json.loads(j)
print(d1)一般 json 编码的数据很少落地,数据都是通过网络传输。传输的时候,要考虑压缩它。
本质上来说它就是个文本,就是个字符串。
13.10.3、MessagePack 模块
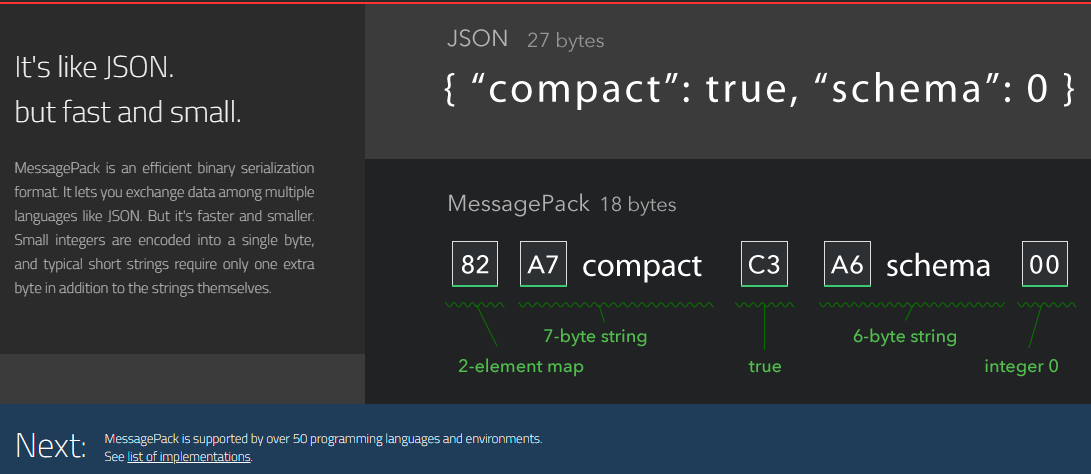
MessagePack 是一个基于二进制高效的对象序列化类库,可用于跨语言通信。
它可以像 JSON 那样,在许多种语言之间交换结构对象。
但是它比 JSON 更快速也更轻巧。
支持 Python、Ruby、Java、C/C++ 等众多语言。兼容 json 和 pickle。宣称比 Google Protocol Buffers 还要快 4 倍。
13.10.3.1、安装
$ pip install msgpack-python13.10.3.2、常用方法
packb 序列化对象。提供了 dumps 来兼容 pickle 和 json。
unpackb 反序列化对象。提供了 loads 来兼容。
pack 序列化对象保存到文件对象。提供了 dump 来兼容。
unpack 反序列化对象保存到文件对象。提供了 load 来兼容。
import msgpack
import json
d = {'person': [{'name': 'tom', 'age': 18}, {'name': 'jerry', 'age': 16}], 'total': 2}
j = json.dumps(d)
m = msgpack.dumps(d) # 本质上就是 packb
print("json={}, msgpack={}".format(len(j), len(m)))
print(j.encode(), len(j.encode())) # json 和 msgpack 的比较
print(m)
u = msgpack.unpackb(m)
print(type(u), u)
u = msgpack.unpackb(m, encoding='utf8')
print(type(u), u)MessagePack 简单易用,高效压缩,支持语言丰富。
所以,用它序列化也是一种很好的选择。