
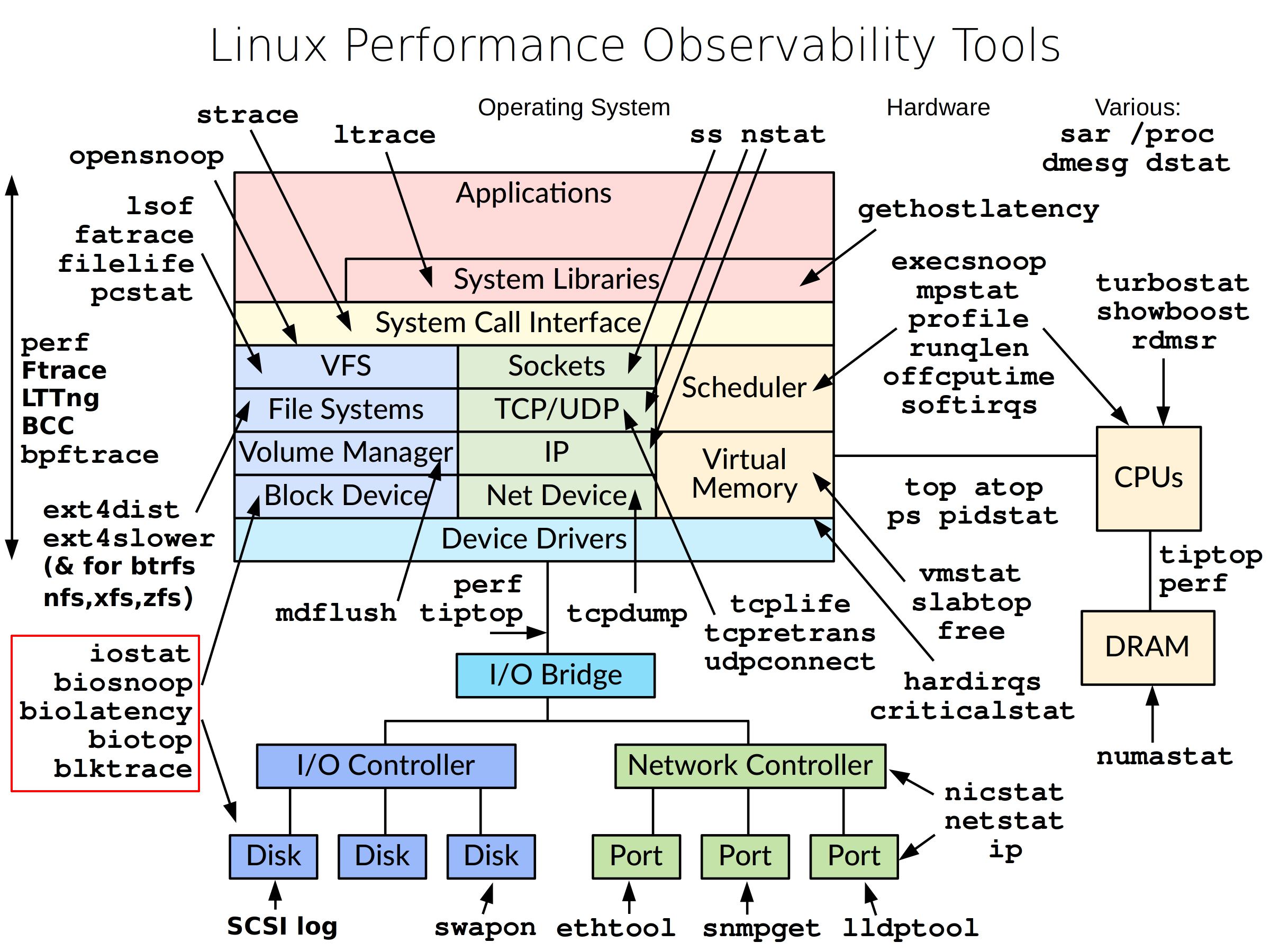
第 10 章 Linux 系统资源监控
Linux 操作系统实际上可以看作是一个资源管家,那么管理哪些资源呢,当然是底层硬件资源,比如 CPU、内存、硬盘、显卡、网卡以及各种扩展外设。
这些硬件设备如何被使用、使用情况如何都由 Linux 操作系统来决定,实际上这是一个非常复杂的过程。经过历史演变,Linux 内核功能越来越多,也越来越强大,我们也不得不更加努力地学习。本章节会介绍如何查看这些硬件资源,以便通过数据分析更加合理地分配资源。
10.1、伪文件系统
在 Linux 中查看各种状态,其实质是查看内核中相关进程的数据结构中的项,通过工具将其格式化后输出出来。
但是内核的数据是绝对不能随意查看或更改的,至少不能直接去修改。所以,在 linux 上出现了伪文件系统 /proc,它是内核中各属性或状态向外提供访问和修改的接口。
在 /proc 下,记录了内核自己的数据信息,各进程独立的数据信息,统计信息等。绝大多数文件都是只读不可改的,即使对 root 也一样,但 /proc/sys 除外,为何如此稍后解释。
[root@computer1 ~]# ls /proc/
1 14 210 2444 2898 3152411 3219322 365 49 916
10 140 211 2445042 29 3157718 3219761 366 49308 918
101 142 213 245 290 316 3219763 3671528 49309 92
1010 143 214 246 2901 3161233 3219965 369 49487 922
1011 144 215 247 2904 3161412 3219966 37 497 924
1012 145 2157892 2477 291 3161628 322 370 498 93
102 147 216 2479 292 3162463 3220776 3707987 499 939
1026 148 2166228 2483 293 3167151 3220973 3708052 50 95
103 1484289 2166605 249 2933337 3167349 3220974 371 500 965894
1030 149 2172873 2491 2942473 3167804 3221784 37148 501 965940
1032 15 2172952 2492920 2943058 3167994 3222825 372 502 97
104 150 2174302 2493740 2943701 3168644 3222954 373 503 977
1044 152 218 2498 295 3169031 3223256 374 504 98
1045 153 2187021 2499 296 3169645 3223259 375 505 99
1046 154 2187301 25 2964786 317 3223494 376 506 acpi
1057 155 2187350 250 297 3170504 323 37620 507 buddyinfo
106 157 22 2507 2974466 3170660 324 377 508 bus
107 158 220 2507753 2975052 3170860 326 3825 509 cgroups
108 159 2209896 2507840 2976725 3172803 327 3829 51 cmdline
109 16 221 251 2977555 3179791 328 3830 510 config.gz
11 160 2218775 2514755 298 318 329 3831 511 consoles
111 162 222 2514917 2997448 3180167 3308060 3832 516 cpuinfo
112 163 224 252 2997861 3180374 331 3833 52 crypto
113 164 2247991 2522146 3 3180601 331292 3834 54 devices
114 1643190 225 2527 30 3181420 3313620 3835 56 diskstats
11513 1643234 226 254 300 3182232 3313748 3836 57 driver
116 165 2261 255 3000087 3183478 332 383638 58 execdomains
117 167 2262 256 302 3184083 333 3837 584745 fb
118 168 2263 257 3020071 3184924 334 3838 586435 filesystems-
其中数字命名的目录对应的是各进程的 pid 号,其内的文件记录的都是该进程当前的数据信息,且都是只读的。
-
例如记录命令信息的 cmdline 文件,进程使用哪颗 cpu 信息 cpuset,进程占用内存的信息 mem 文件,进程 IO 信息 io 文件等其他各种信息文件。
[root@computer1 ~]# ls /proc/62923/ attr cpuset io mounts oom_score_adj setgroups syscall auxv cwd limits mountstats pagemap smaps task cgroup environ loginuid net personality smaps_rollup timers clear_refs exe map_files ns projid_map stack timerslack_ns cmdline fd maps numa_maps root stat uid_map comm fdinfo mem oom_adj schedstat statm wchan coredump_filter gid_map mountinfo oom_score sessionid status [root@computer1 ~]#
非数字命名的目录各有用途,例如 bus 表示总线信息,driver 表示驱动信息,fs 表示文件系统特殊信息,net 表示网络信息,tty 表示跟物理终端有关的信息,最特殊的两个是 /proc/self 和 /proc/sys。
-
先说 /proc/self 目录,它表示的是当前正在访问 /proc 目录的进程,因为 /proc 目录是内核数据向外记录的接口,所以当前访问 /proc 目录的进程表示的就是当前 cpu 正在执行的进程。
如果执行 cat /proc/self/cmdline,会发现其结果总是该命令本身,因为 cat 是手动敲入的命令,它是重要性进程,cpu 会立即执行该命令。
-
再说 /proc/sys 这个目录,该目录是为管理员提供用来修改内核运行参数的,所以该目录中的文件对 root 都是可写的,例如管理数据包转发功能的 /proc/sys/net/ipv4/ip_forward 文件。
使用 sysctl 命令修改内核运行参数,其本质也是修改 /proc/sys 目录中的文件。
10.2、查看进程信息
10.2.1、pstree 命令
pstree 命令将以树的形式显示进程信息,默认树的分支是收拢的,也不显示 pid,要显示这些信息需要指定对应的选项。
pstree [-a] [-c] [-h] [-l] [-p] [pid]
选项说明:
-a:显示进程的命令行
-c:展开分支
-h:高亮当前正在运行的进程及其父进程
-p:显示进程pid,此选项也将展开分支
-l:允许显示长格式进程。默认在显示结果中超过132个字符时将截断后面的字符。[root@computer1 ~]# pstree -h
systemd─┬─3*[agetty]
├─auditd───{auditd}
├─chronyd
├─collectdmon───collectd───11*[{collectd}]
├─containerd─┬─containerd-shim─┬─openresty───4*[openresty]
│ │ └─11*[{containerd-shim}]
│ ├─containerd-shim─┬─npm─┬─sh───node───10*[{node}]
│ │ │ └─10*[{npm}]
│ │ └─11*[{containerd-shim}]
│ └─76*[{containerd}]
├─crond
├─dbus-daemon
├─2*[dnsmasq]
├─dockerd───74*[{dockerd}]
├─etcd───76*[{etcd}]
├─gssproxy───5*[{gssproxy}]
├─irqbalance───{irqbalance}
├─kylin-security-───{kylin-security-}
├─libvirtd───17*[{libvirtd}]
├─2*[lighttpd]
├─mdadm
......10.2.2、ps 命令
ps 命令查看当前这一刻的进程信息,注意查看的是静态进程信息,要查看随时刷新的动态进程信息(如windows的进程管理器那样,每秒刷新一次),使用 top 或 htop 命令。
这个命令的 man 文档及其复杂,它同时支持 3 种类型的选项:GUN/BSD/UNIX,不同类型的选项其展示的信息格式不一样。有些加了 "-" 的是 SysV 风格的选项,不加 "-" 的是 BSD 选项,加不加 "-" 它们的意义是不一样的,例如 ps aux 和 ps -aux 是不同的。
其实只需掌握少数几个选项即可,关键的是要了解 ps 显示出的进程信息中每一列代表什么属性。
对于 BSD 风格的选项,只需知道一个用法 ps aux 足以:
- 选项 "a" 表示列出依赖于终端的进程
- 选项 "x" 表示列出不依赖于终端的进程,所以两者结合就表示列出所有进程
- 选项 "u" 表示展现的进程信息是以用户为导向的,不用管它什么是以用户为导向,用 ps aux 就没错。
[root@computer1 ~]# ps aux | tail
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 3819329 0.0 0.0 0 0 ? I 20:35 0:00 [kworker/25:3-cgroup_destroy]
root 3819915 0.0 0.0 0 0 ? I 20:35 0:00 [kworker/0:2]
root 3820740 0.0 0.0 0 0 ? I 20:36 0:00 [kworker/24:1-cgroup_pidlist_destroy]
root 3820741 0.0 0.0 0 0 ? I 20:36 0:00 [kworker/24:2-cgroup_pidlist_destroy]
root 3822389 0.0 0.0 0 0 ? I 20:37 0:00 [kworker/27:0-cgroup_pidlist_destroy]
root 3822390 0.0 0.0 0 0 ? I 20:37 0:00 [kworker/27:3-cgroup_destroy]
root 3822812 0.0 0.0 0 0 ? I 20:37 0:00 [kworker/14:0-mm_percpu_wq]
root 3822878 0.0 0.0 218816 6272 pts/16 R+ 20:37 0:00 ps aux
root 3822879 0.0 0.0 213056 960 pts/16 S+ 20:37 0:00 tail
nobody 4119590 0.0 0.0 5312 1536 ? S 7月12 0:00 /usr/local/zstack/dnsmasq --conf-file=/var/lib/zstack/dnsmasq/br_bond2_4002_533d732ae8fa49e89b24b384cb869a71/dnsmasq.conf
[root@computer1 ~]#-
%CPU:表示 CPU 占用百分比,注意,CPU 的衡量方式是占用时间,所以百分比的计算方式是 "进程占用 cpu 时间 / cpu 总时间",而不是 cpu 工作强度的状态。
-
%MEM:表示各进程所占物理内存百分比。
-
VSZ:表示各进程占用的虚拟内存,也就是其在线性地址空间中实际占用的内存。单位为 kb。
-
RSS:表示各进程占用的实际物理内存。单位为 Kb。
-
TTY:表示属于哪个终端的进程,"?" 表示不依赖于终端的进程。
-
STAT:进程所处的状态。
- D:不可中断睡眠
- R:运行中或等待队列中的进程(running/runnable)
- S:可中断睡眠
- T:进程处于 stopped 状态
- Z:僵尸进程
对于 BSD 风格的 ps 选项,进程的状态还会显示下面几个组合信息。
- <:高优先级进程
- N:低优先级进程
- L:该进程在内存中有被锁定的页
- s:表示该进程是 session leader,即进程组的首进程。例如管道左边的进程,shell 脚本中的 shell 进程
- l:表示该进程是一个线程
- +:表示是前端进程。前端进程一般来说都是依赖于终端的
-
START:表示进程是何时被创建的
-
TIME:表示各进程占用的 CPU 时间
-
COMMAND:表示进程的命令行。如果是内核线程,则使用方括号 "[]" 包围
注意到了没,ps aux 没有显示出 ppid。
另外常用的 ps 选项是 ps -elf。其中 "-e" 表示输出全部进程信息,"-f" 和 "-l" 分别表示全格式输出和长格式输出。全格式会输出 cmd 的全部参数。
[root@computer1 ~]# ps -elf | tail
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
1 I root 3850806 2 0 80 0 - 0 worker 20:48 ? 00:00:00 [kworker/48:0-cgroup_destroy]
1 I root 3852226 2 0 80 0 - 0 worker 20:49 ? 00:00:00 [kworker/51:2-cgroup_destroy]
1 I root 3854390 2 0 80 0 - 0 worker 20:50 ? 00:00:00 [kworker/0:0]
1 I root 3855361 2 0 80 0 - 0 worker 20:50 ? 00:00:00 [kworker/53:0]
1 I root 3855430 2 0 80 0 - 0 worker 20:50 ? 00:00:00 [kworker/u128:0-bond1]
1 I root 3857251 2 0 80 0 - 0 worker 20:51 ? 00:00:00 [kworker/54:1]
0 S root 3857779 339964 0 80 0 - 78 do_wai 20:51 ? 00:00:00 /bin/bash
0 R root 3857782 3809064 0 80 0 - 3419 - 20:51 pts/16 00:00:00 ps -elf
0 S root 3857783 3809064 0 80 0 - 3329 pipe_w 20:51 pts/16 00:00:00 tail
5 S nobody 4119590 1 0 80 0 - 83 do_sys 7月12 ? 00:00:00 /usr/local/zstack/dnsmasq --conf-file=/var/lib/zstack/dnsmasq/br_bond2_4002_533d732ae8fa49e89b24b384cb869a71/dnsmasq.conf
[root@computer1 ~]#- F:程序的标志位。0 表示该程序只有普通权限,4 表示具有 root 超级管理员权限,1 表示该进程被创建的时候只进行了 fork,没有进行 exec
- S:进程的状态位,注意 ps 选项加了 "-" 的是非 BSD 风格选项,不会有 "s" "<" "N" "+" 等的状态标识位
- C:CPU 的百分比,注意衡量方式是时间
- PRI:进程的优先级,值越小,优先级越高,越早被调度类选中运行
- NI:进程的 NICE 值,值为 -20 到 19,影响优先级的方式是 PRI(new)=PRI(old)+NI,所以 NI 为负数的时候,越小将导致进程优先级越高。
- 但要注意,NICE 值只能影响非实时进程。
- ADDR:进程在物理内存中哪个地方。
- SZ:进程占用的实际物理内存
- WCHAN:若进程处于睡眠状态,将显示其对应内核线程的名称,若进程为 R 状态,则显示 "-"
10.2.3、ps 后 grep 问题
在 ps 后加上 grep 筛选目标进程时,总会发现 grep 自身进程也被显示出来。
[root@computer1 ~]# ps aux | grep "crond"
root 2483 0.0 0.0 216128 4544 ? Ss 4月27 0:12 /usr/sbin/crond -n
root 3894948 0.0 0.0 214080 1536 pts/16 S+ 21:07 0:00 grep crond
[root@computer1 ~]# 先解释下为何会如此。
- 管道是 bash 创建的,bash 创建管道后 fork 两个子进程,然后两子进程各自 exec 加载 ps 程序和 grep 程序,exec 之后这两个子进程就称为 ps 进程和 grep 进程,所以 ps 和 grep 进程几乎可以认为是同时出现的。
- 尽管 ps 进程作为管道的首进程(进程组首进程)它是先出现的,但是在 ps 出现之前确实两个进程都已经 fork 完成了。也就是说,管道左右两端的进程是同时被创建的(不考虑父进程创建进程消耗的那点时间),但数据传输是有先后顺序的,左边先传,右边后收。
要将 grep 自身进程排除在结果之外也简单:
[root@computer1 ~]# ps aux | grep "crond" | grep -v "grep"
root 2483 0.0 0.0 216128 4544 ? Ss 4月27 0:12 /usr/sbin/crond -n
[root@computer1 ~]#10.2.4、uptime 命令
[root@computer1 ~]# uptime
21:11:52 up 90 days, 5:40, 1 user, load average: 9.48, 7.70, 7.06
[root@computer1 ~]#- 显示当前时间,已开机运行多少时间,当前有多少用户已登录系统,以及 3 个平均负载值。
所谓负载率(load),即特定时间长度内,cpu 运行队列中的平均进程数(包括线程),一般平均每分钟每核的进程数小于 3 都认为正常,大于 5 时负载已经非常高。
在 UNIX 系统中,运行队列包括 cpu 正在执行的进程和等待 cpu 的进程(即所谓的可运行 runable)。
在 Linux 系统中,还包括不可中断睡眠态(IO等待)的进程。运行队列中每出现一个进程,load 就加 1,进程每退出运行队列,Load 就减 1。如果是多核 cpu,则还要除以核数。
举个例子:单核 cpu 上的负载值为 "1.73 0.60 7.98" 时
- 最近 1 分钟:1.73 表示平均可运行的进程数,这一分钟要一直不断地执行这 1.73 个进程。0.73个进程等待该核 cpu。
- 最近 5 分钟:平均进程数还不足 1,表示该核 cpu 在过去 5 分钟空闲了 40% 的时间。
- 最近 15 分钟:7.98 表示平均可运行的进程数,这 15 分钟要一直不断地执行这 7.98 个进程。
- 结合前 5 分钟的结果,说明前15 - 前10分钟时间间隔内,该核 cpu 的负载非常高。
如果是多核 cpu,则还要将结果除以核数。例如 4 核时,某个最近一分钟的负载值为 3.73,则意味着有 3.73 个进程在运行队列中,这些进程可被调度至 4 核中的任何一个核上运行。最近 1 分钟的负载值为 1.6,表示这一分钟内每核 cpu 都空闲 (1-1.6/4) = 60% 的时间。
所以,load 的理想值是正好等于 CPU 的核数,小于核数的时候表示 cpu 有空闲,超出核数的时候表示有进程在等待 cpu,即系统资源不足。
10.2.5、top、htop 和 iftop 命令
top 命令查看动态进程状态,默认每 5 秒刷新一次。
top选项说明:
-d:指定top刷新的时间间隔,默认是5 秒
-b:批处理模式,每次刷新分批显示
-n:指定top刷新几次就退出,可以配合-b使用
-p:指定监控的pid,指定方式为-pN1 -pN2 ...或-pN1, N2 [,...]
-u:指定要监控的用户的进程,可以是uid也可以是user_name在 top 动态模式下,按下各种键可以进行不同操作。使用 "h" 或 "?" 可以查看相关键的说明。
- 1 :(数字一)表示是否要在 top 的头部显示出多个 cpu 信息
- H :表示是否要显示线程,默认不显示
- c,S : c 表示是否要展开进程的命令行,S 表示显示的 cpu 时间是否是累积模式,cpu 累积模式下已死去的子进程 cpu 时间会累积到父进程中
- x,y :x 高亮排序的列,y 表示高亮 running 进程
- u :仅显示指定用户的进程
- n or #:设置要显示最大的进程数量
- k :杀进程
- q :退出 top
- P :以 CPU 的使用资源排序显示
- M :以 Memory 的使用资源排序显示
- N :以 PID 来排序
以下是 top 的一次结果
top - 22:14:25 up 90 days, 6:42, 1 user, load average: 8.03, 7.75, 7.47
Tasks: 684 total, 1 running, 683 sleeping, 0 stopped, 0 zombie
%Cpu(s): 7.1 us, 3.0 sy, 0.4 ni, 89.1 id, 0.0 wa, 0.3 hi, 0.2 si, 0.0 st
MiB Mem : 258904.8 total, 27806.9 free, 212285.7 used, 18812.2 buff/cache
MiB Swap: 4095.9 total, 843.4 free, 3252.6 used. 40057.7 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2741972 root 20 0 35.9g 28.2g 67264 S 106.9 11.1 6878:55 qemu-kvm
965894 root 20 0 18.4g 15.4g 49152 S 100.7 6.1 144804:03 qemu-kvm
411643 root 29 9 35.2g 32.3g 48384 S 75.2 12.8 115823:39 qemu-kvm
410344 root 20 0 10.4g 8.3g 46208 S 66.0 3.3 56623:49 qemu-kvm
2507753 root 21 1 19.4g 8.5g 66688 S 53.1 3.4 3674:36 qemu-kvm
411734 root 20 0 35.2g 31.9g 49664 S 46.9 12.6 66581:37 qemu-kvm
759742 root 20 0 20.5g 14.6g 59392 S 43.2 5.8 31980:38 qemu-kvm- 第 1 行:和 w 命令的第一行一样,也和 uptime 命令的结果一样。此行各列分别表示 "当前时间"、"已开机时长"、"当前在线用户"、"前 1、5、15 分钟平均负载率"。
- 第 2 行:分别表示总进程数、running 状态的进程数、睡眠状态的进程数、停止状态进程数、僵尸进程数。
- 第 3 行:cpu 的状况。按数字 1 可以显示所有 CPU 的情况
- us = user mode
- sy = system mode
- ni = low priority user mode (nice)(用户空间中低优先级进程的cpu占用百分比)
- id = idle task
- wa = I/O waiting
- hi = servicing IRQs(不可中断睡眠,hard interruptible)
- si = servicing soft IRQs(可中断睡眠,soft interruptible)
- st = steal (time given to other DomU instances)(被偷走的cpu时间,一般被虚拟化软件偷走)
- 第 4 - 5 行:从字面意思理解即可。
- VIRT:虚拟内存总量
- RES:实际内存总量
- SHR:共享内存量
- TIME:进程占用的 cpu 时间(若开启了时间累积模式,则此处显示的是累积时间)
top 命令虽然非常强大,但是太老了。所以有了新生代的 top 命令 htop。htop 默认没有安装,需要手动安装。
注意:我的实验环境是 arm64 架构服务器,使用的也是国产化操作系统,rpm 源没有 htop 包,可以手动下载一个 aarch64 架构的 htop 包。
[root@computer1 ~]# wget https://download-ib01.fedoraproject.org/pub/epel/7/aarch64/Packages/h/htop-2.2.0-3.el7.aarch64.rpm
--2021-07-26 22:23:16-- https://download-ib01.fedoraproject.org/pub/epel/7/aarch64/Packages/h/htop-2.2.0-3.el7.aarch64.rpm
正在解析主机 download-ib01.fedoraproject.org (download-ib01.fedoraproject.org)... 152.19.134.145, 2610:28:3090:3001:dead:beef:cafe:fed6
正在连接 download-ib01.fedoraproject.org (download-ib01.fedoraproject.org)|152.19.134.145|:443... 已连接。
已发出 HTTP 请求,正在等待回应... 200 OK
长度:103092 (101K) [application/x-rpm]
正在保存至: “htop-2.2.0-3.el7.aarch64.rpm”
htop-2.2.0-3.el7.aarch6 100%[============================>] 100.68K 129KB/s 用时 0.8s
2021-07-26 22:23:18 (129 KB/s) - 已保存 “htop-2.2.0-3.el7.aarch64.rpm” [103092/103092])
[root@computer1 ~]# rpm -ivh htop-2.2.0-3.el7.aarch64.rpm
警告:htop-2.2.0-3.el7.aarch64.rpm: 头V3 RSA/SHA256 Signature, 密钥 ID 352c64e5: NOKEY
Verifying... ################################# [100%]
准备中... ################################# [100%]
软件包 htop-2.2.0-3.el7.aarch64 已经安装
[root@computer1 ~]#
[root@computer1 ~]# htophtop 可以使用鼠标完成点击选中。其他使用方法和 top 类似,使用 h 查看各按键意义即可。
iftop 用于动态显示网络接口的数据流量。用法也很简单,按下 h 键即可获取帮助。
[root@computer1 ~]# wget https://download-ib01.fedoraproject.org/pub/epel/7/aarch64/Packages/i/iftop-1.0-0.21.pre4.el7.aarch64.rpm
--2021-07-26 22:26:27-- https://download-ib01.fedoraproject.org/pub/epel/7/aarch64/Packages/i/iftop-1.0-0.21.pre4.el7.aarch64.rpm
正在解析主机 download-ib01.fedoraproject.org (download-ib01.fedoraproject.org)... 152.19.134.145, 2610:28:3090:3001:dead:beef:cafe:fed6
正在连接 download-ib01.fedoraproject.org (download-ib01.fedoraproject.org)|152.19.134.145|:443... 已连接。
已发出 HTTP 请求,正在等待回应... 200 OK
长度:58521 (57K) [application/x-rpm]
正在保存至: “iftop-1.0-0.21.pre4.el7.aarch64.rpm”
iftop-1.0-0.21.pre4.el7 100%[============================>] 57.15K 113KB/s 用时 0.5s
2021-07-26 22:26:29 (113 KB/s) - 已保存 “iftop-1.0-0.21.pre4.el7.aarch64.rpm” [58521/58521])
[root@computer1 ~]# rpm -ivh iftop-1.0-0.21.pre4.el7.aarch64.rpm
警告:iftop-1.0-0.21.pre4.el7.aarch64.rpm: 头V3 RSA/SHA256 Signature, 密钥 ID 352c64e5: NOKEY
Verifying... ################################# [100%]
准备中... ################################# [100%]
正在升级/安装...
1:iftop-1.0-0.21.pre4.el7 ################################# [100%]
[root@computer1 ~]#
[root@computer1 ~]# iftop10.2.6、分析系统负载
根据前文 uptime 中对系统负载(system load)的描述,分析一下这个 top 的结果。
top - 22:43:43 up 90 days, 7:11, 1 user, load average: 224.02, 215.13, 115.86
Tasks: 676 total, 1 running, 675 sleeping, 0 stopped, 0 zombie
%Cpu(s): 6.6 us, 2.3 sy, 0.2 ni, 90.5 id, 0.0 wa, 0.3 hi, 0.1 si, 0.0 st
MiB Mem : 258904.8 total, 27779.5 free, 212293.6 used, 18831.8 buff/cache
MiB Swap: 4095.9 total, 843.4 free, 3252.6 used. 40048.4 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
965894 root 20 0 18.4g 15.4g 49152 S 99.3 6.1 144842:23 qemu-kvm
2741972 root 20 0 35.9g 28.2g 67264 S 94.4 11.1 6910:46 qemu-kvm
2507753 root 21 1 19.4g 8.5g 66688 S 73.8 3.4 3691:52 qemu-kvm
411643 root 29 9 35.2g 32.3g 48384 S 70.5 12.8 115845:21 qemu-kvm
411734 root 20 0 35.2g 31.9g 48000 S 60.3 12.6 66597:18 qemu-kvm
410344 root 20 0 10.4g 8.3g 46208 S 51.3 3.3 56637:55 qemu-kvm
3313620 root 20 0 19.6g 10.8g 54784 S 42.1 4.3 65953:40 qemu-kvm
759742 root 20 0 20.5g 14.6g 59392 S 40.7 5.8 31990:35 qemu-kvm
2187301 root 20 0 10.2g 5.8g 54144 S 14.6 2.3 82:58.59 qemu-kvm
3707987 root 20 0 10.7g 7.3g 50432 S 7.0 2.9 3687:12 qemu-kvm 根据 top 数据显示,load average 系统负载非常之高,最近一分钟的负载量高达 224.02,这表示这一分钟有 224.02 个进程正在运行或等待调度,如果是单核 CPU,表示这一分钟要毫不停留地执行这么多进程,如果是 8 核 CPU,表示这一分钟内平均每核心 CPU 要执行大概 30 个进程。
从 load average 上看,确实是非常繁忙的场景。但是看 CPU 的 idle 值为 90.5,说明 CPU 非常闲。为什么系统负载如此高,CPU 却如此闲?
前面解释 system load average 的时候,已经说明过可运行的(就绪态,即就绪队列的长度)、正在运行的(运行态)和不可中断睡眠(如IO等待)的进程任务都会计算到负载中。现在负载高、CPU 空闲,说明当前正在执行的任务基本不消耗 CPU 资源,大量的负载进程都在 IO 等待中。
可以从 ps 的进程状态中获取哪些进程是正在运行或运行队列中的(状态为 R),哪些进程是在不可中断睡眠中的(状态为 D)。
[root@computer1 ~]# ps -eo stat,pid,ppid,comm --no-header | grep -E "^(D|R)"
R 4141039 130875 du
R+ 4141085 3809064 ps
[root@computer1 ~]# 10.3、vmstat 命令
注意 vmstat 的第一次统计是自开机起的平均值信息,从第二次开始的统计才是指定刷新时间间隔内的资源利用信息,若不指定刷新时间间隔,则默认只显示一次统计信息。
vmstat [-d] [delay [ count]]
vmstat [-f]
选项说明:
-f:统计自开机起fork的次数。包括fork、clone、vfork的次数。但不包括exec次数。
-d:显示磁盘统计信息。
delay:刷新时间间隔,若不指定,则只统计一次信息就退出vmstat。
count:总共要统计的次数。例如,只统计一次信息。
[root@computer1 ~]# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
15 1 3328960 28476288 1216320 18014592 0 0 0 6 0 0 9 2 88 0 0
[root@computer1 ~]#- procs
- r: 等待队列中的进程数
- b: 不可中断睡眠的进程数
- Memory
- swpd: 虚拟内存使用总量
- free: 空闲内存量
- buff: buffer占用的内存量(buffer 用于缓冲)
- cache: cache 占用的内存量(cache 用于缓存)
- Swap
- si: 从磁盘加载到swap分区的数据流量,单位为 "kb/s"
- so: 从 swap 分区写到磁盘的数据流量,单位为"kb/s"
- IO
- bi: 从块设备接受到数据的速率,单位为 blocks/s
- bo: 发送数据到块设备的速率,单位为 blocks/s
- System
- in: 每秒中断数,包括时钟中断数量
- cs: 每秒上下文切换次数
- CPU:统计的是 cpu 时间百分比,具体信息和 top 的 cpu 统计列一样
- us: Time spent running non-kernel code. (user time, including nice time)
- sy: Time spent running kernel code. (system time)
- id: Time spent idle. Prior to Linux 2.5.41, this includes IO-wait time.
- wa: Time spent waiting for IO. Prior to Linux 2.5.41, included in idle.
- st: Time stolen from a virtual machine. Prior to Linux 2.6.11, unknown.
10.4、iostat 命令
iostat 主要统计磁盘或分区的整体使用情况。也可以输出 cpu 信息,甚至是 NFS 网络文件系统的信息。同 vmstat/sar 一样,第一次统计的都是自系统开机起的平均统计信息。
iostat [选项] [ device [...]| ALL ] [ interval [ count ] ]
选项:
-c: 显示 CPU 利用率报告
-d: 显示 device 利用率报告
--dec={ 0|1|2 }: 指定要使用的小数位数(0 到 2,默认值是 2)。
-h/--human: 用人类可读的格式打印大小(例如 1.0k、1.2M 等)
-k: 以 Kb/s 显示
-m: 以 mb/s 显示
-N: 显示已注册的 device mapper 名称,对于查看 LVM2 报告特别有用
-o JSON: 用 JSON 格式显示报告
-p [device|ALL]: 显示系统所有块设备及块设备分区的报告,如果指定device,则只显示device和其分区报告。
-t: 为每次报告显示增加时间戳,时间戳的格式依赖于 S_TIME_FORMAT 环境变量的值
-V: 打印版本号然后退出
-x: 显示扩展报告
-y: 如果给了interval显示多次报告,该选项可以忽略第一次报告(系统启动至今的统计)。
-z: 如果相同的期间设备没有活动的数据,iostat 会不显示设备相同的输出数据。
环境变量:iostat 会把下面的环境变量考虑进去用来增强特殊功能
POSIXLY_CORRECT: 设置这个变量传输速率将以512字节块展示而不是默认的1K块展示
S_COLORS: 设置这个变量可以使显示报告中的数据带颜色
S_COLORS_SGR: 指定颜色和其它属性用来显示报告,它的值是一个冒号分隔的功能列表,默认值为 H=31;1:I=32;22:M=35;1:N=34;1:Z=34;22.
支持的能力有:
H= SGR (Select Graphic Rendition)子字符串用于大于或等于75%的百分比值。
I= SGR子字符串用于设备名称。
M= SGR子字符串,用于百分比值在50%到75%之间。
N= SGR子串用于非零统计值。
Z= SGR子串为零值。
S_TIME_FORMAT: 如果这个变量存在并且它的值是ISO,那么当在报告标题中打印日期时,当前区域设置将被忽略。
iostat命令将使用ISO 8601格式(YYYY-MM-DD)。 选项-t显示的时间戳也符合ISO 8601格式。举例:
# iostat 为所有的CPU和设备显示系统启动至今的历史报告
# iostat -d 2 每隔2秒钟连续显示设备报告
# iostat -d 2 6 每隔2秒钟连续显示设备报告,共显示6次
# iostat -x sda sdb 2 6 为设备 sda sdb 每隔2秒钟连续显示6次扩展报告
# iostat -p sda 2 6 每隔2秒连续显示6次sda和其分区的报告[root@computer1 ~]# iostat -c
Linux 4.19.90-17.ky10.aarch64 (computer1) 2021年07月27日 _aarch64_ (64 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
9.21 0.00 2.37 0.02 0.00 88.41- %user
- 显示用户空间 CPU 使用率百分比。
- %nice
- 显示拥有 nice 值用户空间 CPU 使用率百分比。
- %system
- 显示内核空间 CPU 使用率百分比。
- %iowait
- 发生 IO 请求时,CPU 空闲等待百分比。
- %steal
- 物理 CPU 为虚拟机服务的时间所占的百分比。
- %idle
- 不算 IO 等待,CPU 完全空闲时间百分比。
注意:如果是多核 CPU,这里显示的是全局多核平均值。
[root@computer1 ~]# iostat -d -x
Linux 4.19.90-17.ky10.aarch64 (computer1) 2021年07月27日 _aarch64_ (64 CPU)
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz aqu-sz %util
sda 0.01 0.34 0.00 24.08 5.27 51.90 5.37 411.65 3.45 39.09 34.68 76.64 0.00 0.00 0.00 0.00 0.00 0.00 0.17 2.09
[root@computer1 ~]#- Device
- 这一列给出了 /dev 目录中列出的设备(或分区)名称。
- r/s
- 设备每秒完成的读请求数(合并后)
- rkB/s
- 每秒从设备读取的 KB 大小
- rrqm/s
- 每秒设备队列中读取请求的合并数量
- %rrqm
- 发送到设备前的读请求合并数所占百分比
- r_await
- 向提供服务的设备发起读请求的平均时间(以毫秒为单位),这包括在请求队列中花费的时间和服务它们的时间
- rareq-sz
- 向设备发起读请求的平均大小,以 kb 为单位
- w/s
- 设备每秒完成的写请求数(合并后)
- wkB/s
- 每秒向设备写入的 KB 大小
- wrqm/s
- 每秒设备队列中写入请求的合并数量
- %wrqm
- 发送到设备前的写请求合并数所占百分比
- w_await
- 向提供服务的设备发起写请求的平均时间(以毫秒为单位),这包括在请求队列中花费的时间和服务它们的时间
- wareq-sz
- 向设备发起写请求的平均大小,以 kb 为单位
- d/s
- 设备每秒完成的丢弃请求数(合并后)
- dkB/s
- 每秒为设备丢弃的 KB 大小
- drqm/s
- 每秒设备队列中丢弃请求的合并数量
- %drqm
- 发送到设备前的丢弃请求合并数所占百分比
- d_await
- 向提供服务的设备发起丢弃请求的平均时间(以毫秒为单位),这包括在请求队列中花费的时间和服务它们的时间
- dareq-sz
- 向设备发起丢弃请求的平均大小,以 kb 为单位
- aqu-sz
- 向设备发起请求的平均队列长度(老版本叫 avgqu-sz)
- %util
- 设备带宽百分比,串行服务的设备此百分比接近 100% 时会达到饱和;但是对于并行设备,比如 RAID 和现代 SSD,这个值还不能反映它们的性能瓶颈。
[root@computer1 ~]# iostat -d
Linux 4.19.90-17.ky10.aarch64 (computer1) 2021年07月27日 _aarch64_ (64 CPU)
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
sda 5.38 0.34 411.62 0.00 2694156 3237630625 0
[root@computer1 ~]#- Device
- 这一列给出了 /dev 目录中列出的设备(或分区)名称。
- tps
- 每秒向设备发起的传输数量,一次传输是一次向设备发起的 IO 请求,多个逻辑请求可以合并成一个到设备的 IO 请求;传输的大小是不确定的。
- kB_read/s
- 每秒从设备读多少 KB 数据
- kB_wrtn/s
- 每秒向设备写多少 KB 数据
- kB_dscd/s
- 每秒为设备丢弃多少 KB 数据
- kB_read
- 读的总 KB 大小
- kB_wrtn
- 写的总 KB 大小
- kB_dscd
- 丢弃的总 KB 大小
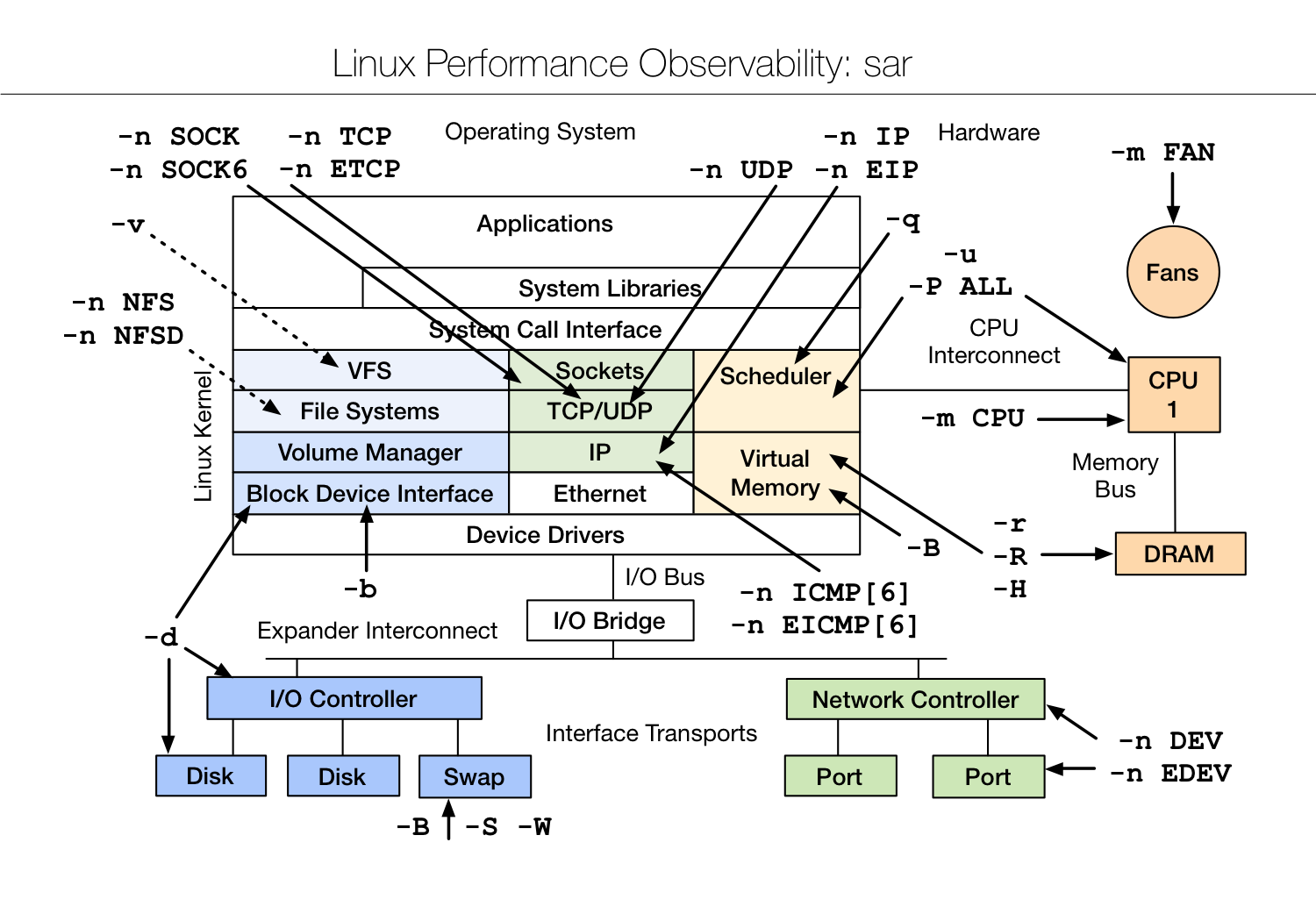
10.5、sar 命令
sar 命令很强大,是分析系统性能的重要工具之一,通过该命令可以全面地获取系统的 CPU、运行队列、磁盘读写(I/O)、分区(交换区)、内存、CPU 中断和网络等性能数据。
sar 命令的基本格式如下:
sar [options] [-o filename] interval [count]
此命令格式中,各个参数的含义如下:
-o filename: 其中,filename 为文件名,此选项表示将命令结果以二进制格式存放在文件中;
interval: 表示采样间隔时间,该参数必须手动设置;
count: 表示采样次数,是可选参数,其默认值为 1;
options: 为命令行选项,由于 sar 命令提供的选项很多,这里不再一一介绍,仅列举出常用的一些选项及对应的功能,如表 1 所示。表 1 sar 命令行选项及功能
| sar命令选项 | 功能 |
|---|---|
| -A | 显示所有的报告信息 |
| -b | 显示I/O速率 |
| -B | 显示换页状态 |
| -c | 显示进程创建活动 |
| -d | 显示每个块设备的状态 |
| -e | 设置显示报告的结束时间 |
| -f | 从指定文件提取报告 |
| -i | 设状态信息刷新的间隔时间 |
| -P | 报告每个CPU的状态 |
| -R | 显示内存状态 |
| -u | 显示CPU利用率 |
| -v | 显示索引节点,文件和其他内核表的状态 |
| -w | 显示交换分区状态 |
| -x | 显示给定进程的状态 |
10.5.1、CPU 资源监控
每 5s 采样一次,连续采样 3 次,观察 cpu 使用情况,并将采样结果以二进制形式存入 sar.bin 中:
[root@computer1 ~]# sar -u -o sar.bin 5 3
Linux 4.19.90-17.ky10.aarch64 (computer1) 2021年07月27日 _aarch64_ (64 CPU)
20时11分56秒 CPU %user %nice %system %iowait %steal %idle
20时12分01秒 all 6.79 0.27 3.15 0.02 0.00 89.76
20时12分06秒 all 7.37 0.23 3.01 0.01 0.00 89.37
20时12分11秒 all 5.58 0.23 2.96 0.04 0.00 91.19
平均时间: all 6.58 0.24 3.04 0.02 0.00 90.11
[root@computer1 ~]#查看二进制文件 sar.bin 中的内容:
[root@computer1 ~]# sar -u -f sar.bin
Linux 4.19.90-17.ky10.aarch64 (computer1) 2021年07月27日 _aarch64_ (64 CPU)
20时11分56秒 CPU %user %nice %system %iowait %steal %idle
20时12分01秒 all 6.79 0.27 3.15 0.02 0.00 89.76
20时12分06秒 all 7.37 0.23 3.01 0.01 0.00 89.37
20时12分11秒 all 5.58 0.23 2.96 0.04 0.00 91.19
平均时间: all 6.58 0.24 3.04 0.02 0.00 90.11
[root@computer1 ~]#输出项说明:
CPU: all 表示统计信息为所有 CPU 的平均值。
%user: 显示在用户空间使用 CPU 时间占总 CPU 时间的百分比。
%nice: 显示在用户空间,用于 nice 操作,所占用 CPU 总时间的百分比。
%system: 显示在内核空间使用 CPU 时间占总 CPU 时间的百分比。
%iowait: 显示用于等待 I/O 时间占 CPU 总时间的百分比。
%steal: 监控程序(hypervisor)为另一个虚拟进程提供服务所用时间占总 CPU 时间的百分比。
%idle: 显示 CPU 空闲时间占用 CPU 总时间的百分比。分析:
1.若 %iowait的值过高,表示硬盘存在I/O瓶颈
2.若 %idle 的值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量
3.若 %idle 的值持续低于 1,则系统的 CPU 处理能力相对较低,表明系统中最需要解决的资源是 CPU。10.5.2、inode、文件和其他内核表监控
每 5 秒采样一次,连续采样 10 次,观察核心表的状态
[root@computer1 ~]# sar -v 5 10
Linux 4.19.90-17.ky10.aarch64 (computer1) 2021年07月27日 _aarch64_ (64 CPU)
20时26分13秒 dentunusd file-nr inode-nr pty-nr
20时26分18秒 376931 7552 386492 17
20时26分23秒 376936 7552 386503 17
20时26分28秒 376934 7424 386493 17
20时26分33秒 376935 7296 386489 17
20时26分38秒 376939 7424 386507 17
20时26分43秒 376935 7296 386494 17
20时26分48秒 376931 7296 386506 17
20时26分53秒 376926 7296 386486 17
20时26分58秒 376923 7168 386485 17
20时27分03秒 376919 7168 386473 17
平均时间: 376931 7347 386493 17
[root@computer1 ~]#输出项说明:
dentunusd: 目录高速缓存中未被使用的条目数量
file-nr: 文件句柄(filehandle)的使用数量
inode-nr: 索引节点句柄(inodehandle)的使用数量
pty-nr: 使用的pty数量10.5.3、内存和交换空间监控
每 5s 采样一次,连续采样 10 次,监控内存分页
[root@computer1 ~]# sar -r 5 10
Linux 4.19.90-17.ky10.aarch64 (computer1) 2021年07月27日 _aarch64_ (64 CPU)
20时35分36秒 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
20时35分41秒 28258816 40953856 216293952 81.58 1226816 17106240 277867072 103.18 204313216 20613184 13504
20时35分46秒 28269184 40964160 216283584 81.58 1226816 17106240 278041472 103.24 204328896 20613440 13632
20时35分51秒 28290112 40985152 216262656 81.57 1226816 17106240 277853056 103.17 204317056 20613568 16384
20时35分56秒 28286400 40981440 216266496 81.57 1226816 17106240 277877632 103.18 204314368 20613568 16832
20时36分01秒 28298368 40993408 216254592 81.57 1226816 17106240 277867392 103.18 204322240 20613568 17728
20时36分06秒 28308352 41003392 216244608 81.57 1226816 17106240 277841728 103.17 204317376 20613568 16512
20时36分11秒 28296512 40991552 216256960 81.57 1226816 17106240 277781888 103.14 204318528 20613568 6208
20时36分16秒 28291520 40986560 216262400 81.57 1226816 17106240 277813696 103.16 204330688 20613568 12160
20时36分21秒 28245952 40940928 216307264 81.59 1226816 17106368 278131072 103.27 204335936 20613568 16704
20时36分26秒 28267776 40962816 216285376 81.58 1226816 17106368 277897152 103.19 204326144 20613504 16512
平均时间: 28281299 40976326 216271789 81.58 1226816 17106266 277897216 103.19 204322445 20613510 14618
[root@computer1 ~]#输出项说明:
kbmemfree: 这个值和free命令中的free值基本一致,所以它不包括buffer和cache的空间.
kbmemused: 这个值和free命令中的used值基本一致,所以它包括buffer和cache的空间.
%memused: 这个值是kbmemused和内存总量(不包括swap)的一个百分比.
kbbuffers kbcached: 这两个值就是free命令中的buffer和cache.
kbcommit: 保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM+swap).
%commit: 这个值是kbcommit与内存总量(包括swap)的一个百分比.
kbactive: 活动内存的 Kb 数量(最近使用的内存,除非绝对必要,否则通常不会回收)。
kbinact: 不活动内存的 Kb 数量(它更适合被回收作其他用途)。
kbdirty: 等待写回磁盘的 Kb 内存量10.5.4、内存分页监控
每 10s 采样一次,连续采样 3 次,监控内存分页
[root@computer1 ~]# sar -B 10 3
Linux 4.19.90-17.ky10.aarch64 (computer1) 2021年07月27日 _aarch64_ (64 CPU)
21时13分20秒 pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff
21时13分30秒 0.00 1645.60 1915.10 0.00 1257.10 0.00 0.00 0.00 0.00
21时13分40秒 0.00 16.00 3075.40 0.00 1614.90 0.00 0.00 0.00 0.00
21时13分50秒 0.00 30.00 1549.10 0.00 1056.40 0.00 0.00 0.00 0.00
平均时间: 0.00 563.87 2179.87 0.00 1309.47 0.00 0.00 0.00 0.00
[root@computer1 ~]#输出项说明:
pgpgin/s: 表示每秒从磁盘或SWAP置换到内存的字节数(KB)
pgpgout/s: 表示每秒从内存置换到磁盘或SWAP的字节数(KB)
fault/s: 每秒钟系统产生的缺页数,即主缺页与次缺页之和(major +minor)
majflt/s: 每秒钟产生的主缺页数.
pgfree/s: 每秒被放入空闲队列中的页个数
pgscank/s: 每秒被kswapd扫描的页个数
pgscand/s: 每秒直接被扫描的页个数
pgsteal/s: 每秒钟从cache中被清除来满足内存需要的页个数
%vmeff: 每秒清除的页(pgsteal)占总扫描页(pgscank+pgscand)的百分比10.5.5、I/O 和传送速率监控
每 5s 采样一次,连续采样 10 次,报告缓冲区的使用情况
[root@computer1 ~]# sar -b 5 10
Linux 4.19.90-17.ky10.aarch64 (computer1) 2021年07月27日 _aarch64_ (64 CPU)
21时30分27秒 tps rtps wtps dtps bread/s bwrtn/s bdscd/s
21时30分32秒 35.00 0.00 35.00 0.00 0.00 6604.80 0.00
21时30分37秒 0.60 0.00 0.60 0.00 0.00 46.40 0.00
21时30分42秒 0.60 0.00 0.60 0.00 0.00 41.60 0.00
21时30分47秒 6.80 0.00 6.80 0.00 0.00 88.00 0.00
21时30分52秒 0.60 0.00 0.60 0.00 0.00 25.60 0.00
21时30分57秒 0.40 0.00 0.40 0.00 0.00 40.00 0.00
21时31分02秒 0.40 0.00 0.40 0.00 0.00 17.60 0.00
21时31分07秒 41.20 0.00 41.20 0.00 0.00 7300.80 0.00
21时31分12秒 0.60 0.00 0.60 0.00 0.00 32.00 0.00
21时31分17秒 0.60 0.00 0.60 0.00 0.00 40.00 0.00
平均时间: 8.68 0.00 8.68 0.00 0.00 1423.68 0.00
[root@computer1 ~]#输出项说明:
tps: 每秒钟物理设备的 I/O传输总量
rtps: 每秒钟从物理设备读入的数据总量
wtps: 每秒钟向物理设备写入的数据总量
bread/s: 每秒钟从物理设备读入的数据量,单位为块/s
bwrtn/s: 每秒钟向物理设备写入的数据量,单位为块/s10.5.6、进程队列长度和平均负载状态监控
每 5s 采样一次,连续采样 10 次,监控进程队列长度和平均负载状态
[root@computer1 ~]# sar -q 5 10
Linux 4.19.90-17.ky10.aarch64 (computer1) 2021年07月27日 _aarch64_ (64 CPU)
21时36分13秒 runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15 blocked
21时36分18秒 4 2469 6.88 6.89 6.92 0
21时36分23秒 5 2462 6.65 6.84 6.91 0
21时36分28秒 6 2462 6.68 6.84 6.91 0
21时36分33秒 2 2462 6.30 6.76 6.88 0
21时36分38秒 6 2471 5.96 6.68 6.85 0
21时36分43秒 4 2488 6.12 6.70 6.86 0
21时36分48秒 2 2462 5.79 6.63 6.83 0
21时36分53秒 7 2462 5.41 6.53 6.80 0
21时36分58秒 4 2471 6.18 6.67 6.85 0
21时37分03秒 14 2464 6.48 6.73 6.86 0
平均时间: 5 2467 6.25 6.73 6.87 0
[root@computer1 ~]#输出项说明:
runq-sz: 运行队列的长度(等待运行的进程数)
plist-sz: 进程列表中进程(processes)和线程(threads)的数量
ldavg-1: 最后1分钟的系统平均负载(Systemload average)
ldavg-5: 过去5分钟的系统平均负载
ldavg-15: 过去15分钟的系统平均负载
blocked: 当前等待I/O完成而阻塞的任务数10.5.7、系统交换活动信息监控
每 5s 采样一次,连续采样 10 次,监控系统交换活动信息
[root@computer1 ~]# sar -W 5 10
Linux 4.19.90-17.ky10.aarch64 (computer1) 2021年07月27日 _aarch64_ (64 CPU)
21时43分30秒 pswpin/s pswpout/s
21时43分35秒 0.00 0.00
21时43分40秒 0.00 0.00
21时43分45秒 0.00 0.00
21时43分50秒 0.00 0.00
21时43分55秒 0.00 0.00
21时44分00秒 0.00 0.00
21时44分05秒 0.00 0.00
21时44分10秒 0.00 0.00
21时44分15秒 0.00 0.00
21时44分20秒 0.00 0.00
平均时间: 0.00 0.00
[root@computer1 ~]#输出项说明:
pswpin/s:每秒系统换入的交换页面(swap page)数量
pswpout/s:每秒系统换出的交换页面(swap page)数量10.5.8、统计网络信息
sar 命令统计网络信息比较细致,语法是:
sar -n { keyword [,...] | ALL }
keyword: DEV, EDEV, FC, ICMP, EICMP, ICMP6, EICMP6, IP, EIP, IP6, EIP6, NFS, NFSD, SOCK, SOCK6, SOFT, TCP, ETCP, UDP and UDP6.- DEV 显示网络接口信息
- EDEV 显示关于网络错误的统计数据
- NFS 统计活动的 NFS 客户端的信息
- NFSD 统计 NFS 服务器的信息
- SOCK 显示套接字信息
- ALL 表示所有 keyword
- 它们可以单独或者一起使用
10.5.8.1、sar -n DEV 1 3
每间隔 1 秒统计一次,总计统计 3 次,下面的 average 是在多次统计后的平均值
[root@controller1 ~]# sar -n DEV 1 1
Linux 4.19.90-17.ky10.aarch64 (controller1) 07/27/2021 _aarch64_ (64 CPU)
10:15:52 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
10:15:53 PM enp2s0f0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:15:53 PM rename3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:15:53 PM ens1 73.00 45.00 47.98 5.14 0.00 0.00 0.00 0.04
10:15:53 PM enp2s0f1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:15:53 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
Average: enp2s0f0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: rename3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: ens1 73.00 45.00 47.98 5.14 0.00 0.00 0.00 0.04
Average: enp2s0f1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
[root@controller1 ~]#
# 如果接口太多,可以使用 --iface 指定接口
[root@controller1 ~]# sar -n DEV --iface=enp2s0f0 1 1
Linux 4.19.90-17.ky10.aarch64 (controller1) 07/27/2021 _aarch64_ (64 CPU)
10:16:29 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
10:16:30 PM enp2s0f0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
Average: enp2s0f0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
[root@controller1 ~]#输出项说明:
IFACE 本地网卡接口的名称
rxpck/s 每秒钟接受的数据包
txpck/s 每秒钟发送的数据库
rxKB/S 每秒钟接受的数据包大小,单位为KB
txKB/S 每秒钟发送的数据包大小,单位为KB
rxcmp/s 每秒钟接受的压缩数据包
txcmp/s 每秒钟发送的压缩包
rxmcst/s 每秒钟接收的多播数据包10.5.8.2、sar -n EDEV 1 1
统计网络设备通信失败信息
[root@controller1 ~]# sar -n EDEV 1 1
Linux 4.19.90-17.ky10.aarch64 (controller1) 07/27/2021 _aarch64_ (64 CPU)
10:20:07 PM IFACE rxerr/s txerr/s coll/s rxdrop/s txdrop/s txcarr/s rxfram/s rxfifo/s txfifo/s
10:20:08 PM enp2s0f0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:20:08 PM rename3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:20:08 PM ens1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:20:08 PM enp2s0f1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:20:08 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: IFACE rxerr/s txerr/s coll/s rxdrop/s txdrop/s txcarr/s rxfram/s rxfifo/s txfifo/s
Average: enp2s0f0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: rename3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: ens1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: enp2s0f1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
[root@controller1 ~]#输出项说明:
IFACE 网卡名称
rxerr/s 每秒钟接收到的损坏的数据包
txerr/s 每秒钟发送的数据包错误数
coll/s 当发送数据包时候,每秒钟发生的冲撞(collisions)数,这个是在半双工模式下才有
rxdrop/s 当由于缓冲区满的时候,网卡设备接收端每秒钟丢掉的网络包的数目
txdrop/s 当由于缓冲区满的时候,网络设备发送端每秒钟丢掉的网络包的数目
txcarr/s 当发送数据包的时候,每秒钟载波错误发生的次数
rxfram 在接收数据包的时候,每秒钟发生的帧对其错误的次数
rxfifo 在接收数据包的时候,每秒钟缓冲区溢出的错误发生的次数
txfifo 在发生数据包的时候,每秒钟缓冲区溢出的错误发生的次数10.5.8.3、sar -n SOCK 1 1
统计 socket 连接信息
[root@controller1 ~]# sar -n SOCK 1 1
Linux 4.19.90-17.ky10.aarch64 (controller1) 07/27/2021 _aarch64_ (64 CPU)
10:23:12 PM totsck tcpsck udpsck rawsck ip-frag tcp-tw
10:23:13 PM 271 65 2 2 0 64
Average: 271 65 2 2 0 64
[root@controller1 ~]#输出项说明:
totsck 当前被使用的socket总数
tcpsck 当前正在被使用的TCP的socket总数
udpsck 当前正在被使用的UDP的socket总数
rawsck 当前正在被使用于RAW的skcket总数
if-frag 当前的IP分片的数目
tcp-twTCP 套接字中处于TIME-WAIT状态的连接数量
如果你使用 FULL 关键字,相当于上述 DEV、EDEV 和 SOCK 三者的综合10.5.8.4、sar -n TCP 1 3
TCP连接的统计
[root@controller1 ~]# sar -n TCP 1 3
Linux 4.19.90-17.ky10.aarch64 (controller1) 07/27/2021 _aarch64_ (64 CPU)
10:25:18 PM active/s passive/s iseg/s oseg/s
10:25:19 PM 5.00 5.00 82.00 82.00
10:25:20 PM 0.00 0.00 11.00 10.00
10:25:21 PM 1.00 0.00 3.00 4.00
Average: 2.00 1.67 32.00 32.00
[root@controller1 ~]#输出项说明:
active/s 新的主动连接
passive/s 新的被动连接
iseg/s 接受的段
oseg/s 输出的段10.5.9、设备使用情况监控
每 5s 采样一次,连续采样 10 次,报告设备使用情况
[root@controller1 ~]# sar -d 5 5 -p
Linux 4.19.90-17.ky10.aarch64 (controller1) 07/27/2021 _aarch64_ (64 CPU)
10:30:02 PM DEV tps rkB/s wkB/s dkB/s areq-sz aqu-sz await %util
10:30:07 PM sda 7.40 0.00 84.00 0.00 11.35 0.00 0.11 0.00
10:30:07 PM loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:30:07 PM DEV tps rkB/s wkB/s dkB/s areq-sz aqu-sz await %util
10:30:12 PM sda 39.60 0.00 3297.60 0.00 83.27 0.67 19.43 1.00
10:30:12 PM loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:30:12 PM DEV tps rkB/s wkB/s dkB/s areq-sz aqu-sz await %util
10:30:17 PM sda 7.00 0.00 75.20 0.00 10.74 0.00 0.09 0.00
10:30:17 PM loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:30:17 PM DEV tps rkB/s wkB/s dkB/s areq-sz aqu-sz await %util
10:30:22 PM sda 14.20 0.00 132.80 0.00 9.35 0.00 0.21 0.00
10:30:22 PM loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:30:22 PM DEV tps rkB/s wkB/s dkB/s areq-sz aqu-sz await %util
10:30:27 PM sda 6.80 0.00 74.40 0.00 10.94 0.00 0.09 0.00
10:30:27 PM loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: DEV tps rkB/s wkB/s dkB/s areq-sz aqu-sz await %util
Average: sda 15.00 0.00 732.80 0.00 48.85 0.13 10.33 0.20
Average: loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
[root@controller1 ~]# 参数
-p 可以打印出sda,hdc等磁盘设备名称,如果不用参数-p,设备节点则有可能是dev8-0,dev22-0输出项说明:
tps: 每秒从物理磁盘I/O的次数.多个逻辑请求会被合并为一个I/O磁盘请求,一次传输的大小是不确定的.
rd_sec/s: 每秒读扇区的次数.
wr_sec/s: 每秒写扇区的次数.
avgrq-sz: 平均每次设备I/O操作的数据大小(扇区).
avgqu-sz: 磁盘请求队列的平均长度.
await: 从请求磁盘操作到系统完成处理,每次请求的平均消耗时间,包括请求队列等待时间,单位是毫秒(1秒=1000毫秒).
svctm: 系统处理每次请求的平均时间,不包括在请求队列中消耗的时间.
%util: I/O请求占CPU的百分比,比率越大,说明越饱和.10.6、free 命令
free 用于查看内存使用情况。
free [options]
选项说明:
-h:人类可读方式显式单位
-m:以MB为显示单位
-w:将buffers和cache分开单独显示。只对CentOS 7上有效
-s:动态查看内存信息时的刷新时间间隔
-c:一共要刷新多少次退出free[root@computer1 ~]# free -mh
total used free shared buff/cache available
Mem: 252Gi 209Gi 24Gi 320Mi 18Gi 36Gi
Swap: 4.0Gi 4.0Gi 0B
[root@computer1 ~]#Mem 和 Swap 分别表示物理内存和交换分区的使用情况。
- total:总内存空间
- used:已使用的内存空间。该值是 total - free - buffers - cache的结果
- free:未使用的内存空间
- shared:多数情况下 /tmpfs 用的内存空间。对内核版本有要求,若版本不够,则显示为 0。
- buff/cache:buffers 和 cache 的总占用空间
- available:可用的内存空间。即程序启动时,将认为可用空间有这么多。可用的内存空间为free + buffers + cache。
所以 available 才是真正需要关注的可使用内存空间量。
使用 -w 可以将 buffers/cache 分开显示。
[root@computer1 ~]# free -wh
total used free shared buffers cache available
Mem: 252Gi 209Gi 24Gi 320Mi 1.2Gi 17Gi 36Gi
Swap: 4.0Gi 4.0Gi 0B
[root@computer1 ~]#还可以动态统计内存信息,例如每秒统计一次,统计 2 次。
[root@computer1 ~]# free -w -m -h -s 1 -c 2
total used free shared buffers cache available
Mem: 252Gi 209Gi 24Gi 316Mi 1.2Gi 17Gi 36Gi
Swap: 4.0Gi 4.0Gi 0B
total used free shared buffers cache available
Mem: 252Gi 209Gi 24Gi 320Mi 1.2Gi 17Gi 36Gi
Swap: 4.0Gi 4.0Gi 0B
[root@computer1 ~]#