
2、Python3 Web 框架
2.1、WEB 开发
CS 即客户端、服务器编程。
客户端、服务端之间需要使用 Socket,约定协议、版本(往往使用的协议是 TCP 或者 UDP),指定地址和端口,就可以通信了。
客户端、服务端传输数据,数据可以有一定的格式,双方必须先约定好。
BS 编程,即 Browser、Server 开发。
Browser 浏览器,一种特殊的客户端,支持 HTTP(s) 协议,能够通过 URL 向服务端发起请求,等待服务端返回 HTML 等数据,并在浏览器内可视化展示的程序。
Server,支持 HTTP(s) 协议,能够接受众多客户端发起的 HTTP 协议请求,经过处理,将 HTML 等数据返回给浏览器。
本质上来说,BS 是一种特殊的 CS,即客户端必须是一种支持 HTTP 协议且能解析并渲染 HTML 的软件,服务端必须是能够接收多客户端 HTTP 访问的服务器软件。
HTTP 协议底层基于 TCP 协议实现。
BS 开发分为两端开发:
-
客户端开发,或称前端开发。HTML、CSS、JavaScript 等。
-
服务端开发,Python 有 WSGI、Django、Flask、Tornado 等。
2.2、HTTP 协议
2.2.1、安装 httpd
# yum install httpd -y使用 httpd 服务,观察 http 协议。
2.2.2、协议
Http 协议是无状态协议。
同一个客户端的两次请求之间没有任何关系,从服务器角度来说,它不知道这两个请求来自同一个客户端。
2.2.2.1、cookie
键值对信息。浏览器发起每一请求时,都会把 cookie 信息发给服务器端。是一种客户端、服务器端传递数据的技术。服务端可以通过判断这些信息,来确定这次请求是否和之前的请求有关联。一般来说 cookie 信息是在服务器端生成,返回给客户端的。客户端可以自己设置 cookie 信息。
2.2.2.2、URL 组成
URL 可以说就是地址,uniform resource locator 统一资源定位符,每一个链接指向一个资源供客户端访问。
schema://host[:port#]/path/.../[;url-params][?query-string][#anchor]
例如,通过下面的 URL 访问网页
http://www.brinnatt.com/pathon/index.html?id=5&name=python
访问静态资源时,通过上面这个 URL 访问的是网站的某路径下的 index.html 文件,而这个文件对应磁盘上的真实文件。会从磁盘上读取这个文件,并把文件的内容发回浏览器端。
scheme 模式、协议:
-
http、ftp、https、file、mailto 等等。mysql 等都是类似这样写。
-
host:port
www.brinnatt.com:80,80 端口是默认端口可以不写。域名会使用 DNS 解析,域名会解析成 IP 才能使用。实际上会对解析后返回的 IP 的 TCP 的 80 端口发起访问。
-
/path/to/resource
path,指向资源的路径。
-
?key1=value1&key2=value2query string,查询字符串,问号分割,后面 key=value 形式,且使用 & 符号分割。
2.2.2.3、HTTP 消息
消息分为 Request、Response。
-
Request:浏览器向服务器发起的请求。
-
Response:服务器对客户端请求的响应。
请求和响应消息都是由请求行、Header 消息报头、Body 消息正文组成。
2.2.2.3.1、请求
请求消息行:请求方法 Method,请求路径,协议版本
GET /index.html HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:87.0) Gecko/20100101 Firefox/87.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Upgrade-Insecure-Requests: 1请求方法 Method
GET 请求获取URL对应的资源
POST 提交数据至服务器端
HEAD 和GET类似,不过不返回消息正文常见传递信息的方式:
-
GET 方法使用 Query String
http://www.brinnatt.com/pathon/index.html?id=5&name=python通过查询字符串在 URL 中传递参数。
-
POST 方法提交数据
http://127.0.0.1:9999/xxx/yyy?id=5&name=brinnatt 使用表单提交数据,文本框input的name属性分别为age、weight、height 请求消息如下 POST /xxx/yyy?id=5&name=brinnatt HTTP/1.1 HOST: 127.0.0.1:9999 content-length: 26 content-type: application/x-www-form-urlencoded age=5&weight=80&height=170 -
URL 中本身就包含着信息
http://www.brinnatt.com/python/student/001
2.2.2.3.2、响应
响应消息行:协议版本,状态码,消息描述
HTTP/1.1 200 OK
Date: Mon, 12 Apr 2023 12:00:00 GMT
Content-Type: text/html; charset=UTF-8
Content-Length: 19562
Server: Apache/2.4.25 (Unix) OpenSSL/1.0.1e-fips mod_bwlimited/1.4
Cache-Control: max-age=3600, public
ETag: "28d9-5bd1c27175a21-gzip"
Vary: Accept-Encoding
Content-Encoding: gzip
X-XSS-Protection: 1; mode=block
X-Content-Type-Options: nosniff
X-Frame-Options: SAMEORIGIN
Strict-Transport-Security: max-age=31536000; includeSubDomains
Access-Control-Allow-Origin: *
Access-Control-Allow-Headers: Content-Type
Connection: keep-alivestatus code 状态码
状态码在响应头第一行
1xx 提示信息,表示请求已被成功接收,继续处理
2xx 表示正常响应
200 正常返回了网页内容
3xx 重定向
301 页面永久性移走,永久重定向。返回新的URL,浏览器会根据返回的url发起新的request请求
302 临时重定向
304 资源未修改,浏览器使用本地缓存。
4xx 客户端请求错误
404 Not Found,网页找不到,客户端请求的资源有错
400 请求语法错误
401 请求要求身份验证
403 服务器拒绝请求
5xx 服务器端错误
500 服务器内部错误
502 上游服务器错误,例如nginx反向代理的时候2.3、无状态,有连接和短连接
无状态,说过了,指的是服务器无法知道 2 次请求之间的联系,即使是前后 2 次同一个浏览器也没有任何数据能够判断出是同一个浏览器的请求。后来可以通过 cookie、session 来判断。
有连接,是因为它基于 TCP 协议,是面向连接的,需要 3 次握手、4 次断开。
短连接,Http 1.1 之前,都是一个请求一个连接,而 TCP 的连接创建销毁成本高,对服务器有很大的影响。所以,自 Http 1.1 开始,支持 keep-alive,默认也开启,一个连接打开后,会保持一段时间(可设置),浏览器再访问该服务器就使用这个 TCP 连接,减轻了服务器压力,提高了效率。
推荐图书《HTTP 权威指南》
2.4、WSGI
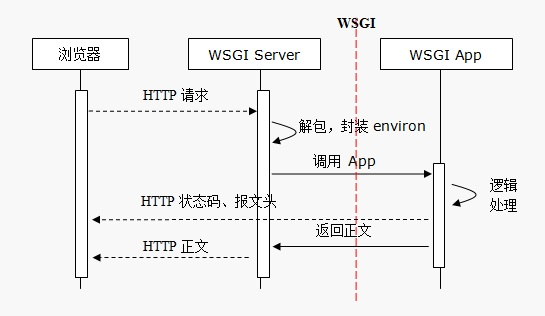
WSGI 主要规定了服务器端和应用程序间的接口。
2.4.1、WSGI 服务器(wsgiref)
wsgiref 是一个 WSGI 参考实现库。
wsgiref.simple_server 模块实现一个简单的 WSGI HTTP 服务器。
wsgiref.simple_server.make_server(host, port, app, server_class=WSGIServer, handler_class=WSGIRequestHandler) 启动一个 WSGI 服务器。
wsgiref.simple_server.demo_app(environ, start_response) 一个函数,小巧完整的 WSGI 的应用程序的实现。
# 返回文本例子
from wsgiref.simple_server import make_server, demo_app
ip = '127.0.0.1'
port = 9999
server = make_server(ip, port, demo_app) # demo_app应用程序,可调用
server.serve_forever() # server.handle_request() 执行一次WSGI 服务器作用:
-
监听 HTTP 服务端口(TCPServer,默认端口 80)。
-
接收浏览器端的 HTTP 请求并解析封装成 environ 环境数据。
-
负责调用应用程序,将 environ 和 start_response 方法传入。
-
将应用程序响应的正文封装成 HTTP 响应报文返回浏览器端。
2.4.2、WSGI APP 应用程序端
-
应用程序应该是一个可调用对象
Python 中应该是函数、类、实现了
__call__方法的类的实例。 -
这个可调用对象应该接收两个参数
# 1 函数实现 def application(environ, start_response): pass # 2 类实现 class Application: def __init__(self, environ, start_response): pass # 3 类实现 class Application: def __call__(self, environ, start_response): pass -
以上的可调用对象实现,都必须返回一个可迭代对象
res_str = b'brinnatt.com\n' # 函数实现 def application(environ, start_response): return [res_str] # 类实现 class Application: def __init__(self, environ, start_response): pass def __iter__(self): # 实现此方法,对象即可迭代 yield res_str # 类实现 class Application: def __call__(self, environ, start_response): return [res_str]environ 和 start_response 这两个参数名可以是任何合法名,但是一般默认都是这 2 个名字。
应用程序端还有些其他的规定,暂不用关心。
2.4.2.1、environ
environ 是包含 Http 请求信息的 dict 对象。
| 名称 | 含义 |
|---|---|
| REQUEST_METHOD | 请求方法,GET、POST等 |
| PATH_INFO | URL中的路径部分 |
| QUERY_STRING | 查询字符串 |
| SERVER_NAME, SERVER_PORT | 服务器名、端口 |
| HTTP_HOST | 地址和端口 |
| SERVER_PROTOCOL | 协议 |
| HTTP_USER_AGENT | UserAgent信息 |
2.4.2.2、start_response
它是一个可调用对象。有 3 个参数,定义如下:
start_response(status, response_headers, exc_info=None)
-
status 是状态码,例如 200 OK。
-
response_headers 是一个元素为二元组的列表,例如
[('Content-Type', 'text/plain;charset=utf-8')]。 -
exc_info 在错误处理的时候使用。
start_response 应该在返回可迭代对象之前调用,因为它返回的是 Response Header。返回的可迭代对象是 Response Body。
2.4.3、WSGI Server 服务器端
服务器程序需要调用符合上述定义的可调用对象 APP,传入 environ、start_response,APP 处理后,返回响应头和可迭代对象的正文,由服务器封装返回浏览器端。
# 返回网页的例子
from wsgiref.simple_server import make_server
def application(environ, start_response):
status = '200 OK'
headers = [('Content-Type', 'text/html;charset=utf-8')]
start_response(status, headers)
# 返回可迭代对象
html = '<h1>北京欢迎你</h1>'.encode("utf-8")
return [html]
ip = '127.0.0.1'
port = 9999
server = make_server(ip, port, application)
server.serve_forever() # server.handle_request() 一次simple_server 只是参考用,不能用于生产。
测试用命令:
$ curl -I http://192.168.142.1:9999/xxx?id=5
$ curl -X POST http://192.168.142.1:9999/yyy -d '{"x":2}'-
-I 使用 HEAD 方法。
-
-X 指定方法,-d 传输数据。
到这里就完成了一个简单的 WEB 程序开发。
WEB 服务器:
-
本质上就是一个 TCP 服务器,监听在特定端口上。
-
支持 HTTP 协议,能够将 HTTP 请求报文进行解析,能够把响应数据进行 HTTP 协议的报文封装并返回浏览器端。
-
实现了 WSGI 协议,该协议约定了和应用程序之间接口(参看 PEP333, https://www.python.org/dev/peps/pep-0333/)
APP 应用程序:
-
遵从 WSGI 协议
-
本身是一个可调用对象
-
调用 start_response,返回响应头部
-
返回包含正文的可迭代对象
为了更好的理解 WSGI 框架的工作原理,现在开始动手自己写一个 WEB 框架。
2.5、类 Flask 框架实现
从现在开始,我们将一步步完成一个 WSGI 的 WEB 框架,从而了解 WEB 框架的内部机制。
2.5.1、WSGI 请求 environ 处理
WSGI 服务器程序会帮我们处理 HTTP 请求报文,但是提供的 environ 还是一个用起来不方便的字典。
http://127.0.0.1:9999/python/index.html?id=1234&name=tom
('SERVER_PROTOCOL', 'HTTP/1.1')
('wsgi.url_scheme', 'http')
('HTTP_HOST', '127.0.0.1:9999')
('SERVER_PORT', '9999')
('REMOTE_ADDR', '127.0.0.1')
('REQUEST_METHOD', 'GET')
('CONTENT_TYPE', 'text/plain')
('PATH_INFO', '/python/index.html')
('QUERY_STRING', 'id=1234&name=tom')
('HTTP_USER_AGENT', 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/5.0 Chrome/55.0.2883.75 Safari/537.36')2.5.1.1、QUERY_STRING 解析
WSGI 服务器程序处理过 HTTP 报文后,返回一个字典,可以得到查询字符串 ('QUERY_STRING', 'id=1234&name=tom') 。这个键值对用起来不方便。
1、编程序解析
# id=5&name=wayne
qstr = environ.get('QUERY_STRING')
print(qstr)
if qstr:
for pair in qstr.split('&'):
k, _, v = pair.partition('=')
print("k={}, v={}".format(k, v))# id=5&name=wayne
querystr = environ.get('QUERY_STRING')
if querystr:
querydict = {k: v for k, _, v in map(lambda item: item.partition('='), querystr.split('&'))}
print(querydict)2、使用 cgi 模块
# id=5&name=wayne
qstr = environ.get('QUERY_STRING')
print(qstr)
print(parse_qs(qstr))
# {'name': ['wayne'], 'id': ['5']}可以看到使用这个库,可以解析查询字符串,请注意 value 是列表,为什么?
这是因为同一个 key 可以有多个值。
cgi 模块过期了,建议使用 urllib。
3、使用 urllib 库
# http://127.0.0.1:9999/?id=5&name=wayne&age=&comment=1,a,c&age=19&age=20
qstr = environ.get('QUERY_STRING')
print(qstr)
print(parse.parse_qs(qstr)) # 字典
print(parse.parse_qsl(qstr)) # 二元组列表
# 运行结果
id=5&name=wayne&age=&comment=1,a,c&age=19&age=20
{'name': ['wayne'], 'age': ['19', '20'], 'id': ['5'], 'comment': ['1,a,c']}
[('id', '5'), ('name', 'wayne'), ('comment', '1,a,c'), ('age', '19'), ('age', '20')]parse_qs 函数,将同一个名称的多值,保存在字典中,使用了列表保存。
comment=1,a,c 这不是多值,这是一个值。
age 是多值。
2.5.1.2、environ 的解析(webob库)
环境数据有很多,都是存在字典中的,字典的存取方式没有对象的属性访问方便。
使用第三方库 webob,可以把环境数据的解析、封装成对象。
2.5.1.2.1、webob 简介
Python 下,可以对 WSGI 请求进行解析,并提供对响应进行高级封装的库。
$ pip install webob官网文档 docs.webob.org。
2.5.1.2.2、webob.Request 对象
将环境参数解析并封装成 request 对象。
GET 方法,发送的数据是 URL 中 Query string,在 Request Header 中。
request.GET 就是一个字典 MultiDict,里面就封装着查询字符串。
POST 方法,"提交"的数据是放在 Request Body 里面,但是也可以同时使用 Query String。
request.POST 可以获取 Request Body 中的数据,也是个字典 MultiDict。
不关心什么方法提交,只关心数据,可以使用 request.params,它里面是所有提交数据的封装。
request = webob.Request(environ)
print(request.headers) # 类字典容器
print(request.method)
print(request.path)
print(request.query_string) # 查询字符串
print(request.GET) # GET方法的所有数据
print(request.POST) # POST方法的所有数据
print('params = {}'.format(request.params)) # 所有数据,参数2.5.1.2.3、MultiDict
MultiDict 允许一个 key 存了好几个值。
from webob.multidict import MultiDict
md = MultiDict()
md.add(1, 'brinnatt')
md.add(1, '.com')
md.add('a', 1)
md.add('a', 2)
md.add('b', '3')
md['b'] = '4'
for pair in md.items():
print(pair)
print(md.getall(1))
# print(md.getone('a')) # 只能有一个值
print(md.get('a')) # 返回一个值
print(md.get('c')) # 不会抛异常KeyError,返回None2.5.1.2.4、webob.Response 对象
res = webob.Response()
print(res.status)
print(res.headerlist)
start_response(res.status, res.headerlist)
# 返回可迭代对象
html = '<h1>北京欢迎你</h1>'.encode("utf-8")
return [html]如果一个 Application 是一个类的实例,可以实现 __call__ 方法。
我们来看看 webob.Response 类的源代码。
def __call__(self, environ, start_response):
"""
WSGI application interface
"""
if self.conditional_response:
return self.conditional_response_app(environ, start_response)
headerlist = self._abs_headerlist(environ)
start_response(self.status, headerlist)
if environ['REQUEST_METHOD'] == 'HEAD':
# Special case here...
return EmptyResponse(self._app_iter)
return self._app_iter由此可以得到下面代码:
def application(environ:dict, start_response):
# 请求处理
request = webob.Request(environ)
print(request.method)
print(request.path)
print(request.query_string)
print(request.GET)
print(request.POST)
print('params = {}'.format(request.params))
# 响应处理
res = webob.Response() # [('Content-Type', 'text/html; charset=UTF-8'), ('Content-Length', '0')]
res.status_code = 200 # 默认200
print(res.content_type)
html = '<h1>北京欢迎你</h1>'.encode("utf-8")
res.body = html
return res(environ, start_response)2.5.1.2.5、webob.dec 装饰器
wsgify 装饰器:
文档:https://docs.pylonsproject.org/projects/webob/en/stable/api/dec.html
class webob.dec.wsgify(func=None, RequestClass=None, args=(), kwargs=None, middleware_wraps=None)
要求提供类似下面的可调用对象,以函数举例:
from webob.dec import wsgify
import webob
@wsgify
def app(request: webob.Request) -> webob.Response:
res = webob.Response('<h1>北京欢迎你. brinnatt.com</h1>')
return reswsgify 装饰器装饰的函数应该具有一个参数,这个参数是 webob.Request 类型,是对字典 environ 的对象化后的实例。
返回值:
-
可以是一个 webob.Response 类型实例。
-
可以是一个 bytes 类型实例,它会被封装成 webob.Response 类型实例的 body 属性。
-
可以是一个字符串类型实例,它会被转换成 bytes 类型实例,然后会被封装成 webob.Response 类型实例的 body 属性。
总之,返回值会被封装成 webob.Response 类型实例返回。
由此修改测试代码,如下:
from wsgiref.simple_server import make_server
import webob
from webob.dec import wsgify
# application函数不用了,用来和app函数对比
def application(environ: dict, start_response):
# 请求处理
request = webob.Request(environ)
print(request.method)
print(request.path)
print(request.query_string)
print(request.GET)
print(request.POST)
print('params = {}'.format(request.params))
# 响应处理
res = webob.Response() # [('Content-Type', 'text/html; charset=UTF-8'), ('Content-Length', '0')]
res.status_code = 200 # 默认200
print(res.content_type)
html = '<h1>北京欢迎你</h1>'.encode("utf-8")
res.body = html
return res(environ, start_response)
@wsgify
def app(request: webob.Request) -> webob.Response:
print(request.method)
print(request.path)
print(request.query_string)
print(request.GET)
print(request.POST)
print('params = {}'.format(request.params))
res = webob.Response('<h1>北京欢迎你. brinnatt.com</h1>')
return res
if __name__ == '__main__':
ip = '127.0.0.1'
port = 9999
server = make_server(ip, port, app)
try:
server.serve_forever() # server.handle_request() 一次
except KeyboardInterrupt:
server.shutdown()
server.server_close()将上面的 app 函数封装成类:
from webob import Response, Request
from webob.dec import wsgify
from wsgiref.simple_server import make_server
class App:
@wsgify
def __call__(self, request: Request):
return '<h1>北京欢迎你. brinnatt.com</h1>'
if __name__ == '__main__':
ip = '127.0.0.1'
port = 9999
server = make_server(ip, port, App())
try:
server.serve_forever() # server.handle_request() 一次
except KeyboardInterrupt:
server.shutdown()
server.server_close()上面的代码中,所有的请求,都由这个 App 类的实例处理,需要对它进行改造。
2.5.2、路由 route
什么是 路由?
简单说,就是路怎么走。就是按照不同的路径分发数据。
URL 代表对不同资源的地址的访问,可以认为请求不同路径对应的数据。对动态网页技术来说,不同的路径应该对应不同的应用程序来处理,返回数据,用户以为还是访问的静态的网页。
所以,代码中要增加对 URL 路径的分析处理。不管是静态 WEB 服务器,还是动态 WEB 服务器,都需要路径和资源或处理程序的映射,最终返回 HTML 的文本。
-
静态 WEB 服务器,解决路径和文件之间的映射。
-
动态 WEB 服务器,解决路径和应用程序之间的映射。
-
所有的 WEB 框架都是如此,都有路由配置。
2.5.2.1、路由类实现
路由功能,使用路由类实现。
路由类实现的功能主要就是完成 path 到 handler 函数的映射,使用字典保存最适合。
路由映射的建立需要提供一个方法 register,它需要提供 2 个参数 path 和 handler。
有以下的路由需求:
| 路径 | 内容 |
|---|---|
| / | 返回欢迎内容 |
| /python | 返回 Hello Python |
| 其它路径 | 返回 404 |
# 路由
# url = 'http://127.0.0.1:9999/python/index.html?id=5&name=wayne&age=19&age=20'
# path = '/python/index.html'
class Router:
ROUTETABLE = {}
def register(self, path, handler):
self.ROUTETABLE[path] = handler
def indexhandler(request):
return '<h1>北京欢迎你. brinnatt.com</h1>'
def pythonhandler(request):
return '<h1>Welcome to brinnatt Python</h1>'
router = Router()
router.register('/', indexhandler)
router.register('/python', pythonhandler)2.5.2.2、404 处理
webob.exc 提供了异常模块:https://docs.pylonsproject.org/projects/webob/en/stable/api/exceptions.html
使用 webob.exc.HTTPNotFound 表示路由表找不到对应的处理函数。
2.5.2.3、注册函数的改造
将注册函数改造装饰器:
# 路由
# url = 'http://127.0.0.1:9999/python/index.html?id=5&name=wayne&age=19&age=20'
# path = '/python/index.html'
class Router:
ROUTETABLE = {}
@classmethod # 注册路由,装饰器
def register(cls, path):
def wrapper(handler):
cls.ROUTETABLE[path] = handler
return handler
return wrapper
@Router.register('/')
def indexhandler(request):
return '<h1>北京欢迎你. brinnatt.com</h1>'
@Router.register('/python')
def pythonhandler(request):
return '<h1>Welcome to brinnatt Python</h1>'将路由功能合并到 App 类中去:
from webob import Response, Request
from webob.dec import wsgify
from wsgiref.simple_server import make_server
from webob.exc import HTTPNotFound
class Router:
ROUTETABLE = {}
@classmethod # 注册路由,装饰器
def register(cls, path):
def wrapper(handler):
cls.ROUTETABLE[path] = handler
return handler
return wrapper
@Router.register('/')
def indexhandler(request):
return '<h1>北京欢迎你. brinnatt.com</h1>'
@Router.register('/python')
def pythonhandler(request):
return '<h1>Welcome to brinnatt Python</h1>'
class App:
_Router = Router
@wsgify
def __call__(self, request: Request):
try:
return self._Router.ROUTETABLE[request.path](request)
except:
raise HTTPNotFound('<h1>你访问的页面被外星人劫持了</h1>')
if __name__ == '__main__':
ip = '127.0.0.1'
port = 9999
server = make_server(ip, port, App())
try:
server.serve_forever() # server.handle_request() 一次
except KeyboardInterrupt:
server.shutdown()
server.server_close()到目前为止,一个框架的雏形基本完成了。
App 是 WSGI 中的应用程序,但是这个应用程序已经变成了一个路由程序,处理逻辑已经移到了应用程序外了,而这部分就是以后留给程序员完成的部分。
2.5.2.4、路由正则匹配
目前实现的路由匹配,路径匹配非常死板,使用正则表达式,可以更好的匹配路径。导入 re 模块。
注册的时候,存入不再是路径字符串,而是模式 pattern。
App 的 __call__ 方法中实现模式和传入路径的匹配。
compile 方法,编译正则表达式
match 方法,必须从头开始匹配,只匹配一次
search 方法,只匹配一次
fullmatch 方法,要完全匹配
findall 方法,从头开始找,找到所有匹配
分组捕获
'/(?P<biz>.*)/(?P<url>.*)' 贪婪
'/(?P<biz>.*?)/(?P<url>.*)' 非贪婪
@Application.register('^/$') # 只匹配根
@Application.register('/python$') # 只匹配/python字典的问题:
如果使用字典,key 保存的是路径,普通字典遍历匹配的时候,是不能保证路径匹配的顺序的。但是匹配过程应该是有顺序的。
正则表达式预编译,何时预编译正则表达式呢?
第一次使用的时候会影响用户体验,所以还是要在注册的时候编译。
综上,改用列表,元素使用二元组(编译后的正则对象, handler)。
from webob import Response, Request
from webob.dec import wsgify
from wsgiref.simple_server import make_server
from webob.exc import HTTPNotFound
import re
class Router:
ROUTETABLE = [] # 列表,有序的
@classmethod # 注册路由,装饰器
def register(cls, pattern):
def wrapper(handler):
cls.ROUTETABLE.append((re.compile(pattern), handler)) # (预编译正则对象,处理函数)
return handler
return wrapper
@Router.register('^/$')
def indexhandler(request):
return '<h1>北京欢迎你. brinnatt.com</h1>'
@Router.register('^/python$')
def pythonhandler(request):
return '<h1>Welcome to brinnatt Python</h1>'
class App:
_Router = Router
@wsgify
def __call__(self, request: Request):
for pattern, handler in self._Router.ROUTETABLE:
if pattern.match(request.path): # 正则匹配
return handler(request)
raise HTTPNotFound('<h1>你访问的页面被外星人劫持了</h1>')
if __name__ == '__main__':
ip = '127.0.0.1'
port = 9999
server = make_server(ip, port, App())
try:
server.serve_forever() # server.handle_request() 一次
except KeyboardInterrupt:
server.shutdown()
server.server_close()2.5.2.5、正则表达式分组捕获
假设 URL 为 http://127.0.0.1:9999/11808,路径为 /11808,如何编写路径匹配的正则表达式?
^/(?P<id>\d+)$
@Router.register(r'^/$')
@Router.register(r'^/(?P<id>\d+)$')
def indexhandler(request):
print(request.groups)
print(request.groupdict)
return '<h1>北京欢迎你. brinnatt.com</h1>'
class App:
_Router = Router
@wsgify
def __call__(self, request: Request):
for pattern, handler in self._Router.ROUTETABLE:
matcher = pattern.match(request.path)
if matcher: # 正则匹配
# 动态为request增加属性
request.groups = matcher.groups() # 所有分组组成的元组,包括命名分组
request.groupdict = matcher.groupdict() # 命名分组组成的字典
return handler(request)
raise HTTPNotFound('<h1>你访问的页面被外星人劫持了</h1>')2.5.2.6、Request Method 过滤
请求方法,一般来说即使是同一个 URL,因为请求方法不同,处理方式也不同。
假设有一个 URL,GET 方法表示希望返回网页内容;POST 方法表示浏览器提交数据过来需要处理并存入数据库,最终返回客户端存储成功或失败的信息。
换句话说,需要请求方法、正则同时匹配才能决定执行什么处理函数。
| 方法 | 含义 |
|---|---|
| GET | 请求指定的页面信息,并返回报头和正文 |
| HEAD | 类似于 get 请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求正文中。POST 请求可能会导致新的资源的建立或已有资源的修改 |
| PUT | 从客户端向服务器传送的数据取代指定的文档的内容 |
| DELETE | 请求服务器删除指定的内容 |
请求方法还有很多,这里不再赘述。
实现请求方法判断的方式有:
1、在 register 装饰器中增加参数。
@classmethod # 注册路由,装饰器
def register(cls, method, pattern):
def wrapper(handler):
cls.ROUTETABLE.append((method.upper(), re.compile(pattern), handler)) # (预编译正则对象,处理函数)
return handler
return wrapper
@Application.register('GET', '^/$')
def handler(request):
pass2、将 register 分解成不同方法的装饰器
@classmethod
def get(cls, pattern):
return cls.register('GET', pattern)将 register 注册方法改名为 route 路由方法。
改造代码如下:
from webob import Response, Request
from webob.dec import wsgify
from wsgiref.simple_server import make_server
from webob.exc import HTTPNotFound
import re
class Router:
ROUTETABLE = [] # 列表,有序的
@classmethod # 注册路由,装饰器
def route(cls, method, pattern):
def wrapper(handler):
cls.ROUTETABLE.append((method.upper(), re.compile(pattern), handler)) # (预编译正则对象,处理函数)
return handler
return wrapper
@classmethod
def get(cls, pattern):
return cls.route('GET', pattern)
@classmethod
def post(cls, pattern):
return cls.route('POST', pattern)
@classmethod
def head(cls, pattern):
return cls.route('HEAD', pattern)
@Router.get(r'^/$')
@Router.route('GET', r'^/(?P<id>\d+)$')
def indexhandler(request):
print(request.groups)
print(request.groupdict)
return '<h1>北京欢迎你. brinnatt.com</h1>'
@Router.get('^/python$')
def pythonhandler(request):
res = Response()
res.charset = 'utf-8'
res.body = '<h1>Welcome to brinnatt Python</h1>'.encode()
return res
class App:
_Router = Router
@wsgify
def __call__(self, request: Request):
for method, pattern, handler in self._Router.ROUTETABLE:
if request.method.upper() != method:
continue
matcher = pattern.match(request.path)
if matcher: # 正则匹配
# 动态为request增加属性
request.groups = matcher.groups() # 所有分组组成的元组,包括命名分组
request.groupdict = matcher.groupdict() # 命名分组组成的字典
return handler(request)
raise HTTPNotFound('<h1>你访问的页面被外星人劫持了</h1>')
if __name__ == '__main__':
ip = '127.0.0.1'
port = 9999
server = make_server(ip, port, App())
try:
server.serve_forever() # server.handle_request() 一次
except KeyboardInterrupt:
server.shutdown()
server.server_close()改进:一个 URL 可以设定多种请求方法,怎么解决?
思路一
如果什么方法都不写,相当于所有方法都支持。
@Application.route('^/$') # 隐含一个默认值 method=None
等价于@Application.route(None, '^/$')
如果一个处理函数handler需要关联多个请求方法 method,如下:
@Router.route(('GET','PUT','DELETE'), '^/$')
@Router.route(['GET','PUT','POST'], '^/$')
@Router.route({'POST','PUT','DELETE'}, '^/$')
思路二
调整参数位置,把method放到后面变成可变参数
def route(cls, pattern, *methods):
pass
那么methods有可能是一个空元组,表示匹配所有方法;非空表示匹配指定方法。
@Router.route('^/$', 'POST','PUT','DELETE')
@Router.route('^/$')
选择思路二完整代码如下:
from webob import Response, Request
from webob.dec import wsgify
from wsgiref.simple_server import make_server
from webob.exc import HTTPNotFound
import re
class Router:
ROUTETABLE = [] # 列表,有序的
@classmethod # 注册路由,装饰器
def route(cls, pattern, *methods):
def wrapper(handler):
cls.ROUTETABLE.append(
(tuple(map(lambda x: x.upper(), methods)),
re.compile(pattern),
handler)
) # (预编译正则对象,处理函数)
return handler
return wrapper
@classmethod
def get(cls, pattern):
return cls.route(pattern, 'GET')
@classmethod
def post(cls, pattern):
return cls.route(pattern, 'POST')
@classmethod
def head(cls, pattern):
return cls.route(pattern, 'HEAD')
@Router.get(r'^/$')
@Router.route(r'^/(?P<id>\d+)$', 'GET', 'PAtCh')
def indexhandler(request):
print(request.groups)
print(request.groupdict)
return '<h1>北京欢迎你. brinnatt.com</h1>'
@Router.get(r'^/python$')
@Router.route(r'^/python/(?P<id>\d+)$', 'POst', 'puT')
def pythonhandler(request):
res = Response()
res.charset = 'utf-8'
res.body = '<h1>Welcome to brinnatt Python</h1>'.encode()
return res
class App:
_Router = Router
@wsgify
def __call__(self, request: Request):
for methods, pattern, handler in self._Router.ROUTETABLE:
# not methods表示一个方法都没有定义,就是支持全部方法
if not methods or request.method.upper() in methods:
matcher = pattern.match(request.path)
if matcher: # 正则匹配
# 动态为request增加属性
request.groups = matcher.groups() # 所有分组组成的元组,包括命名分组
request.groupdict = matcher.groupdict() # 命名分组组成的字典
return handler(request)
raise HTTPNotFound('<h1>你访问的页面被外星人劫持了</h1>')
if __name__ == '__main__':
ip = '127.0.0.1'
port = 9999
server = make_server(ip, port, App())
try:
server.serve_forever() # server.handle_request() 一次
except KeyboardInterrupt:
server.shutdown()
server.server_close()路由匹配从 URL => handler 变成了 method + URL => handler。
2.5.3、路由分组
所谓路由分组,就是按照前缀分别映射。
需求:URL 为 /product/123456,需要将产品 ID 提取出来。
分析:这个 URL 可以看做是一级分组路由,生产环境中够用了。
例如:
product = Router('/product') # 匹配前缀/product,每一个路由实例保存一个前缀
product.get('/(?P<id>\d+)') # 匹配路径为/product/123456,路由实例再管理第二级匹配常见的一级目录:
-
/admin 后台管理
-
/product 产品
这些目录都是 / 根目录下的第一级,暂且称为前缀 prefix。
前缀要求必须以 / 开头,但不能以分隔符结尾
# 下面的定义方法已经不能描述prefix和URL之间的隶属关系
@Router.get(r'^/$')
def index(request: Request):
pass
@Router.route('^/python$')
def showpython(request: Request):
pass如何建立 prefix 和 URL 之间的隶属关系?
-
一个 Prefix 下可以有若干个 URL,这些 URL 都是属于这个 Prefix 的。
-
不同前缀对应不同的 Router 实例管理,所有路由注册方法,都成了实例的方法,路由表实例自己管理。
-
App 中需要保存不同前缀的 Router 实例,提供注册方法,把 Router 对象管理起来。
-
__call__方法依然是 WSGI 回调入口,在其中遍历所有 Router 实例,将路径匹配代码全部挪到 Router 中并新建一个 match 方法。 -
match 方法匹配就返回 Response 对象,否则返回 None。
from webob import Response, Request
from webob.dec import wsgify
from wsgiref.simple_server import make_server
from webob.exc import HTTPNotFound
import re
class Router:
def __init__(self, prefix: str = ''):
self.__prefix = prefix.rstrip('/\\') # 前缀,例如/product
self.__routetable = [] # 存三元组,列表,有序的
# 注册路由,装饰器
def route(self, pattern, *methods):
def wrapper(handler):
self.__routetable.append(
(tuple(map(lambda x: x.upper(), methods)),
re.compile(pattern),
handler)
) # (预编译正则对象,处理函数)
return handler
return wrapper
def get(self, pattern):
return self.route(pattern, 'GET')
def post(self, pattern):
return self.route(pattern, 'POST')
def head(self, pattern):
return self.route(pattern, 'HEAD')
def match(self, request: Request):
# 必须先匹配前缀
if not request.path.startswith(self.__prefix):
return None
# 前缀匹配,说明就必须这个Router实例处理,后续匹配不上,依然返回None
for methods, pattern, handler in self.__routetable:
# not methods表示一个方法都没有定义,就是支持全部方法
if not methods or request.method.upper() in methods:
# 前提已经是以__prefix开头了,可以replace,去掉prefix剩下的才是正则表达式需要匹配的路径
matcher = pattern.match(request.path.replace(self.__prefix, '', 1))
if matcher: # 正则匹配
# 动态为request增加属性
request.groups = matcher.groups() # 所有分组组成的元组,包括命名分组
request.groupdict = matcher.groupdict() # 命名分组组成的字典
return handler(request)
class App:
__ROUTERS = [] # 存储所有一级Router对象
# 注册
@classmethod
def register(cls, *routers: Router):
for router in routers:
cls.__ROUTERS.append(router)
@wsgify
def __call__(self, request: Request):
# 遍历__ROUTERS,调用Router实例的match方法,看谁匹配
for router in self.__ROUTERS:
response = router.match(request)
if response: # 匹配返回非None的Router对象
return response # 匹配则立即返回
raise HTTPNotFound('<h1>你访问的页面被外星人劫持了</h1>')
# 创建Router对象
idx = Router()
py = Router('/python')
# 注册
App.register(idx, py)
@idx.get(r'^/$')
@idx.route(r'^/(?P<id>\d+)$', 'GET', 'PAtCh')
def indexhandler(request):
print(request.groups)
print(request.groupdict)
return '<h1>北京欢迎你. brinnatt.com</h1>'
@py.get(r'^/$')
@py.route(r'^/(?P<id>\d+)$', 'POst', 'puT')
def pythonhandler(request):
res = Response()
res.charset = 'utf-8'
res.body = '<h1>Welcome to brinnatt Python</h1>'.encode()
return res
if __name__ == '__main__':
ip = '127.0.0.1'
port = 9999
server = make_server(ip, port, App())
try:
server.serve_forever() # server.handle_request() 一次
except KeyboardInterrupt:
server.shutdown()
server.server_close()2.5.4、字典访问属性化
这是一个技巧,让 kwargs 这个字典,不使用 [ ] 访问元素,使用 . 点号访问元素,如同属性一样访问。
字典转属性类,如下:
class AttrDict:
def __init__(self, d:dict):
self.__dict__.update(d if isinstance(d, dict) else {})
def __setattr__(self, key, value):
# 不允许修改属性
raise NotImplementedError
def __repr__(self):
return "<AttrDict {}>".format(self.__dict__)
d = {'a':1, 'b':2}
do = AttrDict(d)
print(do.a, do.b)
print(do.__dict__)
# 下面语句抛异常
do.c = 1
do.a = 2
# 下面语句可以
do.__dict__['c'] = 1000 # 前面也有学过,可以巧妙避开使用 .点 给属性赋值
print(do.__dict__)修改 Router 的 match 方法如下:
class AttrDict:
def __init__(self, d: dict):
self.__dict__.update(d if isinstance(d, dict) else {})
def __setattr__(self, key, value):
# 不允许修改属性
raise NotImplementedError
def __repr__(self):
return "<AttrDict {}>".format(self.__dict__)
def __len__(self):
return len(self.__dict__)
class Router:
def match(self, request: Request):
# 必须先匹配前缀
if not request.path.startswith(self.__prefix):
return None
# 前缀匹配,说明就必须这个Router实例处理,后续匹配不上,依然返回None
for methods, pattern, handler in self.__routetable:
# not methods表示一个方法都没有定义,就是支持全部方法
if not methods or request.method.upper() in methods:
# 前提已经是以__prefix开头了,可以replace,去掉prefix剩下的才是正则表达式需要匹配的路径
matcher = pattern.match(request.path.replace(self.__prefix, '', 1))
if matcher: # 正则匹配
# 动态为request增加属性
request.groups = matcher.groups() # 所有分组组成的元组,包括命名分组
request.groupdict = AttrDict(matcher.groupdict()) # # 命名分组组成的字典被属性化
return handler(request)
@idx.get(r'^/$')
@idx.route(r'^/(?P<id>\d+)$', 'GET', 'PAtCh')
def indexhandler(request):
print(request.groups)
print(request.groupdict)
id = ''
if request.groupdict:
id = request.groupdict.id
return f'<h1>北京欢迎你{id}. brinnatt.com</h1>'2.5.5、正则表达式的化简
问题:目前路由匹配使用正则表达式定义,不友好,很多程序员不会使用正则表达式,能否简化?
分析:生产环境中,URL 是规范的,不能随便书写,路径是有意义的,尤其是对 restful 风格。所以,要对 URL 规范。
例如:/product/111023564 ,这就是一种规范,要求第一段是业务,第二段是 ID。
设计:路径规范化,如下定义。
/student/{name:str}/{id:int}
类型设计,支持 str、word、int、float、any 类型。
还可以考虑一种 raw 类型,直接支持正则表达式,暂不考虑实现。
通过这样的定义,可以让用户定义简化了,也规范了,背后的转换由编程者实现。
| 类型 | 含义 | 对应正则 |
|---|---|---|
| str | 不包含/的任意字符。默认类型 | [^/]+ |
| word | 字母和数字 | \w+ |
| int | 纯粹数字,正负数 | [+-]?\d+ |
| float | 正负号,数字,包含 . |
[+-]?\d+.\d+ |
| any | 包含/的任意字符 | .+ |
建立如下的映射关系:
# 类型字符串映射到正则表达式
TYPEPATTERNS = {
'str' : r'[^/]+',
'word' : r'\w+',
'int' : r'[+-]?\d+',
'float' : r'[+-]?\d+\.\d+', # 严苛的要求必须是 15.6这样的形式
'any' : r'.+'
}
# 类型字符串到Python类型的映射
TYPECAST = {
'str' : str,
'word' : str,
'int' : int,
'float' : float,
'any' : str
}/student/{name:str}/{id:int} 怎样转换?
使用 (\{([^\{\}]+):([^\{\}]+)\}) 来 search 整个字符串,分别找到 name:str 和 id:int 并替换成目标的正则表达式。
id 转变为命名分组的名字,int转变为对应的正则表达式,如下
/student/{name:str}/xxx/{id:int} => /student/(?P<name>[^/]+)/xxx/(?P<id>[+-]?\d+)
对于 /student/{name:str} 和 /student/{name:} 正则表达式修改为 /{([^{}:]+):?([^{}:]*)}
先看一个正则替换 sub 函数使用的例子:
import re
pattern = r'\d+'
repl = ''
src = 'welcome 123 to 456 brinnatt.com'
regex = re.compile(pattern)
dest = regex.sub(repl, src)
print(1, '-->', dest)
pattern = r'/{([^{}:]+):?([^{}:]*)}'
src = '/student/{name}/xxx/{id:int}'
print(2, '-->', src)
def repl(matcher):
print(3, '-->', matcher.group(0))
print(4, '-->', matcher.group(1))
print(5, '-->', matcher.group(2)) # {name}或{name:}这个分组都匹配为''
# (?P<name>...)
return '/(?P<{}>{})'.format(
matcher.group(1),
'T' if matcher.group(2) else 'F'
)
regex = re.compile(pattern)
dest = regex.sub(repl, src)
print(6, '-->', dest)编写一个转换例程:
import re
regex = re.compile(r'/{([^{}:]+):?([^{}:]*)}')
s = [
'/student/{name:str}/xxx/{id:int}',
'/student/xxx/{id:int}/yyy',
'/student/xxx/5134324',
'/student/{name:}/xxx/{id}',
'/student/{name:}/xxx/{id:aaa}'
]
# /{id:int} => /(?P<id>[+-]?\d+)
# '/(?<{}>{})'.format('id', TYPEPATTERNS['int'])
TYPEPATTERNS = {
'str': r'[^/]+',
'word': r'\w+',
'int': r'[+-]?\d+',
'float': r'[+-]?\d+\.\d+', # 严苛的要求必须是15.6这样的形式
'any': r'.+'
}
def repl(matcher):
# print(matcher.group(0))
# print(matcher.group(1))
# print(matcher.group(2)) # {name}或{name:}这个分组都匹配为''
return '/(?P<{}>{})'.format(
matcher.group(1),
TYPEPATTERNS.get(matcher.group(2), TYPEPATTERNS['str'])
)
def parse(src: str):
return regex.sub(repl, src)
a = 1
for x in s:
print(a, '-->', parse(x))
a += 1将上面的代码合入 Router 类中:
from webob import Response, Request
from webob.dec import wsgify
from wsgiref.simple_server import make_server
from webob.exc import HTTPNotFound
import re
class AttrDict:
def __init__(self, d: dict):
self.__dict__.update(d if isinstance(d, dict) else {})
def __setattr__(self, key, value):
# 不允许修改属性
raise NotImplementedError
def __repr__(self):
return "<AttrDict {}>".format(self.__dict__)
def __len__(self):
return len(self.__dict__)
class Router:
# 正则转换
__regex = re.compile(r'/{([^{}:]+):?([^{}:]*)}')
# 类型字符串映射到正则表达式
TYPEPATTERNS = {
'str': r'[^/]+',
'word': r'\w+',
'int': r'[+-]?\d+',
'float': r'[+-]?\d+\.\d+', # 严苛的要求必须是 15.6这样的形式
'any': r'.+'
}
def __repl(self, matcher):
# print(matcher.group(0))
# print(matcher.group(1))
# print(matcher.group(2)) # {name}或{name:}这个分组都匹配为''
return '/(?P<{}>{})'.format(
matcher.group(1),
self.TYPEPATTERNS.get(matcher.group(2), self.TYPEPATTERNS['str'])
)
def __parse(self, src: str):
return self.__regex.sub(self.__repl, src)
# 实例
def __init__(self, prefix: str = ''):
self.__prefix = prefix.rstrip('/\\') # 前缀,例如/product
self.__routetable = [] # 存三元组,列表,有序的
# 注册路由,装饰器
def route(self, pattern, *methods):
def wrapper(handler):
# /student/{name:str}/xxx/{id:int} =>
# '/student/(?P<name>[^/]+)/xxx/(?P<id>[+-]?\\d+)'
self.__routetable.append(
(tuple(map(lambda x: x.upper(), methods)),
re.compile(self.__parse(pattern)), # 用户输入规则转换为正则表达式并编译
handler)
) # (方法元组,预编译正则对象,处理函数)
return handler
return wrapper
def get(self, pattern):
return self.route(pattern, 'GET')
def post(self, pattern):
return self.route(pattern, 'POST')
def head(self, pattern):
return self.route(pattern, 'HEAD')
def match(self, request: Request):
# 必须先匹配前缀
if not request.path.startswith(self.__prefix):
return None
# 前缀匹配,说明就必须这个Router实例处理,后续匹配不上,依然返回None
for methods, pattern, handler in self.__routetable:
# not methods表示一个方法都没有定义,就是支持全部方法
if not methods or request.method.upper() in methods:
# 前提已经是以__prefix开头了,可以replace,去掉prefix剩下的才是正则表达式需要匹配的路径
matcher = pattern.match(request.path.replace(self.__prefix, '', 1))
if matcher: # 正则匹配
# 动态为request增加属性
request.groups = matcher.groups() # 所有分组组成的元组,包括命名分组
request.groupdict = AttrDict(matcher.groupdict()) # # 命名分组组成的字典被属性化
return handler(request)
class App:
__ROUTERS = [] # 存储所有一级Router对象
# 注册
@classmethod
def register(cls, *routers: Router):
for router in routers:
cls.__ROUTERS.append(router)
@wsgify
def __call__(self, request: Request):
# 遍历__ROUTERS,调用Router实例的match方法,看谁匹配
for router in self.__ROUTERS:
response = router.match(request)
if response: # 匹配返回非None的Router对象
return response # 匹配则立即返回
raise HTTPNotFound('<h1>你访问的页面被外星人劫持了</h1>')
# 创建Router对象
idx = Router()
py = Router('/python')
# 注册
App.register(idx, py)
@idx.get(r'^/{string}$')
@idx.route(r'^/{id:int}$', 'GET', 'PAtCh')
def indexhandler(request):
print(request.groups)
print(request.groupdict)
if hasattr(request.groupdict, 'id'):
return f'<h1>北京欢迎你{request.groupdict.id}. brinnatt.com</h1>'
elif hasattr(request.groupdict, 'string'):
return f'<h1>北京欢迎你{request.groupdict.string}. brinnatt.com</h1>'
@py.get(r'^/{string}$')
@py.route(r'^/{id:}$', 'POst', 'puT')
def pythonhandler(request):
res = Response()
res.charset = 'utf-8'
res.body = '<h1>Welcome to brinnatt Python</h1>'.encode()
return res
if __name__ == '__main__':
ip = '127.0.0.1'
port = 9999
server = make_server(ip, port, App())
try:
server.serve_forever() # server.handle_request() 一次
except KeyboardInterrupt:
server.shutdown()
server.server_close()如果要增加对捕获数据的类型,使用 re.sub() 就不行了。重写 prase 函数,如下:
def parse(src: str):
start = 0
repl = ''
types = {}
matchers = regex.finditer(src)
for i, matcher in enumerate(matchers):
name = matcher.group(1)
t = matcher.group(2)
types[name] = TYPECAST.get(matcher.group(2), str)
repl += src[start:matcher.start()] # 拼接分组前
tmp = '/(?P<{}>{})'.format(matcher.group(1),
TYPEPATTERNS.get(matcher.group(2), TYPEPATTERNS['str'])
)
repl += tmp # 替换
start = matcher.end() # 移动
else:
repl += src[start:] # 拼接分组后的内容
return repl, types由此,重新修改源码:
from webob import Response, Request
from webob.dec import wsgify
from wsgiref.simple_server import make_server
from webob.exc import HTTPNotFound
import re
class AttrDict:
def __init__(self, d: dict):
self.__dict__.update(d if isinstance(d, dict) else {})
def __setattr__(self, key, value):
# 不允许修改属性
raise NotImplementedError
def __repr__(self):
return "<AttrDict {}>".format(self.__dict__)
def __len__(self):
return len(self.__dict__)
class Router:
# 正则转换
__regex = re.compile(r'/{([^{}:]+):?([^{}:]*)}')
# 类型字符串映射到正则表达式
TYPEPATTERNS = {
'str': r'[^/]+',
'word': r'\w+',
'int': r'[+-]?\d+',
'float': r'[+-]?\d+\.\d+', # 严苛的要求必须是 15.6这样的形式
'any': r'.+'
}
TYPECAST = {
'str': str,
'word': str,
'int': int,
'float': float,
'any': str
}
def __parse(self, src: str):
start = 0
repl = ''
types = {}
matchers = self.__regex.finditer(src)
for i, matcher in enumerate(matchers):
name = matcher.group(1)
t = matcher.group(2)
types[name] = self.TYPECAST.get(matcher.group(2), str)
repl += src[start:matcher.start()] # 拼接分组前
tmp = '/(?P<{}>{})'.format(
matcher.group(1),
self.TYPEPATTERNS.get(matcher.group(2), self.TYPEPATTERNS['str'])
)
repl += tmp # 替换
start = matcher.end() # 移动
else:
repl += src[start:] # 拼接分组后的内容
return repl, types
# 实例
def __init__(self, prefix: str = ''):
self.__prefix = prefix.rstrip('/\\') # 前缀,例如/product
self.__routetable = [] # 存四元组,列表,有序的
# 注册路由,装饰器
def route(self, rule, *methods):
def wrapper(handler):
# /student/{name:str}/xxx/{id:int} =>
# '/student/(?P<name>[^/]+)/xxx/(?P<id>[+-]?\\d+)'
pattern, trans = self.__parse(rule) # 用户输入规则转换为正则表达式
self.__routetable.append(
(tuple(map(lambda x: x.upper(), methods)),
re.compile(pattern), # 用户输入规则转换为正则表达式并编译
trans,
handler)
) # (方法元组,预编译正则对象,处理函数)
return handler
return wrapper
def get(self, pattern):
return self.route(pattern, 'GET')
def post(self, pattern):
return self.route(pattern, 'POST')
def head(self, pattern):
return self.route(pattern, 'HEAD')
def match(self, request: Request):
# 必须先匹配前缀
if not request.path.startswith(self.__prefix):
return None
# 前缀匹配,说明就必须这个Router实例处理,后续匹配不上,依然返回None
for methods, pattern, trans, handler in self.__routetable:
# not methods表示一个方法都没有定义,就是支持全部方法
if not methods or request.method.upper() in methods:
# 前提已经是以__prefix开头了,可以replace,去掉prefix剩下的才是正则表达式需要匹配的路径
matcher = pattern.match(request.path.replace(self.__prefix, '', 1))
if matcher: # 正则匹配
newdict = {}
for k, v in matcher.groupdict().items(): # 命名分组组成的字典
newdict[k] = trans[k](v)
# 动态为request增加属性
request.vars = AttrDict(newdict) # 属性化
return handler(request)
class App:
__ROUTERS = [] # 存储所有一级Router对象
# 注册
@classmethod
def register(cls, *routers: Router):
for router in routers:
cls.__ROUTERS.append(router)
@wsgify
def __call__(self, request: Request):
# 遍历__ROUTERS,调用Router实例的match方法,看谁匹配
for router in self.__ROUTERS:
response = router.match(request)
if response: # 匹配返回非None的Router对象
return response # 匹配则立即返回
raise HTTPNotFound('<h1>你访问的页面被外星人劫持了</h1>')
# 创建Router对象
idx = Router()
py = Router('/python')
# 注册
App.register(idx, py)
@idx.get(r'^/{string}$')
@idx.route(r'^/{id:int}$', 'GET', 'PAtCh')
def indexhandler(request):
if hasattr(request.vars, 'id'):
print(request.vars.id)
return f'<h1>北京欢迎你{request.vars.id}. brinnatt.com</h1>'
elif hasattr(request.vars, 'string'):
print(request.vars.string)
return f'<h1>北京欢迎你{request.vars.string}. brinnatt.com</h1>'
else:
raise NotImplemented('没有实现')
@py.get(r'^/{string}$')
@py.route(r'^/{id:}$', 'POst', 'puT')
def pythonhandler(request):
res = Response()
res.charset = 'utf-8'
res.body = '<h1>Welcome to brinnatt Python</h1>'.encode()
return res
if __name__ == '__main__':
ip = '127.0.0.1'
port = 9999
server = make_server(ip, port, App())
try:
server.serve_forever() # server.handle_request() 一次
except KeyboardInterrupt:
server.shutdown()
server.server_close()Application 中,可以使用字典保存所有 Router 实例。因为每一个 Router 实例的前缀不同,完全可以使用前缀为 key,Router 实例为 value 组成字典。
这样,以后在 __call__ 方法中,就不需要遍历列表了,只需要提取 request 的 path 的前缀就可以和字典的 key 匹配了,这样提高了效率。
目前这么做的原因是一级目录本身不是很多,就几个,所以不用字典也可以。
2.5.6、框架处理流程
客户端发来 HTTP 请求,被 WSGI 服务器处理后传递给 App 的 __call__。
App 中遍历已注册的 Routers,Routers 的 match 来判断是不是自己能处理,前缀匹配,就看注册的规则(当然规则被装饰器已经转换成了命名分组的正则表达式了)。
如果由某一个注册的正则表达式匹配,就把获取的参数放到 request 中,并调用注册时映射的 handler 给它传入 request。
handler 处理后,返回 response。App 中拿到这个 response 的数据,返回给最初的 wsgi。
如果 handler 返回仅仅是数据,将这些数据填入一个 HTML 中,将新生成的 HTML 字符串返回客户端,这就是网页。
这种技术就是模板技术。
2.5.7、模板
目前在框架中返回的是字符串,这些字符串返回时会被 webob 包装成 Response 对象,这些就是 HTTP 响应的正文。
这种方式有一个问题,就是数据和 HTML 混合在一起,也就是数据和数据的格式混在了一起。能否将数据和格式分离?
思路:
request 请求被 handler 处理后得到数据,设计一个 HTML 网页,其中设置一些特殊的字符,将数据插入到这个 HTML 网页中指定的位置,生成新的 HTML,返回浏览器端。
设计首页 HTML 模板 index.html。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>www.brinnatt.com</title>
</head>
<body>
显示数据<br>
{{id}} {{name}} {{age}}
</body>
</html>在网页中使用双花括号来表示占位符, 例如 {id},以后只需要找到这个位置,从数据中找到对应名称的数据替换即可。
为此,提供一个字典 'id':5, 'name':'tom', 'age':20,将这些数据插入对应的占位符中。
import re
from io import StringIO, BytesIO
d = {'id': 5, 'name': 'tom', 'age': 20}
class Template:
_pattern = '{{([a-zA-Z0-9_]+)}}'
regex = re.compile(_pattern)
@classmethod
def render(cls, template, data: dict):
html = StringIO()
with open(template, encoding='utf-8') as f:
for line in f:
start = 0
newline = ''
for matcher in cls.regex.finditer(line):
newline += line[start:matcher.start()]
print(matcher, matcher.group(1))
key = matcher.group(1)
tmp = data.get(key, '')
newline += str(tmp)
start = matcher.end()
else:
newline += line[start:]
html.write(newline)
print(html.getvalue())
html.close()
filename = 'index.html'
Template.render(filename, d)2.5.8、jinja2
基于 Python 的模板引擎。设计思想来自 Django 的模板引擎,和其非常相似。
官网:https://jinja.palletsprojects.com/en/3.1.x/
pip install jinja2
pip install MarkupSafe模板构建:
在当前项目下,新建包 webarch,其下新建一个目录 templates,该目录下新建一个 HTML 模板文件 index.html。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>www.brinnatt.com</title>
</head>
<body>
显示数据<br>
<ul>
{% for id,name,age in userlist %}
<li>{{loop.index}} {{id}}, {{name}}, {{age}}</li>
{% endfor %}
</ul>
总共{{usercount}}人
</body>
</html>加载模板代码如下:
from jinja2 import Environment, PackageLoader, FileSystemLoader
env = Environment(loader=PackageLoader('webarch', 'templates')) # 包加载器
# env = Environment(loader=FileSystemLoader('webarch/templates')) # 文件系统加载器
template = env.get_template('index.html') # 搜索模块
userlist = [
(3, 'tom', 20),
(5, 'jerry', 16),
(6, 'sam', 23),
(8, 'kevin', 18)
]
d = {'userlist': userlist, 'usercount': len(userlist)}
print(template.render(**d))提供模板模块 template.py:
from jinja2 import Environment, PackageLoader, FileSystemLoader
env = Environment(loader=PackageLoader('webarch', 'templates')) # 包加载器
# env = Environment(loader=FileSystemLoader('webarch/templates')) # 文件系统加载器
def render(name, data: dict):
"""
模板渲染
:param name: 去模板目录搜索此模板名的文件
:param data: 字典
:return: HTML字符串
"""
template = env.get_template(name) # 搜索模块index.html
return template.render(**data)代码中增加:
# 创建Router对象
idx = Router()
py = Router('/python')
user = Router('/user')
# 注册
App.register(idx, py)
App.register(user)
@user.get(r'^/?$')
def userhandler(request):
userlist = [
(3, 'tom', 20),
(5, 'jerry', 16),
(6, 'sam', 23),
(8, 'kevin', 18)
]
d = {'userlist': userlist, 'usercount': len(userlist)}
return render('index.html', d)2.5.9、模块化
将所有代码组织成包和模块。
.
├── app.py
└── webarch
├── __init__.py
├── template.py
├── templates
│ └── index.html
└── web.py包 webarch:
-
template.py 模块移入此包。
-
新建 web.py 模块,将 AttrDict、Router、App 类放入其中。
-
将路由定义、注册代码、handler 定义挪入
webarch/__init__.py中。 -
在项目根目录下,建一个 app.py,里面放入启动 server 的代码
2.5.10、拦截器 interceptor
拦截器,就是要在请求处理环节的某处加入处理,有可能是中断后续的处理。
根据拦截点不同,分为:
-
请求时拦截
-
响应时拦截
根据影响面分为:
-
全局拦截
在 App 中拦截
-
局部拦截
在 Router 中拦截
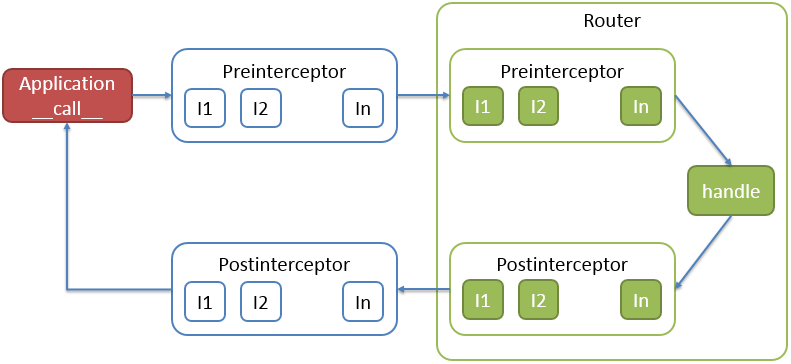
拦截器可以是多个,多个拦截器执行是有顺序的。
数据 response 前执行的命名为 preinterceptor,之后的命名为 postinterceptor。
加入拦截器功能的方式:
-
App 和 Router 类直接加入
把拦截器的相关方法、属性分别添加到相关类中。
实现简单。
-
Mixin
App 和 Router 类都需要这个拦截器功能,这两个类没有什么关系,可以使用 Mixin 方式,将属性、方法组合进来。
但是,App 类拦截器适合使用第二种,但是 Router 的拦截器是每个实例不一样的,所以使用第一种方式实现。
拦截函数 fn 的设计:
fn 不能影响数据继续向下一级的传递,也就是它是 “透明” 的。
handle 之前,函数签名应该如下:
def fn(request:Request) -> Request:
pass引入 app,是为了以后从 Application 上获取一些全局信息。
handle 执行之后,有了 response 对象,所以函数签名应该如下:
def fn(request:Request, response:Response) -> Response:
pass拦截器代码实现,见本文最后的完整代码。
2.5.10.1、IP 拦截
/python 只允许 192 开头的 IP 访问:
# 创建Router对象
idx = Router()
py = Router('/python')
user = Router('/user')
# 注册
App.register(idx, py)
App.register(user)
def ip(request:Request):
print(request.remote_addr, '~~~~~~~~~~~~~~~')
print(type(request.remote_addr))
if request.remote_addr.startswith('192.'):
return request
else:
return None
py.register_preinterceptor(ip)2.5.11、Json 支持
webob.response.Response 支持 json,如下:
@py.get(r'^/{string}$')
@py.route(r'^/{id:}$', 'POst', 'puT')
def pythonhandler(request):
userlist = [
(3, 'tom', 20),
(5, 'jerry', 16),
(6, 'sam', 23),
(8, 'kevin', 18)
]
d = {'userlist': userlist, 'usercount': len(userlist)}
res = Response(json=d)
return res测试 http://127.0.0.1:9999/python/123,返回 "userlist":[[3,"tom",20],[5,"jerry",16],[6,"sam",23],[8,"kevin",18]],"usercount":4
2.5.12、总结
- 熟悉WSGI的编程接口
- 强化模块化、类封装的思想
- 增强分析业务的能力
这个框架基本具备了 WSGI WEB 框架的基本功能,其他框架都类似。权限验证、SQL注入检测的功能使用拦截器实现。
2.5.13、完整代码
webarch/__init__.py
from .web import Router, App
from .template import render
from webob import Response, Request
# 创建Router对象
idx = Router()
py = Router('/python')
user = Router('/user')
# 注册
App.register(idx, py)
App.register(user)
# ip拦截
def ip(request: Request):
print(request.remote_addr, '~~~~~~~~~~~~~~~')
print(type(request.remote_addr))
if request.remote_addr.startswith('192.168.187'):
return request
else:
return None # 返回None将截断请求
py.register_preinterceptor(ip)
@user.get(r'^/?$')
def userhandler(request):
userlist = [
(3, 'tom', 20),
(5, 'jerry', 16),
(6, 'sam', 23),
(8, 'kevin', 18)
]
d = {'userlist': userlist, 'usercount': len(userlist)}
return render('index.html', d)
# @idx.get(r'^/{string}$')
@idx.route(r'^/{id:int}$', 'GET', 'PAtCh')
def indexhandler(request):
if hasattr(request.vars, 'id'):
print(request.vars.id)
return f'<h1>北京欢迎你{request.vars.id}. brinnatt.com</h1>'
elif hasattr(request.vars, 'string'):
print(request.vars.string)
return f'<h1>北京欢迎你{request.vars.string}. brinnatt.com</h1>'
else:
raise NotImplemented('没有实现')
@py.route(r'^/{id:}$', 'POst', 'puT')
def pythonhandler(request):
userlist = [
(3, 'tom', 20),
(5, 'jerry', 16),
(6, 'sam', 23),
(8, 'kevin', 18)
]
d = {'userlist': userlist, 'usercount': len(userlist)}
res = Response(json=d)
return reswebarch/web.py
from webob import Request
from webob.exc import HTTPNotFound
from webob.dec import wsgify
import re
class AttrDict:
def __init__(self, d: dict):
self.__dict__.update(d if isinstance(d, dict) else {})
def __setattr__(self, key, value):
# 不允许修改属性
raise NotImplementedError
def __repr__(self):
return "<AttrDict {}>".format(self.__dict__)
def __len__(self):
return len(self.__dict__)
class Router:
# 正则转换
__regex = re.compile(r'/{([^{}:]+):?([^{}:]*)}')
# 类型字符串映射到正则表达式
TYPEPATTERNS = {
'str': r'[^/]+',
'word': r'\w+',
'int': r'[+-]?\d+',
'float': r'[+-]?\d+\.\d+', # 严苛的要求必须是 15.6这样的形式
'any': r'.+'
}
TYPECAST = {
'str': str,
'word': str,
'int': int,
'float': float,
'any': str
}
def __parse(self, src: str):
start = 0
repl = ''
types = {}
matchers = self.__regex.finditer(src)
for i, matcher in enumerate(matchers):
name = matcher.group(1)
types[name] = self.TYPECAST.get(matcher.group(2), str)
repl += src[start:matcher.start()] # 拼接分组前
tmp = '/(?P<{}>{})'.format(
matcher.group(1),
self.TYPEPATTERNS.get(matcher.group(2), self.TYPEPATTERNS['str'])
)
repl += tmp # 替换
start = matcher.end() # 移动
else:
repl += src[start:] # 拼接分组后的内容
return repl, types
# 实例
def __init__(self, prefix: str = ''):
self.__prefix = prefix.rstrip('/\\') # 前缀,例如/product
self.__routetable = [] # 存四元组,列表,有序的
# 拦截器
self.pre_interceptor = []
self.post_interceptor = []
# 拦截器注册函数
def register_preinterceptor(self, fn):
self.pre_interceptor.append(fn)
return fn
def register_postinterceptor(self, fn):
self.post_interceptor.append(fn)
return fn
# 注册路由,装饰器
def route(self, rule, *methods):
def wrapper(handler):
# /student/{name:str}/xxx/{id:int} =>
# '/student/(?P<name>[^/]+)/xxx/(?P<id>[+-]?\\d+)'
pattern, trans = self.__parse(rule) # 用户输入规则转换为正则表达式
self.__routetable.append(
(tuple(map(lambda x: x.upper(), methods)),
re.compile(pattern), # 用户输入规则转换为正则表达式并编译
trans,
handler)
) # (方法元组,预编译正则对象,处理函数)
return handler
return wrapper
def get(self, pattern):
return self.route(pattern, 'GET')
def post(self, pattern):
return self.route(pattern, 'POST')
def head(self, pattern):
return self.route(pattern, 'HEAD')
def match(self, request: Request):
# 必须先匹配前缀
if not request.path.startswith(self.__prefix):
return None
# 是此Router的请求,开始拦截,处理request
for fn in self.pre_interceptor:
request = fn(request)
if not request:
return None # 请求为None将不再向后传递,截止
# 前缀匹配,说明就必须这个Router实例处理,后续匹配不上,依然返回None
for methods, pattern, trans, handler in self.__routetable:
# not methods表示一个方法都没有定义,就是支持全部方法
if not methods or request.method.upper() in methods:
# 前提已经是以__prefix开头了,可以replace,去掉prefix剩下的才是正则表达式需要匹配的路径
matcher = pattern.match(request.path.replace(self.__prefix, '', 1))
if matcher: # 正则匹配
newdict = {}
for k, v in matcher.groupdict().items(): # 命名分组组成的字典
newdict[k] = trans[k](v)
# 动态为request增加属性
request.vars = AttrDict(newdict) # 属性化
response = handler(request)
# 依次拦截,处理响应
for fn in self.post_interceptor:
response = fn(request, response)
return response
class App:
__ROUTERS = [] # 存储所有一级Router对象
# 全局拦截器
PRE_INTERCEPTOR = []
POST_INTERCEPTOR = []
# 全局拦截器注册函数
@classmethod
def register_preinterceptor(cls, fn):
cls.PRE_INTERCEPTOR.append(fn)
return fn
@classmethod
def register_postinterceptor(cls, fn):
cls.POST_INTERCEPTOR.append(fn)
return fn
# 注册路由
@classmethod
def register(cls, *routers: Router):
for router in routers:
cls.__ROUTERS.append(router)
@wsgify
def __call__(self, request: Request):
# 全局拦截请求
for fn in self.PRE_INTERCEPTOR:
request = fn(request)
# 遍历__ROUTERS,调用Router实例的match方法,看谁匹配
for router in self.__ROUTERS:
response = router.match(request)
# 全局拦截响应
for fn in self.POST_INTERCEPTOR:
response = fn(request, response)
if response: # 匹配返回非None的Router对象
return response # 匹配则立即返回
raise HTTPNotFound('<h1>你访问的页面被外星人劫持了</h1>')webarch/template.py
from jinja2 import Environment, PackageLoader
from jinja2 import FileSystemLoader
# env = Environment(loader=PackageLoader('webarch', 'templates')) # 包加载器
env = Environment(loader=FileSystemLoader('webarch/templates')) # 文件系统加载器
def render(name, data: dict):
"""
模板渲染
:param name: 去模板目录搜索此模板名的文件
:param data: 字典
:return: HTML字符串
"""
template = env.get_template(name) # 搜索模块index.html
return template.render(**data)app.py
from wsgiref.simple_server import make_server
from webarch.web import App
if __name__ == '__main__':
ip = '192.168.187.1'
port = 9999
server = make_server(ip, port, App())
try:
server.serve_forever() # server.handle_request() 一次
except KeyboardInterrupt:
server.shutdown()
server.server_close()2.5.14、发布
setup.py
from distutils.core import setup
import glob
# 导入setup函数并传参
setup(name='webarch',
version='0.1.0',
description='Python WSGI WEB Framework',
author='Brinnatt',
author_email='brinnatt@gmail.com',
url='https://www.brinnatt.com',
packages=['webarch'],
# data_files=['webarch/templates/index.html']
data_files=glob.glob('webarch/templates/*') # 返回列表
)
# name名字
# version 版本
# packages=[] 打包列表,
# packages=['webarch'],指定webarch,就会把webarch所有的非目录子模块打包
# description 描述信息
# author 作者
# author_email 作者邮件
# url 包的主页,可以不写
# data_files 配置文件、图片等文件列表。参看distutils.command.sdist.sdist#add_defaults# 打包
$ python setup.py sdist
# 安装
$ pip install webarch-0.1.0.zip