
6、Python3 CMDB
CMDB,Configuration Management DB,配置管理数据库。
配置管理不是用来管理配置文件的,而是管理资产的。狭义的 CMDB 是偏向纯资产管理的,而宽泛的 CMDB 集成了很多其他功能,已经发展成一个运维管理信息系统了。
因为,运维系统往往围绕着这些资产管理中心,从这个 CMDB 中获取公共的数据。设计一个 CMDB 的核心是 DB。
6.1、设计
目标:设计一个数据库系统,以实现存储主机信息、交换机信息、网络信息、系统信息等 IT 信息化系统。
原始版本:
资产管理的初期,需要把凌乱、分散的各种软硬件、配置信息集中管理。
构建 MySQL 数据库的表,将数据放置其中。
由于管理的资产的多样性,表如果没有很好的设计,就会很难适应需求的增长,经常需要改动,例如增加字段来适应存储更多的属性。
管理服务器、防火墙等,需要的字段不一样;管理主机信息、数据库信息等,所需字段也不一样。而这些信息都需要管理,但又不能每一种设备单独建表。
虚拟表设计:依然基于 MySQL 来实现 CMDB。充分考虑运维日常管理信息的复杂性,将管理信息所需要的表、字段、值抽离出去形成不同的表。
6.1.1、CMDB 实现
-
手动建立一个数据库 CMDB
-
建立 schema 模型表
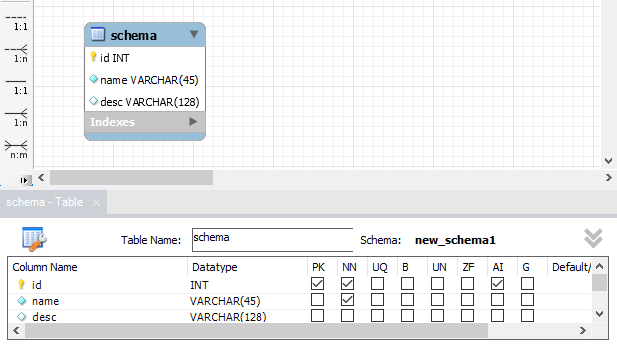
-
建立 field 字段表
描述可用字段,用来给模型表动态增加字段。
meta,字段的元数据。
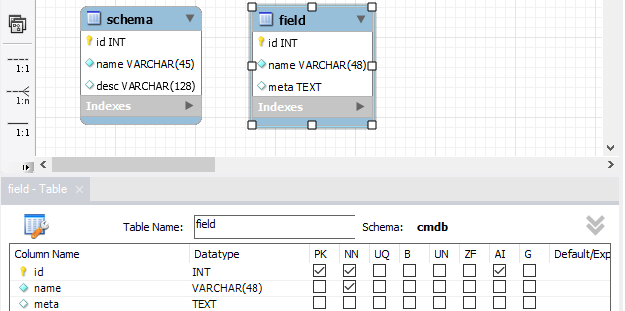
-
建立关系
一对多关系,在多端加字段 schema_id 解决,模型自动生成。
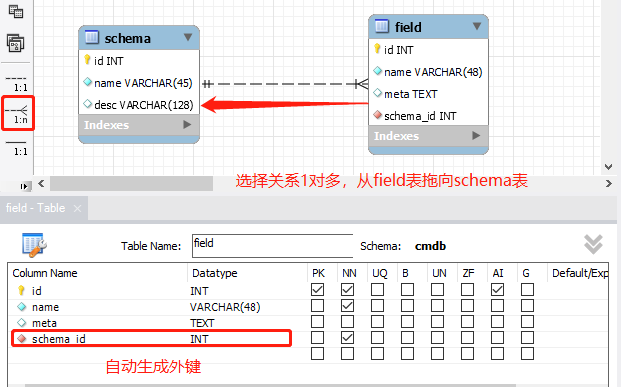
描述资产是非常难的事情,不同资产,或不同资产的不同型号,就有着不同的属性和值。很难在一张表中设计固定个数的字段保存数据,所以,这里使用 2 张表来描述,schema 中建立一种资产,就可以为其在 field 表中建立很多记录来描述属性,以后要加属性只需要在 field 表中增加一条记录描述。
可以使用 schema + field 构成一张张虚拟的表定义。
每一个 schema 的 id 对应一张表。例如 ipaddress 表对应的 schema_id 为 10,它有 2 个字段,字段的描述在 field 表中,1,controller1,null,10 和字段 2,compute1,null,10。这 2 部分构成一张表的定义。
-
entity 实体表
entity 表中实体化一条条记录,一条条实体记录使用哪一个 schema,也就是说属于哪一张表,一对多的关系。
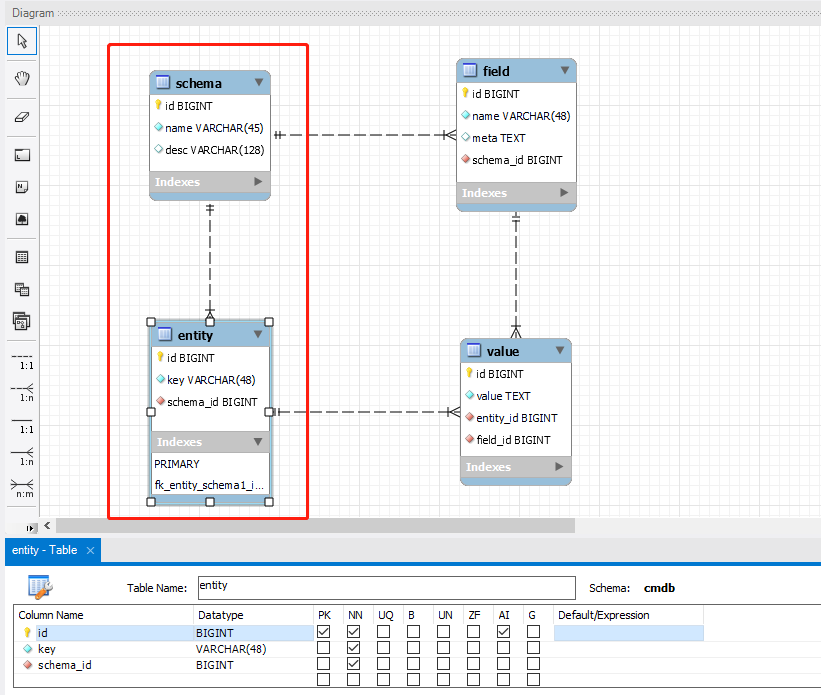
key 使用 uuid 来描述一个唯一值。
-
value 记录表
entity 使用了 schema,就等于使用 field 表中这个 schema_id 对应的所有字段,这些字段的值需要保存。
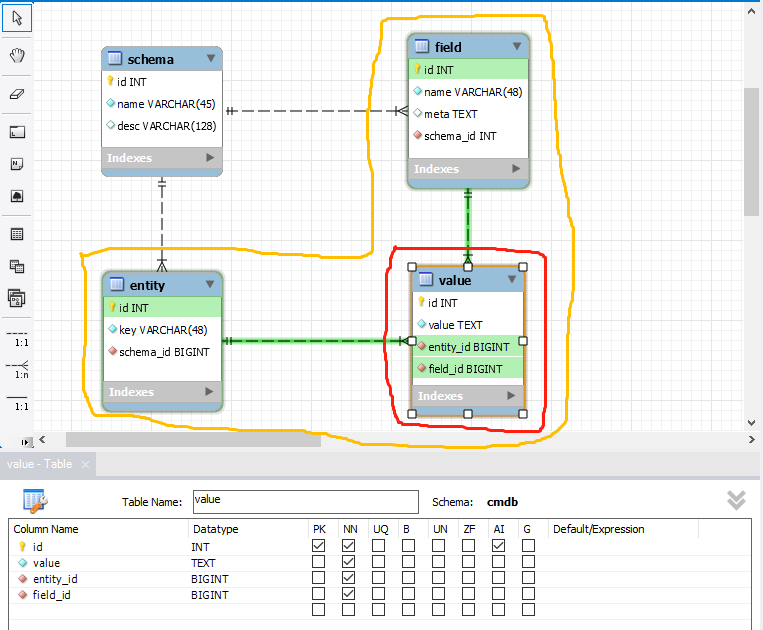
明确的一个数据,通过 entity_id 就等于知道了使用哪一张虚拟表,就可以在 value 表中为虚拟表的字段填入值了。
整个表关系如下所示:
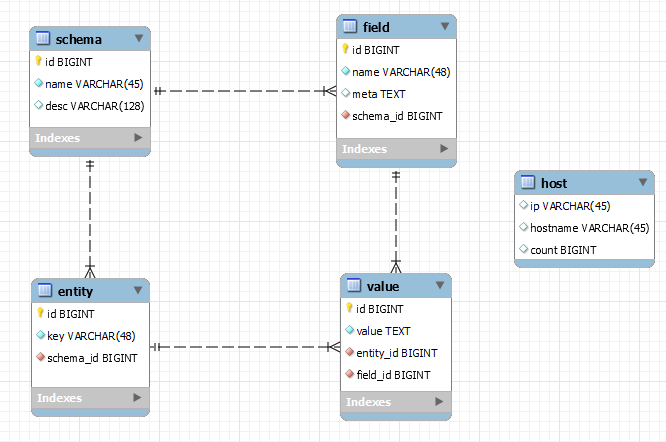
注意:右边的 host 表是假想的虚拟表,仅作参考。另外,表中的 INT 类型都修改为 BIGINT,否则模型转表报错。
在建模工具 workbench 中点 Database -> Forward Engineer,根据提示操作,将模型转化成数据库的表,全部建表语句:
-- MySQL Workbench Forward Engineering SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0; SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0; SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION'; -- ----------------------------------------------------- -- Schema cmdb -- ----------------------------------------------------- -- ----------------------------------------------------- -- Schema cmdb -- ----------------------------------------------------- CREATE SCHEMA IF NOT EXISTScmdb; USEcmdb; -- ----------------------------------------------------- -- Tablecmdb.schema-- ----------------------------------------------------- CREATE TABLE IF NOT EXISTScmdb.schema(idBIGINT NOT NULL AUTO_INCREMENT,nameVARCHAR(45) NOT NULL,descVARCHAR(128) NULL, PRIMARY KEY (id)) ENGINE = InnoDB; -- ----------------------------------------------------- -- Tablecmdb.field-- ----------------------------------------------------- CREATE TABLE IF NOT EXISTScmdb.field(idBIGINT NOT NULL AUTO_INCREMENT,nameVARCHAR(48) NOT NULL,metaTEXT NULL,schema_idBIGINT NOT NULL, PRIMARY KEY (id), INDEXfk_field_schema_idx(schema_idASC) VISIBLE, CONSTRAINTfk_field_schemaFOREIGN KEY (schema_id) REFERENCEScmdb.schema(id) ON DELETE NO ACTION ON UPDATE NO ACTION) ENGINE = InnoDB; -- ----------------------------------------------------- -- Tablecmdb.entity-- ----------------------------------------------------- CREATE TABLE IF NOT EXISTScmdb.entity(idBIGINT NOT NULL AUTO_INCREMENT,keyVARCHAR(48) NOT NULL,schema_idBIGINT NOT NULL, PRIMARY KEY (id), INDEXfk_entity_schema1_idx(schema_idASC) VISIBLE, CONSTRAINTfk_entity_schema1FOREIGN KEY (schema_id) REFERENCEScmdb.schema(id) ON DELETE NO ACTION ON UPDATE NO ACTION) ENGINE = InnoDB; -- ----------------------------------------------------- -- Tablecmdb.value-- ----------------------------------------------------- CREATE TABLE IF NOT EXISTScmdb.value(idBIGINT NOT NULL AUTO_INCREMENT,valueTEXT NOT NULL,entity_idBIGINT NOT NULL,field_idBIGINT NOT NULL, PRIMARY KEY (id), INDEXfk_value_entity1_idx(entity_idASC) VISIBLE, INDEXfk_value_field1_idx(field_idASC) VISIBLE, CONSTRAINTfk_value_entity1FOREIGN KEY (entity_id) REFERENCEScmdb.entity(id) ON DELETE NO ACTION ON UPDATE NO ACTION, CONSTRAINTfk_value_field1FOREIGN KEY (field_id) REFERENCEScmdb.field(id) ON DELETE NO ACTION ON UPDATE NO ACTION) ENGINE = InnoDB; SET SQL_MODE=@OLD_SQL_MODE; SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS; SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS;
举例:
定义一张主机表来管理主机。
insert into cmdb.schema(name) values('host');
select * from cmdb.schema;
insert into field(name, schema_id) values('hostname', 1),('ip',1);
select * from field;
select * from cmdb.schema, field where field.schema_id = cmdb.schema.id and cmdb.schema.id = 1;注意:schema 是个关键字,直接用报错,要指定哪个数据库的表,即 cmdb.schema。
上面的语句就可以成功创建一张虚拟的 host 表,有 2 个字段 hostname、ip。
假设现在需要记录一条主机信息,hostname 为 webserver,ip 为 192.168.1.10。
-- 增加一条实体记录A
insert into entity(`key`, schema_id) values('355e7056794411ee8898000c29d20aed', 1);
-- 实体记录A的值记录在value表中
insert into cmdb.value(entity_id, field_id, `value`) values(1, 1, 'webserver'), (1, 2, '192.168.1.10');
-- 增加一条实体记录B
insert into entity(`key`, schema_id) values('ac0732f0794a11ee8898000c29d20aed',1);
-- 实体记录B的值记录在value表中
insert into cmdb.value(entity_id, field_id, `value`) values(2, 1, 'DBserver'), (2, 2, '192.168.1.20');好,这样就把数据存进去了。
查询看看:
SELECT
`entity`.`id` AS `entity_id`,
`entity`.`key`,
`entity`.`schema_id`,
`schema`.`name`,
`field`.`id`,
`field`.`name` AS `fname`,
`value`.`value`
FROM
`entity`
INNER JOIN `value` ON `value`.`entity_id` = `entity`.`id`
INNER JOIN `schema` ON `entity`.`schema_id` = `schema`.`id`
INNER JOIN `field` ON `value`.`field_id` = `field`.`id`
好处:
不管需要多少配置项,需要就在 schema 表中添加。
不管配置项有多少属性字段,需要就在 field 表中增加即可。
坏处:
表结构复杂了,关系复杂了,原来一张张表变成了多张表的关系。复杂的同时,带来了灵活。
ORM 不认识这种表,需要自己封装实现。
问题:
有这样一个需求,host 中业务需要所有主机 ip 不可重复记录,也就是一台主机占用这个 IP 地址并记录了,不可以重复记录,也不可以其他主机使用这个 IP 了。如何实现?
为 value 表的 value 字段加上 unique 唯一约束行吗?
看似可以,但是这个 value 字段还要记录其它虚拟表的值,可能会写不进来数据。例如,记录数据库服务器地址,可能使用了这个 IP,就会写入失败,因为 value 字段唯一键约束。
如何使用约束?
数据库的约束无法使用了,只能在应用层代码上解决了。这个时候,刚才在 field 表中预留的 meta 字段就派上用场了。
6.1.2、约束设计
思路 1:meta 字段中存储一个校验字段的方式。
-
数据类型
例如 int、str,这些都可以被程序后续用作类型转换。
但是如果是 IP 地址,怎么转换?或者更加复杂类型,如何实现。
-
如何校验
可以使用正则表达式。
正则表达式较难掌握,实现规则多样,复杂难以测试,且不是面向对象的实现方式。
思路 2:
meta 是 text 类型,就是字符串。是否可以使用 Json 来描述呢?
将 Json 中的字符串变成 Python 代码运行,使用反射动态加载运行。
这样实现需要约定好调用的接口。
6.2、开发
使用 pycharm 构建项目,名称为 cmdb,使用虚拟环境,python 版本 3.10.10。
本项目主要代码都放在 cmdb 包下。
6.2.1、约束实现
cmdb.types 包里面定义类 BaseType 和其子类 Int
class BaseType:
"""cmdb 类型基类"""
def stringify(self, value):
"""基类方法,未实现"""
raise NotImplementedError()
def destringify(self, value):
"""基类方法,未实现"""
raise NotImplementedError()
class Int(BaseType):
def stringify(self, value):
return str(int(value))
def destringify(self, value):
return value项目根目录下,建立 app.py
import json
# 模拟字段保存的json字符串
jsonstr = """
{
"type": "cmdb.types.Int",
"value": 300
}
"""
obj = json.loads(jsonstr)
print(obj)
# 结果:{'type': 'cmdb.types.Int', 'value': 300}cmdb.types.Int 这个字符串中包含我们要的类型信息。如何取?
1、建立字典映射。
2、使用反射。
采用第二种反射方式完成。
import json
# 模拟字段保存的json字符串
jsonstr = """
{
"type": "cmdb.types.Int",
"value": 300
}
"""
obj = json.loads(jsonstr)
import importlib
from cmdb.types import BaseType
def get_instance(type: str):
m, c = type.rsplit('.', maxsplit=1)
print(m, c)
mod = importlib.import_module(m)
cls = getattr(mod, c)
obj = cls()
if isinstance(obj, BaseType):
return obj
raise TypeError(f'Wrong Type {type}. Not subclass of BaseType.')
Int = get_instance(obj.get('type'))
print(Int.stringify(obj.get('value')))get_instance 可以放到 cmdb.types 模块中去。
6.2.2、IP 地址的约束
Python 3.3 提供了 ipaddress 库,ipaddress.ip_address(address),address 可以是 int 或者 str,返回一个 IPAddress 对象,使用 str 返回一个 IP 地址。
编写 cmdb.types.IP 类:
import importlib
import ipaddress
def get_instance(type: str):
m, c = type.rsplit('.', maxsplit=1)
print(m, c)
mod = importlib.import_module(m)
cls = getattr(mod, c)
obj = cls()
if isinstance(obj, BaseType):
return obj
raise TypeError(f'Wrong Type {type}. Not subclass of BaseType.')
class BaseType:
"""cmdb 类型基类"""
def stringify(self, value):
"""基类方法,未实现"""
raise NotImplementedError()
def destringify(self, value):
"""基类方法,未实现"""
raise NotImplementedError()
class Int(BaseType):
def stringify(self, value):
return str(int(value))
def destringify(self, value):
return value
class IP(BaseType):
"""实现IP数据检验和转换"""
def stringify(self, value):
"""错误的数据不要给默认值,就抛异常让外部捕获"""
return str(ipaddress.ip_address(value))
def destringify(self, value):
return valueapp.py 中使用如下:
import json
from cmdb.types import get_instance
# 模拟字段保存的json字符串
jsonstr = """
{
"type": "cmdb.types.Int",
"value": 300
}
"""
obj = json.loads(jsonstr)
Int = get_instance(obj.get('type'))
print(Int.stringify(obj.get('value')))
ipdict = {
"type": "cmdb.types.IP",
"value": "192.168.142.135"
}
IP = get_instance(ipdict.get('type'))
print(IP.stringify(ipdict.get('value')))使用反射实现动态加载类型的方式,非常的灵活,可以扩展更多的类型,并把数据验证、转换交给类型自己完成。
这是一种插件化编程思想的具体实现。
6.2.3、增加限制
例如,Int 类型能否提供一个验证机制,给出函数是一种办法。
json 中存函数可以做到,但 Python 不太好解析。可以考虑其他语言动态生成函数并验证,但是和 python 通信是个问题。问题复杂了。
那么,Int 类型无非就是一个范围,提供最小值就是要求大于它,提供最大值,就是一定要小于它。
{
"type": "cmdb.types.Int",
"option": {
"min": 10,
"max": 30
},
"value": 28
}如何把数据送给 Int 类型呢?
通过构造函数送入:
class BaseType:
"""cmdb 类型基类"""
def __init__(self, **option):
self.__dict__['option'] = option
def __getattr__(self, item): # 这是魔术方法的意义,忘了就去查文档
return self.option[item]
def stringify(self, value):
"""基类方法,未实现"""
raise NotImplementedError()
def destringify(self, value):
"""基类方法,未实现"""
raise NotImplementedError()为了可以通过属性的方式方便地访问 option,增加了 __getattr__ 方法。
用户并不能直接创建 BaseType 或者其子类的实例,是通过 get_instance 方法动态创建,所以需要在这个函数中增加 option 参数。
def get_instance(type: str, **option):
m, c = type.rsplit('.', maxsplit=1)
print(m, c)
mod = importlib.import_module(m)
cls = getattr(mod, c)
obj = cls(**option) # 从这里导入选项
if isinstance(obj, BaseType):
return obj
raise TypeError(f'Wrong Type {type}. Not subclass of BaseType.')在 Int 中实现,增加最大值、最小值的验证,放在 stringify 函数中。
class Int(BaseType):
def stringify(self, value):
"""转换,错误的数据不要给默认值,就抛异常让外部捕获"""
val = int(value)
min = self.min
if min and val < min:
raise ValueError("too small")
max = self.max
if max and val > max:
raise ValueError("too big")
return str(val)
def destringify(self, value):
return valueInt 使用方式:
import json
from cmdb.types import get_instance
# 模拟字段保存的json字符串
jsonstr = """
{
"type": "cmdb.types.Int",
"option": {
"min": 10,
"max": 30
},
"value": 20
}
"""
obj = json.loads(jsonstr)
Int = get_instance(obj.get('type'), **obj.get('option'))
print(Int.stringify(obj.get('value')))实现 IP 的限制。例如,要求 IPv4 地址必须以 192 开头 prefix。
class IP(BaseType):
"""实现IP数据检验和转换"""
def stringify(self, value):
"""错误的数据不要给默认值,就抛异常让外部捕获"""
prefix = self.prefix
if prefix and not str(value).startswith(prefix):
raise ValueError(f'Must start with {prefix}')
return str(ipaddress.ip_address(value))
def destringify(self, value):
return valueIP 使用方式:
meta = {
"type": "cmdb.types.IP",
"value": "192.168.142.135",
"option": {
"prefix": "192.1"
}
}
IP = get_instance(meta.get('type'), **meta.get('option'))
print(IP.stringify(meta.get('172.16.0.9')))6.2.4、拆分 get_instance
get_instance 这个函数分为 2 部分:
1、加载初始化类
2、创建初始化
按照上面的功能拆分。
def get_class(type: str):
m, c = type.rsplit('.', maxsplit=1)
print(m, c)
mod = importlib.import_module(m)
cls = getattr(mod, c)
if issubclass(cls, BaseType):
return cls
raise TypeError(f'Wrong Type {type}. Not subclass of BaseType.')
def get_instance(type: str, **option):
obj = get_class(type)(**option)
return obj6.2.5、缓存
为了使用一个实例,每一次都需要获取类创建实例。能够缓存?
减少每次都需要重新创建实例的过程,采用懒加载思想,第一次用才创建。
classes_cache = {} # 类缓存
缓存什么?key 是什么?
动态加载模块、类的函数 get_class,加入类缓存是为了减少类加载过程吗,避免重复加载吗?
cmdb.types.IP 作为 key,value 是类对象。
classes_cache = {} # 类缓存
def get_class(type: str):
# 使用缓存
cls = classes_cache.get(type)
if cls:
return cls
m, c = type.rsplit('.', maxsplit=1)
print(m, c)
mod = importlib.import_module(m)
cls = getattr(mod, c)
if issubclass(cls, BaseType):
classes_cache[type] = cls
return cls
raise TypeError(f'Wrong Type {type}. Not subclass of BaseType.')其实这个类缓存是为了加快获取类对象的速度,原来是导入模块后搜索类对象,变成了直接到 classes_cache 字典
中使用 key 搜索。
instances_cache = {} # 实例缓存
key 是什么?cmdb.types.IP 行吗?
假设有如下的 meta 描述:
{
"type": "cmdb.types.IP",
"value": "192.168.0.1",
"option": {
"prefix": "192.168"
}
}
{
"type": "cmdb.types.IP",
"value": "172.16.10.1",
"option": {
"prefix": "176.16"
}
}它们是否使用缓存的同一个对象?
差异就在 stringify 方法中,option 中 prefix 不一样。所以,相同 option 的实例创建一个就够了,但是 option 是一个字典,如何解决?
instances_cache = {} # 实例缓存
def get_instance(type: str, **option):
key = ",".join(f"{k}={v}" for k, v in sorted(option.items())) # 先排序避免顺序差异
key = f"{type}|{key}"
instance = instances_cache.get(key)
if instance:
return instance
obj = get_class(type)(**option) # 从这里导入选项
instances_cache[key] = obj
return obj6.2.6、名称简化
cmdb.types.IP 这个名字太长不好记忆,对于用户来说,只需要记住 IP 并填写就行了。
既然想 cmdb.types.IP 或者 IP 都是表达 IP 类,那我们跟前端用户约定好,cmdb.types 是固定要送入的模块。也就是说,使用 IP 这个短名称,也要对应到 IP 这个类。
这还需要建立字典吗?
不需要。因为模块一旦加载创建后,这些类都会放在模块的全局字典中。
为了方便,把这个短名称即类名注入到 classes_cache 这个字典中。长名称也可以同时注入进来。
def inject_classes_cache():
mod = globals().get('__package__')
for k, v in globals().items():
if type(v) == type and k != 'BaseType' and issubclass(v, BaseType):
classes_cache[k] = v
classes_cache[".".join((mod, k))] = v
inject_classes_cache() # 函数调用放在模块最后# 模块加载后,classes_cache 中的内容如下
{'Int': <class 'cmdb.types.Int'>, 'cmdb.types.Int': <class 'cmdb.types.Int'>, 'IP': <class 'cmdb.types.IP'>, 'cmdb.types.IP': <class 'cmdb.types.IP'>}那么,只要模块加载了,classes_cache 就有了长名称、短名称对应的类对象的映射。
如果送入一个类型 cmdb.types.IP,直接查字典就可以了,不需要动态加载模块了。因此,简化 get_class 函数如下:
def get_class(type: str):
# 使用缓存
cls = classes_cache.get(type)
if cls:
return cls
raise TypeError(f'Wrong Type {type}. Not subclass of BaseType.')6.2.7、单值约束
目前,可以认为 value 里面存放的是 一个 值。对这种单一值,可以做一些约束,例如 nullable、unique。
nullable:值是否可以为空。如果设置为 false,则值不可以为空,如果为空抛异常;如果为 true,值可以为空,就直接过。
unique:值是否唯一。如果设置为 false,则不检查值的唯一性;如果设置为 true,则需要检查值的唯一性。
怎么判断唯一?
schema + filed 表构成的虚拟表,entity 表使用同一个 schema_id 就是同一张表的数据。
依照 host 举例,找 ip 是否重复,schema_id=1,ip 对应 field_id=2,在 value 表中管理 schema 表查找所有 entity_id 对应的 schema_id=1 的所有 field_id=2 的 value 字段的数据,且 value='192.168.0.10' 的数据的 count 是否大于 1,大于 1 说明现有的数据重复了,等于 1 说明里面有一条了,等于 0 说明数据库中还没有。
假设准备插入一个 IP 数据进去,如果 count > 0 就不可以插入,说明已经有同样的 IP 被使用过了。
meta 的 json 描述:
{
"type": "cmdb.types.IP",
"value": "192.168.0.1",
"nullable": false,
"unique": false,
"option": {
"prefix": "192.168"
}
}6.2.8、多值约束
需求:一个主机名对应多个 IP 地址,如何描述?
meta 的 json 描述:
{
"type": "cmdb.types.IP",
"value": "192.168.0.1,192.168.0.2",
"nullable": false,
"unique": false,
"option": {
"prefix": "192.168"
},
"multi": true
}某一个主机如果允许绑定多个 ip 地址,有 2 种存储方法:
-
在 value 表的 value 字段上存储
192.168.0.1,192.168.0.2。好处是实现简单,但是,提取修改不方便。
IP 存储顺序发生变化,就成了不同的 IP 值了,无法判断是否重复。
-
使用多条记录存储
在 value 表中使用多条存储,但是有唯一键约束 UNIQUE KEY index4 ( entity_id , field_id )。
2 个 ip 存储就会有 2 个一样的 entity_id 和 field_id,会违反唯一键约束的。需要移除这个唯一键约束。
移除语句:
ALTER TABLE `value` DROP INDEX `index4`;好处是字段容易控制,而且还可以使用 unique 约束来约束某一个 IP 在虚拟表中只能出现一次。
采用第二种方式。注意需要移除唯一键约束。
6.2.9、多值约束设计
multi=false(单值,默认)
提交一个值,值存在就更新;不存在就新增。
举例:一个主机只能记录一个 IP,那么提交上来数据,不存在就增加,存在数据就覆盖。
multi=true(多值)
多值情况较为复杂,需要分析。
-
假设该主机没有记录一个 IP,现在提交了多条。
-
假设该主机已经有 IP 记录,又有 IP 提交,又可以分 3 种情况
-
提交的 IP 都是新的 IP
-
提交的 IP 有些是新的 IP
-
提交的 IP 全是已经存在的 IP
-
怎么办?
我的思路是,思考提交的 IP 代表什么?是原有 IP 的修改,还是用户提交的新 IP?
想象用户看到的界面,上面有好多 IP,用户通过修改 IP 列表,然后提交眼前看到的 IP 列表,也就是说用户提交的才是最新的 IP 列表,原有的列表他不关心了。
所以,不管数据库中当前 IP 列表是什么,不关心,最终只保存用户提交的就行了。
当然,这里面也许有的 IP 当前就在数据库中存着,可以删除,但是删除代价大于更新,所以尽可能的更新。
但是更新,又需要判断哪些 IP 是否在,哪些 IP 不在,麻烦。
因为,相对来说,用户修改 IP 这种事做的少,所以可以有下面的设计。
设计如下:
将这个主机的所有 IP 查回来,条目数为 c1。新提交的 IP 数目为 c2。
如果 c1 == c2,循环迭代,用新 IP 替换所有库中 IP;
如果 c1 < c2,替换 c1 个数据,剩下 c2-c1 个新增。
如果 c1 > c2,替换 c2 个数据,剩下 c1-c2 个删除。
6.2.10、多表关系设计
前面讨论的都是单表之间的关系,如何在这种设计上实现多表关联?
提供 reference 来表示,它要说明它引用了哪一张虚拟表的哪一个字段,即 schema_id 等于几,同时 field_id 等于几。
meta 的 json 描述例子:
{
"type": "cmdb.types.IP",
"value": "192.168.0.1,192.168.0.2",
"nullable": false,
"unique": false,
"option": {
"prefix": "192.168"
},
"multi": true,
"reference": {
"schema": 1,
"field": 1
}
}上面的意思是这个字段引用 schema_id 等于 1 对应的虚拟表的 field_id 为 1 的字段。
例如这个字段是 host 表的 IP 字段,它引用了 ipaddress 表的 IP 字段。
host 表称为 Source 表,ipaddress 表称为 Target 表。
类型一致校验
增加了引用后,需要先查询看看 schema_id 为 1 的表且 field_id 为 1 的字段的 meta 字段里面的 type 定义是否和当前字段定义的一致?如果一致,才能继续。
约束设计
Source 表:
1、新增数据,首先做类型校验,例如是不是 int 类型,是否在取值范围内,可否为空,是否唯一,这些检验做完,再做外键约束。去查 Target 表,看看被引用字段中是否存在当前 Source 表的字段值,如果有,数据可以插入,不存在就抛异常。
2、修改数据,同上,就相当于加入新的值。
3、删除数据,直接删除。
4、查询数据,直接查即可。
Target 表:
1、查询数据,直接查即可。
2、增加数据,新增的数据还没有被引用,直接插入即可。
3、删除数据,可能已经被引用了,所以需要有删除策略。
-
级联删除 cascade
先查询 Host 表中使用这个字段值对应的记录并删除,然后再去删除 ipaddress 表的记录。
举例:
host.ip 和 switch.ip 都引用了 ipaddress.ip。
ipaddress.ip 要删除 192.168.1.10,那么就要去 value 表先删除 host 表、switch 表的引用。
-
置空 set_null
如果 Target 表的主键字段的值删除,那么引用这个值的外键字段都要置 null。
举例:
host.ip 和 switch.ip 都引用了 ipaddress.ip。
ipaddress.ip 要删除 192.168.1.10,那么就要去 value 表先置空 host 表、switch 表的引用。
-
禁用 disable
被引用了就不允许删除。
举例:
host.ip 和 switch.ip 都引用了 ipaddress.ip。
ipaddress.ip 要删除 192.168.1.10,不允许。
4、修改数据
-
级联更新 cascade
和删除类似,不过这里是把 source 表更新成新值。
Target 表更新这个新值要通过检验,Source 表也要通过自己字段的检验,否则抛异常。
-
disable 禁用
如果被引用,就更新失败。
注意这里不用设计 set_null,因为 Target 表字段更新值,Source 表的字段应该和其一致,而不是设置为 null。
Source 表 meta 的 json 描述:
{
"type": "cmdb.types.IP",
"value": "192.168.0.1,192.168.0.2",
"nullable": false,
"unique": false,
"option": {
"prefix": "192.168"
},
"multi": true,
"reference": {
"schema": 1,
"field": 1,
"on_delete": "cascade|set_null|disable",
"on_update": "cascade|disable"
}
}以上设计,都可以转换为当前 MySQL 数据库表的各种 SQL 语句。
多表关联的外键约束设计,非常复杂,代码实现成本非常高,非常难控制。
所以这种设计要少用外键约束,约束还是要用的,但是建议约束在业务层实现,不要放到数据库中实现。
思考:
如果设计了这种外键约束,Target 表主键变动了,首先不知道谁引用了,需要自己代码实现,去遍历 field 表所有记录,从 meta 字段中解析谁引用了这个字段,非常没有效率。
有没有办法提高效率?
可以不可以不遍历?
不遍历是可以的,有 2 种方法:
1、在 Target 表的 meta 字段中记录,谁引用了它。
2、在 field 表中,增加一个字段 reference,如果是 Source 表,它引用 Target 表的字段,则这个 reference 字段一定有值。
使用 SQL 语句:
select * from field where reference = 2;这个 2 指的是 field 表的主键值,也就是说 2 对应一条唯一的记录,这个记录指的是 schema_id=1 的虚拟表的字段 ip 的信息。
用这种方法,就可以是 Target 表快速找到引用自己的 Source 表的字段。
上面 2 种方法都采用了冗余设计的方式,但第二种更佳。
实验语句:
insert into cmdb.`schema`(id, name) values(2, 'ippool');
SELECT
*
FROM
cmdb.`schema`
ORDER BY
id DESC;
insert into field(name, schema_id) values('ip', 2);
SELECT
cmdb.`schema`.id,
cmdb.`schema`.NAME,
field.id AS fid,
field.NAME AS fname,
field.meta
FROM
cmdb.`schema`
INNER JOIN field ON field.schema_id = cmdb.`schema`.id;
-- 表2 ippool
INSERT INTO entity (`key`, schema_id) VALUES('3dea5d2e39eb47b5a5b95cee6fc64f8d', 2);
INSERT INTO entity (`key`, schema_id) VALUES('6bbd0d91e6cf44cba7e71207ddaa06d6', 2);
INSERT INTO entity (`key`, schema_id) VALUES('fc377c758e5a463cb246ff693ab11434', 2);
INSERT INTO `value` (`value`, entity_id, field_id) VALUES('192.168.1.10', 3, 3);
INSERT INTO `value` (`value`, entity_id, field_id) VALUES('192.168.1.20', 4, 3);
INSERT INTO `value` (`value`, entity_id, field_id) VALUES('192.168.1.30', 5, 3);
-- 表1 host
INSERT INTO entity (`key`, schema_id) VALUES ('587723df88a54b2e9f449888d75f50de', 1);
INSERT INTO `value` (`value`, entity_id, field_id) VALUES('DNS Server', 6, 1);
INSERT INTO `value` (`value`, entity_id, field_id) VALUES('172.16.100.1', 6, 2);6.3、DDL 设计
有哪些 DDL 语句?
虚拟表的创建,增、删、改虚拟表的字段。
6.3.1、创建表
没有什么影响。因为是全新的表,没有任何数据和它相关。
6.3.2、增加字段
新增一个字段到表里面,这个字段是新的,还没有任何数据使用这个字段。
只需要考虑要不要为所有记录更新这个字段并设置值。一个新字段,就是能不能为空。
nullable 是否可以为空:
-
如果可以为空,什么都不用做;
-
如果不可以为空,需要在现有虚拟表上遍历所有记录增加值,这个值只能是缺省值。
-
引入 default 来设置缺省值。
-
如果设置了 unique=true,default 的值一定要满足唯一性。
-
如果使用引用,那么此字段是外键,还得考虑此缺省值是否存在于被引用表的主键中。
-
6.3.3、修改字段
修改 name,没有问题,只是一个描述字符串而已。
修改 meta:
-
改 type,要遍历所有虚拟表的该字段数据,拿出来转类型成功后,写回去。操作成本太高了,因此,禁用。
-
nullable
-
从 false 到 true,什么都不做。
-
从 true 到 false,就需要对这个虚拟表的该字段遍历。使用 schema_id 和 field_id 在 value 表中查找 value 字段是否为 null,或者缺失(因为新增字段时,可以为空,就什么都不做)。如果为 null 或者缺失,校验失败
SELECT count(id) from value WHERE field_id=2 and entity_id=3,count 为 0,校验失败。
-
-
unique
-
从 true 到 false,什么都不做。
-
从 false 到 true,如何判断?
使用 field_id 在 value 表中查找 value 字段中 count 的变化
SELECT count(id) from value WHERE field_id=2,SELECT DISTINCT count(value) from value WHERE field_id=2,如果两次 count 结果一样,就是无重复的。注意这种查询太慢了
-
-
multi
-
从 false 到 true,什么都不做。
-
从 true 到 false,需要计算每一个 entity 的 entity_id、field_id 的 count,
SELECT count(id) from value WHERE field_id=2 and entity_id=1,count > 1 说明是多个值,检验失败。
-
-
reference
-
清除引用信息,就是去掉约束,不用校验。而且value字段上的值原来谁就是合法的,所以继续保留。
-
增加引用,就要检验外键的值是否出现在了被引用表的主键上,只要有一个不在,检验失败。
如果检验成功,在 reference 字段上填上外键信息。这些主键、外键值都存储在 value 表中,所以使用自关联。
看下面的
参考1。如果通过自关联左联查出 count 大于 0,就检验失败。 -
-
option 修改,只是数据处理的限制条件,我们这里的约定修改了,将影响以后的数据限制,已经入库的不检验不更新。
参考 1:
-- 使用自连接
SELECT source.*, target.* FROM `value` AS source LEFT JOIN `value` AS target ON source.`value` = target.`value` AND target.field_id = 3 WHERE target.`value` is NULL AND source.field_id = 2
SELECT count(source.id) FROM `value` AS source LEFT JOIN `value` AS target ON source.`value` = target.`value` AND target.field_id = 3 WHERE target.`value` is NULL AND source.field_id = 2
-- 使用左联,从外键所在的source表往主键所在的target表看,不过target表的数据在join时先要过滤一下
target.field_id = 3,也就是field表中id=3的字段被引用了。这样,左联后,如果source表的ip比target表多,
就违反了外键约束,代表source用到的ip不存在target表中。为了过滤出这个多出来的ip,使用了条件
target.`value` is NULL AND source.field_id = 2。6.4、开发
环境准备,继续使用前面项目的构建,使用虚拟环境。
安装依赖:
$ pip install PyMySQL SQLAlchemy webob6.4.1、Model 层
cmdb 包下建立 models.py。
每个表增加 deleted 字段,所有数据都是逻辑删除,因为有可能使用,不要真删除。
from sqlalchemy import Column, Integer, BigInteger, String, Text, Boolean
from sqlalchemy import ForeignKey, UniqueConstraint, create_engine
from sqlalchemy import text
from sqlalchemy.orm import relationship, sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from . import config
Base = declarative_base()
# 逻辑表
class Schema(Base):
__tablename__ = "schema"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(48), nullable=False, unique=True)
desc = Column(String(128), nullable=True)
deleted = Column(Boolean, nullable=False, server_default=text("False"))
fields = relationship('Field')
class Field(Base):
__tablename__ = 'field'
__table_args_ = (UniqueConstraint('schema_id', 'name'),)
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(48), nullable=False)
schema_id = Column(Integer, ForeignKey('schema.id'), nullable=False)
meta = Column(Text, nullable=False)
ref_id = Column(Integer, ForeignKey('field.id'), nullable=True)
deleted = Column(Boolean, nullable=False, server_default=text("False"))
schema = relationship('Schema')
ref = relationship('Field', uselist=False) # 1对1,被引用的id
# 逻辑表的记录表
class Entity(Base):
__tablename__ = 'entity'
id = Column(BigInteger, primary_key=True, autoincrement=True)
key = Column(String(64), nullable=False, unique=True)
schema_id = Column(Integer, ForeignKey('schema.id'), nullable=False)
deleted = Column(Boolean, nullable=False, server_default=text("False"))
schema = relationship('Schema')
class Value(Base):
__tablename__ = "value"
__table_args__ = (UniqueConstraint('entity_id', 'field_id', name='uq_entity_field'),)
id = Column(BigInteger, primary_key=True, autoincrement=True)
value = Column(Text, nullable=False)
field_id = Column(Integer, ForeignKey('field.id'), nullable=False)
entity_id = Column(BigInteger, ForeignKey('entity.id'), nullable=False)
deleted = Column(Boolean, nullable=False, server_default=text("False"))
entity = relationship('Entity')
field = relationship('Field')
# 引擎
engine = create_engine(config.URL, echo=config.DATABASE_DEBUG)
# 创建表
def create_all():
Base.metadata.create_all(engine)
# 删除表
def drop_all():
Base.metadata.drop_all(engine)
Session = sessionmaker(bind=engine)
session = Session()注意:deleted 字段默认值使用的是 default_server=,借助 mysql 服务器存储引擎完成默认值填充,不支持整型和浮点型,借用 text() 函数转换;也可以使用 default=,不过 default 是指通过 sqlalchemy 客户端自动生成指定的值交给 pymysql 驱动去执行 sql,所以需要实例化 Model 表才能实现。
在 cmdb 包下建立 config.py 配置文件:
host = "192.168.136.131"
user = "brinnatt"
password = "WelC0me168!"
port = 3306
database = 'cmdb'
URL = f'mysql+pymysql://{user}:{password}@{host}:{port}/{database}'
DATABASE_DEBUG = True使用 models.py 来 drop 所有表并生成所有表,然后执行下面的实验语句:
-- 表1 虚拟表host,有2个字段hostname、ip
INSERT INTO `schema` (name) VALUES('host');
INSERT INTO `field` (name, schema_id) VALUES ('hostname', 1);
INSERT INTO `field` (name, schema_id) VALUES ('ip', 1);
-- 表2 虚拟表ippool,有1个字段ip
INSERT INTO `schema` (name) VALUES('ippool');
INSERT INTO `field` (name, schema_id) VALUES ('ip', 2);
-- host表添加记录
INSERT INTO entity (`key`, schema_id) VALUES ('5846d1499dd544198475a9d517766494', 1);
INSERT INTO `value`(entity_id, field_id, `value`) VALUES(1, 1, 'webserver');
INSERT INTO `value`(entity_id, field_id, `value`) VALUES(1, 2, '192.168.1.10');
INSERT INTO entity (`key`, schema_id) values ('0f51405a04344f0e9f11109895ab2f19', 1);
INSERT INTO `value`(entity_id, field_id, `value`) VALUES(2, 1, 'DBserver');
INSERT INTO `value`(entity_id, field_id, `value`) VALUES(2, 2, '192.168.1.20');
INSERT INTO entity (`key`, schema_id) VALUES ('587723df88a54b2e9f449888d75f50de', 1);
INSERT INTO `value` (entity_id, field_id, `value`) VALUES(3, 1, 'DNS Server');
INSERT INTO `value` (entity_id, field_id, `value`) VALUES(3, 2, '172.16.100.1');
-- ip表添加记录
INSERT INTO entity (`key`, schema_id) VALUES('3dea5d2e39eb47b5a5b95cee6fc64f8d', 2);
INSERT INTO entity (`key`, schema_id) VALUES('6bbd0d91e6cf44cba7e71207ddaa06d6', 2);
INSERT INTO entity (`key`, schema_id) VALUES('fc377c758e5a463cb246ff693ab11434', 2);
INSERT INTO `value` (entity_id, field_id, `value`) VALUES(4, 3, '192.168.1.10');
INSERT INTO `value` (entity_id, field_id, `value`) VALUES(5, 3, '192.168.1.20');
INSERT INTO `value` (entity_id, field_id, `value`) VALUES(6, 3, '192.168.1.30');
-- 查询
SELECT
`schema`.id AS sid,
`schema`.`name` AS sname,
entity.id AS eid,
entity.`key`,
field.id AS fid,
field.`name` AS fname,
`value`.id,
`value`.`value`
FROM
`value`
INNER JOIN entity ON `value`.entity_id = entity.id AND entity.deleted = FALSE
INNER JOIN `schema` ON entity.schema_id = `schema`.id AND `schema`.deleted = FALSE
INNER JOIN field ON `value`.field_id = field.id AND field.deleted = FALSE
WHERE `value`.deleted = FALSE问题:
schema 中设置了 name 为 unique,但是如果删除一个逻辑表后 deleted=True,加入一个同名的逻辑表名,就会报错。
field 表中使用了 UniqueConstraint('schema_id', 'name'),也一样有这种问题。
解决:
field 表中把 deleted 字段设置为 Integer 类型,多次删除同名时 deleted 计数就加 1,使用 UniqueConstraint('schema_id', 'name', 'deleted') 就可以实现多次删除和使用同名,deleted=0 表示没有删除,即正在使用这个虚拟字段。凡是 deleted 大于 0,表示该虚拟字段已经删除。这时候的 deleted 有点类似于版本号。
6.4.1.1、meta 处理
field 表中 meta 字段,需要对 json 数据进行包装。
这里略作一些改动:
1、把 option 放到 type 中,因为它和 type 类型有关。
2、引用仿照 MySQL,指定表名和字段名。因为字段有可能删除后重新添加同名的字段,id 就变了。
{
"type": {
"name": "cmdb.types.IP",
"option": {
"prefix": "192.168"
}
},
"value": "192.168.0.1,192.168.0.2",
"nullable": true,
"unique": false,
"default": "",
"multi": true,
"reference": {
"schema": "ippool",
"field": "ip",
"on_delete": "cascade|set_null|disable",
"on_update": "cascade|disable"
}
}type 简化写法:
{
"type": "cmdb.types.IP",
"unique": true
}在 models.py 中增加 meta 解析类,并为 Field 提供一个属性:
import json
from .types import get_instance
class Reference:
def __init__(self, ref: dict):
self.schema = ref['schema'] # 引用的schema
self.field = ref['field'] # 引用的field
self.on_delete = ref.get('on_delete', 'disable') # cascade, set_null, disable
self.on_update = ref.get('on_update', 'disable') # cascade, disable
class FieldMeta:
def __init__(self, metastr: str):
meta = json.loads(metastr)
if isinstance(meta['type'], str):
self.instance = get_instance(meta['type'])
else:
option = meta['type'].get('option')
if option:
self.instance = get_instance(meta['type']['name'], **option)
else:
self.instance = get_instance(meta['type']['name'])
self.unique = meta.get('unique', False)
self.nullable = meta.get('nullable', True)
self.default = meta.get('default')
self.multi = meta.get('multi', False)
# 引用是一个json对象
ref = meta.get('reference')
if ref:
self.reference = Reference(ref)
else:
self.reference = None
class Field(Base):
__tablename__ = 'field'
__table_args_ = (UniqueConstraint('schema_id', 'name'),)
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(48), nullable=False)
schema_id = Column(Integer, ForeignKey('schema.id'), nullable=False)
meta = Column(Text, nullable=False)
ref_id = Column(Integer, ForeignKey('field.id'), nullable=True)
deleted = Column(Boolean, nullable=False, server_default=text("False"))
schema = relationship('Schema')
ref = relationship('Field', uselist=False) # 1对1,被引用的id
@property # 增加一个属性将meta解析成对象,注意不要使用metadata这个名字
def meta_data(self):
return FieldMeta(self.meta)6.4.2、Service 层
6.4.2.1、日志
在 app.py 中加入日志配置:
import logging
#logging.basicConfig(level=logging.INFO, format="%(asctime)s [%(name)s %(funcName)s] %(message)s")这是全局设置,影响范围很大。sqlalchemy 也会受影响。所以模块单独设置自己的 logger,就不在 app.py 设置了。
cmdb 包下建立 service 模块,在 __init__.py 中编写:
import logging
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO) # 单独设置
logger.propagate = False # 阻止传送给父logger
handler = logging.FileHandler('D:/test.log')
handler.setLevel(logging.INFO)
formatter = logging.Formatter(fmt="%(asctime)s [%(name)s %(funcName)s] %(message)s")
handler.setFormatter(formatter)
logger.addHandler(handler)由于其他模块也使用,所以封装成函数,放到 cmdb/utils.py:
import logging
def getlogger(mod_name: str, filepath: str):
logger = logging.getLogger(mod_name)
logger.setLevel(logging.INFO) # 单独设置
logger.propagate = False # 阻止传送给父logger
handler = logging.FileHandler(filepath)
handler.setLevel(logging.INFO)
formatter = logging.Formatter(fmt="%(asctime)s [%(name)s %(funcName)s] %(message)s")
handler.setFormatter(formatter)
logger.addHandler(handler)
return logger模块使用:
from ..utils import getlogger
logger = getlogger(__name__, 'o:/{}.log'.format(__name__)) # 路径自行更换6.4.2.2、schema 接口
service 包下建立 schema.py 模块:
from ..models import session, Schema, Field, Entity, Value
import logging
import math
logger = logging.getLogger(__name__)
# schema 接口
# 返回一个 schema 对象
def get_schema_by_name(name: str, deleted: bool = False):
query = session.query(Schema).filter(Schema.name == name.strip())
if not deleted:
query = query.filter(Schema.deleted == False)
return query.first()
# 增加一个 schema
def add_schema(name: str, desc: str = None):
schema = Schema()
schema.name = name.strip()
schema.desc = desc
session.add(schema)
try:
session.commit()
return schema
except Exception as e:
session.rollback()
logger.error('Fail to add a new schema {}. Error: {}'.format(name, e))
# 删除使用id,id唯一,比使用name删除好
def delete_schema(id: int):
try:
schema = session.query(Schema).filter((Schema.id == id) & (Schema.deleted == False))
if schema:
schema.deleted = True
session.add(schema)
try:
session.commit()
return schema
except Exception as e:
session.rollback()
raise e
else:
raise ValueError('Wrong ID {}'.format(id))
except Exception as e:
logger.error('Fail to del a schema. id={}. Error: {}'.format(id, e))
# 列出所有逻辑表
def list_schema(page: int, size: int, deleted: bool = False):
try:
query = session.query(Schema)
if not deleted:
query = query.filter(Schema.deleted == False)
page = page if page > 0 else 1
size = size if 0 < size < 101 else 20
count = query.count()
pages = math.ceil(count / size)
result = query.limit(size).offset(size * (page - 1)).all()
return result, (page, size, count, pages)
except Exception as e:
logger.error()list_schema 方法是列出所有信息,其它信息显示实际上也要用这个通用逻辑,所以,抽出一个函数。
# 列出所有逻辑表
def list_schema(page:int=1, size:int=20, deleted:bool=False):
query = session.query(Schema)
if not deleted:
query = query.filter(Schema.deleted == False)
return paginate(page, size, query)
# 通用分页函数
def paginate(page, size, query):
try:
page = page if page > 0 else 1
size = size if 0 < size < 101 else 20
count = query.count()
pages = math.ceil(count / size)
result = query.limit(size).offset(size * (page - 1)).all()
return result, (page, size, count, pages)
except Exception as e:
logger.error("{}".format(e))6.4.2.3、field 接口
service 包下建立 field.py 模块:
from .schema import get_schema_by_name
from ..models import session, Field, Entity, FieldMeta, Value
import logging
logger = logging.getLogger(__name__)
# field 接口
# 获取字段
def get_field(schema_name, field_name, deleted=False):
schema = get_schema_by_name(schema_name)
if not schema:
raise ValueError(f"{schema_name} is not a Tablename.")
query = session.query(Field).filter((Field.schema_id == schema.id) & (Field.name == field_name))
if not deleted:
query = query.filter(Field.deleted == False)
return query.first()
# 逻辑表是否已经使用
def table_used(schema_id, deleted=False):
query = session.query(Entity).filter(Entity.schema_id == schema_id)
if not deleted:
query = query.filter(Entity.deleted == False)
return query.first() is not None
# 直接添加字段
def _add_field(field: Field):
session.add(field)
try:
session.commit()
return field
except Exception as e:
session.rollback()
logger.error('Failed to add a field {}. Error: {}'.format(field.name, e))
# 2种情况:(1)完全新增,(2)已有表增加字段
def add_field(schema_name, name, meta):
schema = get_schema_by_name(schema_name)
if not schema:
raise ValueError(f'{schema_name} is not a Tablename.')
# 解析meta,from ..models import FieldMeta
meta_data = FieldMeta(meta)
field = Field()
field.name = name.strip()
field.schema_id = schema.id
field.meta = meta # 能解析成功说明符合格式要求
# ref_id 引用
if meta_data.reference:
ref = get_field(meta_data.reference.schema, meta_data.reference.field)
if not ref:
raise TypeError('Wrong Reference {}.{}'.format(
meta_data.reference.schema, meta_data.reference.field
))
field.ref_id = ref.id
# 判断字段是否已经使用
if not table_used(schema.id): # 未使用的逻辑表,直接加字段
return _add_field(field)
# 已使用的逻辑表
if meta_data.nullable: # 可以为空,直接加字段
return _add_field(field)
# 到这里已经有一个隐含条件即不可为空
if meta_data.unique: # 必须唯一
# 当前的条件是 对一个正在使用的逻辑表加字段不可以为空又要唯一,做不到
raise TypeError('This field is required an unique.')
# 到这里的隐含条件是,不可以为空,但可以不唯一
if not meta_data.default: # 没有缺省值
raise TypeError('This field requires a default value.')
else:
# 为逻辑表所有记录增加字段,操作entity表
entities = session.query(Entity).filter((Entity.schema_id == schema.id) & (Entity.deleted == False)).all()
for entity in entities: # value表新增记录
value = Value()
value.entity_id = entity.id
value.field = field
value.value = meta_data.default
session.add(value)
return _add_field(field)上面的代码中,最后一个遍历 entity 表,可以考虑使用生成器:
def add_field(schema_name, name, meta):
# ...... 省略
# 到这里的隐含条件时,不可以为空,但可以不唯一
if not meta_data.default: # 没有缺省值
raise TypeError('This field requires a default value.')
else:
# 为逻辑表所有记录增加字段,操作entity表
for entity in iter_entities(schema.id): # value表新增记录
value = Value()
value.entity_id = entity.id
value.field = field
value.value = meta_data.default
session.add(value)
return _add_field(field)
def iter_entities(schema_id, patch=100):
page = 1
while True:
query = session.query(Entity).filter((Entity.schema_id == schema_id) & (Entity.deleted == False))
result = query.limit(patch).offset((page - 1) * patch).all()
if not result:
return None
yield from result
page += 1说明:
可以看到增加字段已经非常繁琐了,修改字段也是一样。
生产环境中,对已经使用的逻辑表,除非万不得已,否则不要增加和修改字段。
到目前为止,代码已经基本说明如何实现这个 cmdb 库了。剩下的按照设计完成即可。