
11、Python3 函数应用
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。你已经知道 Python 提供了许多内建函数,比如 print()。但你也可以自己创建函数,这被叫做用户自定义函数。
11.1、定义一个函数
你可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
- 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的 return 相当于返回 None。
11.1.1、语法
Python 定义函数使用 def 关键字,一般格式如下:
def 函数名(参数列表):
函数体默认情况下,参数值和参数名称是按函数声明中定义的顺序匹配起来的。
11.1.2、实例
让我们使用函数来输出 "Hello World!":
>>>def hello() :
print("Hello World!")
>>> hello()
Hello World!
>>>更复杂点的应用,函数中带上参数变量:
#!/usr/bin/python3
# 计算面积函数
def area(width, height):
return width * height
def print_welcome(name):
print("Welcome", name)
print_welcome("Runoob")
w = 4
h = 5
print("width =", w, " height =", h, " area =", area(w, h))以上实例输出结果:
Welcome Runoob
width = 4 height = 5 area = 2011.2、函数调用
定义一个函数:给了函数一个名称,指定了函数里包含的参数,和代码块结构。
这个函数的基本结构完成以后,你可以通过另一个函数调用执行,也可以直接从 Python 命令提示符执行。
如下实例调用了 printme() 函数:
#!/usr/bin/python3
# 定义函数
def printme( str ):
# 打印任何传入的字符串
print (str)
return
# 调用函数
printme("我要调用用户自定义函数!")
printme("再次调用同一函数")以上实例输出结果:
我要调用用户自定义函数!
再次调用同一函数11.3、参数传递
在 python 中,类型属于对象,变量是没有类型的:
a=[1,2,3]
a="Runoob"以上代码中,[1,2,3] 是 List 类型,"Runoob" 是 String 类型,而变量 a 是没有类型,她仅仅是一个对象的引用(一个指针),可以是指向 List 类型对象,也可以是指向 String 类型对象。
11.3.1、mutable 与 immutable 对象
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
- 不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变a的值,相当于新生成了a。
- 可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
- 不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
- 可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
11.3.2、python 传不可变对象实例
#!/usr/bin/python3
def ChangeInt( a ):
a = 10
b = 2
ChangeInt(b)
print( b ) # 结果是 2实例中有 int 对象 2,指向它的变量是 b,在传递给 ChangeInt 函数时,按传值的方式复制了变量 b,a 和 b 都指向了同一个 Int 对象,在 a=10 时,则新生成一个 int 值对象 10,并让 a 指向它。
11.3.3、传可变对象实例
可变对象在函数里修改了参数,那么在调用这个函数的函数里,原始的参数也被改变了。例如:
#!/usr/bin/python3
# 可写函数说明
def changeme( mylist ):
"修改传入的列表"
mylist.append([1,2,3,4])
print ("函数内取值: ", mylist)
return
# 调用changeme函数
mylist = [10,20,30]
changeme( mylist )
print ("函数外取值: ", mylist)传入函数的和在末尾添加新内容的对象用的是同一个引用。故输出结果如下:
函数内取值: [10, 20, 30, [1, 2, 3, 4]]
函数外取值: [10, 20, 30, [1, 2, 3, 4]]11.4、参数
以下是调用函数时可使用的正式参数类型:
- 必需(位置)参数
- 关键字参数
- 默认参数
- 不定长参数
11.4.1、必需(位置)参数
必需参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
调用 printme() 函数,你必须传入一个参数,不然会出现语法错误:
#!/usr/bin/python3
#可写函数说明
def printme( str ):
"打印任何传入的字符串"
print (str)
return
# 调用 printme 函数,不加参数会报错
printme()以上实例输出结果:
Traceback (most recent call last):
File "test.py", line 10, in <module>
printme()
TypeError: printme() missing 1 required positional argument: 'str'11.4.2、关键字参数
关键字参数和函数调用关系紧密,使用形参的名字来传入实参。
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
以下实例在函数 printme() 调用时使用参数名:
#!/usr/bin/python3
#可写函数说明
def printme( str ): # 位置参数
"打印任何传入的字符串"
print (str)
return
#调用printme函数
printme( str = "菜鸟教程") # 关键字的方式传入以上实例输出结果:
菜鸟教程以下实例中演示了函数参数的使用不需要使用指定顺序:
#!/usr/bin/python3
#可写函数说明
def printinfo( name, age ): # 位置参数
"打印任何传入的字符串"
print ("名字: ", name)
print ("年龄: ", age)
return
#调用printinfo函数
printinfo( age=50, name="runoob" ) # 关键字方式传入以上实例输出结果:
名字: runoob
年龄: 50通过以上描述,很明显,位置参数并没有在 python 中专门实现,因为位置参数也可以用关键字传入
11.4.3、默认参数
调用函数时,如果没有传递参数,则会使用默认参数。以下实例中如果没有传入 age 参数,则使用默认值:
#!/usr/bin/python3
#可写函数说明
def printinfo( name, age = 35 ):
"打印任何传入的字符串"
print ("名字: ", name)
print ("年龄: ", age)
return
#调用printinfo函数
printinfo( age=50, name="runoob" )
print ("------------------------")
printinfo( name="runoob" )以上实例输出结果:
名字: runoob
年龄: 50
------------------------
名字: runoob
年龄: 3511.4.4、不定长参数
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述 2 种参数不同,声明时不会命名。基本语法如下:
def functionname([formal_args,] *var_args_tuple ):
"函数_文档字符串"
function_suite
return [expression]加了星号 * 的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数。
#!/usr/bin/python3
# 可写函数说明
def printinfo( arg1, *vartuple ):
"打印任何传入的参数"
print ("输出: ")
print (arg1)
print (vartuple)
# 调用printinfo 函数
printinfo( 70, 60, 50 )以上实例输出结果:
输出:
70
(60, 50)如果在函数调用时没有指定参数,它就是一个空元组。我们也可以不向函数传递未命名的变量。如下实例:
#!/usr/bin/python3
# 可写函数说明
def printinfo( arg1, *vartuple ):
"打印任何传入的参数"
print ("输出: ")
print (arg1)
for var in vartuple:
print (var)
return
# 调用printinfo 函数
printinfo( 10 )
printinfo( 70, 60, 50 )以上实例输出结果:
输出:
10
输出:
70
60
50还有一种就是参数带两个星号 ** 基本语法如下:
def functionname([formal_args,] **var_args_dict ):
"函数_文档字符串"
function_suite
return [expression]加了两个星号 ** 的参数会以字典的形式导入。
#!/usr/bin/python3
# 可写函数说明
def printinfo( arg1, **vardict ):
"打印任何传入的参数"
print ("输出: ")
print (arg1)
print (vardict)
# 调用printinfo 函数
printinfo(1, a=2,b=3)以上实例输出结果:
输出:
1
{'a': 2, 'b': 3}声明函数时,参数中星号 * 可以单独出现,例如:
def f(a,b,*,c):
return a+b+c如果单独出现星号 * 后的参数必须用关键字传入。
>>> def f(a,b,*,c):
... return a+b+c
...
>>> f(1,2,3) # 报错
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: f() takes 2 positional arguments but 3 were given
>>> f(1,2,c=3) # 正常
6
>>>11.4.5、参数解构
参数解构和可变参数
- 给函数提供实参的时候,可以在集合类型前使用
*或者**,把集合类型的结构解开,提取出所有元素作为函数的实参 - 非字典类型使用
*解构成位置参数 - 字典类型使用
**解构成关键字参数 - 提取出的元素数目要和参数的要求匹配,也要和参数的类型匹配
def add(x,*y):
print(x,y,sep=",")
t = (4,5)
add(t[0],t[1])
add(*t)
add(*(4,5))
add(*{4,6,7,8,9,2})
add(*range(1,3))
--------------------------
4,(5,)
4,(5,)
4,(5,)
2,(4, 6, 7, 8, 9)
1,(2,)- 通过对比可以透析参数解构的用法
add(*{4,6,7,8,9,2})这个参数解构比较特殊,集合解构无序
def add(x,y):
print(x,y,sep=",")
add(**{'x':5,'y':6}) # 解构成 x=5,y=6 作为关键字参数传递,正常运行
add(**{'a':5,'b':6}) # 解构成 a=5,b=6 作为关键字参数传递,不匹配形参,异常
add(*{'a':5,'b':6}) # 解构成 a,b 作为位置参数传递,正常运行11.5、匿名函数
python 使用 lambda 来创建匿名函数。
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
- lambda 只是一个表达式,函数体比 def 简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
- 不需要使用return,表达式的值,就是匿名函数返回值
语法:
lambda 函数的语法只包含一个语句
格式
lambda 参数列表:表达式
lambda [arg1 [,arg2,.....argn]]:expression定义一个匿名函数
lambda x:x**2调用
(lambda x:x**2)(4)- 不推荐
foo = lambda x,y:(x+y)**2,foo(4,5);如果这样写还不如 def foo(x,y),匿名函数就优秀在匿名二字
实例分析:
print(1,"-->",(lambda :0)())
print(2,"-->",(lambda x,y=3:x+y)(5))
print(3,"-->",(lambda x,y=3:x+y)(5,6))
print(4,"-->",(lambda x,*,y=30:x+y)(5))
print(5,"-->",(lambda x,*,y=30:x+y)(5,y=10))
print(6,"-->",(lambda *args:(x for x in args))(*range(5)))
print(7,"-->",(lambda *args:[x+1 for x in args])(*range(5)))
print(8,"-->",(lambda *args:{x+2 for x in args})(*range(5)))
------------------------------------------------------------
1 --> 0
2 --> 8
3 --> 11
4 --> 35
5 --> 15
6 --> <generator object <lambda>.<locals>.<genexpr> at 0x000001D06D19ABA0>
7 --> [1, 2, 3, 4, 5]
8 --> {2, 3, 4, 5, 6}- 注意第6行的返回值是一个生成器对象
[x for x in (lambda *args:map(lambda x:x+1,args))(*range(5))]
[x for x in (lambda *args:map(lambda x:(x+1,args),args))(*range(5))]- lambda 在高阶函数中应用得非常广泛,第一个 lambda 获取
(*range(5))参数,第二个 lambda 作为 map 函数的 func,来修改第一个 lambda 获取到的参数
11.6、return语句
return [表达式] 语句用于退出函数,选择性地向调用方返回一个表达式。不带参数值的return语句返回None。之前的例子都没有示范如何返回数值,以下实例演示了 return 语句的用法:
#!/usr/bin/python3
# 可写函数说明
def sum( arg1, arg2 ):
# 返回2个参数的和."
total = arg1 + arg2
print ("函数内 : ", total)
return total
# 调用sum函数
total = sum( 10, 20 )
print ("函数外 : ", total)以上实例输出结果:
函数内 : 30
函数外 : 30def fn(x):
for i in range(x):
if i > 3:
return i
else:
print("{} is not greater than 3".format(x))
print(fn(6))
print(fn(3))
---------------------------------------------------
4
3 is not greater than 3
None- 结合 for...else 的概念很容易理解,return 语句执行后,函数立即结束
函数返回值小结:
- Python 函数使用 return 语句返回“返回值”
- 所有函数都有返回值,如果没有 return 语句,隐式调用 return None
- return 语句并不一定是函数的语句块的最后一条语句
- 一个函数可以存在多个 return 语句,但是只有一条可以被执行。如果没有一条 return 语句被执行到,隐式调用 return None
- 如果有必要,可以显示调用 return None,可以简写为 return
- 如果函数执行了 return 语句,函数就会返回,当前被执行的 return 语句之后的其它语句就不会被执行了
- 作用:结束函数调用、返回值
- 函数不能同时返回多个值
- return [1, 3, 5] 是指明返回一个列表,是一个列表对象
- return 1, 3, 5 看似返回多个值,隐式的被 python 封装成了一个元组,用 x, y, z = showlist() 解构提取更为方便
11.7、变量作用域
Python 中,程序的变量并不是在哪个位置都可以访问的,访问权限决定于这个变量是在哪里赋值的。
变量的作用域决定了在哪一部分程序可以访问哪个特定的变量名称。Python的作用域一共有4种,分别是:
- L (Local) 局部作用域
- E (Enclosing) 闭包函数外的函数中
- G (Global) 全局作用域
- B (Built-in) 内置作用域(内置函数所在模块的范围)
以 L –> E –> G –>B 的规则查找,即:在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内置中找。
g_count = 0 # 全局作用域
def outer():
o_count = 1 # 闭包函数外的函数中
def inner():
i_count = 2 # 局部作用域内置作用域是通过一个名为 builtin 的标准模块来实现的,但是这个变量名自身并没有放入内置作用域内,所以必须导入这个文件才能够使用它。在Python3.0中,可以使用以下的代码来查看到底预定义了哪些变量:
>>> import builtins
>>> dir(builtins)Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else/、try/except、for/while等)是不会引入新的作用域的,也就是说这些语句内定义的变量,外部也可以访问,如下代码:
>>> if True:
... msg = 'I am from Runoob'
...
>>> msg
'I am from Runoob'
>>>实例中 msg 变量定义在 if 语句块中,但外部还是可以访问的。
如果将 msg 定义在函数中,则它就是局部变量,外部不能访问:
>>> def test():
... msg_inner = 'I am from Runoob'
...
>>> msg_inner
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'msg_inner' is not defined
>>>从报错的信息上看,说明了 msg_inner 未定义,无法使用,因为它是局部变量,只有在函数内可以使用。
11.7.1、全局变量和局部变量
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。如下实例:
#!/usr/bin/python3
total = 0 # 这是一个全局变量
# 可写函数说明
def sum( arg1, arg2 ):
#返回2个参数的和."
total = arg1 + arg2 # total在这里是局部变量.
print ("函数内是局部变量 : ", total)
return total
#调用sum函数
sum( 10, 20 )
print ("函数外是全局变量 : ", total)以上实例输出结果:
函数内是局部变量 : 30
函数外是全局变量 : 0嵌套函数结构变量分析:
def outer1():
o = 65
def inner():
print("inner{}".format(o),chr(o),sep=" ")
print("outer{}".format(o))
inner()
outer1()
输出:
outer65
inner65 A
====================================================
def outer2():
o = 65
def inner():
o = 97
print("inner{}".format(o),chr(o),sep=" ")
print("outer{}".format(o))
inner()
outer2()
输出:
outer65
inner97 a- 外层变量作用域在内层作用域可见
- 内层作用域inner中,如果定义了o=97,相当于当前作用域中重新定义了一个新的变量o,但是这个o并没有覆盖外层作用域outer中的o
x = 5
def foo():
y = x + 1 # 报错吗
x += 1 # 报错,报什么错?为什么?换成x=1还有错吗?
print(x) # 为什么它不报错
foo()- x += 1 其实是 x = x + 1
- 一旦出现 x=,相当于在foo内部定义一个局部变量x,那么foo内部所有x都是这个局部变量x了
- 但是这个 x 还没有完成赋值,就被右边拿来做加 1 操作了
- 如何解决这个问题?引入下面的 global 和 nonlocal 概念
11.7.2、global 和 nonlocal 关键字
当内部作用域想修改外部作用域的变量时,就要用到 global 和 nonlocal 关键字了。
x = 5
def foo():
global x
x += 1
print(x)
foo()
print(x)
输出:
5
6- 使用 global 关键字的变量,将 foo 内的 x 声明为使用外部的全局作用域中定义的 x
- 全局作用域中必须有 x 的定义
- 如果全局作用域中没有x定义会怎样?
# x = 5
def foo():
global x
x = 10
x += 1 # 不会出错
print(x)
# print(x) # 会报错
foo()
print(x) # 不会报错- 使用 global 关键字的变量,将 foo 内的 x 声明为使用外部的全局作用域中定义的 x
- 但是,x = 10 赋值即定义,在内部作用域为一个外部作用域的变量 x 赋值,不是在内部作用域定义一个新变量,所以 x+=1 不会报错。注意,这里 x 的作用域还是全局的
11.7.2.1、global 总结
- x+=1 这种是特殊形式产生的错误的原因?
- 先引用后赋值,而 python 动态语言是赋值才算定义,才能被引用。解决办法,在这条语句前增加 x=0 之类的赋值语句,或者使用 global 告诉内部作用域,去全局作用域查找变量定义
- 内部作用域使用x = 5之类的赋值语句会重新定义局部作用域使用的变量x,但是,一旦这个作用域中使用global声明x为全局的,那么x=5相当于在为全局作用域的变量x赋值
- global 使用原则
- 外部作用域变量会内部作用域可见,但也不要在这个内部的局部作用域中直接使用,因为函数的目的就是为了封装,尽量与外界隔离
- 如果函数需要使用外部全局变量,请使用函数的形参传参解决
- 一句话:不用global。学习它就是为了深入理解变量作用域
11.7.2.2、闭包的两个概念
- 自由变量:未在本地作用域中定义的变量。例如定义在内层函数外的外层函数的作用域中的变量
- 闭包:就是一个概念,出现在嵌套函数中,指的是内层函数引用到了外层函数的自由变量,就形成了闭包。很多语言都有这个概念,最熟悉就是JavaScript
def counter():
c = [0]
def inc():
c[0] += 1 # 报错吗?为什么?
return c[0]
return inc
foo = counter()
print(foo(),foo())
c = 100
print(foo())
输出:
1 2
3- 第 4 行会报错吗?为什么?
- 不会报错,c 已经在 counter 函数中定义过了。而且 inc 中的使用方式是为 c 的元素修改值,而不是重新定义变量
- 第 8 行打印什么结果?
- 打印 1 2
- 第 10 行打印什么结果?
- 打印 3
- 第 9 行的 c 和 counter 中的 c 不一样,而 inc 引用的是自由变量正是 counter 的变量 c
- 这是 python2 中实现闭包的方式, python3 还可以使用 nonlocal 关键字
def counter():
count = 0
def inc():
count += 1
return count
return inc
foo = counter()
foo()
foo()- 第 4 行会报错吗?怎么解决?
- 使用global可以解决,但是这使用的是全局变量,而不是闭包
- 如果要对普通变量闭包,Python3中可以使用nonlocal
- 使用了nonlocal关键字,将变量标记为不在本地作用域定义,而在上级的某一级局部作用域中定义,但不能是全局作用域中定义
代码1:
def counter():
count = 0
def inc():
nonlocal count
count += 1
return count
return inc
foo = counter()
foo()
foo()
===========================
代码2:
a = 50
def counter():
nonlocal a
a += 1
print(a)
counter = 0
def inc():
nonlocal count
count += 1
return count
return inc
foo = counter()
foo()
foo()- count 是外层函数的局部变量,被内部函数引用
- 内部函数使用nonlocal关键字声明count变量在上级作用域而非本地作用域中定义
- 代码 1 可以正常使用,且形成闭包
- 代码 2 不能正常运行,变量 a 不能在全局作用域中
11.7.3、默认值的作用域
默认值举例
def foo(xyz=[]):
xyz.append(1)
print(xyz)
foo() # [1]
foo() # [1,1]
print(xyz) # NameError,当前作用域没有 xyz 变量- 为什么第二次调用foo函数打印的是[1,1]?
- 因为函数也是对象,python把函数的默认值放在了属性中,这个属性就伴随着这个函数对象的整个生命周期
- 查看 foo.__defaults__ 属性
引用类型举例
def foo(xyz=[],u="abc",z=123):
xyz.append(1)
return xyz
print(foo(),id(foo))
print(foo.__defaults__)
print(foo(),id(foo))
print(foo.__defaults__)
输出:
[1] 1830991902512
([1], 'abc', 123)
[1, 1] 1830991902512
([1, 1], 'abc', 123)- 函数地址并没有变,就是说函数这个对象的没有变,调用它,它的属性__defaults__中使用元组保存默认值
- xyz默认值是引用类型,引用类型的元素变动,并不是元组的变化
非引用类型举例
def foo(w,u="abc",z=123):
u = "xyz"
z = 789
print(w,u,z)
print(foo.__defaults__)
foo('greatwall')
print(foo.__defaults__)
输出:
('abc', 123)
greatwall xyz 789
('abc', 123)- 属性__defaults__中使用元组保存所有位置参数默认值,它不会因为在函数体内使用了它而发生改变
混合参数类型举例
def foo(w,u="abc",*,z=123,zz=[456]):
u = "xyz"
z = 789
zz.append(1)
print(w,u,z,zz)
print(foo.__defaults__)
foo("greatwall")
print(foo.__kwdefaults__)
输出:
('abc',)
greatwall xyz 789 [456, 1]
{'zz': [456, 1], 'z': 123}- 属性__defaults__中使用元组保存所有位置参数默认值
- 属性__kwdefaults__中使用字典保存所有keyword-only参数的默认值
默认值作用域说明
- 使用可变类型作为默认值,就可能修改这个默认值
- 有时候这个特性是好的,有的时候这种特性是不好的,有副作用
- 如何做到按需改变呢?看下面的2种方法
def foo(xyz=[],u="abc",z=123):
xyz = xyz[:] # 影子拷贝
xyz.append(1)
print(xyz)
foo()
print(foo.__defaults__)
foo()
print(foo.__defaults__)
foo([10])
print(foo.__defaults__)
foo([10,5])
print(foo.__defaults__)
输出:
[1]
([], 'abc', 123)
[1]
([], 'abc', 123)
[10, 1]
([], 'abc', 123)
[10, 5, 1]
([], 'abc', 123)- 函数体内,不改变默认值
- xyz都是传入参数或者默认参数的副本,如果就想修改原参数,无能为力
def foo(xyz=None,u="abc",z=132):
if xyz is None:
xyz = []
xyz.append(1)
print(xyz)
foo()
print(foo.__defaults__)
foo()
print(foo.__defaults__)
foo([10])
print(foo.__defaults__)
foo([10,5])
print(foo.__defaults__)
输出:
[1]
(None, 'abc', 132)
[1]
(None, 'abc', 132)
[10, 1]
(None, 'abc', 132)
[10, 5, 1]
(None, 'abc', 132)- 使用不可变类型默认值
- 如果使用缺省值None就创建一个列表
- 如果传入一个列表,就修改这个列表
小结:
- 第一种方法
- 使用影子拷贝创建一个新的对象,永远不能改变传入的参数
- 第二种方法
- 通过值的判断就可以灵活的选择创建或者修改传入对象
- 这种方式灵活,应用广泛
- 很多函数的定义,都可以看到使用None这个不可变的值作为默认参数,可以说这是一种惯用法
11.8、函数的销毁
全局函数销毁
-
重新定义同名函数
-
del 语句删除函数对象
-
程序结束时
局部函数销毁
-
重新在上级作用域定义同名函数
-
del 语句删除函数名称,函数对象的引用计数减1
-
上级作用域销毁时
11.9、思考
上面描述了很多有关函数的根本概念,接下来,思考一些不一样的场景
def f(x,y,z):
pass
f(z=None,y=10,x=[1])
f((1,),z=6,y=4.1)
f(y=5,z=6,2)- f(y=5,z=6,2) 这种表达方式会报错,要求位置参数必须在关键字参数之前传入,位置参数是按位置对应的
def add(x=4,y=5):
return x+y
print(add(6,10))
print(add(6,y=7))
print(add(x=5))
print(add())
print(add(y=7))
print(add(x=5,y=6))
print(add(y=5,x=6))
---------------------
16
13
10
9
11
11
11- 参数的默认值可以在未传入足够的实参的时候,对没有给定的参数赋值为默认值
- 参数非常多的时候,并不需要每次都输入所有的参数,简化函数调用
def add(x=4,y=5):
return x+y
print(add(x=5,6))
print(add(y=8,4))
---------------------
File "<ipython-input-9-01c6d3f4eebe>", line 1
print(add(x=5,6))
^
SyntaxError: positional argument follows keyword argument- 异常中已经说的很清楚,有位置参数,必须要放在关键字参数前面
def add (nums):
sum = 0
for x in nums:
sum += x
return sum
print(add([1,2,3,4]))
print(add((2,4,6)))
print(add("abcd"))- print(add("abcd")) 会报错
- 虽然传入的参数都是可迭代对象,但是函数内部的变量类型与传入参数的变量类型可能不一致
def showconfig(username,password,**kwargs):
pass
def showconfig(username,*args,**kwargs):
pass
-----------------------------------------------------
def showconfig(username,password,**kwargs,*args):
pass
File "<ipython-input-23-888fb4d83337>", line 1
def showconfig(username,password,**kwargs,*args):
^
SyntaxError: invalid syntax- 上面两个是正确的定义方式,最后一个报错了,对比就可以看出来,要遵守语法规范。
小结:可变参数混合使用的时候,可以参考下面的规范总结
- 有位置可变参数和关键字可变参数
- 位置可变参数在形参前使用一个星号
* - 关键字可变参数在形参前使用两个星号
** - 位置可变参数和关键字可变参数都可以收集若干个实参,位置可变参数收集形成一个tuple,关键字可变参数收集形成一个dict
- 混合使用参数的时候,可变参数要放到参数列表的最后,普通参数需要放到参数列表前面,位置可变参数需要在关键字可变参数之前
def fn(x, y, *args, **kwargs):
print(x)
print(y)
print(args)
print(kwargs)
fn(3,5,7,9,10,a=1,b='python')
fn(3,5)
fn(3,5,7)
fn(3,5,a=1,b='python')
fn(7,9,y=5,x=3,a=1,b='python') # 错误,7和9分别赋给了x,y,又y=5、x=3,重复了def fn(*args):
print(args)
fn(a=1,b=2)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-29-7640750972b9> in <module>
2 print(args)
3
----> 4 fn(a=1,b=2)
TypeError: fn() got an unexpected keyword argument 'a'- 传入关键字参数,要么与参数列表中的形参对应,要么归于**kwargs,不能归于*args
def fn(*args,x,y,**kwargs):
print(x)
print(y)
print(args)
print(kwargs)
fn(3,5) #出错
fn(3,5,7) #出错
fn(3,5,a=1,b='python') #出错
fn(7,9,y=5,x=3,a=1,b='python')- 只有 fn(7,9,y=5,x=3,a=1,b='python') 是可以正常运行的,x 和 y 必须用关键字参数了,而且给 x 和 y 赋值先满足 x 和 y,而不是被
**kwargs捕获 - 前三个报错"TypeError: fn() missing 2 required keyword-only arguments: 'x' and 'y'"
- 这种表达方式引入了一个新的概念 keyword-only 参数
keyword-only 参数(Python3加入):
如果在一个星号参数后,或者一个位置可变参数后,出现的普通参数,实际上已经不是普通的参数了,而是keyword-only参数
def fn(*args,x):
print(x)
print(args)
fn(3,5,x=7)- args可以看做已经截获了所有的位置参数,x不使用关键字参数就不可能拿到实参
def fn(**kwargs,x):
print(x)
print(kwargs)- 直接报语法错误
- 可以理解为kwargs会截获所有的关键字参数,就算你写了x=5,x也永远得不到这个值,所以语法错误
def fn(*,x,y):
print(x,y)
fn(x=5,y=6)*号之后,普通形参都变成了必须给出的 keyword-only 参数
参数规则:
- 参数列表参数一般顺序是,普通参数、缺省参数、可变位置参数、keyword-only参数(可带缺省值)、可变关键字参数
def fn(x,y,z=3,*args,m=4,n,**kwargs):
print(x,y,z,m,n)
print(args)
print(kwargs)
fn(4,5,7,14,15,17,m=24,n=25,a=1,b=2)
-------------------------------------
4 5 7 24 25
(14, 15, 17)
{'a': 1, 'b': 2}注意:
- 代码应该易读易懂,而不是为难别人
- 请按照书写习惯定义函数参数
11.10、举列
编写一个函数,能够至少接受 2 个参数,返回最大值和最小值
import random
def double_values(*nums):
print(nums)
return max(nums),min(nums)
print(*double_values(*[random.randint(10,20) for _ in range(10)]))
------------------------------------------------------------------
(16, 20, 10, 16, 20, 17, 17, 17, 13, 14)
20 10编写一个函数,接受一个参数 n,n 为正整数,左右两种打印方式

def show(n):
tail = " ".join([str(i) for i in range(n,0,-1)])
length = len(tail)
for i in range(1,n):
print("{:>{}}".format(" ".join([str(j) for j in range(i,0,-1)]),length))
print(tail)
show(12)def show(n):
tail = " ".join([str(i) for i in range(n,0,-1)])
length = len(tail)
print(tail)
for i in range(n-1,0,-1):
print("{:>{}}".format(" ".join([str(j) for j in range(i,0,-1)]),length))
show(12)11.11、函数的高级用法
11.11.1、Python 递归函数
函数的执行流程
def foo1(b,b1=3):
print("foo1 called",b,b1)
def foo2(c):
foo3(c)
print("foo2 called",c)
def foo3(d):
print("foo3 called",d)
def main():
print("main called")
foo1(100,101)
foo2(200)
print("main ending")
main()- 全局帧中生成 foo1、foo2、foo3、main 函数对象
- main 函数调用
- main 中查找内建函数压栈,将常量字符串压栈,调用函数,弹出栈顶
- main 中全局查找函数 foo1 压栈,将常量 100、101 压栈,调用函数 foo1,创建栈帧;print函数压栈,字符串和变量b、b1压栈,调用函数,弹出栈顶,返回值
- main 中全局查找 foo2 函数压栈,将常量200压栈,调用foo2,创建栈帧,foo3函数压栈,变量c引用压栈,调用 foo3,创建栈帧,foo3 完成 print 函数调用后返回;foo2 恢复调用,执行 print 后,返回值;main 中 foo2 调用结束弹出栈顶,main 继续执行 print 函数调用,弹出栈顶。main 函数返回
递归函数的基本概念
- 函数直接或者间接调用自身就是递归
- 递归需要有边界条件、递归前进段、递归返回段
- 递归一定要有边界条件
- 当边界条件不满足时,递归前进
- 当边界条件满足的时候,递归返回
1、斐波那契数列Fibonacci number: 1,1,2,3,5,8,13,21,34,55,89,144......
2、如果设F(n)为该数列的第n项(n∈N*),那么这句话可以写成如下形式:F(n) = F(n-1) + F(n-2)
3、F(0)=0,F(1)=1,F(n)=F(n-1)+F(n-2)
# for 循环实现
pre = 0
cur = 1
print(pre,cur,end=" ")
n=8
for i in range(n):
pre, cur = cur, pre+cur
print(cur,end=" ")
# 递归函数实现
def fib(n):
return 1 if n < 2 else fib(n-1) + fib(n-2)
for i in range(5):
print(fib(i),end=" ")
解析:
fib(3) + fib(2)
fib(3)调用fib(3)、fib(2)、fib(1)
fib(2)调用fib(2)、fib(1)
fib(1)是边界
递归函数的要求
- 递归一定要有退出条件,递归调用一定要执行到这个退出条件,没有退出条件的递归调用,就是无限调用
- 递归调用的深度不宜过深
- Python 对递归调用的深度做了限制,以保护解释器
- 超过递归深度限制,抛出 RecursionError:maxinum recursion depth exceeded 超出最大深度
- sys.getrecursionlimit()
递归的性能
import datetime
start = datetime.datetime.now()
pre = 0
cur = 1
print(pre,cur,end=" ")
n = 35
for i in range(n-1):
pre,cur = cur,pre+cur
print(cur,end=" ")
delta = (datetime.datetime.now() - start).total_seconds()
print()
print("This program used {}s".format(delta))
-------------------------------------------------------------
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584 4181 6765 10946 17711 28657 46368 75025 121393 196418 317811 514229 832040 1346269 2178309 3524578 5702887 9227465
This program used 0.002004s
=============================================================
import datetime
n = 35
start = datetime.datetime.now()
def fib(n):
return 1 if n < 2 else fib(n-1) + fib(n-2)
for i in range(n):
print(fib(i),end=" ")
delta = (datetime.datetime.now() - start).total_seconds()
print()
print("This program used {}s".format(delta))
-------------------------------------------------------------
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584 4181 6765 10946 17711 28657 46368 75025 121393 196418 317811 514229 832040 1346269 2178309 3524578 5702887 9227465
This program used 6.641008s- 循环稍微复杂一些,但是只要不是死循环,可以多次迭代直至算出结果
- fib函数代码极简易懂,但是只能获取到最外层的函数调用,内部递归结果都是中间结果,而且给定一个 n 都要进行近 2n 次递归,深度越深,效率越低,为了获取斐波那契数列需要外面再套一个 n 次循环,效率就更低了
- 递归还有深度限制,如果递归复杂,函数反复压栈,栈内存很快就溢出了
上面这个递归可以改进
import datetime
start = datetime.datetime.now()
pre = 0
cur = 1
print(pre,cur,end=" ")
def fib(n,pre=0,cur=1):
pre,cur = cur,pre+cur
print(cur,end=" ")
if n == 2:
return
fib(n-1,pre,cur)
fib(35)
delta = (datetime.datetime.now()-start).total_seconds()
print()
print("This program used {}s".format(delta))
----------------------------------------------------------
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584 4181 6765 10946 17711 28657 46368 75025 121393 196418 317811 514229 832040 1346269 2178309 3524578 5702887 9227465
This program used 0.001973s- 此 fib 函数和循环的思想类似
- 参数 n 是边界条件,用 n 来计数
- 上一次的计算结果直接作为函数的实参
- 效率很高
- 和循环比较,性能相近,所以并不是说递归一定效率低下,但是递归有深度限制
间接递归
def foo1():
foo2()
def foo2():
foo1()
foo1()- 间接递归,是通过别的函数调用了函数自身
- 但是,如果构成了循环递归调用是非常危险的,但是往往在代码非常复杂的情况下有可能发生,要用代码规范来避免
递归总结
- 递归是一种很自然的表达,符合逻辑思维
- 递归相对运行效率低,每一次调用函数都要开辟栈帧
- 递归有深度限制,如果递归层次太深,函数反复压栈,栈内存很快就溢出了
- 如果是有限次数的递归,可以使用递归调用,或者使用循环代替,循环代码稍微复杂一些,但是只要不是死循环,可以多次迭代直至算出结果
- 绝大多数递归,都可以使用循环实现
- 即使递归代码很简洁,但是能不用则不用递归
习题练习
# 求 n 的阶乘
def fac(n):
if n == 1:
return 1
return n * fac(n-1)
print(fac(5))
print(type(5))
-------------------------------
120
<class 'int'>
===============================
def fac1(n,factorial=1):
if n == 1:
return factorial
factorial *= n
return fac1(n-1,factorial)
print(fac1(5))
print(type(fac1(5)))
--------------------------------
120
<class 'int'>
================================
def fac2(n,factorial=1):
if n == 1:
return factorial
factorial *= n
fac2(n-1,factorial)
print(fac2(5))
print(type(fac2(5)))
--------------------------------
None
<class 'NoneType'>- 对比 fac1 和 fac2,两个函数唯一的区别是 fac1 有两个 return,fac2 只有一个 return
- fac1 在递归循环中,执行到 n = 1 时,if 中的 return 把 factorial 返回给了递归中最后一层的 fac1,而并不是 def 后面的 fac1,而最后一个 return 正好把最后一层的 fac1 的返回值再一次返回给 def 后面的 fac1
- 通过上面分析,很明显,fac2 没有最后一个 return,所以无法把最后一层的 fac2 返回的值再一次返回给 def 后的 fac2
# 将一个数逆序放入列表中,例如 1234 => [4,3,2,1]
data = str(123456798)
def revert(x):
if x == -1:
return ""
return data[x] + revert(x-1)
print(revert(len(data)-1))
---------------------------------
897654321
=================================
def revert(n,lst=None):
if lst is None:
lst = []
x,y = divmod(n,10)
lst.append(y)
if x == 0:
return lst
return revert(x,lst)
revert(123456)
----------------------------------
[6, 5, 4, 3, 2, 1]
==================================
def revert(num=str(12345),target=[]):
if num:
target.append(num[len(num)-1])
revert(num[:len(num)-1])
return target
print(revert())
-----------------------------------
['5', '4', '3', '2', '1']# 解决猴子吃桃问题
# 猴子第一天摘n个桃子,当即吃了一半零一个,往后每天都是吃一半零一个,到第10天还没吃,发现只剩一个,求n
day1 d1 = n//2-1
day2 d2 = d1//2-1
day3 d3 = d2//2-1
...
day9 1 = d8//2-1
所以反推到 n
day8 d8 = (1+1)*2
day7 d7 = (d8+1)*2
day6 d6 = (d7+1)*2
...
day1 d1 = (d2+1)*2
n n = (d1+1)*2
def peach(days=9,num=1):
num = (num+1)*2
if days == 1:
return num
return peach(days-1,num)
print(peach())
-----------------------------
1534
=============================
def peach(days=10):
if days == 1:
return 1
return (peach(days-1)+1)*2
print(peach())
-----------------------------
1534
==============================
def peach(days=1):
if days == 10:
return 1
return (peach(days+1)+1)*2
print(peach())
------------------------------
153411.11.2、高阶函数
函数进阶概述
- 函数在 Python 中是一等公民
- 函数也是对象,可调用的对象
- 函数可以作为普通变量、参数、返回值等等
高阶函数
- 数学概念 y=g(f(x))
- 在数学和计算机科学中,高阶函数应当是至少满足下面一个条件的函数
- 接受一个或多个函数作为参数
- 输出一个函数
举个列子分析
def counter(base):
def inc(step=1):
nonlocal base
base += step
return base
return inc
print(1,"-->",counter(1)())
print(2,"-->",counter(1)())
c = counter(1)
print(3,"-->",c())
print(4,"-->",c())
--------------------------
1 --> 2
2 --> 2
3 --> 2
4 --> 3- 函数 counter 是不是一个高阶函数
- 根据高阶函数的定义,要么函数作为函数的参数,要么输出一个函数,很明显 return inc 即是输出一个函数,所以是高阶函数
- 分析1 2 和 3 4 的差别
- 1 2 都是直接使用 counter(1)(),相当于生成两个新的对象; 3 4 相当于对同一个对象进行两次调用,counter 函数没有销毁,base 值可以累加
- 分析 f1 = counter(5) 和 f2 = counter(5),f1 和 f2 相等吗?
- 不相等,因为 f1 和 f2 都是 inc 对象,而 inc 对象只是一个标识符,通过 id(f1) id(f2) 可以发现在内存中它们并不是同一个对象
- 但是 f1() is f2() 返回的是 True,可以理解为 f1() 和 f2() 指向的是同一个值,相当于这个值的引用计数增加了
自定义 sort 函数,深入理解高阶函数的用法
思路
- 内建函数 sorted 函数是返回一个新的列表,可以设置升序或降序,可以设置一个排序的函数。自定义的 sort 函数也要实现这个功能
- 新建一个列表,遍历原列表,和新列表的值依次比较决定如何插入到新列表中
思考
- sorted 函数的实现原理,扩展到 map、filter 函数的实现原理
def sort(iterable):
ret = []
for x in iterable:
for i,y in enumerate(ret):
if x > y:
ret.insert(i,x) # 降序
break
else:
ret.append(x)
return ret
print(sort([1,2,5,4,2,3,5,6]))
------------------------------------------
[1, 2, 2, 3, 4, 5, 5, 6]
==========================================
def sort(iterable,reverse=False):
ret = []
for x in iterable:
for i,y in enumerate(ret):
flag = x > y if reverse else x < y # 表达技巧,将表达式转换成逻辑值
if flag:
ret.insert(i,x)
break
else:
ret.append(x)
return ret
print(sort([1,2,5,4,2,3,5,6],reverse=True))
--------------------------------------------
[6, 5, 5, 4, 3, 2, 2, 1]
============================================
def sort(iterable,key=lambda a,b:a>b):
ret = []
for x in iterable:
for i,y in enumerate(ret):
if key(x,y): # 函数的返回值是 bool
ret.insert(i,x)
break
else:
ret.append(x)
return ret
print(sort([1,2,5,4,2,3,5,6]))
--------------------------------------------
[6, 5, 5, 4, 3, 2, 2, 1]
============================================
def sort(iterable,reverse=False,key=lambda x,y:x<y):
ret = []
for x in iterable:
for i,y in enumerate(ret):
flag = key(x,y) if not reverse else not key(x,y)
if flag:
ret.insert(i,x)
break
else:
ret.append(x)
return ret
print(sort([1,2,5,4,3,6]))
---------------------------------------------
[1, 2, 3, 4, 5, 6]通过自定义 sort 函数的不断演化,可以举一反三,理解下面几个函数的逻辑
sorted(iterable [,key] [,reverse])
- 返回一个新的列表,对一个可迭代对象的所有元素排序,排序规则为 key 定义的函数,reverse 表示是否排序翻转
- sorted(lst,key=lambda x:6-x) 返回新列表
- list.sort(key=lambda x:6-x) 就地修改
filter(function,iterable)
- 过滤可迭代对象的元素,返回一个迭代器
- function 是一个具有一个参数的函数,返回 bool
- 比如过滤列表中能被 3 整除的数字 list(filter(lambda x:x%3==0,[1,9,55,150,-3,78,28,123]))
map(function,*iterables) --> map object
- 对多个可迭代对象的元素按照指定的函数进行映射,返回一个迭代器
- list(map(lambda x:2*x+1,range(5)))
- dict(map(lambda x:(x%5,x),range(500)))
11.11.3、柯里化 Currying
柯里化
- 指的是将原来接受两个参数的函数变成新的接受一个参数的函数的过程,新的函数返回一个以原有第二个参数为参数的函数
- z = f(x,y) 转换成 z = f(x)(y) 的形式
举个例子说明
# 将加法函数柯里化
def add(x,y):
return x + y
# 转换成
def add1(x):
def _add1(y):
return x+y
return _add1
add(5,6) == add1(5)(6)
------------------------
True- 通过嵌套函数就可以把函数转换成柯里化函数
11.11.4、装饰器
需求
一个加法函数,想增强它的功能,能够输出被调用过以及调用的参数信息
def add(x,y):
return x+y
# 增加信息输出功能
def add(x,y):
print("call add, x+y") # 日志输出到控制台
return x+y上面加法函数是完成了需求,但是有以下的缺点
- 打印语句的耦合太高
- 加法函数属于业务功能,而输出信息的功能,属于非业务功能代码,不该放在业务函数加法中
改进
def add(x,y):
return x + y
def logger(fn):
print("begin") # 增强的输出
x = fn(4,5)
print("end") # 增强的功能
return x
print(logger(add))
-----------------------------------------
begin
end
9- 做到了业务功能分离,但是 fn 函数调用传参是个问题
再改进
def add(x,y):
return x + y
def logger(fn,*args,**kwargs):
print("begin")
x = fn(*args,**kwargs)
print("end")
return x
print(logger(add,5,y=60))
------------------------------------------
begin
end
65- 解决了传参的问题
再改进,这一次改进是用柯里化进行的改进,目的是把函数和函数所需要的参数进行分开传参,从进化的历程来看,思想维度在不断进化
# 柯里化
def add(x,y):
return x + y
def logger(fn):
def wrapper(*args,**kwargs):
print("begin")
x = fn(*args,**kwargs)
print("end")
return x
return wrapper
print(logger(add)(5,y=50)) # 换一种写法 add=logger(add) print(add(x=5,y=10))
---------------------------------------------------------------------------
begin
end
55- 进化到这里,其实就是装饰器的演化过程,需要注意的是,最后一句的等价写法,两个 add 虽然都指向各自的对象,但它不过是一个标识符而已,跟变量是一个道理,可以随时按需求覆盖
真正的装饰器来了,装饰器其实是一个语法糖
def logger(fn):
def wrapper(*args,**kwargs):
print("begin")
x = fn(*args,**kwargs)
print("end")
return x
return wrapper
@logger # 等价于 add = logger(add)
def add(x,y):
return x + y
print(add(45,40))
--------------------------------------------
begin
end
85- @logger 就是装饰器语法
- 这是一个无参装饰器
下面对无参装饰器进行简单总结
- 它是一个函数
- 函数作为它的参数
- 返回值也是一个函数
- 可以使用 @functionname 方式,简化调用
装饰器是高阶函数,但装饰器是对传入函数的功能的装饰(功能增强)
import datetime
import time
def logger(fn):
def wrap(*args,**kwargs):
# before 功能增强
print("args={},kwargs={}".format(args,kwargs))
start = datetime.datetime.now()
ret = fn(*args,**kwargs)
# after 功能增强
duration = datetime.datetime.now() - start
print("function {} took {}s.".format(fn.__name__,duration.total_seconds()))
return ret
return wrap
@logger # 相当于 add = logger(add)
def add(x,y):
print("========call add========")
time.sleep(2)
return x+y
print(add(4,y=7))
------------------------------------------------------------------------------------
args=(4,),kwargs={'y': 7}
========call add========
function add took 2.000493s.
11- 怎么理解装饰器?
- 装饰器函数-->前置功能增强-->被增强函数<--后置功能增强
装饰器的副作用
def logger(fn):
def wrapper(*args,**kwargs):
"""I am wrapper"""
print("begin")
x = fn(*args,**kwargs)
print("end")
return x
return wrapper
@logger # add=logger(add)
def add(x,y):
"""This is a function for add"""
return x+y
print("name={},doc={}".format(add.__name__,add.__doc__))
--------------------------------------------------------
name=wrapper,doc=I am wrapper- 很明显,原函数的属性都被替换了,我们希望使用装饰器后,看到的仍然是被封装函数的属性,如何解决?
改进方案,提供一个函数,被封装函数属性 == copy ==> 包装函数属性
def copy_properties(src,dst): # 可以改造成装饰器
dst.__name__ = src.__name__
dst.__doc__ = src.__doc__
def logger(fn):
def wrapper(*args,**kwargs):
"I am wrapper"
print("begin")
x = fn(*args,**kwargs)
print("end")
return x
copy_properties(fn,wrapper)
return wrapper
@logger # add = logger(add)
def add(x,y):
"""This is a function for add"""
return x + y
print("name={},doc={}".format(add.__name__,add.__doc__))
----------------------------------------------------------
name=add,doc=This is a function for add- 通过 copy_properties 函数将被包装函数的属性覆盖掉包装函数
- 凡是被包装的函数都需要复制这些属性,这个函数很通用
- 可以将复制属性的函数构建成装饰器函数,带参装饰器
再改进,提供一个函数,被封装函数属性 == copy ==> 包装函数属性,改造成带参装饰器
def copy_properties(src):
def _copy(dst):
dst.__name__ = src.__name__
dst.__doc__ = src.__doc__
return dst
return _copy
def logger(fn):
@copy_properties(fn) # wrapper = copy_properties(fn)(wrapper)
def wrapper(*args,**kwargs):
"""I am wrapper"""
print("begin")
x = fn(*args,**kwargs)
print("end")
return x
return wrapper
@logger # add = logger(add)
def add(x,y):
"""This is a function for add"""
return x+y
print("name={},doc={}".format(add.__name__,add.__doc__))
---------------------------------------------------------------------
name=add,doc=This is a function for add再进化一步,使用带参装饰器
获取函数的执行时长,对时长超过阈值的函数记录一下
import datetime,time
def copy_properties(src):
def _copy(dst):
dst.__name__ = src.__name__
dst.__doc__ = src.__doc__
return dst
return _copy
def logger(duration):
def _logger(fn):
@copy_properties(fn) # wrapper = copy_properties(fn)(wrapper)
def wrapper(*args,**kwargs):
"""I am wrapper"""
start = datetime.datetime.now()
print("begin")
x = fn(*args,**kwargs)
delta = (datetime.datetime.now() - start).total_seconds()
print("end")
print("so slow") if delta > duration else print("so fast")
return x
return wrapper
return _logger
@logger(2) # add = logger(5)(add)
def add(x,y):
"""This is a function for add"""
time.sleep(3)
return x+y
print("name={},doc={}".format(add.__name__,add.__doc__))
print(add(5,6))
-------------------------------------------------------------------------
name=add,doc=This is a function for add
begin
end
so slow
11- 这个环境已经很难用一句话概括了,需要从头至尾不断优化代码,思路才能清析
进一步美化,将记录的功能提取出来,这样就可以通过外部提供的函数来灵活地控制输出
import datetime,time
def copy_properties(src):
def _copy(dst):
dst.__name__ = src.__name__
dst.__doc__ = src.__doc__
return dst
return _copy
def logger(duration,func=lambda name,duration:print("{} took {}s".format(name,duration))):
def _logger(fn):
@copy_properties(fn) # wrapper = copy_properties(fn)(wrapper)
def wrapper(*args,**kwargs):
"""I am wrapper"""
start = datetime.datetime.now()
print("begin")
x = fn(*args,**kwargs)
delta = (datetime.datetime.now() - start).total_seconds()
print("end")
if delta > duration:
func(fn.__name__,delta)
return x
return wrapper
return _logger
@logger(2) # add = logger(5)(add)
def add(x,y):
"""This is a function for add"""
time.sleep(3)
return x+y
print("name={},doc={}".format(add.__name__,add.__doc__))
print(add(5,6))
------------------------------------------------------------------------
name=add,doc=This is a function for add
begin
end
add took 3.000332s
1111.11.5、functools 模块
functools.update_wrapper(wrapper,wrapped,assigned=WRAPPER_ASSIGNMENTS,updated=WRAPPER_UPDATES)
- 类似 copy_properties 功能
- wrapper 包装函数、被更新者,wrapped 被包装函数、数据源
- 元组 WRAPPERASSIGNMENTS 中是要被覆盖的属性 "__module__","__name__","__qualname__","__doc__","__annotations_\" 模块名、名称、限定名、文档、参数注解
- 元组 WRAPPERUPDATES 中是要被更新的属性,__dict\_属性字典
- 增加一个__wrapped__属性,保留着 wrapped 函数
import datetime,time,functools
def logger(duration,func=lambda name,duration:print("{} took {}s".format(name,duration))):
def _logger(fn):
def wrapper(*args,**kwargs):
start = datetime.datetime.now()
ret = fn(*args,**kwargs)
delta = (datetime.datetime.now() - start).total_seconds()
if delta > duration:
func(fn.__name__,duration)
return ret
return functools.update_wrapper(wrapper,fn)
return _logger
@logger(5) # add = logger(5)(add)
def add(x,y):
time.sleep(1)
return x + y
print(add(5,6),add.__name__,add.__wrapped__,add.__dict__,sep="\n")
-----------------------------------------------------------------------
11
add
<function add at 0x000002547F1D4A60>
{'__wrapped__': <function add at 0x000002547F1D4A60>}@functools.wraps(wrapped,assigned=WRAPPER_ASSIGNMENTS,updated=WRAPPER_UPDATES)
- 类似 copy_properties 功能
- wrapped 被包装函数
- 元组 WRAPPERASSIGNMENTS 中是要被覆盖的属性 "__module__","__name__","__qualname__","__doc__","__annotations_\" 模块名、名称、限定名、文档、参数注解
- 元组 WRAPPERUPDATES 中是要被更新的属性,__dict_\ 属性字典
- 增加一个 __wrapped__ 属性,保留着 wrapped 函数
import datetime,time,functools
def logger(duration,func=lambda name,duration:print("{} tooks {}s".format(name,duration))):
def _logger(fn):
@functools.wraps(fn)
def wrapper(*args,**kwargs):
start = datetime.datetime.now()
ret = fn(*args,**kwargs)
delta = (datetime.datetime.now() - start).total_seconds()
if delta > duration:
func(fn.__name__,duration)
return ret
return wrapper
return _logger
@logger(5) # add = logger(5)(add)
def add(x,y):
"This is add func"
time.sleep(1)
return x+y
print(add(5,6),add.__name__,add.__doc__,add.__wrapped__,add.__dict__,sep="\n")
------------------------------------------------------------------------------
11
add
This is add func
<function add at 0x000002547FD8AF28>
{'__wrapped__': <function add at 0x000002547FD8AF28>}11.11.6、Python 类型注解
函数定义的弊端
- Python 是动态语言,变量随时可以被赋值,且能赋值为不同的类型
- Python 不是静态编译型语言,变量类型是在运行器决定的
- 动态语言很灵活,但是这种特性也是弊端
- 难发现,由于不做任何类型检查,直到运行期问题才显现出来,或者线上运行时才能暴露出问题
- 难使用,函数的使用者看到函数的时候,并不知道你函数的设计,并不知道应该传入什么类型的数据
解决方法
-
增加文档 Documentation String
- 这只是一种惯例,不是强制标准,不能要求程序员一定为函数提供说明文档
- 函数定义更新了,文档未必同步更新
def add(x,y): """ :param x:int :param y:int :return: int """ return x+y print(help(add)) -
函数注解
- Python 3.5 引入
- 对函数的参数进行类型注解
- 对函数的返回值进行类型注解
- 只对函数参数做一个辅助说明,并不对函数参数进行类型检查
- 提供给第三方工具,做代码分析,发现隐藏的 bug
- 函数注解的信息,保存在 __annotations__ 属性中
def add(x:int,y:int) -> int: """ :param x:int :param y:int :return: int """ return x + y print(help(add)) print(add(4,5)) print(add("mag","edu")) # 不会报错,类型注解并非强制要求 print(add.__annotations__) -------------------------------------- Help on function add in module __main__: add(x:int, y:int) -> int :param x:int :param y:int :return: int None 9 magedu {'y':, 'return': , 'x': } -
变量注解
- Python 3.6 引入,i : int = 3
函数参数类型检查思路
- 函数参数的检查,一定是在函数外
- 函数应该作为参数,传入到检查函数中
- 检查函数拿到函数传入的实际参数,与形参声明对比
- __annotations__ 属性是一个字典,其中包括返回值类型的声明。假设要做位置参数的判断,无法和字典中的声明对应。使用 inspect 模块
inspect 模块,提供获取对象信息的函数,可以检查函数和类、类型检查
inspect.signature(callable),获取签名(函数签名包含了一个函数的信息,包括函数名、它的参数类型、它所在的类和名称空间及其他信息)
import inspect
def add(x:int,y:int,*args,**kwargs) -> int:
return x + y
sig = inspect.signature(add)
print(1,"-->",sig,type(sig))
print(2,"-->","params:",sig.parameters) # OrderedDict
print(3,"-->","return:",sig.return_annotation)
print(4,"-->",sig.parameters['y'],type(sig.parameters['y']))
print(5,"-->",sig.parameters['x'].annotation)
print(6,"-->",sig.parameters["args"])
print(7,"-->",sig.parameters["args"].annotation)
print(8,"-->",sig.parameters["kwargs"])
print(9,"-->",sig.parameters["kwargs"].annotation)
-----------------------------------------------------------------
1 --> (x:int, y:int, *args, **kwargs) -> int <class 'inspect.Signature'>
2 --> params: OrderedDict([('x', <Parameter "x:int">), ('y', <Parameter "y:int">), ('args', <Parameter "*args">), ('kwargs', <Parameter "**kwargs">)])
3 --> return: <class 'int'>
4 --> y:int <class 'inspect.Parameter'>
5 --> <class 'int'>
6 --> *args
7 --> <class 'inspect._empty'>
8 --> **kwargs
9 --> <class 'inspect._empty'>inspect.isfunction(add) 是否是函数
inspect.ismethod(add) 是否是类的方法
inspect.isgenerator(add) 是否是生成器对象
inspect.isgeneratorfunction(add) 是否是生成器函数
还有很多 is 函数,需要的时候查阅 inspect 模块帮助Parameter 对象
- 保存在元组中,是只读的
- name,参数的名字
- annotation,参数的注解,可能没有定义
- default,参数的缺省值,可能没有定义
- empty,特殊的类,用来标记 default 属性或者注释 annotation 属性的空值
- kind,实参如何绑定到形参,就是形参的类型
- POSITIONAL_ONLY,值必须是位置参数提供,python 中并没有实现
- POSITIONAL_OR_KEYWORD,值可以作为关键字或者位置参数提供
- VAR_POSITIONAL,可变位置参数,对应 *args
- KEYWORD_ONLY,keyword-only 参数,对应 * 或者 *args 之后出现的非可变关键字参数
- VAR_KEYWORD,可变关键字参数,对应 **kwargs
import inspect
def add(x,y:int=7,*args,z,t=10,**kwargs) -> int:
return x + y
sig = inspect.signature(add)
print(1,"-->",sig)
print(2,"-->","params:",sig.parameters) # 有序字典
print(3,"-->","return:",sig.return_annotation)
print()
for i,item in enumerate(sig.parameters.items()):
name,param = item
print(i+1,name,param.annotation,param.kind,param.default)
print(param.default is param.empty,end="\n\n")
--------------------------------------------------------------------
1 --> (x, y:int=7, *args, z, t=10, **kwargs) -> int
2 --> params: OrderedDict([('x', <Parameter "x">), ('y', <Parameter "y:int=7">), ('args', <Parameter "*args">), ('z', <Parameter "z">), ('t', <Parameter "t=10">), ('kwargs', <Parameter "**kwargs">)])
3 --> return: <class 'int'>
1 x <class 'inspect._empty'> POSITIONAL_OR_KEYWORD <class 'inspect._empty'>
True
2 y <class 'int'> POSITIONAL_OR_KEYWORD 7
False
3 args <class 'inspect._empty'> VAR_POSITIONAL <class 'inspect._empty'>
True
4 z <class 'inspect._empty'> KEYWORD_ONLY <class 'inspect._empty'>
True
5 t <class 'inspect._empty'> KEYWORD_ONLY 10
False
6 kwargs <class 'inspect._empty'> VAR_KEYWORD <class 'inspect._empty'>
True业务应用
请检查用户输入是否符合参数注解的要求
思路
- 调用时,判断用户输入的实参是否符合要求
- 调用时,用户感觉上还是在调用 add 函数
- 对用户输入的数据和声明的类型进行对比,如果不符合,提示用户
import inspect
def add(x,y:int=7) -> int:
return x + y
def check(fn):
def wrapper(*args,**kwargs):
sig = inspect.signature(fn)
params = sig.parameters
values = list(params.values())
for i,p in enumerate(args):
if isinstance(p,values[i].annotation):
print(p,"==",values[i].annotation)
else:
print(p,"!=",values[i].annotation)
for k,v in kwargs.items():
if isinstance(v,params[k].annotation):
print(v,"is",params[k].annotation)
else:
print(v,"is not",params[k].annotation)
return fn(*args,**kwargs)
return wrapper
print(check(add)(10,y=20))
------------------------------------------------------------
10 != <class 'inspect._empty'>
20 is <class 'int'>
30进一步改进,业务需求是参数有注解就要求实参类型和声明应该一致,没有注解的参数不比较,如何修改代码?
import inspect
def check(fn):
def wrapper(*args,**kwargs):
sig = inspect.signature(fn)
params = sig.parameters
values = list(params.values())
for i,p in enumerate(args):
param = values[i]
if param.annotation is not param.empty and not isinstance(p,param.annotation):
print(p,"!==",values[i].annotation)
for k,v in kwargs.items():
if params[k].annotation is not inspect._empty and not isinstance(v,params[k],annotation):
print(k,v,"!===",params[k].annotation)
return fn(*args,**kwargs)
return wrapper
@check # add = check(add)
def add(x,y:int=7) -> int:
return x + y
print(add("a","b"))
--------------------------------------------------------------------
b !== <class 'int'>
ab11.11.7、functools 模块之 partial
partial 方法
- 偏函数,把函数的部分参数固定下来,相当于为部分参数添加了一个固定的默认值,形成一个新的函数并返回
- 从 partial 生成的新函数,是对原函数的封装
import functools
def add(x,y) -> int:
return x + y
newadd = functools.partial(add,y=5)
print(1,"-->",newadd(8))
print(2,"-->",newadd(8,y=6))
print(3,"-->",newadd(y=10,x=6))
import inspect
print(11,"-->",inspect.signature(newadd))
----------------------------------------------
1 --> 13
2 --> 14
3 --> 16
11 --> (x, *, y=5) -> intimport functools
def add(x,y,*args) -> int:
print(args)
return x + y
newadd = functools.partial(add,1,3,6,5)
print(1,"-->",newadd(7))
print(2,"-->",newadd(7,10))
# print(3,"-->",newadd(9,10,y=20,x=26)) 报错
print(4,"-->",newadd())
import inspect
print(inspect.signature(newadd))
----------------------------------------------------
(6, 5, 7)
1 --> 4
(6, 5, 7, 10)
2 --> 4
(6, 5)
4 --> 4
(*args) -> intpartial 函数本质
def partial(func,*args,**keywords):
def newfunc(*fargs,**fkeywords): # 包装函数
newkeywords = keywords.copy()
newkeywords.update(fkeywords)
return func(*(args+fargs),**newkeywords)
newfunc.func = func # 保留原函数
newfunc.args = args # 保留原函数的位置参数
newfunc.keywords = keywords # 保留原函数的关键字参数
return newfunc
def add(x,y):
return x + y
foo = partial(add,4)
foo(5)-
这个代码片段不太好理解的部分是 "保留原函数及参数",一开始是从装饰器的角度来理解,但它并不是装饰器,当 partial 打造了一个函数之后,就会进入 newfunc 片段,这个片段是要接受新的参数,问题是 partial 固定的那一部分参数怎么办呢,按理说必须跟 newfunc 接受的新参数合并才行,所以必须要把 partial 固定的函数及参数保留下来,便于合并
@functools.lru_cache(maxsize=128, typed=False)
-
Least-recently-used 装饰器,lru 最近最少使用,cache 缓存
-
如果 maxsize 设置为 None,则禁用 LRU 功能,并且缓存可以无限制增长,当maxsize是二的幂时,LRU功能执行得最好
-
如果typed设置为True,则不同类型的函数参数将单独缓存。例如,f(3)和f(3.0)将被视为具有不同结果的不同调用
import functools
import time
@functools.lru_cache()
def add(x, y, z=3):
time.sleep(z)
return x + y
print(1,"-->",add(4, 5)) # 等 5 秒
print(2,"-->",add(4.0, 5)) # 立即返回
print(3,"-->",add(4, 6)) # 等 5 秒
print(4,"-->",add(4, 6, 3)) # 等 5 秒
print(5,"-->",add(6, 4)) # 等 5 秒
print(6,"-->",add(4, y=6)) # 等 5 秒
print(7,"-->",add(x=4, y=6)) # 等 6 秒
print(8,"-->",add(y=6, x=4)) # 立即返回- 缓存的机制,根据一个引索,查看其值是否有缓存,很明显使用 kv 对实现是最方便的,所以用字典数据结构来实现缓存最便捷,lru 源码的实现也正是利用字典。根据这个例子的效果分析,如果 key 是一样的,那取缓存值就很快了,问题是 key 是如何确定的,这就引出了下面的 _make_key 函数
_make_key 函数
print(1,"-->",functools._make_key((4,6),{'z':3},False))
print(2,"-->",functools._make_key((4,6,3),{},False))
print(3,"-->",functools._make_key(tuple(),{'z':3,'x':4,'y':6},False))
print(4,"-->",functools._make_key(tuple(),{'z':3,'x':4,'y':6}, True))
---------------------------------------------------------------------
1 --> [4, 6, <object object at 0x000002AD0E8E0090>, 'z', 3]
2 --> [4, 6, 3]
3 --> [<object object at 0x000002AD0E8E0090>, 'x', 4, 'y', 6, 'z', 3]
4 --> [<object object at 0x000002AD0E8E0090>, 'x', 4, 'y', 6, 'z', 3, <class 'int'>, <class 'int'>, <class 'int'>]_make_key 源码
def _make_key(args, kwds, typed,
kwd_mark = (object(),), # 默认值是一个空对象元组
fasttypes = {int, str, frozenset, type(None)},
sorted=sorted, tuple=tuple, type=type, len=len): # 会用到的函数作为默认值传参进来
key = args # 首先将位置参数元组赋值给 key
if kwds:
sorted_items = sorted(kwds.items()) # 关键字参数排序后立即返回一个排好序的二元组列表
key += kwd_mark # 这一步结果类似 (4,6,<object object at 0x000002AD0E8E0090>)
for item in sorted_items: # 二元组也是元组,元素直接加到 key 里面
key += item # 这一步结果类似 (4,6,<object object at 0x000002AD0E8E0090>,'z', 3)
if typed:
key += tuple(type(v) for v in args) # 如果 type 为 True,3.0 和 3 这两个数是不一样的,key 自然要加以区分
if kwds:
key += tuple(type(v) for k, v in sorted_items)
elif len(key) == 1 and type(key[0]) in fasttypes:
return key[0]
return _HashedSeq(key) # key 做出来后,一定要 hash 一下,不然如果传的参是 y=[2],这就没法作为字典的 key 了lru_cache 装饰器加速一下 fibonacci 数列
import functools
@functools.lru_cache() # maxsize=None
def fib(n):
if n < 2:
return n
return fib(n-1) + fib(n-2)
print([fib(x) for x in range(35)])- 这个学习的过程中,有一个同学提出如果 maxsize=5,fib(500),速度还会快吗,针对上面的 fibonacci 数列,依然很快,fib(500) fib(499) ... fib(3) 都是一路问下来,缓存中 fib(1) fib(2) ... fib(499) 一路缓存上去,发生的计算很少,所以照样很快
lru_cache装饰器应用
使用前提
- 同样的函数参数一定得到同样的结果
- 函数执行时间很长,且要多次执行
- 本质是函数调用的参数=>返回值
- 适用场景,单机上需要空间换时间的地方,可以用缓存来将计算变成快速的查询
缺点
- 不支持缓存过期,key无法过期、失效
- 不支持清除操作
- 不支持分布式,是一个单机的缓存
11.11.8、举例
11.11.8.1、实现一个 cache 装饰器
简化设计,函数的形参定义不包含可变位置参数,可变关键词参数和 keyword-only 参数。可以不考虑缓存满了之后的换出问题。
-
数据类型的选择
缓存的应用场景,是有数据需要频繁查询,且每次查询都需要大量计算或者等待时间之后才能返回结果的情况。使用缓存来提高查询速度,用空间换取时间
-
cache 应该选用什么数据结构
通过输入某些参数,获得另外一个值,这就是查询的原型,查询用到的数据结构应该就是字典,输入 key,获得 value 值。难点在 key 的设计上面,
-
key 的存储
key 必须是可 hashable,key 能接受位置参数和关键字参数,位置参数被收集在 tuple 中,本身就有序;关键字参数被收集在字典中,本身无序。
让关键字参数有序?
- OrderDict 记录顺序。
- 用一个 tuple 保存排过序的字典的 item 的 kv 对。
11.11.8.2、key 的设计分析
假设 add(x,y) 是一个加法函数,接受的参数方式可能有以下几种:
- add(4,5)
- add(4,y=5)
- add(y=4,x=5)
- add(x=5,y=4)
可以有两种理解:第一种是 3 和 4 相同,而1、2 和 3 都不同;第二种是全部相同。
lru_cache 实现了第一种,可以看出单独的处理了位置参数和关键字参数
如果函数定义为 def add(4,y=5),使用了默认值,如何理解 add(4,5) 和 add(4) 是否一样呢?
如果认为一样,那么 lru_cache 无能为力,需要使用 inspect 来自己实现算法
11.11.8.3、key 的算法设计
inspect 模块获取函数签名后,取 parameters,这是一个有序字典,会保存所有参数的信息。
构建一个字典 params_dict,按照位置顺序从 args 中依次对应参数名和传入的实参,组成 kv 对,存入 params_dict 中。
kwargs 所有值 update 到 params_dict 中。
如果使用了缺省值的参数,不会出现在实参 params_dict 中,会出现在签名的取 parameters 中,缺省值也在定义中。
11.11.8.4、调用的方式
普通的函数调用可以,但是过于明显,最好类似 lru_cache 的方式,让调用者无察觉的使用缓存,构建装饰器函数。
目标:下面几种都等价,也就是 key 一样,这样都可以缓存。
def add(x,z,y=6):
return x + y + z
add(4,5)
add(4,z=5)
add(4,y=6,z=5)
add(y=6,z=5,x=4)
add(4,5,6)代码框架如下
from functools import wraps
import inspect
def ly_cache(fn):
local_cache = {} # 设计不同函数名对应不同的 cache
@wraps(fn)
def wrapper(*args,**kwargs): # 接收各种参数
ret = fn(*args,**kwargs)
return ret
return wrapper
@ly_cache
def add(x,y,z=6):
return x + y + z完成 key 的生成,这里使用普通的字典 params_dict,先把位置参数的对应好,再填充关键字参数,最后补充缺省值,然后再排序生成 key
from functools import wraps
import inspect
import time
def ly_cache(fn):
local_cache = {} # 设计不同函数名对应不同的 cache
@wraps(fn)
def wrapper(*args,**kwargs): # 接收各种参数
sig = inspect.signature(fn) # 签名可以辅助构建 key,重点还可以记录默认值
params = sig.parameters # 只读有序字典
param_names = [key for key in params.keys()] # list(params.keys())
params_dict = {}
for i,v in enumerate(args):
k = param_names[i]
params_dict[k] = v
params_dict.update(kwargs) # 这是优化的结果,最开始 params_dict 用的是元组,改成字典的好处
for k,v in params.items(): # 缺省值处理
if k not in params_dict.keys():
params_dict[k] = v.default
key = tuple(sorted(params_dict.items()))
if key not in local_cache.keys(): # 判断是否需要缓存
local_cache[key] = fn(*args,**kwargs)
return key, local_cache[key]
return wrapper
@ly_cache
def add(x,y,z=6):
time.sleep(3)
return x + y + z
print(add(4,5))
print(add(y=5,x=4))
print(add(4,5,6))
----------------------------------------------------------------------------------------
((('x', 4), ('y', 5), ('z', 6)), 15)
((('x', 4), ('y', 5), ('z', 6)), 15)
((('x', 4), ('y', 5), ('z', 6)), 15)增加 logger 装饰器查看执行时间
from functools import wraps
import inspect,time,datetime
def logger(fn):
@wraps(fn)
def wrapper(*args,**kwargs):
start = datetime.datetime.now()
ret = fn(*args,**kwargs)
delta = (datetime.datetime.now() - start).total_seconds()
print(fn.__name__,delta)
return ret
return wrapper
def ly_cache(fn):
local_cache = {} # 设计不同函数名对应不同的 cache
@wraps(fn)
def wrapper(*args,**kwargs): # 接收各种参数
sig = inspect.signature(fn) # 签名可以辅助构建 key,重点还可以记录默认值
params = sig.parameters # 只读有序字典
param_names = [key for key in params.keys()] # list(params.keys())
params_dict = {}
for i,v in enumerate(args):
k = param_names[i]
params_dict[k] = v
params_dict.update(kwargs) # 这是优化的结果,最开始 params_dict 用的是元组,改成字典的好处
for k,v in params.items(): # 缺省值处理
if k not in params_dict.keys():
params_dict[k] = v.default
key = tuple(sorted(params_dict.items()))
if key not in local_cache.keys(): # 判断是否需要缓存
local_cache[key] = fn(*args,**kwargs)
return key, local_cache[key]
return wrapper
@logger # 等价 add = logger(add)
@ly_cache # 等价 add = ly_cache(add)
def add(x,y,z=6):
time.sleep(3)
return x + y + z
print(add(4,5))
print(add(y=5,x=4))
print(add(4,5,6))
-----------------------------------------------------------------------------------------
add 3.00635
((('x', 4), ('y', 5), ('z', 6)), 15)
add 0.0
((('x', 4), ('y', 5), ('z', 6)), 15)
add 0.0
((('x', 4), ('y', 5), ('z', 6)), 15)11.11.8.5、cache 过期功能
一般缓存系统都有过期功能
过期指的是某一个 key 过期,可以对每一个 key 单独设置过期时间,也可以对这些 key 统一设定过期时间
本次设计简单点,统一设定 key 的过期时间,当 key 生存周期超过了这个时间,就自动被清除
这里并没有考虑多线程问题,而且这种过期机制,每一次都有遍历所有数据,大量数据的时候,有效率问题
清除时机,何时清除过期 key?
- 用到某个 key 之前,先判断是否过期,如果过期重新调用函数生成新的 key 对应 value 值
- 一个线程负责清除过期的 key,这个以后实现,本次在创建 key 之前,清除所有过期的 key
value 的设计?
- key => (v,createtimestamp),适合 key 过期时间都是统一的设定
- key => (v,createtimestamp,duration),duration 是过期时间,这样每一个 key 就可以单独控制过期时间,在这种设计中,-1 可以表示永不过期,0 可以表示立即过期,正整数表示持续一段时间过期
本次采用第一种实现:
from functools import wraps
import inspect,time,datetime
def logger(fn):
@wraps(fn)
def wrapper(*args,**kwargs):
start = datetime.datetime.now()
ret = fn(*args,**kwargs)
delta = (datetime.datetime.now() - start).total_seconds()
print(fn.__name__,delta)
return ret
return wrapper
def ck_cache(duration):
def _cache(fn):
local_cache = {} # 设计不同函数名对应不同的 cache
@wraps(fn)
def wrapper(*args,**kwargs): # 接收各种参数
expire_keys = [] # 清除过期的key
for k,(_,stamp) in local_cache.items():
now = datetime.datetime.now().timestamp()
if now - stamp > duration:
expire_keys.append(k)
for k in expire_keys:
local_cache.pop(k)
sig = inspect.signature(fn) # 签名可以辅助构建 key,重点还可以记录默认值
params = sig.parameters # 只读有序字典
param_names = [key for key in params.keys()] # list(params.keys())
params_dict = {}
for i,v in enumerate(args):
k = param_names[i]
params_dict[k] = v
params_dict.update(kwargs) # 这是优化的结果,最开始 params_dict 用的是元组,改成字典的好处
for k,v in params.items(): # 缺省值处理
if k not in params_dict.keys():
params_dict[k] = v.default
key = tuple(sorted(params_dict.items()))
if key not in local_cache.keys(): # 判断是否需要缓存
local_cache[key] = (fn(*args,**kwargs),datetime.datetime.now().timestamp())
return key, local_cache[key]
return wrapper
return _cache
@logger # 等价 add = logger(add)
@ck_cache(6) # 等价 add = ly_cache(add)
def add(x,y,z=6):
time.sleep(3)
return x + y + z
print(add(4,5))
print(add(y=5,x=4))
print(add(4,5,6))
time.sleep(7)
print(">>>>>>>>>>>>>>>>>>>>>>>")
print(add(4,5,6))
----------------------------------------------------------------------------------------
add 3.004313
((('x', 4), ('y', 5), ('z', 6)), (15, 1586068635.485182))
add 0.0
((('x', 4), ('y', 5), ('z', 6)), (15, 1586068635.485182))
add 0.0
((('x', 4), ('y', 5), ('z', 6)), (15, 1586068635.485182))
>>>>>>>>>>>>>>>>>>>>>>>
add 3.014408
((('x', 4), ('y', 5), ('z', 6)), (15, 1586068645.502859))- 可以进一步美化一下代码,把过期删除代码块抽象成函数 clear_expire(),把制作 key 的代码块抽象成函数 make_key()
抽象函数美化代码:
from functools import wraps
import inspect,time,datetime
def logger(fn):
@wraps(fn)
def wrapper(*args,**kwargs):
start = datetime.datetime.now()
ret = fn(*args,**kwargs)
delta = (datetime.datetime.now() - start).total_seconds()
print(fn.__name__,delta)
return ret
return wrapper
def ck_cache(duration):
def _cache(fn):
local_cache = {} # 设计不同函数名对应不同的 cache
@wraps(fn)
def wrapper(*args,**kwargs): # 接收各种参数
def clear_expire(cache):
expire_keys = [] # 清除过期的key
for k,(_,stamp) in cache.items():
now = datetime.datetime.now().timestamp()
if now - stamp > duration:
expire_keys.append(k)
for k in expire_keys:
cache.pop(k)
clear_expire(local_cache)
def make_key():
sig = inspect.signature(fn) # 签名可以辅助构建 key,重点还可以记录默认值
params = sig.parameters # 只读有序字典
param_names = [key for key in params.keys()] # list(params.keys())
params_dict = {}
for i,v in enumerate(args):
k = param_names[i]
params_dict[k] = v
params_dict.update(kwargs) # 这是优化的结果,最开始 params_dict 用的是元组,改成字典的好处
for k,v in params.items(): # 缺省值处理
if k not in params_dict.keys():
params_dict[k] = v.default
return tuple(sorted(params_dict.items()))
key = make_key()
if key not in local_cache.keys(): # 判断是否需要缓存
local_cache[key] = (fn(*args,**kwargs),datetime.datetime.now().timestamp())
return key, local_cache[key]
return wrapper
return _cache
@logger # 等价 add = logger(add)
@ck_cache(6) # 等价 add = ly_cache(add)
def add(x,y,z=6):
time.sleep(3)
return x + y + z
print(add(4,5))
print(add(y=5,x=4))
print(add(4,5,6))
time.sleep(7)
print(">>>>>>>>>>>>>>>>>>>>>>>")
print(add(4,5,6))
-----------------------------------------------------------------------------------------
add 3.000478
((('x', 4), ('y', 5), ('z', 6)), (15, 1586069416.768573))
add 0.001008
((('x', 4), ('y', 5), ('z', 6)), (15, 1586069416.768573))
add 0.0
((('x', 4), ('y', 5), ('z', 6)), (15, 1586069416.768573))
>>>>>>>>>>>>>>>>>>>>>>>
add 3.00155
((('x', 4), ('y', 5), ('z', 6)), (15, 1586069426.772568))11.12、练习
11.12.1、字典扁平化
# 源字典 {'a':{'b':1,'c':2},'d':{'e':3,'f':{'g':4}}}
# 目标字典 {'a.c':2,'d.e':3,'d.f.g':4,'a.b':1}
source = {'a':{'b':1,'c':2},'d':{'e':3,'f':{'g':4}}}
target = {}
# recursion
def flatmap(src,prefix=""):
for k,v in src.items():
if isinstance(v,(list,tuple,set,dict)):
flatmap(v,prefix=prefix+k+".")
else:
target[prefix+k] = v
flatmap(source)
print(target)
------------------------------------------------------
{'a.b': 1, 'd.f.g': 4, 'a.c': 2, 'd.e': 3}一般这种函数都会生成一个新的字典,因此改造一下
dest 字典可以由内部创建,也可以由外部提供
source = {'a':{'b':1,'c':2},'d':{'e':3,'f':{'g':4}}}
# recursion
def flatmap(src,dest=None,prefix=""):
if dest == None:
dest = {}
for k,v in src.items():
if isinstance(v,(list,dict,tuple,set)):
flatmap(v,dest,prefix=prefix+k+".") # 递归调用
else:
dest[prefix+k] = v
return dest
print(flatmap(source))
---------------------------------------------------------
{'a.b': 1, 'd.f.g': 4, 'a.c': 2, 'd.e': 3}能否不暴露给外界内部的字典?
能否函数就提供一个参数源字典,返回一个新的扁平化字典?
递归时候要把目标字典的引用传递多层,怎么处理?
source = {'a':{'b':1,'c':2},'d':{'e':3,'f':{'g':4}}}
# recursion
def flatmap(src):
def _flatmap(src,dest=None,prefix=""):
for k,v in src.items():
key = prefix + k
if isinstance(v,(list,tuple,set,dict)):
_flatmap(v,dest,key+".")
else:
dest[key] = v
dest = {}
_flatmap(src,dest)
return dest
print(flatmap(source))
----------------------------------------------------------
{'a.b': 1, 'd.f.g': 4, 'a.c': 2, 'd.e': 3}11.12.2、实现 Base64 编码解码
Base64 位编码索引表
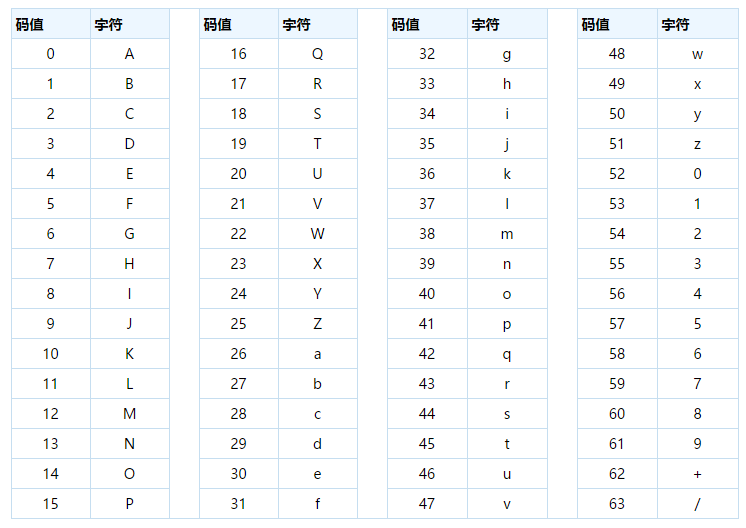
Base64 位编码的基本原则
- 将输入的字符串每 3 个字节断开,拿出一个 3 字节,每 6 个 bit 断开成 4 段
- 每一段当作一个 8bit 看它的值,这个值就是 Base64 编码表的索引值,找到对应字符
- 虽然每一段看作 8bit,但是有效值是 6bit,2**6=64,因此有了 Base64 的编码表
- 继续往后取 3 个字节,同样处理,直到最后
举例说明
# 如果取的是abc,对应的ASCII码为:0x61 0x62 0x63
01100001 01100010 01100011 # abc的二进制
011000 010110 001001 100011 # 每6位一组,前面可以补2个0看作8位
24 22 9 35
# 有时也不可能刚好3个字节,如果取的是a,怎么处理?
# a 对应的ASCII码为:0x61
01100001 # a的二进制
011000 010000 000000 000000- 正好 3 个字节,处理方式同 abc
- 剩 1 个字节或 2 个字节,用 0 补满 3 个字节
- 补 0 的字节用 = 表示,这里要注意,如果是 01100000,变成 4 个 6 位,相当于补了 2 个 =,因为第 2 个 6 位有两个有效 0
自己实现对一段字符串进行base64编码
alphabet = b"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
teststr="abcd"
def base64(src):
src = src.encode() # 将字符串转换成 bytes
ret = bytearray()
length = len(src)
r = 0 # 记录补 0 的个数
for offset in range(0,length,3):
if offset + 3 <= length:
triple = src[offset:offset + 3]
else:
triple = src[offset:]
r = 3 - len(triple)
triple = triple + b"\x00" * r
# 将 3 个字节看成一个整体,得到整数,大端模式
# abc => 0x616263
b = int.from_bytes(triple,"big")
print(b,hex(b))
# 01100001 01100010 01100011 # abc
# 011000 010110 001001 100011 # 每 6 位断开
for i in range(18,-1,-6):
if i == 18:
index = b >> i
else:
index = b >> i & 0x3F
ret.append(alphabet[index]) # 得到 base64 编码的列表
# 补了几个 0 就替换几个 =
for i in range(1,r+1):
ret[-i] = 0x3D
return ret
print(base64(teststr))
print("======================")
import base64
print(base64.b64encode(teststr.encode()))
----------------------------------------------------------------------
6382179 0x616263
6553600 0x640000
bytearray(b'YWJjZA==')
======================
b'YWJjZA=='base64 解码实现
alphabet = b"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
def base64decode(src:bytes):
ret = bytearray()
length = len(src)
step = 4 # 对齐的,每次取4个
for offset in range(0,length,step):
tmp = 0x00
block = src[offset:offset + step]
# 开始移位计算
for i,c in enumerate(reversed(block)):
index = alphabet.find(c) # 替换字符为序号
if index == -1:
continue # 找不到就是 0,不用移位相加了
tmp += index << i*6
ret.extend(tmp.to_bytes(3,'big'))
return bytes(ret.rstrip(b"\x00")) # 把最右边的 \x00 去掉,不可变
txt = "SSBsb3ZlIHlvdSAqIA=="
txt = txt.encode()
print(txt)
print(base64decode(txt).decode())
print()
import base64
print(base64.b64decode(txt).decode())
---------------------------------------------------------------------------------
b'SSBsb3ZlIHlvdSAqIA=='
I love you *
I love you *改进:1. reversed 可以不需要,2. alphabet.find 效率低
from collections import OrderedDict
base_tbl = b"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
alphabet = OrderedDict(zip(base_tbl,range(64)))
def base64decode(src:bytes):
ret = bytearray()
length = len(src)
step = 4 # 对齐的,每次取 4 个
for offset in range(0,length,step):
tmp = 0x00
block = src[offset:offset + step]
# 开始移位计算
for i in range(4):
index = alphabet.get(block[-i-1])
if index is not None:
tmp += index << i*6
ret.extend(tmp.to_bytes(3,"big"))
return bytes(ret.rstrip(b"\x00")) # 把最右边的 \x00 去掉,不可变
txt = "SSBsb3ZlIHlvdSAqIA=="
txt = txt.encode()
print(base64decode(txt).decode())
print()
import base64
print(base64.b64decode(txt).decode())
-----------------------------------------------------------------------------
I love you *
I love you *11.12.3、实现命令分发器
- 程序员可以方便的注册函数到某一个命令,用户输入命令时,路由到注册的函数
- 如果此命令没有对应的注册了函数,执行默认函数
- 用户输入用 input(">>")
# 基本框架
cmds = {}
def ls():
print("我是 ls ")
def default_func():
print("没有注册")
def reg(cmd,fn):
cmds[cmd] = fn
reg("ls",ls)
def dispatch():
while True:
cmd = input("please input cmd:")
if cmd == "quit":
break
else:
cmds.get(cmd,default_func)()
dispatch()
------------------------------------------------------
please input cmd:ls
我是 ls
please input cmd:cat
没有注册
please input cmd:quit此代码很丑陋,所有函数和字典都在全局中定义,不好看,如何改进?
封装,将 reg 函数封装成装饰器,并用它来注册函数
def reg(cmd):
def _reg(fn):
cmds[cmd] = fn
return fn
return _reg
@reg("ls") # 等价 ls = reg("ls")(ls)
def ls():
print("我是 ls ")用户一般只用到调度各注册,是否可以把字典、reg、dispatcher等封装起来
def cmd_dispatcher():
cmds = {}
def reg(cmd): # 注册函数
def _reg(fn):
cmds[cmd] = fn
return fn
return _reg
def default_func():
print("没有注册")
def dispatcher():
while True:
cmd = input(">>")
if cmd.strip() == "":
return
cmds.get(cmd,default_func)()
return reg,dispatcher
reg,dispatcher = cmd_dispatcher()
@reg("ls") # 等价 ls = reg("ls")(ls)
def ls():
print("我是 ls ")
dispatcher()
---------------------------------------------------------------------------
>>ls
我是 ls
>>cat
没有注册
>>到这里,代码优雅了不少,不过这样的代码在业务上也存在一些问题
- 如果一个函数使用同样的 cmd 名称注册,就等于覆盖了原来的 cmd 到 fn 的关系,这样的逻辑也是合理的
- 也可以加一个判断,如果 key 已存在,重复注册,抛出异常,看业务要求
- 有注册应该有注销,注销得有权限,什么样的人才有这个权限,看业务需求
11.12.4、求最长公共子串
s1 = "abcdefg"
s2 = "defabcd"
矩阵算法:让s2的每一个元素,去分别和s1的每一个元素比较,相同就是1,不同就是0,有下面的矩阵
| s1(abcdefg) | |
|---|---|
| s2("d") | 0001000 |
| s2("e") | 0000100 |
| s2("f") | 0000010 |
| s2("a") | 1000000 |
| s2("b") | 0100000 |
| s2("c") | 0010000 |
| s2("d") | 0001000 |
观察,将相邻的1串起来组成一条斜线,哪条斜线最长就是最长公共子串
扫描的过程就是 len(s1) len(s2) 次,O(nm) 的效率
核心算法就是 s2 的单个字符到 s1 中遍历,相等的话,就在上一个数(横纵坐标减 1 记录的那个数)的基础上加 1,如果是边界情况,直接赋值 1 就好,如下图矩阵所示
| s1(abcdefg) | |
|---|---|
| s2("d") | 0001000 |
| s2("e") | 0000200 |
| s2("f") | 0000030 |
| s2("a") | 1000000 |
| s2("b") | 0200000 |
| s2("c") | 0030000 |
| s2("d") | 0004000 |
s1 = "abcdefg"
s2 = "defabcd"
def findit(str1,str2):
matrix = []
# 从 x 轴或者 y 轴取都可以,选择 x 轴,xmax 和 xindex
xmax = 0
xindex = 0
for i,x in enumerate(str2):
matrix.append([])
for j,y in enumerate(str1):
if x != y: # 若两个字符不相等
matrix[i].append(0)
else:
if i == 0 or j == 0:
matrix[i].append(1)
else:
matrix[i].append(matrix[i-1][j-1] + 1)
if matrix[i][j] > xmax: # 判断当前加入的值和记录的最大值比较
xmax = matrix[i][j] # 记录最大值,用于下次比较
xindex = j # 记录当前值的 x 轴偏移量
return str1[xindex+1-xmax:xindex+1]
print(findit(s1,s2))
---------------------------------------------------------------------------------
abcd