
4、Python3 爬虫工具
很多网站都采用 AJAX 技术、SPA 技术,部分内容都是异步动态加载的。可以提高用户体验,减少不必要的流量,方便 CDN 加速等。
但是,对于爬虫程序来说,爬取到的 HTML 页面只是一个模板,动态内容不在其中。
解决办法之一,如果能构造一个包含 JS 引擎的浏览器,让它加载网页并和网站交互,我们编程从这个浏览器获取内容,包括动态内容。这个浏览器不需要和用户交互的界面,只要能支持 HTTP、HTTPS 协议和服务器端交互,能解析 HTML、CSS、JS 就可以了。
4.1、ChromeDriver
它是一个 headless 无头浏览器,支持 Javascript。可以运行在 Windows、Linux、Mac OS 等。
所谓无头浏览器,就是包含 Js 引擎、浏览器排版引擎等核心组件,但是没有和用户交互的界面。
官网:https://chromedriver.chromium.org/
从导航菜单栏点击 Downloads 下载对应版本,解压缩就可以使用,这种用法适用于 selenium 3.x。
selenium 4.6+ 以后的版本需要在代码中配置自动下载对应版本的 ChromeDriver,老实说官网的用例思路很不适用,请做必要实验摸索。
以下实验使用 selenium v4.11.2 操作。
4.2、Selenium
它是一个 WEB 自动化测试工具。它可以直接运行在浏览器中,支持主流的浏览器,包括 ChromeDriver (无界面浏览器)。
官网:https://www.seleniumhq.org/
# 安装
pip install selenium不同浏览器都会提供操作的接口,Selenium 就是使用这些接口来操作浏览器。
Selenium 最核心的对象就是 webdriver,通过它就可以操作浏览器、截图、HTTP 访问、解析 HTML 等。
4.2.1、处理异步请求
bing 的查询结果是通过异步请求返回结果,所以,直接访问页面不能直接获取到搜索结果。
# 获取bing查询数据
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
import datetime
import random
import time
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.set_window_size(1280, 2400)
# 打开网页GET方法,模拟浏览器地址栏输入网址
url = "http://cn.bing.com/search?q=brinnatt"
driver.get(url)
# 保存图片
def save_pic():
base_dir = './'
filename = "{}{:%Y%m%d%H%M%S}{:03}.png".format(base_dir, datetime.datetime.now(),
random.randint(1, 100))
driver.save_screenshot(filename)
save_pic() # 是否看到查询结果?
time.sleep(5)
save_pic()
driver.close()webdriver_manager 是一个用于管理 WebDriver(例如 ChromeDriver)的工具库,它的作用是自动下载和管理适用于特定浏览器版本的 WebDriver。
WebDriver 是一个用于自动化浏览器操作的工具,它使得你可以通过编程的方式控制浏览器执行各种操作,例如打开网页、点击按钮、填写表单等。
注意:webdriver_manager 会自动探测本地浏览器版本以便下载适当的 WebDriver 版本,避免兼容性问题和功能限制。所以如果本地浏览器版本过低,会存在自动下载失败的风险,最好更新本地浏览器。本实验使用 ChromeDriver,我已将本地 Chrome 更新到最新。
4.2.2、下拉框处理
Selenium 专门提供了 Select 类来处理网页中的下拉框,虽然现在很少有人用 Select 下拉框,不排除老网站还在使用,学习操作方法。本次使用 https://getbootstrap.com/docs/5.0/forms/select/
<select class="form-select" aria-label="Default select example">
<option selected>Open this select menu</option>
<option value="1">One</option>
<option value="2">Two</option>
<option value="3">Three</option>
</select># 下拉框操作
import time
from selenium import webdriver # 核心对象
import datetime
import random
from selenium.webdriver.support.ui import Select
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.set_window_size(1280, 2400) # 设置窗口大小
# 保存图片
def save_pic():
base_dir = './'
filename = f"{base_dir}{datetime.datetime.now():%Y%m%d%H%M%S}{random.randint(1, 100):03}.png"
driver.save_screenshot(filename)
# 打开网页GET方法,模拟浏览器地址栏输入网址
url = 'https://getbootstrap.com/docs/5.0/forms/select/'
driver.get(url)
# 获取select
ele = driver.find_element(By.CLASS_NAME, "form-select") # 获取元素
print(ele.tag_name)
print(driver.current_url)
save_pic()
s = Select(ele)
s.select_by_index(2) # 选择Two,触发新事件(这个例子没有新事件,找不到这种网站了)
print(driver.current_url) # 新事件地址
save_pic()
driver.close()4.2.3、模拟键盘操作(模拟登录)
webdriver 提供了一系列 find 方法,让用户获取一个网页中的元素。元素对象可以使用 send_keys 模拟键盘输入。
oschina 的登录页,登录成功后会跳转到首页,首页右上角会显示会员信息,如果未登录,无此信息。
# 下拉框操作
from selenium import webdriver # 核心对象
import datetime
import random
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.common.keys import Keys
# 保存图片
def save_pic():
base_dir = './'
filename = f"{base_dir}{datetime.datetime.now():%Y%m%d%H%M%S}{random.randint(1, 100):03}.png"
driver.save_screenshot(filename)
# 创建一个浏览器实例
driver = webdriver.Chrome()
# 打开网页GET方法,模拟浏览器地址栏输入网址
driver.get("https://www.oschina.net/home/login")
# 设置窗口大小
driver.set_window_size(1280, 2400)
try:
# 等待密码登录按钮出现并点击
password_login_button = WebDriverWait(driver, 3).until(
expected_conditions.element_to_be_clickable((By.XPATH, "//div[text()='密码登录']"))
)
password_login_button.click()
# 在这里您可以继续填写用户名、密码等登录信息
# 模拟键盘输入
username = driver.find_element(By.NAME, 'username')
username.send_keys('brinnatt@gmail.com')
pwd = driver.find_element(By.NAME, 'password')
pwd.send_keys('WelC0me168!')
save_pic()
# 模拟回车
pwd.send_keys(Keys.ENTER)
# 直到找到某个元素
element = WebDriverWait(driver, 3).until(lambda x: x.find_element(By.ID, "userSidebar"))
save_pic()
except Exception as e:
print(e)
finally:
# 关闭浏览器
cookies = driver.get_cookie('oscid') # 获取长期登陆的cookie
print(cookies)
driver.close()4.2.4、页面等待
越来越多的页面使用 Ajax 这样的异步加载技术,这就会导致代码中要访问的页面元素,还没有被加载就被访问了,抛出异常。
4.2.4.1、线程休眠
使用 time.sleep(n) 来等待数据加载。
配合循环一直等到数据被加载完成,可以解决很多页面动态加载或加载慢的问题。当然可以设置一个最大重试次数,以免一直循环下去。
4.2.4.2、Selenium 等待
官网:https://www.selenium.dev/documentation/webdriver/waits/
Selenium 的等待分为显示等待和隐式等待。
-
隐式等待,等待特定的时间;
-
显式等待,指定一个条件,一直等到这个条件成立后继续执行,也可以设置超时时间,超时会抛异常。
显式等待
| expected_conditionsn 内置条件 | 说明 |
|---|---|
| title_is | 判断当前页面的title是否精确等于预期。 |
| title_contains | 判断当前页面的title是否包含预期字符串。 |
| presence_of_element_located | 判断某个元素是否被加到了dom树中,并不代表该元素一定可见。 |
| visibility_of_element_located | 判断某个元素是否可见,可见代表元素非隐藏,并且元素的宽和高都不等于 0。 |
| visibility_of | 跟上面的方法做一样的事情,只是上面的方法要传入 locator,这个方法直接传定位到的 element 就好了。 |
| presence_of_all_elements_located | 判断是否至少有1个元素存在于dom树中。 举个例子,如果页面上有n个元素的class都是 column-md-3,那么只要有1个元素存在,这个方法就返回True。 |
| text_to_be_present_in_element | 判断某个元素中的text是否包含了预期的字符串。 |
| text_to_be_present_in_element_value | 判断某个元素中的value属性是否包含了预期的字符串。 |
| frame_to_be_available_and_switch_to_it | 判断该frame是否可以switch进去,如果可以的话,返回True并且switch进去,否则返回False。 |
| invisibility_of_element_located | 判断某个元素是否不存在于dom树或不可见。 |
| element_to_be_clickable | 判断某个元素是否可见并且是enable的,这样的话才叫clickable。 |
| staleness_of | 等某个元素从dom树中移除,注意,这个方法也是返回True或False。 |
| element_to_be_selected | 判断某个元素是否被选中了,一般用在下拉列表。 |
| element_selection_state_to_be | 判断某个元素的选中状态是否符合预期。 |
| element_located_selection_state_to_be | 跟上面的方法作用一样,只是上面的方法传入定位到的element,而这个方法传入locator。 |
| alert_is_present | 判断页面上是否存在alert。 |
# 定位搜索框,搜索电影
import datetime
import random
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as ec
from selenium.webdriver.support.wait import WebDriverWait
driver = webdriver.Chrome()
driver.set_window_size(1280, 2400) # 设置窗口大小
driver.get("https://movie.douban.com/") # 打开网页GET方法,模拟浏览器地址栏输入网址
# 保存图片
def save_pic():
base_dir = './'
filename = f"{base_dir}{datetime.datetime.now():%Y%m%d%H%M%S}{random.randint(1, 100):03}.png"
driver.save_screenshot(filename)
try:
# 元素是否已经加载到了dom树中
# 使用哪个driver,等到什么条件ok,ec就是等待的条件
ele = WebDriverWait(driver, 20).until(ec.presence_of_element_located((By.XPATH, '//input[@id="inp-query"]')))
ele.send_keys('TRON')
ele.send_keys(Keys.ENTER)
save_pic()
except Exception as e:
print(e)
finally:
driver.close()默认的查看频率是 0.5 秒每次,当元素存在则立即返回这个元素。
隐式等待
如果出现 No Such Element Exception,则等待指定的时长。缺省值是 0。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
print(1,'waiting?')
driver.implicitly_wait(10) # 增加这一句,全局设置,会导致下面找元素等待10秒
driver.get("https://movie.douban.com/")
print(2,'waiting?')
try:
print('begin~~~~~~~~~~~~~~~~')
ele = driver.find_element(By.ID, 'abcd')
except Exception as e:
print(type(e)) # <class 'selenium.common.exceptions.NoSuchElementException'>
print(e, '~~~~~~~~~~~~~~~~~')
finally:
driver.quit()4.2.5、小结
Selenium 的 WebDriver 是其核心,从 Selenium2 开始就是最重要的编程核心对象,在 Selenium3+ 中更是如此。
与浏览器交互全靠它,它可以:
- 打开 URL,可以跟踪跳转,可以返回当前页面的实际 URL。
- 获取页面的 title。
- 处理 cookie。
- 控制浏览器的操作,例如前进、后退、刷新、关闭,最大化等。
- 执行 JS 脚本。
- 在 DOM 中搜索页面元素 Web Element,支持 find 系方法。
- 操作网页元素
- 模拟下拉框操作 Select(element)。
- 在元素上模拟鼠标操作 click()。
- 在元素上模拟键盘输入 send_keys()。
- 获取元素文字 text。
- 获取元素的属性 get_attribute()。
Selenium 通过 WebDriver 来驱动浏览器工作,而浏览器是一个个独立的浏览器进程。
4.3、Scrapy 框架
Scrapy 是用 Python 实现的一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘、信息处理或存储历史数据等一系列的程序中。
Scrapy 使用 Twisted 高效异步网络框架来处理网络通信,可以加快下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
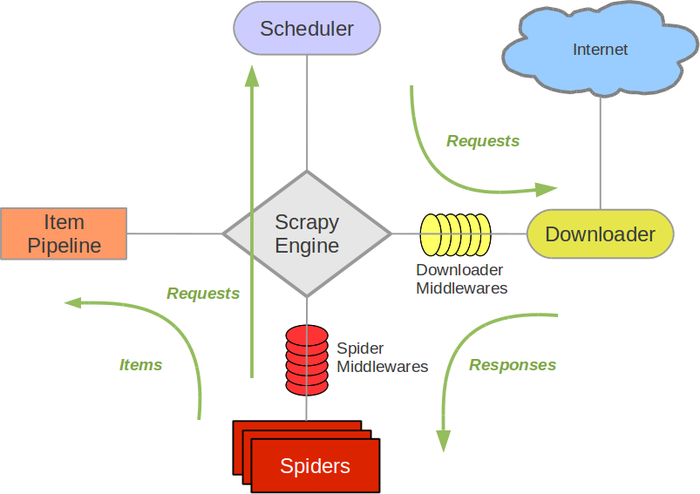
Scrapy Engine
引擎,负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。此组件相当于爬虫的“大脑”,是整个爬虫的调度中心。
调度器(Scheduler)
调度器接收从引擎发送过来的 request,并将他们入队,以便之后引擎请求他们时提供给引擎。
初始要爬取的 URL 和后续在页面中获取待爬取的 URL 将放入调度器中,等待爬取。同时调度器会自动去除重复的 URL(如果特定的 URL 不需要去重也可以通过设置实现,如 post 请求的 URL)。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给 spider。
Spiders 爬虫
Spider 是编写的类,作用如下:
-
分析 responses 并提取 items;
-
跟进额外的 URL,将 URL 提交给引擎,加入到 Scheduler 调度器中;
-
每个 spider 负责处理一个特定或一些网站。
Item Pipeline
Item Pipeline 负责处理被 spider 提取出来的 item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
爬虫解析页面把数据存入 Item 后,会发送到项目管道(Pipeline),并经过设置好次序的 pipeline 程序处理,最后将所需数据存入本地文件或数据库中。
以下是 item pipeline 的一些典型应用:
- 清理 HTML 数据。
- 验证爬取的数据(检查 item 包含某些字段)。
- 查重(或丢弃)。
- 将爬取结果保存到数据库中。
下载器中间件(Downloader middlewares)
简单讲就是扩展下载功能的组件。
下载器中间件,是引擎和下载器之间的特定钩子(specific hook),处理它们之间的请求 request 和响应 response。 它提供了一个简便的机制,通过插入自定义代码来扩展 Scrapy 功能。
通过设置下载器中间件可以实现爬虫自动更换 user-agent、IP 等功能。
Spider 中间件(Spider middlewares)
Spider 中间件,是引擎和 Spider 之间的特定钩子(specific hook),处理 spider 的输入(response) 和输出(items 或 requests)。也提供了同样的简便机制,通过插入自定义代码来扩展 Scrapy 功能。
4.3.1、数据流(Data flow)
-
引擎打开一个网站(open a domain),找到处理该网站的 Spider 并向该 spider 请求第一个(批)要爬取的 URL(s);
-
引擎从 Spider 中获取到第一个要爬取的 URL 并加入到调度器(Scheduler),作为请求以备调度;
-
引擎向调度器请求下一个要爬取的 URL;
-
调度器返回下一个要爬取的 URL 给引擎,引擎让 URL 通过下载中间件后转发给下载器(Downloader);
-
一旦页面下载完毕,下载器生成一个该页面的 Response,并让其通过下载中间件发送给引擎;
-
引擎从下载器中接收到 Response,然后通过 Spider 中间件发送给 Spider 处理;
-
Spider 处理 Response 并返回提取到的 Item 及跟进的新 Request 给引擎;
-
引擎将 Spider 返回的 Item 交给 Item Pipeline,将 Spider 返回的 Request 交给调度器;
-
重复执行(从第二步),直到调度器中没有待处理的 request,引擎关闭。
注意:只有当调度器中没有任何 request 了,整个程序才会停止执行。如果有下载失败的 URL,会重新下载。
4.3.2、安装 Scrapy
在 windows 全局环境下做一个实验,梳理 scrapy 工作流程。注意,项目上要用虚拟环境生产。
$ pip install scrapy我这里使用的是 python v3.10.10 最新版本,直接使用该命令就可以完成,但是老版本的 python v3.5 v3.6 在 windows 上安装 scrapy 会出现以下问题。
# windows下出现如下问题
copying src\twisted\words\xish\xpathparser.g -> build\lib.win-amd64-3.5\twisted\words\xish
running build_ext
building 'twisted.test.raiser' extension
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
解决方案是,下载编译好的 twisted,http://mirrors.aliyun.com/pypi/simple/twisted/
python3.5 下载 Twisted-18.4.0-cp35-cp35m-win_amd64.whl
python3.6 下载 Twisted-18.4.0-cp36-cp36m-win_amd64.whl
安装twisted
$ pip install Twisted-18.4.0-cp35-cp35m-win_amd64.whl
之后再安装scrapy就没有什么问题了安装好,使用 scrapy 命令看看:
(venv) PS C:\Users\Brinnatt\PycharmProjects\pythonProject> scrapy.exe
Scrapy 2.10.0 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command4.3.3、Scrapy 开发
项目编写流程
-
创建项目
使用 scrapy startproject proname 创建一个 scrapy 项目。
-
编写爬虫
编写 spiders/proname_spider.py,即 spider 爬取网站并提取出 item。
-
编写 item
在 items.py 中编写 Item 类,明确从 response 中提取的 item。
-
编写 item pipeline
对 item 进行处理,可以存储。
4.3.3.1、创建项目
豆瓣书评爬取:
标签为“编程”,第一页、第二页链接
https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start=0&type=T
https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start=20&type=T随便找一个目录来创建项目,执行下面命令:
$ scrapy startproject first会产生如下目录和文件:
first
├─ scrapy.cfg
└─ first
├─ items.py
├─ middlewares.py
├─ pipelines.py
├─ settings.py
├─ __init__.py
└─ spiders
└─ __init__.py
first:外部的first目录是整个项目目录,内部的first目录是整个项目的全局目录
scrapy.cfg:重要的项目配置文件
first 项目目录
__init__.py 必须有,包文件
item.py 定义Item类,从scrapy.Item继承,里面定义scrapy.Field类
pipelines.py 重要的是process_item()方法
settings.py:
BOT_NAME 爬虫名
ROBOTSTXT_OBEY = True 是否遵从robots协议
USER_AGENT = '' 指定爬取时使用
CONCURRENT_REQEUST = 16 默认16个并行
DOWNLOAD_DELAY = 3 下载延时
COOKIES_ENABLED = False 缺省是启用,一般需要登录时才需要开启cookie
DEFAULT_REQUEST_HEADERS = {} 默认请求头,需要时填写
SPIDER_MIDDLEWARES 爬虫中间件
DOWNLOADER_MIDDLEWARES 下载中间件
'first.middlewares.FirstDownloaderMiddleware': 543 数字越小优化级越高
ITEM_PIPELINES 管道配置
'firstscrapy.pipelines.FirstscrapyPipeline': 300 item交给哪一个管道处理,数字越小优化级越高
spiders 目录
__init__.py 必须有,可以在这里写爬虫类,也可以写爬虫子模块# first/settings.py参考
BOT_NAME = 'first'
SPIDER_MODULES = ['first.spiders']
NEWSPIDER_MODULE = 'first.spiders'
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36"
ROBOTSTXT_OBEY = False
# Disable cookies (enabled by default)
COOKIES_ENABLED = False注意:一定要更改 User-Agent,否则访问 https://book.douban.com/ 会返回 403。
4.3.3.2、编写爬虫
在 spiders 目录下创建一个叫 book.py 的文件,为爬取豆瓣书评编写爬虫类。
编写的爬虫类需要继承自 scrapy.Spider,在这个类中定义爬虫名、爬取范围、起始地址等。
在 scrapy.Spider 中 parse 方法未实现,所以子类应该实现 parse 方法。该方法传入 response 对象。
# scrapy源码中
class Spider():
def parse(self, response):
raise NotImplementedError爬取读书频道,爬取 tag 为“编程”的书名和评分。
https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start=20&type=T
# spiders/book.py
import scrapy
class BookSpider(scrapy.Spider):
name = 'doubanbook' # 爬虫名
allowed_domains = ['douban.com'] # 爬虫爬取范围
url = 'https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start=0&type=T'
start_urls = [url] # 起始URL
# 下载器获取了WEB Server的response就行了,parse就是解析响应的内容
def parse(self, response):
print(type(response)) # scrapy.http.response.html.HtmlResponse
print('-' * 30)
print(response)以上模板代码可以使用 $ scrapy genspider -t basic book douban.com 创建,注意,先要进入项目根目录,模板代码才会在 spiders 目录下自动生成。
进入项目根目录,使用 crawl 爬取子命令:
$ scrapy list
$ scrapy crawl -h
scrapy crawl [options] <spider>
# 指定爬虫名称开始爬取
$ scrapy crawl doubanbookresponse 是服务器端 HTTP 响应,它是 scrapy.http.response.html.HtmlResponse 类。由此,修改代码如下:
# spiders/book.py
import scrapy
from scrapy.http.response.html import HtmlResponse
class BookSpider(scrapy.Spider):
name = 'doubanbook' # 爬虫名
allowed_domains = ['douban.com'] # 爬虫爬取范围
url = 'https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start=0&type=T'
start_urls = [url] # 起始URL
# 下载器获取了WEB Server的response就行了,parse就是解析响应的内容
def parse(self, response: HtmlResponse):
print(type(response)) # scrapy.http.response.html.HtmlResponse
print('-' * 30)
print(type(response.text), type(response.body))
print('-' * 30)
print(response.encoding)
with open('I:/testbook.html', 'w', encoding='utf-8') as f:
try:
f.write(response.text)
f.flush()
except Exception as e:
print(e)4.3.3.2.1、解析 HTML
爬虫获得的内容 response 对象,可以使用解析库来解析。scrapy 包装了 lxml,父类 TextResponse 类也提供了 xpath 方法和 css 方法,可以混合使用这两套接口解析 HTML。
# 项目根目录下创建一个测试文件test.py
from scrapy.http.response.html import HtmlResponse
# 手动构造response,没有实际请求,是个空对象
response = HtmlResponse('file://I:/testbook.html', encoding='utf-8')
with open('I:/testbook.html', encoding='utf-8') as f:
response._set_body(f.read()) # 把内容塞到response对象里面去
# print(response.text)
# 获取所有标题及评分
# xpath解析
subjects = response.xpath('//li[@class="subject-item"]')
for subject in subjects:
title = subject.xpath('.//h2/a/text()').extract() # list
print(title[0].strip())
rate = subject.xpath('.//span[@class="rating_nums"]/text()').extract()
print(rate[0].strip())
print('-' * 30)
# css解析
subjects = response.css('li.subject-item')
for subject in subjects:
title = subject.css('h2 a::text').extract()
print(title[0].strip())
rate = subject.css('span.rating_nums::text').extract()
print(rate[0].strip())
print('-' * 30)
# xpath和css混合使用、正则表达式匹配
subjects = response.css('li.subject-item')
for subject in subjects:
# 提取链接
href = subject.xpath('.//h2').css('a::attr(href)').extract()
print(href[0])
# 使用正则表达式
id = subject.xpath('.//h2/a/@href').re(r'\d*99\d*')
if id:
print(id[0])
# 要求显示9分以上数据
rate = subject.xpath('.//span[@class="rating_nums"]/text()').re(r'^9.*')
# rate = subject.css('span.rating_nums::text').re(r'^9\..*')
if rate:
print(rate)4.3.3.2.2、Item 封装数据
# spiders/book.py
import scrapy
from scrapy.http.response.html import HtmlResponse
from ..items import BookItem
class BookSpider(scrapy.Spider):
name = 'doubanbook' # 爬虫名
allowed_domains = ['douban.com'] # 爬虫爬取范围
url = 'https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start=0&type=T'
start_urls = [url] # 起始URL
# 下载器获取了WEB Server的response就行了,parse就是解析响应的内容
def parse(self, response: HtmlResponse):
items = []
# xpath解析
subjects = response.xpath('//li[@class="subject-item"]')
for subject in subjects:
title = subject.xpath('.//h2/a/text()').extract()
rate = subject.xpath('.//span[@class="rating_nums"]/text()').extract_first()
item = BookItem()
item['title'] = title[0].strip()
item['rate'] = rate.strip()
items.append(item)
print('-->', items)
return items
# 使用命令保存return的数据
# scrapy crawl -h
# --output=FILE, -o FILE dump scraped items into FILE (use - for stdout)
# 文件扩展名支持'json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle'
# scrapy crawl doubanbook -o dbbooks.json得到的 json 数据如下:
[
{"title": "Python工匠", "rate": "8.9"},
{"title": "Effective C++", "rate": "9.5"},
{"title": "代码大全2(纪念版)", "rate": "9.3"},
{"title": "Programming Rust, 2nd Edition", "rate": "9.8"},
{"title": "程序员修炼之道(第2版)", "rate": "9.1"},
{"title": "算法(第4版)", "rate": "9.4"},
{"title": "JavaScript高级程序设计(第3版)", "rate": "9.2"},
{"title": "On Java 中文版 基础卷", "rate": "9.0"},
{"title": "C++ Primer 中文版(第 5 版)", "rate": "9.4"},
{"title": "代码整洁之道", "rate": "8.7"},
{"title": "C++并发编程实战(第2版)", "rate": "9.5"},
{"title": "Python编程", "rate": "9.2"},
{"title": "C Primer Plus(第6版)中文版", "rate": "9.5"},
{"title": "Go语言设计与实现", "rate": "8.7"},
{"title": "C程序设计语言(第2版·新版)", "rate": "9.4"},
{"title": "流畅的Python(第2版)", "rate": "8.2"},
{"title": "代码大全(第2版)", "rate": "9.3"},
{"title": "程序员数学", "rate": "9.2"},
{"title": "Python编程(第3版)", "rate": "9.6"},
{"title": "编译原理", "rate": "9.0"}
]4.3.3.3、编写 Item
在 items.py 中编写:
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field() # 书名
rate = scrapy.Field() # 评分4.3.3.4、Pipeline 处理
将 book.py 中 BookSpider 改成生成器,只需要把 return items 改造成 yield item。
脚手架帮我们创建了一个 pipelines.py 文件和一个类。
4.3.3.4.1、开启 Pipeline
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
"first.pipelines.FirstPipeline": 300,
}整数 300 表示优先级,越小越高。取值范围为 0-1000。
4.3.3.4.2、常用方法
| 名称 | 参数 | |
|---|---|---|
process_item(self, item, spider) |
item,爬取的一个个数据; spider,item 的爬取者; 每一个 item 的处理都会调用; 返回一个 Item 对象,或抛出 DropItem 异常; 被丢弃的 Item 对象将不会被之后的 pipeline 组件处理。 |
必须 |
open_spider(self, spider) |
spider,表示被开启的 spider; 调用一次。 |
可选 |
close_spider(self, spider) |
spider,表示被关闭的 spider; 调用一次。 |
可选 |
__init__(self) |
spider 实例创建时调用一次。 | 可选 |
# 常用方法
class FirstPipeline(object):
def __init__(self): # 全局设置
print('~~~~~~~~~~ init ~~~~~~~~~~~~')
def open_spider(self, spider): # 当某spider开启时调用
print(spider, '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~')
def process_item(self, item, spider):
# item 获取的item;spider 获取该item的spider
return item
def close_spider(self, spider): # 当某spider关闭时调用
print(spider, '========================================')需求:通过 pipeline 将爬取的数据存入 json 文件中。
# spiders/book.py
import scrapy
from scrapy.http.response.html import HtmlResponse
from ..items import BookItem
class BookSpider(scrapy.Spider):
name = 'doubanbook' # 爬虫名
allowed_domains = ['douban.com'] # 爬虫爬取范围
url = 'https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start=0&type=T'
start_urls = [url] # 起始URL
# spider上自定义配置信息
custom_settings = {
'filename': 'I:/books.json'
}
# 下载器获取了WEB Server的response就行了,parse就是解析响应的内容
def parse(self, response: HtmlResponse):
# items = []
# xpath解析
subjects = response.xpath('//li[@class="subject-item"]')
for subject in subjects:
title = subject.xpath('.//h2/a/text()').extract()
rate = subject.xpath('.//span[@class="rating_nums"]/text()').extract_first()
item = BookItem()
item['title'] = title[0].strip()
item['rate'] = rate.strip()
# items.append(item)
yield item
# pipelines.py
import json
class FirstPipeline(object):
def __init__(self): # 全局设置
print('~~~~~~~~~~ init ~~~~~~~~~~~~')
def open_spider(self, spider): # 当某spider开启时调用
print(1, '-->', spider)
print(1.1, '-->', spider.settings.get('filename'))
self.file = open(spider.settings['filename'], 'w', encoding='utf-8')
self.file.write('[\n')
def process_item(self, item, spider):
# item,传过来的item;spider,传递item的spider
self.file.write(json.dumps(dict(item)) + ',\n')
return item
def close_spider(self, spider): # 当某spider关闭时调用
self.file.write(']')
self.file.close()
print(2, '-->', spider)
print('-' * 30)4.4、爬取豆瓣读书项目
4.4.1、需求
爬取豆瓣读书,并提取后续链接加入待爬取队列。
4.4.2、链接分析
第一页 https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start=0&type=T
第二页 https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start=20&type=Tstart 的值一直在变化。
4.4.3、项目开发
4.4.3.1、创建项目
(venv) PS C:\Users\Brinnatt\PycharmProjects\pythonProject> scrapy startproject spiderman .
New Scrapy project 'spiderman', using template directory 'C:\Users\Brinnatt\PycharmProjects\pythonProject\v
env\Lib\site-packages\scrapy\templates\project', created in:
C:\Users\Brinnatt\PycharmProjects\pythonProject
You can start your first spider with:
cd .
scrapy genspider example example.com4.4.3.2、配置 settings.py
BOT_NAME = "spiderman"
SPIDER_MODULES = ["spiderman.spiders"]
NEWSPIDER_MODULE = "spiderman.spiders"
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36"
ROBOTSTXT_OBEY = False
COOKIES_ENABLED = False4.4.3.3、创建爬虫
scrapy genspider [-t template] <name> <domain>
模板:-t 模板,这个选项可以使用一个模板来创建爬虫类,常用模板有 basic、crawl。
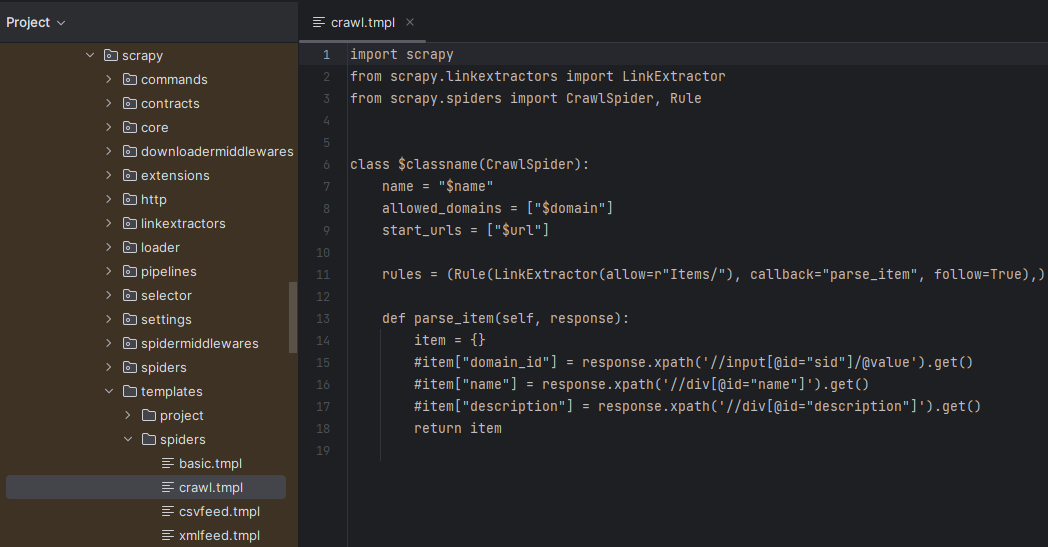
进入 spiderman 项目根目录,使用模板创建爬虫 scrapy genspider -t crawl book douban.com,得到如下代码:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class BookSpider(CrawlSpider):
name = "book"
allowed_domains = ["douban.com"]
start_urls = ["https://douban.com"]
rules = (Rule(LinkExtractor(allow=r"Items/"), callback="parse_item", follow=True),)
def parse_item(self, response):
item = {}
#item["domain_id"] = response.xpath('//input[@id="sid"]/@value').get()
#item["name"] = response.xpath('//div[@id="name"]').get()
#item["description"] = response.xpath('//div[@id="description"]').get()
return itemscrapy.spiders.crawl.CrawlSpider 是 scrapy.spiders.Spider 的子类,增强了功能。在其中可以使用 LinkExtractor、Rule。
规则 Rule 定义:
-
rules 元组里面定义多条规则 Rule,用规则来方便地跟进链接。
-
LinkExtractor 从 response 中提取链接。
- allow 需要一个对象或可迭代对象,其中配置正则表达式,表示匹配什么链接,即只关心
<a>标签。
- allow 需要一个对象或可迭代对象,其中配置正则表达式,表示匹配什么链接,即只关心
-
callback 定义匹配链接后执行的回调,特别注意不要使用 parse 这个名称。返回一个包含 Item 或 Request 对象的列表。
- 参考
scrapy.spiders.crawl.CrawlSpider#_parse_response。
- 参考
-
follow 是否跟进链接。
由此得到一个本例程的规则,如下:
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy.http.response.html import HtmlResponse
from ..items import BookItem
class BookSpider(CrawlSpider):
name = "book"
allowed_domains = ["douban.com"]
start_urls = ['https://book.douban.com/tag/%E7%BC%96%E7%A8%8B']
rules = (
Rule(LinkExtractor(allow=r"start=\d+"), callback="parse_pagination", follow=False),
) # follow为False将不跟进
def parse_pagination(self, response: HtmlResponse):
print(response.url) # scrapy crawl book > u.txt
for subject in response.xpath('//li[@class="subject-item"]'):
item = BookItem()
item['title'] = subject.xpath('.//h2/a/text()')[0].extract().strip()
rate = subject.xpath('.//span[@class="rating_nums"]/text()').extract()
if rate:
item['rate'] = rate[0]
else:
item['rate'] = '0'
yield item上面的代码,爬虫在运行时,会分析页面内的链接,提取到匹配链接就会执行回调函数 parse_pagination。回调中 response 就是提取到的链接请求返回的 HTML 页面,直接对这个 HTML 页面使用 xpath 或 css 分析即可。
4.4.3.4、编写 item
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field() # 书名
rate = scrapy.Field() # 分数
def __repr__(self):
return '<{} {}>'.format(self.__class__.__name__, dict(self))执行 scrapy crawl book,开始爬取。将 follow 改为 True 试一试。
4.4.3.5、代理
在爬取过程中,豆瓣使用了反爬策略,可能会出现以下现象:
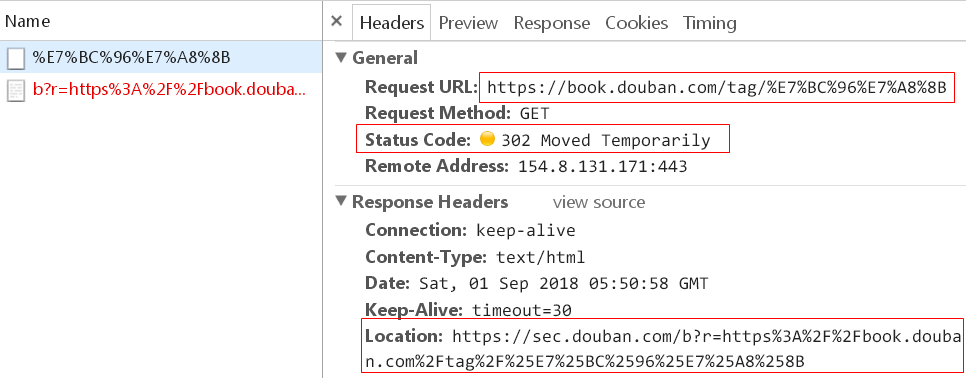
这相当于封了 IP,所以,可以在爬取时使用代理来解决。
思路:在发起 HTTP 请求之前,会经过下载中间件,自定义一个下载中间件,在其中临时获取一个代理地址,然后再发起 HTTP 请求。
1、下载中间件
仿照 middlewares.py 中的下载中间件,编写 process_request,返回 None。
from scrapy.http.request import Request
import random
class ProxyDownloaderMiddleware:
# 增加代理IP池,可以从网络搜索,可以从配置文件中读取
proxy_ip = '192.168.0.163' # 代理ip
proxy_port = '58591' # 代理端口号
proxies = [
f'http://{proxy_ip}:{proxy_port}',
]
def process_request(self, request: Request, spider):
request.meta['proxy'] = random.choice(self.proxies) # 增加proxy
print(request.url, request.meta['proxy'])
print('-' * 30)2、配置
在 settings.py 中配置:
# 3秒
DOWNLOAD_DELAY = 3
DOWNLOADER_MIDDLEWARES = {
'spiderman.middlewares.ProxyDownloaderMiddleware': 125,
}增加一个测试用的 spider 类,如果代理设置成功,该爬虫返回的内容就会是当前代理的信息:
import scrapy
class IPTestSpider(scrapy.Spider):
name = 'test'
allowed_domains = ['ipip.net']
start_urls = ['http://myip.ipip.net/']
def parse(self, response, **kwargs):
text = response.text
print(1, '-->', text)
return text执行 scrapy crawl test,查看打印的内容,是不是代理的地址信息。如果代理测试成功,就可以继续下面的操作。
在 settings.py 中开启 pipeline:
ITEM_PIPELINES = {
"spiderman.pipelines.SpidermanPipeline": 300,
}将数据存入 json 文件:
import json
class SpidermanPipeline:
def process_item(self, item, spider):
# item 获取的item;spider 获取该item的spider
self.jsonfile.write(json.dumps(dict(item)) + ',\n')
return item # 向后处理
def open_spider(self, spider):
filename = 'e:/books.json'
self.jsonfile = open(filename, 'w')
self.jsonfile.write('[\n')
def close_spider(self, spider):
if self.jsonfile:
self.jsonfile.write(']')
self.jsonfile.close()4.5、Scrapy-redis 组件
这是一个能给 Scrapy 框架引入分布式的组件。分布式由 Redis 提供,可以在不同节点上运行爬虫,共用同一个 Redis 实例。在 Redis 中存储待爬取的 URLs、Items。
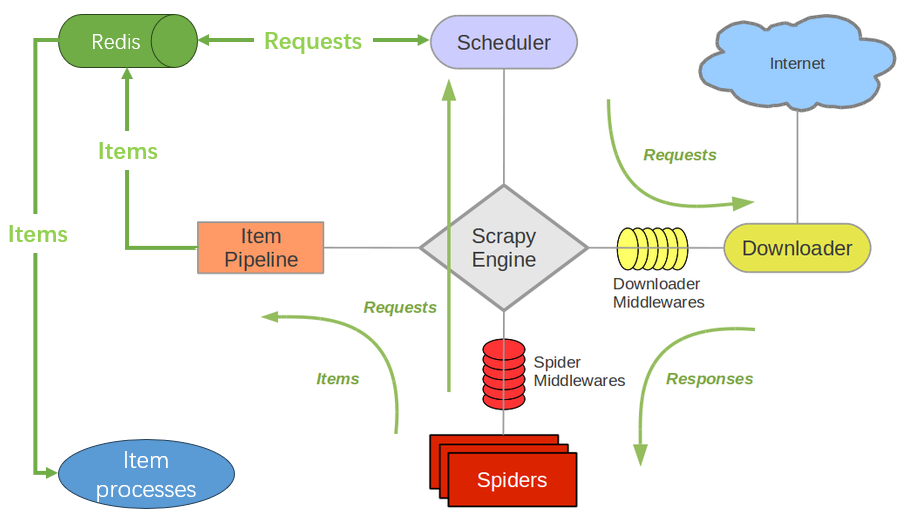
在以下方面做了增强:
Scheduler + Duplication Filter, Item Pipeline, Base Spiders
-
Scheduler
本质上将原来的普通队列,变成了 redis 以提供多爬虫多进程共享,并行能力增强。
-
Duplication Filter
scrapy 使用 set 来去重,scrapy-redis 使用 redis 的 set 类型去重。
-
Item Pipeline
在 Item Pipeline 增加一个处理,即将数据 items 存入 redis 的 items queue 中。
-
Base Spiders
提供了基于 RedisMixin 的 RedisSpider 和 RedisCrawlSpider,从 Redis 中读取 Url。
Redis 是服务,爬虫就是它的客户端,客户端就可以扩展出并行的很多爬虫一起爬取。
4.5.1、安装
$ pip install redis
$ pip install scrapy-redis4.5.2、豆瓣影评分析项目
抓取最新 top 1 电影,分析其影评。
点击“全部正在热映”,跳转至 https://movie.douban.com/cinema/nowplaying/beijing/。

这部分内容是直接通过网页 HTML 返回的,提取影片 id 的 xpath 为 //div[@id="nowplaying"]//li[@id][1]/@id。
影片页
点击电影,出现影片主题页面 https://movie.douban.com/subject/35593344/,在页面下面的短评处点击 全部(n)条 进入影片评论页面,从而得到影评的链接 https://movie.douban.com/subject/35593344/comments?status=P。
点击后页得到链接 https://movie.douban.com/subject/35593344/comments?start=20&limit=20&status=P&sort=new_score。
修改 limit=40,发送请求,可以得到预想的 40 条评论结果。经过测试 start 最大到 200,limit 最大到 100,超过最大值,页面报错。
提取影评的 xpath
//div[@class="comment-item "]//span[@class="short"]
注意,comment-item 后面有一个空格,这是豆瓣网页自带的一个小毛病。
4.5.2.1、创建 Scrapy 项目
$ scrapy startproject review moviereview 使用 scrapy-redis 配置 settings.py:
BOT_NAME = "review"
SPIDER_MODULES = ["review.spiders"]
NEWSPIDER_MODULE = "review.spiders"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
# Enables scheduling storing requests queue in redis.
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Ensure all spiders share same duplicates filter through redis.
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# Don't cleanup redis queues, allows to pause/resume crawls.
#SCHEDULER_PERSIST = True
# The item pipeline serializes and stores the items in this redis key.
# 注意,必须开启该选项,scrapy爬取的结果才会存到redis,以供后续数据分析处理。
REDIS_ITEMS_KEY = '%(spider)s:items'
ITEM_PIPELINES = {
'review.pipelines.ReviewPipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 300
}
# Specify the host and port to use when connecting to Redis (optional).
REDIS_HOST = '192.168.229.135'
REDIS_PORT = 6379
# Specify the full Redis URL for connecting (optional).
# If set, this takes precedence over the REDIS_HOST and REDIS_PORT settings.
REDIS_URL = 'redis://:WelC0me168!@192.168.229.135:6379'
# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"Note:redis 6.0 以前版本认证很简单,服务器端配置
requirepass <password>,客户端配置AUTH <password>就可以认证,没有用户的概念。[root@slave ~]# redis-cli -h 192.168.229.135 192.168.229.135:6379> AUTH WelC0me168! OK 192.168.229.135:6379> KEYS * 1) "key1" 2) "key3" 3) "key2"redis 6.0 以后版本增加了 ACL 功能,支持用户权限控制,https://redis.io/docs/management/security/acl/
我们使用的 redis 服务器是 v6.2.7,没有使用 ACL,只是简单配置了
requirepass <password>,所以 settings.py 配置文件中要设置REDIS_URL = 'redis://:WelC0me168!@192.168.229.135:6379'认证,注意格式,不要随便加引号。
4.5.2.2、构建 Item
import scrapy
class ReviewItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
review = scrapy.Field()4.5.2.3、构建爬虫
$ cd moviereview
$ scrapy genspider -t crawl dbreview douban.com写完先测试,然后将类型改为 RedisCrawlSpider
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import ReviewItem
from scrapy_redis.spiders import RedisCrawlSpider
class DbreviewSpider(RedisCrawlSpider):
name = "dbreview"
allowed_domains = ["douban.com"]
# start_urls = ["https://movie.douban.com/subject/35593344/comments?start=0&limit=20&status=P&sort=new_score"]
"""Spider that reads urls from redis queue (myspider:start_urls)."""
redis_key = 'dbreview:start_urls'
rules = (Rule(LinkExtractor(allow=r"start=\d+"), callback="parse_item", follow=False),)
def parse_item(self, response):
item = {}
comment = '//div[@class="comment-item "]//span[@class="short"]/text()'
reviews = response.xpath(comment).extract()
for review in reviews:
item = ReviewItem()
item['review'] = review.strip()
yield item4.5.2.4、爬取
$ cd moviereview
$ scrapy crawl dbreview会发现程序会卡住,这是因为在等待起始 URL。
4.5.2.5、手动添加起始 url
redis 中:
master:6379> lpush dbreview:start_urls https://movie.douban.com/subject/35593344/comments?start=0&limit=20&status=P&sort=new_score注意:这里有版本兼容问题出现
Traceback (most recent call last):
File "C:\Users\Brinnatt\PycharmProjects\pythonProject1\venv\lib\site-packages\scrapy\utils\signal.py", li
ne 46, in send_catch_log
response = robustApply(
File "C:\Users\Brinnatt\PycharmProjects\pythonProject1\venv\lib\site-packages\pydispatch\robustapply.py",
line 55, in robustApply
return receiver(*arguments, **named)
File "C:\Users\Brinnatt\PycharmProjects\pythonProject1\venv\lib\site-packages\scrapy_redis\spiders.py", l
ine 208, in spider_idle
self.schedule_next_requests()
File "C:\Users\Brinnatt\PycharmProjects\pythonProject1\venv\lib\site-packages\scrapy_redis\spiders.py", l
ine 197, in schedule_next_requests
self.crawler.engine.crawl(req, spider=self)
TypeError: ExecutionEngine.crawl() got an unexpected keyword argument 'spider'scrapy-redis 0.7.3 和 Scrapy 2.11.0 就会出现以上问题,这里把 scrapy 降级到 2.8.0 版本可以正常工作。
4.5.2.6、分析
使用爬虫,爬取所有数据,然后使用 redis 中的数据开始分析。
jieba 分词
官网 https://github.com/fxsjy/jieba
$ pip install jieba测试代码:
# encoding=utf-8
import jieba
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
s = jieba.lcut("他来到了网易杭研大厦") # 直接返回列表
print(s)
s = jieba.cut("他来到了网易杭研大厦") # 返回生成器
print(s)stopword 停用词
数据清洗:把脏数据洗掉。检测出并去除掉数据中无效或无关的数据。例如,空值、非法值的检测,重复数据检测等。
对于一条条影评来说,我们分析的数据中包含了很多无效的数据,比如标点符号、英文的冠词、中文"的"等等,需要把它们清除掉。
使用停用词来去除这些无效的数据。
from redis import Redis
import json
import jieba
redis = Redis(host='192.168.229.135', password='WelC0me168!', port=6379)
stopwords = set()
with open('E:/ChineseStopWords.txt', encoding='utf8') as f:
for line in f:
stopwords.add(line.rstrip('\r\n'))
print('stopwords', '-->', stopwords)
items = redis.lrange('dbreview:items', 0, -1)
print('items', '-->', type(items))
print('items', '-->', items)
words = {}
for item in items:
val = json.loads(item)['review']
for word in jieba.cut(val):
if word not in stopwords:
words[word] = words.get(word, 0) + 1
print('words', '-->', words)
total = len(words)
frenq = {k: v / total for k, v in words.items()}
print('result', '-->', sorted(frenq.items(), key=lambda x: x[1], reverse=True))wordcloud 词云
可以使用词云对上面的 result 进行画图,后续有时间再补充。