
第 2 章 Linux 防火墙
所谓防火墙就是 "防火的墙",如果过来的是 "火" 就得挡住,如果过来的不是 "火" 就放行,但什么是 "火",这由人为自行定义。
但无论如何,所谓的 "火" 都是基于 OSI 七层模型的,简单的划分为四层:最高的应用层(HTTP/FTP/SMTP),往下一层是传输层(TCP/UDP),再往下一层是网络层,最后是链路层。可以基于整个 7 层模型的每一层来定制防火墙,但是默认防火墙(没有编译内核源码定制七层防火墙)一般认为工作在以上的 4 层中。
2.1、数据传输流程
2.1.1、网络数据传输过程
首先看看网络数据传输的基本流程。
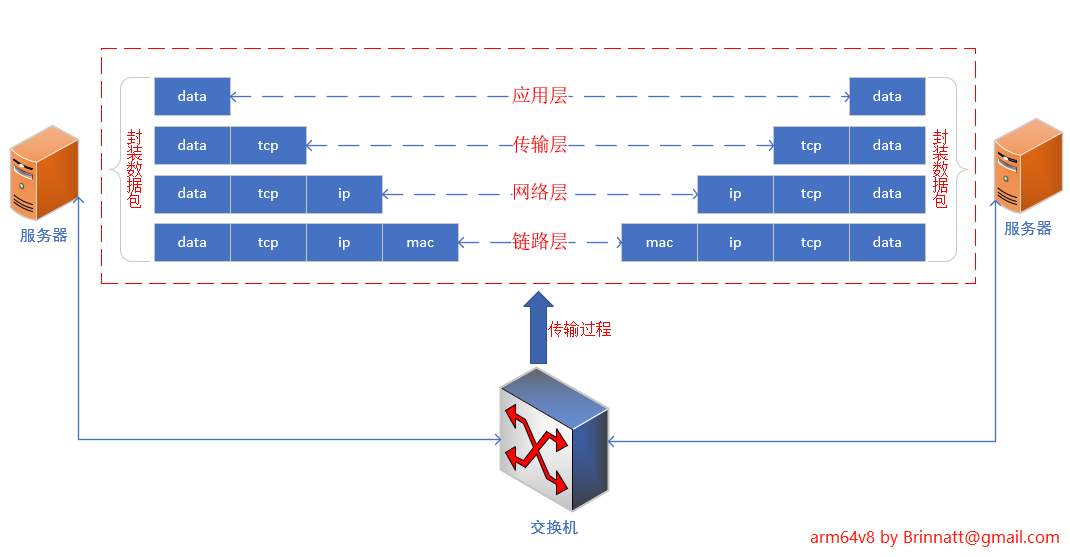
- 国际通用的 OSI 标准网络七层模型包括:应用层、表示层、会话层、传输层、网络层、数据链路层、物理层,很多时候人们为了针对某个场景想要说透一个问题,会简化这七层模型,比如将应用层、表示层、会话层合并成应用层。此图为了过渡到防火墙的专业知识,不深入应用层,所以合并上三层,另外物理层指的就是物理设备,省略。
- 应用层通过通用的协议(比如 http,ftp 等)封装好数据,进入传输层。
- 传输层基于 tcp 或 udp 协议将源端口和目标端口继续封装,然后过渡到网络层。
- 网络层加上源 IP 和目标 IP 成为数据包,再进入链路层。
- 链路层加上源 MAC 地址和目标 MAC 地址成为数据帧。
- 以上整个过程是一种 "加头" 封装数据的过程。数据经过网络传输到达目标主机后,逐层 "剃头" 解包,最终得到 data 纯数据内容。
2.1.2、本机数据路由决策
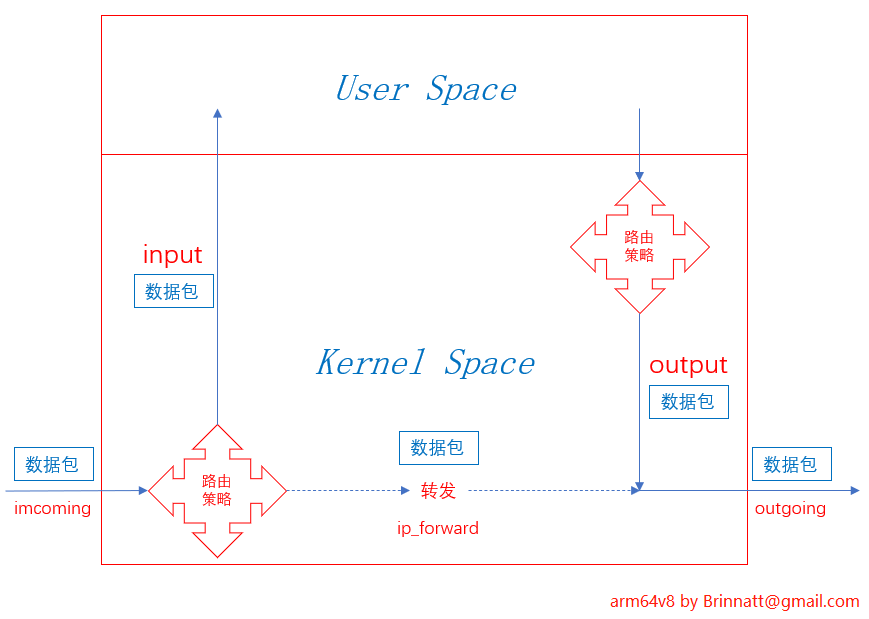
先看结论,再看后面的描述:
iptables 5 大链触发条件总结
| 链 | 触发时机 |
|---|---|
| PREROUTING | 数据包进入 本机 或 需要转发,在路由决策前触发。通常用于 DNAT。 |
| INPUT | 目的 IP 是 本机,路由决策后触发。 |
| FORWARD | 目的 IP 不是本机,需要从一个接口转发到另一个接口时触发。 |
| OUTPUT | 由本机生成的数据包,在离开本机前触发。 |
| POSTROUTING | 数据包即将离开本机或被转发出去,在路由决策后触发。通常用于 SNAT/MASQUERADE。 |
数据包流向示意
📌 外部 -> 本机:PREROUTING → INPUT
📌 本机 -> 外部:OUTPUT → POSTROUTING
📌 外部 -> 另一台机器(通过本机转发):PREROUTING → FORWARD → POSTROUTING
数据包的流转是个很复杂的过程,期间主要由多种 hook 函数和路由策略决定数据包从哪里来到哪里去:
- 数据包从网卡流入后需要对它做路由决策,根据其目标决定是流入本机数据还是转发给其他主机,如果是流入本机的数据,则数据会从内核空间进入用户空间(被应用程序接收、处理)。
- 当用户空间响应(应用程序生成新的数据包)时,响应数据包是本机产生的新数据包,在响应包流出之前,需要做路由决策,根据目标决定从哪个网卡流出。
- 如果不是流入本机的,而是要转发给其他主机的,则必然涉及到另一个流出网卡,此时数据包必须从流入网卡完整地转发给流出网卡,这要求 Linux 主机能够完成这样的转发。
- 但 Linux 主机默认未开启 ip_forward 功能,这使得数据包无法转发而被丢弃。
- Linux 主机和路由器不同,路由器本身就是为了转发数据包,所以路由器内部默认就能在不同网卡间转发数据包,而 Linux 主机默认则不能转发。
注意:IP 地址是属于内核的,不尽如此,整个 tcp/ip 协议栈都属于内核,包括端口号;这个概念在使用 iptables 时尤其要注意,可能会疑惑,为什么 ip_forward 没有打开,两个不同的 ip 地址段之间可以通信,因为 IP 地址是属于内核的,不是属于网卡的。
-
举例:某 Linux 主机有两网卡 eth0:172.16.10.5 和 eth1:192.168.100.20,某 192.168.100.22 主机网关指向 192.168.100.20,若它 ping 172.16.10.5,结果将是通的,因为地址属于内核,从 eth1 进来的数据包被内核分析时,发现目标地址为本机地址,直接就回应 192.168.100.22,回应数据包继续从 eth1 出去。
-
举例:Linux 主机 A 有两网卡 eth0:172.16.10.5 和 eth1:192.168.100.20,某 192.168.100.22 主机网关指向 192.168.100.20,某 172.16.10.7 主机网关指向 172.16.10.5;若 192.168.100.22 直接 ping 172.16.10.7 是不通的,必须开启 Linux 主机 A 的 ip_forward 功能才能通起来。
方法1: # echo 1 > /proc/sys/net/ipv4/ip_forward 方法2: # sysctl -w net.ipv4.ip_forward=1- 以上两种方法是临时生效的,若要永久生效,则应该写入配置文件,建议写在 /etc/sysctl.d/*.conf 中,这是 systemd 提供自定义内核修改项的目录。
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/ip_forward.conf- 可以使用以下几种方式查看是否开启了转发功能。
[root@arm64v8 ~]# sysctl net.ipv4.ip_forward net.ipv4.ip_forward = 0 [root@arm64v8 ~]# [root@arm64v8 ~]# cat /proc/sys/net/ipv4/ip_forward 0 [root@arm64v8 ~]# [root@arm64v8 ~]# sysctl -a | grep ip_forward net.ipv4.ip_forward = 0 net.ipv4.ip_forward_use_pmtu = 0
2.2、TCP 重要概念
2.2.1、TCP 三次握手
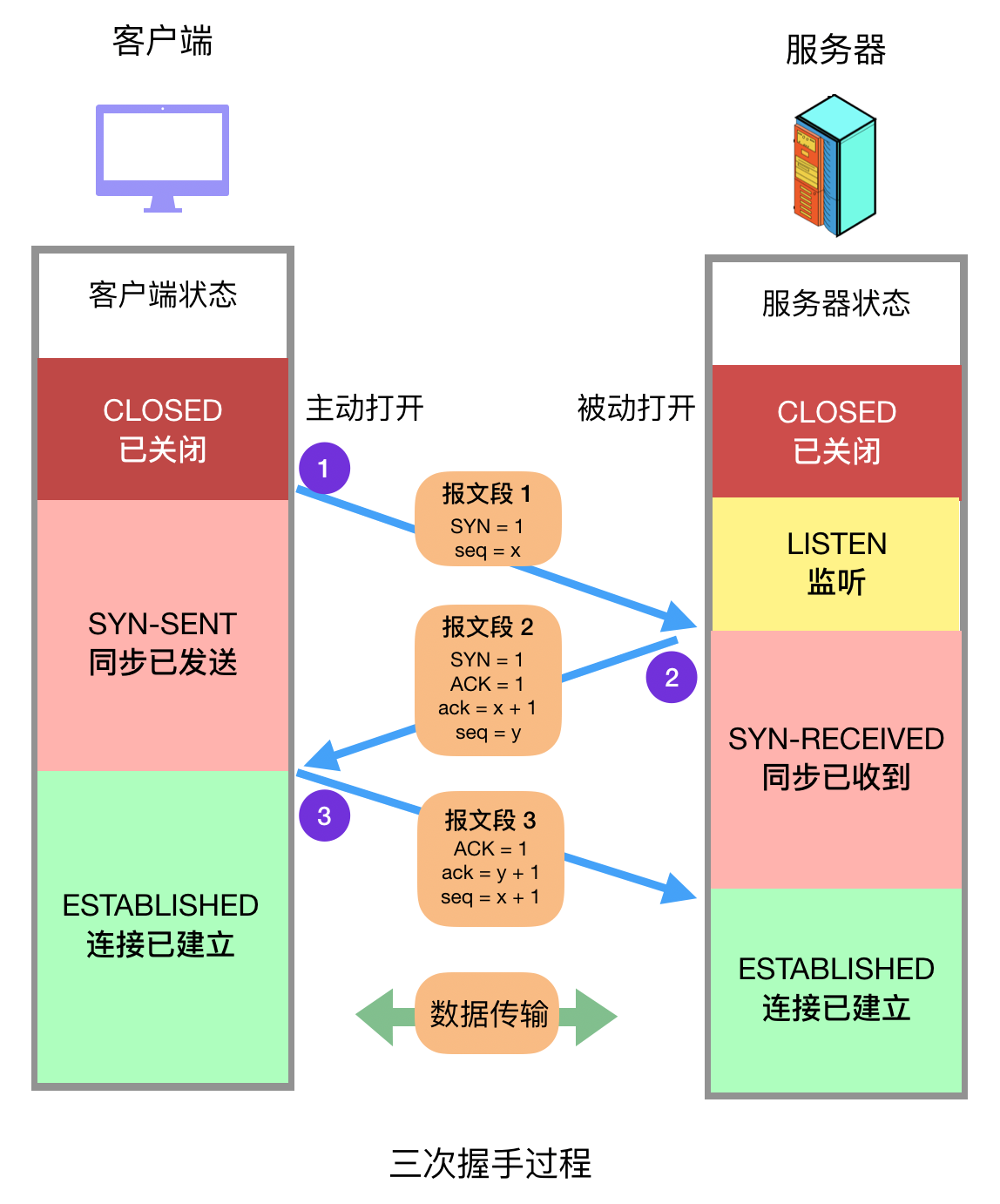
- 客户端和服务端都处于 CLOSED 状态,发起 TCP 请求的称为客户端,接受请求的称为服务端。
- 服务端打开服务端口,处于 listen 状态。
- 客户端向服务器发送报文段 1,其中的 SYN 标志位的值为 1,表示这是一个用于请求发起连接的报文段,其中的序号字段 (Sequence Number,图中简写为 seq)被设置为初始序号 x (Initial Sequence Number,ISN),TCP 连接双方均可随机选择初始序号。发送完报文段 1 之后,客户端进入 SYN-SENT 状态,等待服务器的确认。
- 服务器在收到客户端的连接请求后,向客户端发送报文段 2 作为应答,其中 ACK 标志位设置为 1,表示对客户端做出应答,其确认序号字段 (Acknowledgment Number,图中简写为小写 ack) 生效,该字段值为 x + 1,也就是从客户端收到的报文段的序号加一,代表服务器期望下次收到客户端的数据的序号。此外,报文段 2 的 SYN 标志位也设置为 1,代表这同时也是一个用于发起连接的报文段,序号 seq 设置为服务器初始序号 y。发送完报文段 2 后,服务器进入 SYN-RECEIVED 状态。
- 客户端在收到报文段 2 后,向服务器发送报文段 3,其 ACK 标志位为 1,代表对服务器做出应答,确认序号字段 ack 为 y + 1,序号字段 seq 为 x + 1。此报文段发送完毕后,双方都进入 ESTABLISHED 状态,表示连接已建立。
2.2.2、TCP 四次挥手
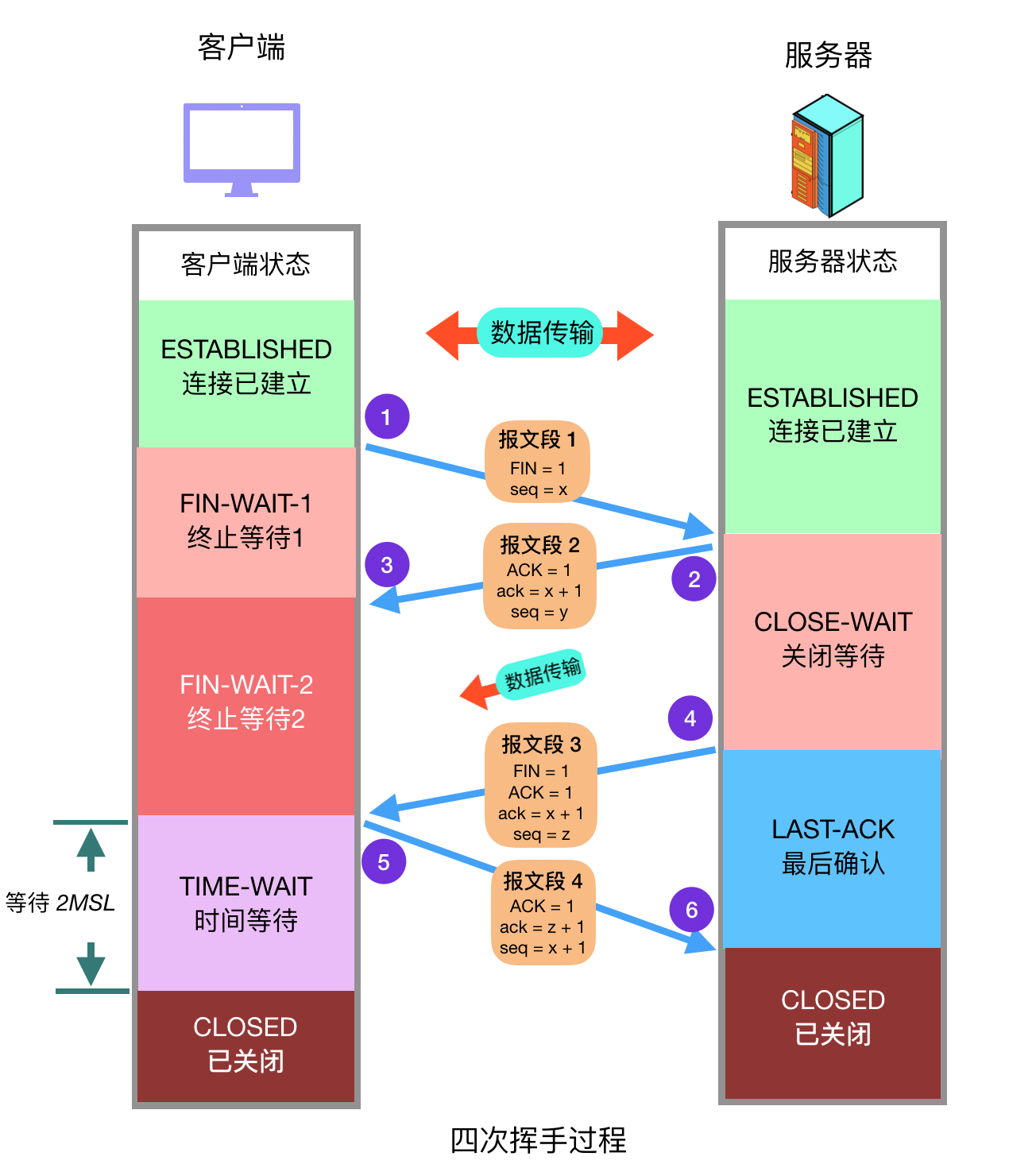
- 当前客户端和服务器端处于 established 已连接状态,而且可以正常相互传输文件。
- 客户端发送关闭连接的报文段,FIN 标志位 1,请求关闭连接,并停止发送数据。序号字段 seq = x (等于之前发送的所有数据的最后一个字节的序号加一),然后客户端会进入 FIN-WAIT-1 状态,等待来自服务器的确认报文。
- 服务器收到 FIN 报文后,发回确认报文,ACK = 1, ack = x + 1,并带上自己的序号 seq = y,然后服务器就进入 CLOSE-WAIT 状态。服务器还会通知上层的应用程序对方已经释放连接,此时 TCP 处于半关闭状态,也就是说客户端已经没有数据要发送了,但是服务器还可以发送数据,客户端也还能够接收。
- 客户端收到服务器的 ACK 报文段后随即进入 FIN-WAIT-2 状态,此时还能收到来自服务器的数据,直到收到 FIN 报文段。
- 服务器发送完所有数据后,会向客户端发送 FIN 报文段,各字段值如图所示,随后服务器进入 LAST-ACK 状态,等待来自客户端的确认报文段。
- 客户端收到来自服务器的 FIN 报文段后,向服务器发送 ACK 报文,随后进入 TIME-WAIT 状态,等待 2MSL(2 * Maximum Segment Lifetime,两倍的报文段最大存活时间) ,这是任何报文段在被丢弃前能在网络中存在的最长时间,常用值有 30 秒、1 分钟和 2 分钟。如无特殊情况,客户端会进入 CLOSED 状态。
- 按照常理,在网络正常的情况下,四个报文段发送完后,双方就可以关闭连接进入 CLOSED 状态了,但是网络并不总是可靠的,如果客户端发送的 ACK 报文段丢失,服务器在接收不到 ACK 的情况下会一直重发 FIN 报文段,这显然不是我们想要的。
- 因此客户端为了确保服务器收到了 ACK,会设置一个定时器,并在 TIME-WAIT 状态等待 2MSL 的时间,如果在此期间又收到了来自服务器的 FIN 报文段,那么客户端会重新设置计时器并再次等待 2MSL 的时间,如果在这段时间内没有收到来自服务器的 FIN 报文,那就说明服务器已经成功收到了 ACK 报文,此时客户端就可以进入 CLOSED 状态了。
- 服务器在接收到客户端的 ACK 报文后会随即进入 CLOSED 状态,由于没有等待时间,一般而言,服务器比客户端更早进入 CLOSED 状态。
2.2.3、syn flood 攻击
syn 洪水攻击是一种常见的 DDos 攻击手段。
- 攻击者可以通过工具在极短时间内伪造大量随机不存在的 ip 向服务器指定端口发送 tcp 连接请求,也就是发送了大量 syn=1 ack=0 的数据包。
- 服务器收到了该数据包后会回复并同样发送 syn 请求 tcp 连接,也就是发送 ack=1 syn=1 的数据包,此后服务器进入 SYN-RECV 状态。
- 正常情况下,服务器期待收到客户端的 ACK 回复。但问题是服务器回复的目标 ip 是不存在的,所以回复的数据包总被丢弃,也一直无法收到 ACK 回复,于是不断重发 ack=1 syn=1 的回复包直至超时。
在服务器被 syn flood 攻击时,由于不断收到大量伪造的 syn=1 ack=0 请求包,它们将长时间占用资源队列,使得正常的 SYN 请求无法得到正确处理,而且服务器一直处于重传响应包的状态,使得 cpu 资源也被消耗。
因此,防范 syn flood 攻击非常重要。当然,首先需要判断出是否受到了 syn flood 攻击。可以通过抓包工具或者 netstat 等工具获取处于 SYN_RECV 状态的半连接,如果有大量处于 SYN_RECV 且源地址都是乱七八糟的,说明受到了 syn 洪水攻击。
例如使用 netstat 工具判断的方法如下:
[root@arm64v8 ~]# netstat -tnlpa | grep tcp | awk '{print $6}' | sort | uniq -c2.3、防火墙的应用
从设备上分类,防火墙分为软件防火墙、硬件防火墙、芯片级防火墙。后文所说的可能是软件防火墙、也可能是硬件防火墙,在理解上它们没什么区别,只是将防火墙剥离成了独自的服务器而已。
从技术上分类,防火墙分为数据包过滤型防火墙、应用代理型防火墙。这是因为四层模型的每一层都可以应用防火墙。
从链路层判断是否处理
基于链路层的防火墙是控制 MAC 的。例如,可以将公司内网员工电脑的 MAC 地址全部记录到防火墙上,从而限制他们上外网。再例如,可以将公司电脑的 MAC 地址全部记录到防火墙使他们能够上网,但是非本公司的电脑就无法从本公司上网。
但是,基本上不会有公司这样做,这样的行为太死板,而且记录 MAC 地址本身就是一件很麻烦的事。
从网络层判断是否处理
网络层的核心是 IP(也包括 icmp 等)。所以从网络层来判断,可以基于源 IP、目标 IP 来指定防火墙的规则。例如,来自 38.68.100.61 的主机不能穿过防火墙;访问目标是 192.168.109.19 的服务器的请求不能让其穿过防火墙;还可以设置 icmp 协议作为判断依据,使得外网人员的 ping 包被挡住。
在网络层可以用来制定防火墙规则的内容有很多。如下表。最常用的也就是后三个而已。

从传输层判断是否处理
可以从 TCP 或者 UDP 来判断。以 TCP 为例,例如限制目标端口是 22 端口的请求,这样 SSH 就无法连接上服务器了。
下表是 TCP 数据包中可以用来制定防火墙规则的字段。

从应用层判断是否处理
到了这一层的处理就属于应用代理型的防火墙了。他需要解开数据包并还原数据,也就是说它可以获取到数据包中的所有内容,但也因此负担很重,所需 CPU 和内存较大。这种防火墙在企业当中很常见,便于管理企业员工上网行为,企业级应用防火墙非常昂贵,由企业实力决定。
2.4、Linux 防火墙
2.4.1、netfilter 与其模块
Linux 是一个极其模块化的内核。netfilter 也是以模块化的形式存在于 Linux 中,所以每添加一个和 netfilter 相关的模块,代表着 netfilter 就多一个功能。
但是有些模块是使用 netfilter 所必须的,所以这些模块已经默认编译到内核中而非需要时加载。
存放 netfilter 模块的目录有三个:/lib/modules/$kernel_ver/net/{netfilter,ipv4/netfilter,ipv6/netfilter}。$kernel_ver 代表内核版本号。
其中 ipv4/netfilter/ 存放的 ipv4 的 netfilter,ipv6/netfilter/ 存放的 ipv6 的 netfilter,/lib/modules/$kernel_net/kernel/netnetfilter/ 存放的是同时满足 ipv4 和 ipv6 的 netfilter。在最后一个目录中放入更多的模块,是 netfilter 团队发展的目标,因为要维护 ipv4 和 ipv6 两个版本挺累的。
2.4.2、iptables 和 netfilter 的关系
Linux 中最常用的基本防火墙软件叫做 iptables。iptables 防火墙通过与 Linux 内核网络堆栈中的包过滤钩子交互来工作。这些内核钩子被称为 netfilter 框架。
防火墙起作用的是 Netfilter,而 iptables 只是管理控制 netfilter 的工具,可以使用该工具进行相关规则的制定以及其他的动作。iptables 是用户层的程序,netfilter 是内核空间的,在 netfilter 刚加入到 Linux 中时,netfilter 是一个 Linux 的一个内核模块,要实现其他的防火墙行为还需要加载其他对应的模块,到了后来 netfilter 一部分必须的模块已经加入到内核中了。
2.4.3、netfilter 的结构
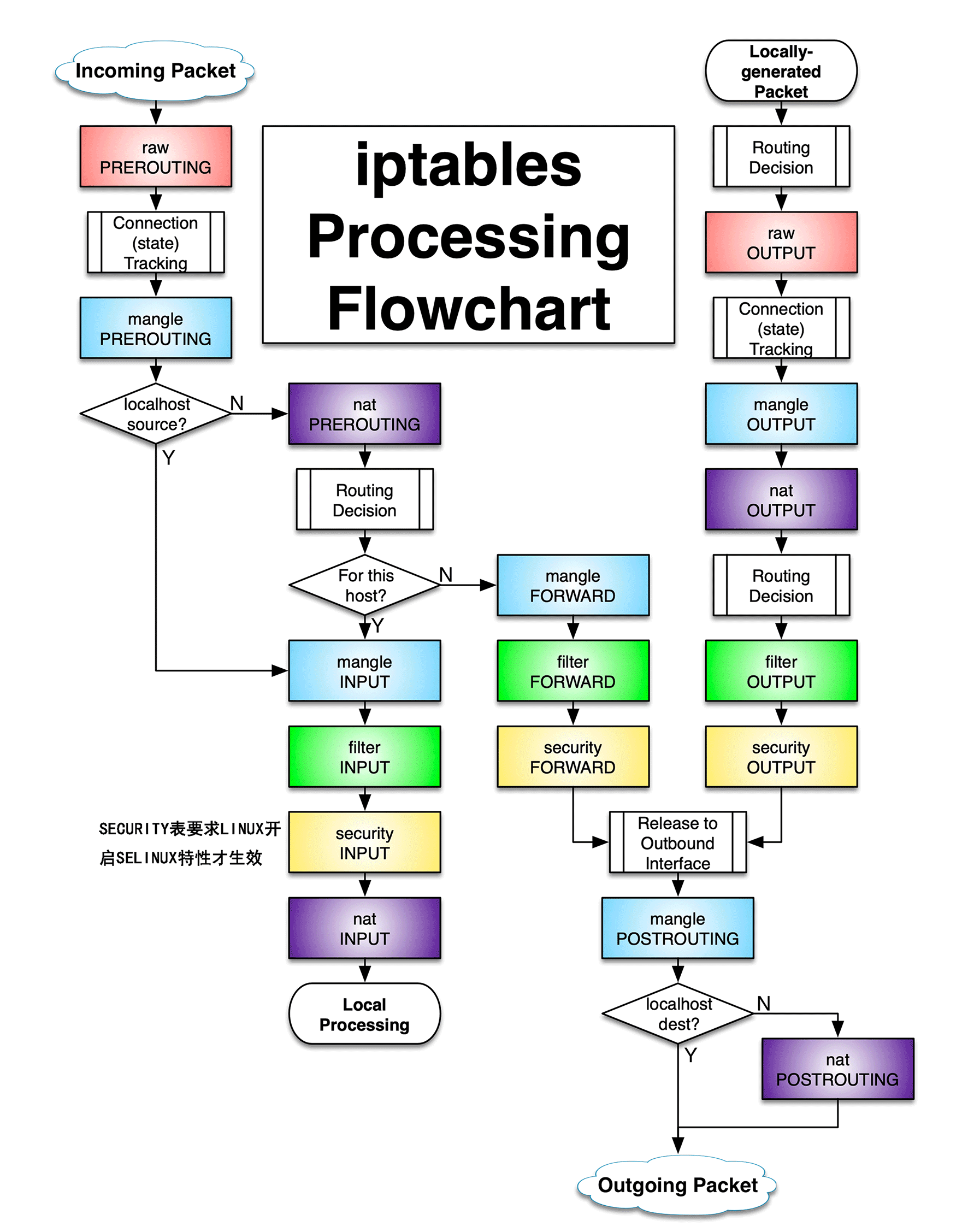
想要完全理解这个图,得有一定的基础知识,下面我们需要理解几个概念:
-
Netfilter Hooks:有五个 netfilter 钩子程序可以注册。当包通过堆栈时,它们将触发已经注册了这些钩子的内核模块。数据包触发的钩子取决于数据包是传入还是传出、数据包的目的地以及数据包是否在前一个点被丢弃或拒绝。
- NF_IP_PRE_ROUTING:在进入网络堆栈后不久,任何传入的流量都会触发这个钩子。这个钩子在决定将包发送到哪里之前被处理。
- NF_IP_LOCAL_IN:如果传入的数据包的目的地是本地系统,则在该数据包被路由后触发该钩子。
- NF_IP_FORWARD:如果传入的数据包要转发到另一个主机,则在路由完成后触发该钩子。
- NF_IP_LOCAL_OUT:任何本地创建的出站流量一旦到达网络堆栈就会触发这个钩子。
- NF_IP_POST_ROUTING:路由发生后和在线路上发出之前的任何传出或转发的流量会触发该钩子。
-
IPTables Chains:正如你所看到的,内置链的名称反映了它们关联的 netfilter 钩子的名称:
- PREROUTING:由 NF_IP_PRE_ROUTING 钩子触发。
- INPUT:由 NF_IP_LOCAL_IN 钩子触发。
- FORWARD:由 NF_IP_FORWARD 钩子触发。
- OUTPUT:由 NF_IP_LOCAL_OUT 钩子触发。
- POSTROUTING:由 NF_IP_POST_ROUTING 钩子触发。
-
IPTables Tables:iptables 防火墙使用表来组织其规则。这些表根据规则所使用的决策类型对规则进行分类。例如,如果一个规则处理网络地址转换,它将被放入 nat 表中。如果使用该规则来决定是否允许数据包继续到达它的目的地,它可能会被添加到 filter 表中。
-
Filter Table:filter 表是 iptables 中使用最广泛的表之一。filter 表用于决定是让数据包继续到达预期目的地还是拒绝它的请求。用防火墙的说法,这被称为 "过滤" 包。该表提供了人们在讨论防火墙时想到的大部分功能。
# 查看表中的链和规则 [root@arm64v8 ~]# iptables -t filter -L Chain INPUT (policy ACCEPT) target prot opt source destination Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination [root@arm64v8 ~]# -
NAT Table:nat 表用于实现网络地址转换规则。可以转换源地址、源端口、目标地址、目标端口等。
# 查看表中的链和规则 [root@arm64v8 ~]# iptables -t nat -L Chain PREROUTING (policy ACCEPT) target prot opt source destination Chain INPUT (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination Chain POSTROUTING (policy ACCEPT) target prot opt source destination [root@arm64v8 ~]# -
Mangle Table:mangle 表用于以各种方式改变数据包的 IP 头。例如,可以调整数据包的 TTL(生存时间)值,可以延长或缩短数据包维持的有效网络跳数。其他 IP 报头可以用类似的方式更改。
该表还可以在包上放置一个内部内核 "标记",以便在其他表和其他网络工具中进行进一步处理。这个标记不接触实际的包,而是将标记添加到内核对包的表示中。
# 查看表中的链和规则 [root@arm64v8 ~]# iptables -t mangle -L Chain PREROUTING (policy ACCEPT) target prot opt source destination Chain INPUT (policy ACCEPT) target prot opt source destination Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination Chain POSTROUTING (policy ACCEPT) target prot opt source destination [root@arm64v8 ~]# -
Raw Table:iptables 防火墙是有状态的,这意味着数据包根据它们与前一个数据包的关系进行评估。建立在 netfilter 框架之上的连接跟踪特性,允许 iptables 将数据包视为正在进行的连接或会话的一部分,而不是作为离散的、不相关的数据包流。通常在数据包到达网络接口后很快进行连接跟踪。
raw 表有一个定义非常狭窄的函数。它的唯一目的是提供一种机制来标记数据包,以便选择退出连接跟踪。
# 查看表中的链和规则 [root@arm64v8 ~]# iptables -t raw -L Chain PREROUTING (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination [root@arm64v8 ~]# -
Security Table:security 表用于在数据包上设置内部 SELinux 安全上下文标记,这将影响 SELinux 或其他可以解释 SELinux 安全上下文的系统处理包的方式。这些标记可以应用在每个包或每个连接的基础上。
# 查看表中的链和规则 [root@arm64v8 ~]# iptables -t security -L Chain INPUT (policy ACCEPT) target prot opt source destination Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination [root@arm64v8 ~]#
-
到这里,再看上面这个图,可以非常清晰地看出 5 种彩色对应的 5 个表;每一种彩色都有该表对应的自己的多个链,也就是 hook 函数;另外,此图从 incoming package 和 locally generated package 两个角度分析了数据包的流转过程,并且整个过程中,经历了哪些 hook 函数关卡,根据用户的需求,可以在这些关卡设置规则。
2.5、iptables 命令
Usage: iptables [-t TABLE] COMMAND CHAIN [ expressions -j target ]这表示要操作 TABLE 表中的链,操作动作由 COMMAND 决定,例如添加一条规则、删除一条规则、列出规则列表等。
如果是向链中增加规则,则需要写出规则表达式用来检查数据包,并指明数据包被规则匹配上时应该做什么操作,例如允许该数据包 ACCEPT、拒绝该数据包 REJECT、丢弃该数据包 DROP,这些操作称为 target,由 "-j" 选项来指定。
2.5.1、iptables 语法
Commands:
Either long or short options are allowed.
--append -A chain 链尾部追加一条规则
--delete -D chain 从链中删除能匹配到的规则
--delete -D chain rulenum 从链中删除第几条链,从1开始计算
--insert -I chain [rulenum] 向链中插入一条规则使其成为第rulenum条规则,从1开始计算
--replace -R chain rulenum 替换链中的地rulenum条规则,从1开始计算
--list -L [chain [rulenum]] 列出某条链或所有链中的规则
--list-rules -S [chain [rulenum]] 打印出链中或所有链中的规则
--flush -F [chain] 删除指定链或所有链中的所有规则
--zero -Z [chain [rulenum]] 置零指定链或所有链的规则计数器
--new -N chain 创建一条用户自定义的链
--delete-chain -X [chain] 删除用户自定义的链
--policy -P chain target 设置指定链的默认策略(policy)为指定的target
--rename-chain -E old new 重命名链名称,从old到new
Options:
[!] --proto -p proto 指定要检查哪个协议的数据包:可以是协议代码也可以是协议名称,
如tcp,udp,icmp等。协议名和代码对应关系存放在/etc/protocols中
省略该选项时默认检查所有协议的数据包,等价于all和协议代码0
[!] --source -s address[/mask][...] 指定检查数据包的源地址,或者使用"--src"
[!] --destination -d address[/mask][...] 指定检查数据包的目标地址,或者使用"--dst"
[!] --in-interface -i input name[+] 指定数据包流入接口,若接口名后加"+",表示匹配该接口开头的所有接口
[!] --out-interface -o output name[+] 指定数据包流出接口,若接口名后加"+",表示匹配该接口开头的所有接口
--jump -j target 为规则指定要做的target动作,例如数据包匹配上规则时将要如何处理
--goto -g chain 直接跳转到自定义链上
--match -m match 指定扩展模块
--numeric -n 输出数值格式的ip地址和端口号。默认会尝试反解为主机名和端口号对应的服务名
--table -t table 指定要操作的table,默认table为filter
--verbose -v 输出更详细的信息
--line-numbers 当list规则时,同时输出行号
--exact -x 默认统计流量时是以1000为单位的,使用此选项则使用1024为单位iptables 支持 extension 匹配。支持两种扩展匹配:使用 "-p" 时的隐式扩展和使用 "-m" 时的显式扩展。根据指定的扩展,随后可使用不同的选项。在指定扩展项的后面可使用 "-h" 来获取该扩展项的语法帮助。
"-p" 选项指定的是隐式扩展,用于指定协议类型,每种协议类型都有一些子选项。常见协议和子选项如下说明:
-p tcp 子选项
子选项:
[!] --source-port,--sport port[:port]
指定源端口号或源端口范围。指定端口范围时格式为"range_start:range_end",最大范围为0:65535。
[!] --destination-port,--dport port[:port]
指定目标端口号或目标端口号范围。
[!] --tcp-flags mask comp
匹配已指定的tcp flags。mask指定的是需要检查的flag列表,comp指定的是必须设置的flag。
mask列表和comp列表之间用空格隔开,各自列表用逗号隔开,mask是列表范围,comp指定mask里面相同的标记都为1其余为0
有效的flag值为:SYN ACK FIN RST URG PSH ALL NONE。
例如:iptables -A FORWARD -p tcp --tcp-flags SYN,ACK,FIN,RST SYN
表示只匹配设置了SYN=1而ACK、FIN和RST都为0数据包,也即只匹配TCP三次握手的第一次握手。
[!] --syn
是"--tcp-flags SYN,ACK,FIN,RST SYN"的简写格式。
-p udp 子选项
子选项:
[!] --source-port,--sport port[:port]
指定源端口号或源端口范围。指定端口范围时格式为"range_start:range_end",最大范围为0:65535。
[!] --destination-port,--dport port[:port]
指定目标端口号或目标端口号范围。
-p icmp 子选项
子选项:
[!] --icmp-type {type[/code]|typename}
用于指定ICMP类型,可以是ICMP类型的数值代码或类型名称。有效的ICMP类型
可由iptables -p icmp -h获取。常用的是"echo-request"和"echo-reply",分别
表示ping和pong,数值代号分别是8和0
ping时先请求后响应:ping别人先出去8后进来0;别人ping自己,先进来8后出去0"-m" 选项指定的是显式扩展。其实隐式扩展也是要指定扩展名的,只不过默认已经知道所使用的扩展,于是可以省略。例如:-p tcp --dport = -p tcp -m tcp --dport。
常用的扩展和它们常用的选项如下:
-
iprange:匹配给定的 IP 地址范围。
[!] --src-range from[-to]:匹配给定的源地址范围 [!] --dst-range from[-to]:匹配给定的目标地址范围 -
multiport:离散的多端口匹配模块,如将 21、22、80 三个端口的规则合并成一条。
最多支持写 15 个端口,其中 "555:999" 算 2 个端口。只有指定了 -p tcp 或 -p udp 时该选项才生效。
[!] --source-ports,--sports port[,port|,port:port]... [!] --destination-ports,--dports port[,port|,port:port]... [!] --ports port[,port|,port:port]... :不区分源和目标,只要是端口就行 -
state:状态扩展。结合 ip_conntrack 追踪会话的状态。
[!] --state state其中 state 有如下 4 种:
- INVALID:非法连接(如 syn=1 fin=1 )
- ESTABLISHED:数据包处于已建立的连接中,它和连接的两端都相关联
- NEW:新建连接请求的数据包,且该数据包没有和任何已有连接相关联
- RELATED:表示数据包正在新建连接, 但它和已有连接是相关联的(如被动模式的 ftp 的命令连接和数据连接)
-m state --state NEW,ESTABLISHED -j ACCEPT -
string:匹配报文中的字符串。
--algo {kmp|bm}:两种算法,随便指定一种 --string "string_pattern"iptables -A OUTPUT -m string --algo bm --sting "taobao.com" -j DROP -
mac:匹配 MAC 地址,格式必须为 XX:XX:XX:XX:XX:XX。
[!] --mac-source address -
limit:使用令牌桶(token bucket)来限制过滤连接请求数。
--limit RATE[/second/minute/hour/day]:允许的平均数量。如每分钟允许10次ping,即6秒一次ping。默认为3/hour。 --limit-burst:允许第一次涌进的并发数量。第一次涌进超出后就按RATE指定数来给出响应。默认值为5。例如:允许每分钟 6 次 ping,但第一次可以 ping 10 次。10 次之后按照 RATE 计算。所以,前 10 个 ping 包每秒能正常返回,从第 11 个 ping 包开始,每 10 秒允许一次 ping
iptables -A INPUT -d ServerIP -p icmp --icmp-type 8 -m limit --limit 6/minute --limit-burst 10 -j ACCEPT -
connlimit:限制每个客户端的连接上限。
--connlimit-above n:连接数量高于上限n个时就执行TARGET如最多只允许某 ssh 客户端建立 3 个 ssh 连接,超出就拒绝。两种写法:
iptables -A INPUT -d ServerIP -p tcp --dport 22 -m connlimit --connlimit-above 3 -j DROP iptables -A INPUT -d ServerIP -p tcp --dport 22 -m connlimit ! --connlimit-above 3 -j ACCEPT这个模块虽然限制能力不错,但要根据环境计算出网页正常访问时需要建立的连接数,另外还要考虑使用 NAT 转换地址时连接数会翻倍的问题。
最后剩下 "-j" 指定的 target 还未说明,target 表示对匹配到的数据包要做什么处理,比如丢弃 DROP、拒绝 REJECT、接受 ACCEPT 等,除这 3 个 target 外,还支持很多种 target。以下是其中几种:
DNAT:目标地址转换 SNAT:源地址转换 REDIRECT:端口重定向 MASQUERADE:地址伪装(其实也是源地址转换) RETURN:用于自定义链,自定义链中匹配完毕后返回到自定义的前一个链中继续向下匹配
2.5.2、ip_conntrack 功能和 iptstate 命令
ip_conntrack 提供追踪功能,后来改称为 nf_conntrack,由 nf_conntrack 模块提供。
只要一加载该模块,/proc/net/nf_conntrack 文件中就会记录下追踪的连接状态。
[root@arm64v8 ~]# yum install iptables-services
[root@arm64v8 ~]# systemctl start iptables.service
[root@arm64v8 ~]# modprobe nf_conntrack
[root@arm64v8 ~]# cat /proc/net/nf_conntrack
ipv4 2 tcp 6 299 ESTABLISHED src=192.168.0.181 dst=192.168.0.188 sport=22 dport=5464 src=192.168.0.188 dst=192.168.0.181 sport=5464 dport=22 [ASSURED] mark=0 zone=0 use=3
ipv4 2 tcp 6 431999 ESTABLISHED src=192.168.0.188 dst=192.168.0.181 sport=5798 dport=22 src=192.168.0.181 dst=192.168.0.188 sport=22 dport=5798 [ASSURED] mark=0 zone=0 use=2
[root@arm64v8 ~]#- 这两条都是 ESTABLISH 状态的连接,分别是 192.168.0.181:22 <-> 192.168.0.188:5464 通信,192.168.0.188:5798 <-> 192.168.0.181:22 通信。
也可以使用 iptstate 命令实时显示连接状态,它是像 top 工具一样的显示。该命令工具在 iptstate 包中,可能需要手动安装。如图为 iptstate 的一次结果。
IPTState - IPTables State Top
Version: 2.2.5 Sort: SrcIP b: change sorting h: help
Source Destination Prt State TTL
192.168.0.181:22 192.168.0.188:5464 tcp ESTABLISHED 0:04:05
192.168.0.188:6117 192.168.0.181:22 tcp ESTABLISHED 119:59:59
192.168.0.188:6126 192.168.0.181:22 tcp ESTABLISHED 119:49:52
192.168.0.188:5798 192.168.0.181:22 tcp ESTABLISHED 119:59:59在 /proc/sys/net/netfilter/ 目录下的文件中定义了很多跟踪连接状态的规范,比如 nf_conntrack_tcp_timeout_time_wait 定义了 TCP 连接 4 次挥手主动断开方的倒数第二个阶段 TIME_WAIT 的值。
[root@arm64v8 ~]# ls /proc/sys/net/netfilter/
nf_conntrack_acct nf_conntrack_sctp_timeout_cookie_wait
nf_conntrack_buckets nf_conntrack_sctp_timeout_established
nf_conntrack_checksum nf_conntrack_sctp_timeout_heartbeat_acked
nf_conntrack_count nf_conntrack_sctp_timeout_heartbeat_sent
nf_conntrack_dccp_loose nf_conntrack_sctp_timeout_shutdown_ack_sent
nf_conntrack_dccp_timeout_closereq nf_conntrack_sctp_timeout_shutdown_recd
nf_conntrack_dccp_timeout_closing nf_conntrack_sctp_timeout_shutdown_sent
nf_conntrack_dccp_timeout_open nf_conntrack_tcp_be_liberal
nf_conntrack_dccp_timeout_partopen nf_conntrack_tcp_loose
nf_conntrack_dccp_timeout_request nf_conntrack_tcp_max_retrans
nf_conntrack_dccp_timeout_respond nf_conntrack_tcp_timeout_close
nf_conntrack_dccp_timeout_timewait nf_conntrack_tcp_timeout_close_wait
nf_conntrack_events nf_conntrack_tcp_timeout_established
nf_conntrack_expect_max nf_conntrack_tcp_timeout_fin_wait
nf_conntrack_frag6_high_thresh nf_conntrack_tcp_timeout_last_ack
nf_conntrack_frag6_low_thresh nf_conntrack_tcp_timeout_max_retrans
nf_conntrack_frag6_timeout nf_conntrack_tcp_timeout_syn_recv
nf_conntrack_generic_timeout nf_conntrack_tcp_timeout_syn_sent
nf_conntrack_helper nf_conntrack_tcp_timeout_time_wait
nf_conntrack_icmp_timeout nf_conntrack_tcp_timeout_unacknowledged
nf_conntrack_icmpv6_timeout nf_conntrack_timestamp
nf_conntrack_log_invalid nf_conntrack_udp_timeout
nf_conntrack_max nf_conntrack_udp_timeout_stream
nf_conntrack_sctp_timeout_closed nf_log
nf_conntrack_sctp_timeout_cookie_echoed nf_log_all_netns
[root@arm64v8 ~]#
[root@arm64v8 ~]# cat /proc/sys/net/netfilter/nf_conntrack_tcp_timeout_time_wait
120
[root@arm64v8 ~]#nf_conntrack 在增加便利的同时会带来性能问题,nf_conntrack 会消耗一定的资源,所以在设计的时候默认给出了其最大的追踪数量,最大追踪数量值由 /proc/sys/net/netfilter/nf_conntrack_max 文件决定。默认是 262144 个。
这个值可能无法满足较高并发量的服务器的,所以可以将其增大一些,否则追踪数达到了最大值后,后续的所有连接都将排队被阻塞,可能会因此给出警告。但是无论如何要明白的是追踪是会消耗性能的,所以该值应该酌情考虑。
[root@arm64v8 ~]# cat /proc/sys/net/netfilter/nf_conntrack_max
262144
[root@arm64v8 ~]#注意:nf_conntrack 模块不是一定需要显式装载才会被装载的,有些依赖它的模块被装载时该模块也会被装载。例如 iptables 命令中包含 iptables -t nat 时,就会装载该模块自动开启追踪,进而可能导致达到追踪 max 值而出错。
2.5.3、-m state 的状态解释
使用 -m state 表示使用简称为 "state" 的模块。该模块提供 4 种状态:NEW、ESTABLISHED、RELATED 和 INVALID。但是这些状态和 TCP 三次握手四次挥手的十几种状态没任何关系。而且 state 提供的 4 种状态对于 tcp/udp/icmp 类型的数据包都是通用的。
注意:这四种状态是数据包的状态,不是客户端或者服务器当时所处的状态。也可以认为是防火墙 state 模块的状态,因为 state 模块在收到对应状态的包时会设置为相同的状态。
-
NEW 状态与 TCP/UDP/ICMP 数据包的关系
为了建立一条连接,发送的第一个数据包(如 tcp 三次握手的第一次 SYN 数据包)的状态为 NEW。如果第一次连接没建立成功,则第二个继续请求的数据包已经不是 NEW 数据包了。
所以,如果不允许 NEW 状态的数据包表示不允许主动和对方建立连接,也不允许外界和本机建立连接。
-
ESTABLISHED 状态与 tcp/udp/icmp 数据包的关系
无论是 tcp 数据包、udp 数据包还是 icmp 数据包,只要发送的请求数据包穿过了防火墙,那么接下来双方传输的数据包状态都是 ESTABLISHED,也就是说发过去的和返回回来的都是 ESTABLISHED 状态数据包。
-
RELATED 数据包的解释
对于 RELATED 数据包的解释是:与当前任何连接都无关,完全是被动或临时建立的连接之间传输的数据包。
例如,图中客户端为了探测服务器的地址发送了 tracert 命令。
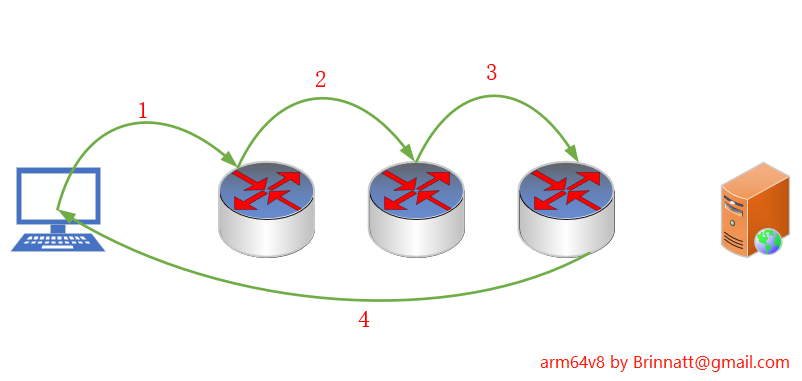
- 这个命令首先会标记一个 tcp 数据包的 TTL 值为 1,当数据包到达第一个路由器该值就减 1,所以 TTL 变为 0 表示该数据包到了寿终正寝该 DROP 掉的时候。
- 然后该路由器就会发送一个 icmp 数据包(icmp-type=11)返回给客户端,这样客户端就知道了第一个路由器的地址。
- 接着客户端的 tracert 命令继续标记一个 TTL 为 2 的数据包向外发送,直到第二个路由器才被丢弃,第二个路由器又发送一个 icmp 包给客户端,这样客户端就知道了第二个路由器的地址。同理第三次也一样。
在 tracert 探测的过程中,由路由器返回的 icmp 包都是 RELATED 状态的数据包。因为可以肯定的说,客户端发送给路由器的 tcp 数据包是走的一条连接,数据包被路由器丢弃后路由器发送的 icmp 数据包与原来的连接已经无关了,这是另外一条返回的连接。但是之所以有这个数据包,完全是因为前面的连接结束而产生的应答数据包。
不过 RELATED 状态和协议无关,只要数据包是因为本机先送出一个数据包而导致另一条连接的产生,那么这个新连接的所有数据包都属于 RELATED 状态的数据包。
这样就容易理解 ftp 被动模式设置的 related 状态了。在 ftp 服务器上的 21 号端口上开启了命令通道(也就是命令连接)后,以后无论是被动模式的随机数据端口还是主动模式的固定 20 数据端口,可以肯定的是数据通道的建立是由命令通道指定要开启的,所以这个数据通道中传输的数据包都是 RELATED 状态的。
-
INVALID 状态的数据包
所谓的 INVALID 状态,就是恶意的数据包。只要不是 ESTABLISHED、NEW、RELATED 状态的数据包,那么就一定是 INVALID 状态。对于 INVALID 数据包最应该放在链中的第一条,以防止恶意的循环攻击。
2.5.4、filter 表示例
实验主机:ip 地址 192.168.0.181,安装 iptables-services 软件包,启动 iptables 服务。
[root@arm64v8 ~]# yum install iptables-services -y
[root@arm64v8 ~]# systemctl start iptables.service
[root@arm64v8 ~]# systemctl enable iptables.service-
清空自定义链、清空规则、清空规则计数器。
[root@arm64v8 ~]# iptables -X [root@arm64v8 ~]# iptables -F [root@arm64v8 ~]# iptables -Z -
允许 192.168.0.0/24 网段连接 ssh(端口22)。
[root@arm64v8 ~]# iptables -A INPUT -s 192.168.0.0/24 -d 192.168.0.181 -p tcp --dport 22 -j ACCEPT [root@arm64v8 ~]# iptables -A OUTPUT -s 192.168.0.181 -p tcp --sport 22 -j ACCEPT [root@arm64v8 ~]# -
设置 filter 表默认规则为 DROP。
[root@arm64v8 ~]# iptables -P INPUT DROP [root@arm64v8 ~]# iptables -P FORWARD DROP [root@arm64v8 ~]# iptables -P OUTPUT DROP一般防火墙对外是 ACCEPT 的,所以 OUTPUT 链采用默认的 ACCEPT。
由于将 INPUT 链设置为全部 DROP,因此除了前面设置的目标为 22 端口的数据包允许通过,其余全部丢弃,即使是 ping 环回地址。
[root@arm64v8 ~]# ping -c 4 127.0.0.1 PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data. --- 127.0.0.1 ping statistics --- 4 packets transmitted, 0 received, 100% packet loss, time 3156ms [root@arm64v8 ~]# -
查看规则列表和统计数据。
[root@arm64v8 ~]# iptables -L -n Chain INPUT (policy DROP) target prot opt source destination ACCEPT tcp -- 192.168.0.0/24 192.168.0.181 tcp dpt:22 Chain FORWARD (policy DROP) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination ACCEPT tcp -- 192.168.0.181 0.0.0.0/0 tcp spt:22 [root@arm64v8 ~]#如果加上 "-v" 选项,则会显示每条规则上的流量统计数据。
[root@arm64v8 ~]# iptables -L -n -v Chain INPUT (policy DROP 4 packets, 336 bytes) pkts bytes target prot opt in out source destination 269 19900 ACCEPT tcp -- * * 192.168.0.0/24 192.168.0.181 tcp dpt:22 Chain FORWARD (policy DROP 0 packets, 0 bytes) pkts bytes target prot opt in out source destination Chain OUTPUT (policy ACCEPT 4 packets, 336 bytes) pkts bytes target prot opt in out source destination 92 10904 ACCEPT tcp -- * * 192.168.0.181 0.0.0.0/0 tcp spt:22 [root@arm64v8 ~]# -
放行环回设备的进出数据包(环回地址的放行很重要)。
[root@arm64v8 ~]# iptables -A INPUT -i lo -s 127.0.0.1 -d 127.0.0.1 -j ACCEPT [root@arm64v8 ~]# iptables -A OUTPUT -o lo -s 127.0.0.1 -d 127.0.0.1 -j ACCEPT [root@arm64v8 ~]# [root@arm64v8 ~]# ping 127.0.0.1 PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data. 64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.041 ms 64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.015 ms ^C --- 127.0.0.1 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1044ms rtt min/avg/max/mdev = 0.015/0.028/0.041/0.013 ms [root@arm64v8 ~]#但是不建议直接写 127.0.0.1,而是省略目标地址和源地址,因为 ping 本机 ip 地址最后交给环回设备但是不是交给 127.0.0.1 的,而是交给 127.0.0 网段的其他地址。所以应该这么写:
[root@arm64v8 ~]# iptables -A INPUT -i lo -j ACCEPT [root@arm64v8 ~]# iptables -A OUTPUT -o lo -j ACCEPT所以可以将前面多余的规则删除掉。
[root@arm64v8 ~]# iptables -D INPUT 2 [root@arm64v8 ~]# iptables -D OUTPUT 2 -
能自己 ping 自己的 IP,也能 ping 别人的 IP,但是别人不能 ping 自己。
ping 的过程实际上是 ping 请求对方,然后对方 pong 回应,协议类型为 icmp。其中 ping 请求时,icmp 类型为 echo-request,数值代号为 8,pong 回应时的 icmp 类型为 echo-reply,数值代号为 0。
所以本机向外 ping 时,流出的是 echo-request 数据包,流入的是 echo-reply 数据包。而外界 ping 本机时,则是流入 echo-request 数据包,流出 echo-reply 数据包。因此,要允许本机向外 ping,只需允许 icmp-type=8 的流出包、icmp-type=0 的流入包即可,又由于前面的试验中设置了 INPUT 和 OUTPUT 链的默认规则为 DROP,所以外界主机无法 ping 本机。
[root@arm64v8 ~]# iptables -A OUTPUT -p icmp --icmp-type=8 -j ACCEPT [root@arm64v8 ~]# iptables -A INPUT -p icmp --icmp-type=0 -j ACCEPT -
安装 httpd,让外界能够访问 web 页面(端口为80)。
[root@arm64v8 ~]# iptables -A INPUT -d 192.168.0.181 -p tcp --dport 80 -j ACCEPT [root@arm64v8 ~]# iptables -A OUTPUT -s 192.168.0.181 -p tcp --sport 80 -j ACCEPT -
替换 ssh 服务和 web 服务的规则,并写出基于 ip_conntrack 放行 ssh 和 web 的规则(进入的数据包的状态只可能会是 NEW 和 ESTABLISHED,出去的状态只可能是 ESTABLISHED)
放行 ssh:
[root@arm64v8 ~]# iptables -R INPUT 1 -s 192.168.0.0/24 -d 192.168.0.181 -p tcp --dport 22 -m state --state=NEW,ESTABLISHED -j ACCEPT [root@arm64v8 ~]# iptables -R OUTPUT 1 -s 192.168.0.181 -p tcp --sport 22 -m state --state=ESTABLISHED -j ACCEPT [root@arm64v8 ~]#放行 web:
[root@arm64v8 ~]# iptables -R INPUT 4 -d 192.168.0.181 -p tcp --dport 80 -m state --state=NEW,ESTABLISHED -j ACCEPT [root@arm64v8 ~]# iptables -R OUTPUT 4 -s 192.168.0.181 -p tcp --sport 80 -m state --state=ESTABLISHED -j ACCEPT [root@arm64v8 ~]#[root@arm64v8 ~]# iptables -L -n --line-number Chain INPUT (policy DROP) num target prot opt source destination 1 ACCEPT tcp -- 192.168.0.0/24 192.168.0.181 tcp dpt:22 state NEW,ESTABLISHED 2 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 3 ACCEPT icmp -- 0.0.0.0/0 0.0.0.0/0 icmptype 0 4 ACCEPT tcp -- 0.0.0.0/0 192.168.0.181 tcp dpt:80 state NEW,ESTABLISHED Chain FORWARD (policy DROP) num target prot opt source destination Chain OUTPUT (policy DROP) num target prot opt source destination 1 ACCEPT tcp -- 192.168.0.181 0.0.0.0/0 tcp spt:22 state ESTABLISHED 2 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 3 ACCEPT icmp -- 0.0.0.0/0 0.0.0.0/0 icmptype 8 4 ACCEPT tcp -- 192.168.0.181 0.0.0.0/0 tcp spt:80 state ESTABLISHED [root@arm64v8 ~]#这样的设置使得外界可以和主机建立会话,但是由主机出去的数据包则一定只能是 ESTABLISHED 状态的服务发出的,这样本机想主动和外界建立会话是不可能的。这样就实现了状态监测的功能,防止黑客通过开放的 22 端口或 80 端口植入木马并主动联系黑客。
-
放行外界 ping 自己,但是要基于 ip_conntrack 来放行。
[root@arm64v8 ~]# iptables -A INPUT -d 192.168.0.181 -p icmp --icmp-type=8 -m state --state=NEW,ESTABLISHED -j ACCEPT [root@arm64v8 ~]# iptables -A OUTPUT -s 192.168.0.181 -p icmp --icmp-type=0 -m state --state=ESTABLISHED -j ACCEPT [root@arm64v8 ~]# -
安装 vsftpd,并设置其防火墙。
由于 ftp 有主动模式和被动模式,被动模式的数据端口不定,且使用哪种模式是由客户端决定的,这使得 ftp的防火墙设置比较复杂,但是借助 netfilter 的 state 模块,设置就简单的多了。
首先装载其专门的模块 nf_conntrack_ftp。
[root@arm64v8 ~]# modprobe nf_conntrack_ftp也可以写入 /etc/sysconfig/iptables-config 的 "IPTABLES_MODULES="nf_conntrack_ftp"。
然后编写规则:放行 21 端口的进入数据包,放行 related 关联数据包,放行出去的包。
[root@arm64v8 ~]# iptables -A INPUT -d 192.168.0.181 -p tcp --dport 21 -m state --state=NEW,ESTABLISHED -j ACCEPT [root@arm64v8 ~]# iptables -A INPUT -d 192.168.0.181 -m state --state=RELATED,ESTABLISHED -j ACCEPT [root@arm64v8 ~]# iptables -A OUTPUT -s 192.168.0.181 -m state --state=ESTABLISHED -j ACCEPT [root@arm64v8 ~]#
以上示例完成后,得到的总规则集如下:
[root@arm64v8 ~]# iptables -L -n --line-numbers
Chain INPUT (policy DROP)
num target prot opt source destination
1 ACCEPT tcp -- 192.168.0.0/24 192.168.0.181 tcp dpt:22 state NEW,ESTABLISHED
2 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0
3 ACCEPT icmp -- 0.0.0.0/0 0.0.0.0/0 icmptype 0
4 ACCEPT tcp -- 0.0.0.0/0 192.168.0.181 tcp dpt:80 state NEW,ESTABLISHED
5 ACCEPT icmp -- 0.0.0.0/0 192.168.0.181 icmptype 8 state NEW,ESTABLISHED
6 ACCEPT tcp -- 0.0.0.0/0 192.168.0.181 tcp dpt:21 state NEW,ESTABLISHED
7 ACCEPT all -- 0.0.0.0/0 192.168.0.181 state RELATED,ESTABLISHED
Chain FORWARD (policy DROP)
num target prot opt source destination
Chain OUTPUT (policy DROP)
num target prot opt source destination
1 ACCEPT tcp -- 192.168.0.181 0.0.0.0/0 tcp spt:22 state ESTABLISHED
2 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0
3 ACCEPT icmp -- 0.0.0.0/0 0.0.0.0/0 icmptype 8
4 ACCEPT tcp -- 192.168.0.181 0.0.0.0/0 tcp spt:80 state ESTABLISHED
5 ACCEPT icmp -- 192.168.0.181 0.0.0.0/0 icmptype 0 state ESTABLISHED
6 ACCEPT all -- 192.168.0.181 0.0.0.0/0 state ESTABLISHED
[root@arm64v8 ~]#现在 iptables 已经有很多规则,但是也足够乱的。不仅想看懂挺复杂,在数据包检查的时候性能也更差,所以有必要将它们合并成简单易懂的规则。
2.5.5、优化规则
执行 iptables-save 命令,可以 dump 出当前内核维护的 netfilter 指定表中的规则,默认导出 filter 表。
[root@arm64v8 ~]# iptables-save -t filter
# Generated by iptables-save v1.4.21 on Wed Sep 29 06:17:54 2021
*filter
:INPUT DROP [3:885]
:FORWARD DROP [0:0]
:OUTPUT DROP [66:21100]
-A INPUT -s 192.168.0.0/24 -d 192.168.0.181/32 -p tcp -m tcp --dport 22 -m state --state NEW,ESTABLISHED -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -p icmp -m icmp --icmp-type 0 -j ACCEPT
-A INPUT -d 192.168.0.181/32 -p tcp -m tcp --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
-A INPUT -d 192.168.0.181/32 -p icmp -m icmp --icmp-type 8 -m state --state NEW,ESTABLISHED -j ACCEPT
-A INPUT -d 192.168.0.181/32 -p tcp -m tcp --dport 21 -m state --state NEW,ESTABLISHED -j ACCEPT
-A INPUT -d 192.168.0.181/32 -m state --state RELATED,ESTABLISHED -j ACCEPT
-A OUTPUT -s 192.168.0.181/32 -p tcp -m tcp --sport 22 -m state --state ESTABLISHED -j ACCEPT
-A OUTPUT -o lo -j ACCEPT
-A OUTPUT -p icmp -m icmp --icmp-type 8 -j ACCEPT
-A OUTPUT -s 192.168.0.181/32 -p tcp -m tcp --sport 80 -m state --state ESTABLISHED -j ACCEPT
-A OUTPUT -s 192.168.0.181/32 -p icmp -m icmp --icmp-type 0 -m state --state ESTABLISHED -j ACCEPT
-A OUTPUT -s 192.168.0.181/32 -m state --state ESTABLISHED -j ACCEPT
COMMIT
# Completed on Wed Sep 29 06:17:54 2021
[root@arm64v8 ~]#从导出结果中可以看到,input 链中有好几条规则都是针对 state=NEW,ESTABLISHED 而建立的,同理 OUTPUT 链中的 state=ESTABLISHED,且他们的 target 都是一样的,这样的规则可以考虑是否能够合并。
注意:环回接口 lo 一定要显式指定所有类型的数据都通过。
# INPUT:
-A INPUT -s 192.168.0.0/24 -d 192.168.0.181/32 -p tcp -m tcp --dport 22 -m state --state NEW,ESTABLISHED -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -p icmp -m icmp --icmp-type 0 -j ACCEPT
-A INPUT -d 192.168.0.181/32 -p tcp -m tcp --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
-A INPUT -d 192.168.0.181/32 -p icmp -m icmp --icmp-type 8 -m state --state NEW,ESTABLISHED -j ACCEPT
-A INPUT -d 192.168.0.181/32 -p tcp -m tcp --dport 21 -m state --state NEW,ESTABLISHED -j ACCEPT
-A INPUT -d 192.168.0.181/32 -m state --state RELATED,ESTABLISHED -j ACCEPT
# 可以考虑合并如下:
# INPUT:
-A INPUT -d 192.168.0.181/32 -p tcp -m multiport --destination-ports 21,22,80 -m state --state NEW,ESTABLISHED,RELATED -j ACCEPT
-A INPUT -d 192.168.0.181/32 -p icmp -j ACCEPT
-A INPUT -i lo -j ACCEPT# OUTPUT
-A OUTPUT -s 192.168.0.181/32 -p tcp -m tcp --sport 22 -m state --state ESTABLISHED -j ACCEPT
-A OUTPUT -o lo -j ACCEPT
-A OUTPUT -p icmp -m icmp --icmp-type 8 -j ACCEPT
-A OUTPUT -s 192.168.0.181/32 -p tcp -m tcp --sport 80 -m state --state ESTABLISHED -j ACCEPT
-A OUTPUT -s 192.168.0.181/32 -p icmp -m icmp --icmp-type 0 -m state --state ESTABLISHED -j ACCEPT
-A OUTPUT -s 192.168.0.181/32 -m state --state ESTABLISHED -j ACCEPT
# 可以考虑合并如下:
# OUTPUT:
-A OUTPUT -s 192.168.0.181/32 -m state --state ESTABLISHED -j ACCEPT
-A OUTPUT -s 192.168.0.181/32 -p icmp -j ACCEPT
-A OUTPUT -o lo -j ACCEPT通过上述思路的净化,最终可以得到如下的规则集
[root@arm64v8 ~]# iptables -L -n --line-numbers
Chain INPUT (policy DROP)
num target prot opt source destination
1 ACCEPT tcp -- 0.0.0.0/0 192.168.0.181 multiport dports 21,22,80 state NEW,RELATED,ESTABLISHED
2 ACCEPT icmp -- 0.0.0.0/0 192.168.0.181
3 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0
Chain FORWARD (policy DROP)
num target prot opt source destination
Chain OUTPUT (policy DROP)
num target prot opt source destination
1 ACCEPT all -- 192.168.0.181 0.0.0.0/0 state ESTABLISHED
2 ACCEPT icmp -- 192.168.0.181 0.0.0.0/0
3 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0
[root@arm64v8 ~]#其实学到这里,可以算是已经触及到 iptables filter 表的核心了,针对用户不同的需求,可以灵活定制了,后面会给出最佳实践。
2.5.6、保存规则
使用 iptables 写的规则都存放在内存中,内核会维护 netfilter 的每张表中的规则,所以重启 iptables "服务" 会使内存中的规则列表全部被清空。
要想手动写的规则长期有效,需要将规则保存到持久存储文件中,例如 iptables "服务" 启动时默认加载的脚本配置文件 /etc/sysconfig/iptables。
有两种方法保存规则:
-
直接保存到 /etc/sysconfig/iptables 中
service iptables save -
可自定义保存位置
iptables-save > /etc/sysconfig/iptables iptables-save > /etc/sysconfig/iptables.20211005
恢复规则的方法:
iptables-restore < /etc/sysconfig/iptables
iptables-restore < /etc/sysconfig/iptables.202110052.5.7、自定义链
自定义链是被主链引用的。引用位置由 "-j" 指定自定义链名称,表示跳转到自定义链并匹配其内部规则列表。
例如,在 INPUT 链中的第三条规则为自定义链的引用规则,则数据包匹配到了第三条时进入自定义链匹配,匹配完自定义链后如果定义了返回主链的 RETURN 动作,则返回主链继续向下匹配,如果没有定义 RETURN 动作,则匹配结束。
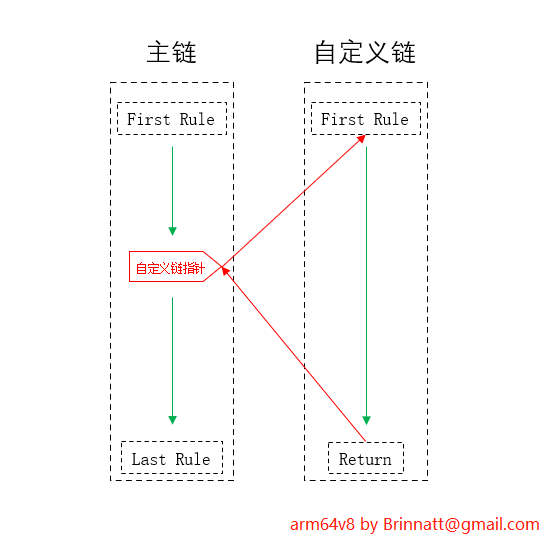
创建一条自定义链。
[root@arm64v8 ~]# iptables -N mychain向其中加入一些基于安全的攻防规则,让每次数据包进入都匹配一次攻防链。
[root@arm64v8 ~]# iptables -A mychain -d 255.255.255.255 -p icmp -j DROP
[root@arm64v8 ~]# iptables -A mychain -d 192.168.255.255 -p icmp -j DROP
[root@arm64v8 ~]# iptables -A mychain -p tcp ! --syn -m state --state NEW -j DROP
[root@arm64v8 ~]# iptables -A mychain -p tcp --tcp-flags ALL ALL -j DROP
[root@arm64v8 ~]# iptables -A mychain -p tcp --tcp-flags ALL NONE -j DROP
[root@arm64v8 ~]#在自定义链中的最后一条加上一条返回主链的规则,表示匹配完自定义后继续回到主链进行匹配。
[root@arm64v8 ~]# iptables -A mychain -d 192.168.0.181/32 -j RETURN在主链的适当位置加上一条引用主链的规则。表示数据包匹配到了这个位置开始进入自定义链匹配,如果自定义链都没被匹配而是被最后的 RETURN 规则匹配,则回到主链再次匹配。
[root@arm64v8 ~]# iptables -I INPUT -d 192.168.0.181/32 -j mychain - 如果不指定插入到第几条规则,默认插入第一条。
删除自定义链:需要先清空自定义链,去除被引用记录,然后使用 -X 删除空的自定义链。
[root@arm64v8 ~]# iptables -F mychain
[root@arm64v8 ~]# iptables -D INPUT 1
[root@arm64v8 ~]# iptables -X mychain可以使用 -E 命令重命名自定义链。
2.5.7.1、自定义链示例
如果我们在云服务厂商那里买了一台云服务器,经常会遇到别人暴力破解我们的 sshd 服务,为了抑制这种情况的发生,我们通过下面几个步骤实现。
第一步:编写检测恶意 IP 的脚本
[root@brinnatt ~]# cat /security/deny_sshcrack.sh
#! /bin/bash
# 提取所有的IP到black.list文件中
cat /var/log/secure|awk '/Failed/{print $(NF-3)}'|sort|uniq -c|awk '{print $2"="$1;}' > /usr/local/bin/black.list
# 设定次数
define="3"
for i in `cat /usr/local/bin/black.list`
do
IP=`echo $i |awk -F= '{print $1}'`
NUM=`echo $i|awk -F= '{print $2}'`
if [ $NUM -gt $define ]; then
/usr/sbin/iptables -C DENY_SSHCRACK -s $IP -j DROP &> /dev/null
if [ $? -gt 0 ];then
/usr/sbin/iptables -I DENY_SSHCRACK 1 -s $IP -j DROP
fi
fi
done
[root@brinnatt ~]# chmod +x /security/deny_sshcrack.sh第二步:创建自定义链专门用来过滤恶意 IP
[root@brinnatt ~]# iptables -N DENY_SSHCRACK
[root@brinnatt ~]# iptables -A DENY_SSHCRACK -i eth0 -j RETURN- 脚本会自动向该自定义链中插入过滤规则
第三步:创建任务计划
[root@brinnatt ~]# crontab -l
*/3 * * * * /security/deny_sshcrack.sh- 注意,先要熟练撑握任务计划应用,不然很有可能任务不生效,特别是要注意 crontab 的配置文件,里面的 PATH 如果没有包含脚本中的命令,会出现 command not found,从而任务计划失败。
- 本来通过 tcp_wrapper 可以更简单实现,可惜由于安全原因 openssh v6.7 以后不支持 tcp_wrapper。
- 这种脚本实现的方式固然可以,但是有些繁琐,有一个开源项目 fail2ban,实现起来简单而且功能强大。
2.5.8、NAT 表
NAT 依赖于 ip_forward,因此需要先开启它。NAT 的基础是 nf_conntrack,用来记录 NAT 表的映射关系。
NAT 有三个作用:
- 地址转换:让内网(私有地址)可以共用一个或几个公网地址连接 Internet。这是从内向外的,需要在网关式防火墙的 POSTROUTING 处修改源地址,这是 SNAT 功能。
- 保护内网服务器:内网主机连接 Internet 使用的是公网地址,对外界而言是看不到内网服务器地址的,所以外界想要访问内部主机只能经过防火墙主机的公网地址,然后将目标地址转换为内网服务器地址,这起到了保护内网服务器的作用。转换目标地址需要在网关式防火墙的 PREROUTING 链处修改,这是 DNAT 功能。
- 端口映射:DNAT 是修改目标地址,端口映射是修改目标端口。如将 web 服务器的 8080 端口映射为防火墙的 80 端口。
外网主机和内网主机通信有两种情况的数据包:一种情况是建立NEW状态的新请求连接数据包,一种是回应的数据包。
无论哪种情况,在 NEW 状态数据包经过地址转换之后会在防火墙内存中维护一张 NAT 表,保存未完成连接的地址转换记录,这样当回应数据包到达防火墙时可以根据这些记录路由给正确的主机。
也就是说,SNAT 主要应付的是内部主机连接到 Internet 的源地址转换,转换的位置是 POSTROUTING 链;DNAT 主要应付的是外部主机连接内部服务器防止内部服务器被攻击的目标地址转换,转换位置在 PREROUTING;端口映射可以在多个地方转换。
2.5.8.1、配置网关以及转发
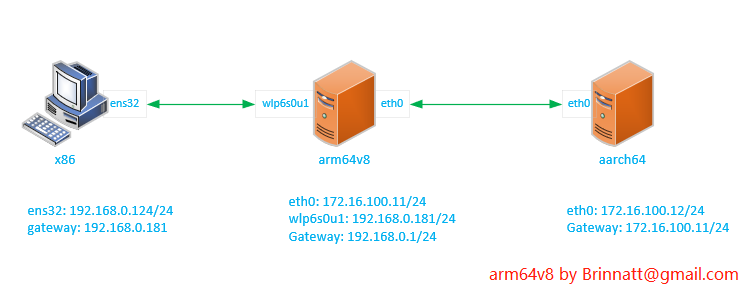
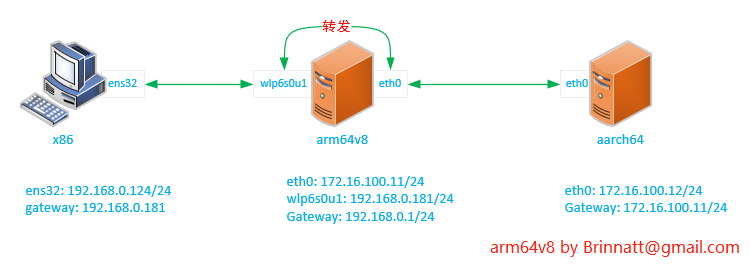
实验环境如上图所示:
-
arm64v8 作为转发主机有两个网卡两个网段,一个是 192.168.0.0/24 网段和 172.16.100.0/24 网段;
-
x86 主机网关指向 arm64v8 主机;
-
aarch64 主机网关指向 arm64v8 主机 ;
实验步骤:
-
x86 主机 ping arm64v8 主机 192.168.0.181 网卡,aarch64 主机 ping arm64v8 主机 172.16.100.11 网卡。
[root@x86 ~]# route -n # 查看路由 Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.0.181 0.0.0.0 UG 0 0 0 ens32 169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 ens32 192.168.0.0 0.0.0.0 255.255.255.0 U 0 0 0 ens32 [root@x86 ~]# ping 192.168.0.181 # 可以通 PING 192.168.0.181 (192.168.0.181) 56(84) bytes of data. 64 bytes from 192.168.0.181: icmp_seq=1 ttl=64 time=2.49 ms 64 bytes from 192.168.0.181: icmp_seq=2 ttl=64 time=1.70 ms 64 bytes from 192.168.0.181: icmp_seq=3 ttl=64 time=2.15 ms ^C --- 192.168.0.181 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2004ms rtt min/avg/max/mdev = 1.703/2.118/2.498/0.325 ms [root@x86 ~]#[root@aarch64 ~]# route -n # 查看路由 Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 172.16.100.11 0.0.0.0 UG 0 0 0 eth0 169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0 172.16.100.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0 [root@aarch64 ~]# [root@aarch64 ~]# ping 172.16.100.11 # 可以通 PING 172.16.100.11 (172.16.100.11) 56(84) bytes of data. 64 bytes from 172.16.100.11: icmp_seq=1 ttl=64 time=0.558 ms 64 bytes from 172.16.100.11: icmp_seq=2 ttl=64 time=0.591 ms 64 bytes from 172.16.100.11: icmp_seq=3 ttl=64 time=0.587 ms ^C --- 172.16.100.11 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2097ms rtt min/avg/max/mdev = 0.558/0.578/0.591/0.031 ms [root@aarch64 ~]#结论:对于中间的 arm64v8 这台主机来说,有两个直连网段,192.168.0.0/24 网段和 172.16.100.0/24 网段,同一网段内的主机可以相互通信是理所当然的。
-
x86 主机 ping arm64v8 主机 172.16.100.11 网卡,x86 主机 ping aarch64 主机 172.16.100.12 网卡。
[root@x86 ~]# ping 172.16.100.11 # 可以通 PING 172.16.100.11 (172.16.100.11) 56(84) bytes of data. 64 bytes from 172.16.100.11: icmp_seq=1 ttl=64 time=3.44 ms 64 bytes from 172.16.100.11: icmp_seq=2 ttl=64 time=1.60 ms 64 bytes from 172.16.100.11: icmp_seq=3 ttl=64 time=1.66 ms ^C --- 172.16.100.11 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2004ms rtt min/avg/max/mdev = 1.606/2.239/3.446/0.855 ms [root@x86 ~]# [root@x86 ~]# ping 172.16.100.12 # 不可以通 PING 172.16.100.12 (172.16.100.12) 56(84) bytes of data. ^C --- 172.16.100.12 ping statistics --- 32 packets transmitted, 0 received, 100% packet loss, time 31011ms [root@x86 ~]#结论:这个实验可能会让人疑惑,因为它涉及一个很重要的知识点,IP 地址属于内核,不属于网卡。
-
对于 arm64v8 这台主机来说,内核手里握着两个 IP 地址,192.168.0.181 和 172.16.100.11,x86 主机的 192.168.0.124 跟 arm64v8 主机的 192.168.0.181 属于直连,也就是说可以直达 arm64v8 主机的内核网络栈,所以可以 ping 通 172.16.100.11。
-
而 172.16.100.12 并不在 arm64v8 主机内核手上,而在另外一个主机 aarch64 内核手上,x86 主机想要通过 arm64v8 主机 ping 通 aarch64 主机,必须要求 arm64v8 这个主机开启转发功能。
方法:echo 1 > /proc/sys/net/ipv4/ip_forward
-
-
开启 arm64v8 主机的转发功能,x86 主机再 ping aarch64 主机的 172.16.100.12 试试
[root@arm64v8 ~]# echo 1 > /proc/sys/net/ipv4/ip_forward [root@arm64v8 ~]# cat /proc/sys/net/ipv4/ip_forward 1 [root@arm64v8 ~]#[root@x86 ~]# ping 172.16.100.12 # 可以通 PING 172.16.100.12 (172.16.100.12) 56(84) bytes of data. 64 bytes from 172.16.100.12: icmp_seq=1 ttl=63 time=4.17 ms 64 bytes from 172.16.100.12: icmp_seq=2 ttl=63 time=2.96 ms 64 bytes from 172.16.100.12: icmp_seq=3 ttl=63 time=2.35 ms 64 bytes from 172.16.100.12: icmp_seq=4 ttl=63 time=3.16 ms 64 bytes from 172.16.100.12: icmp_seq=5 ttl=63 time=2.16 ms ^C --- 172.16.100.12 ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4006ms rtt min/avg/max/mdev = 2.163/2.963/4.175/0.711 ms [root@x86 ~]#
2.5.8.2、配置网关防火墙
打开转发后就可以对 filter 表的 FORWARD 链进行设置了,只要是被 forward 的数据包都会受到防火墙的 "钩子伺候",并进行一番检查。
要注意的是,此时防火墙是负责两个网段的,转发后的数据包状态并不会因为经过 FORWARD 而改变。
比如 x86 主机发送 NEW 状态的数据包到 aarch64 主机,经过 arm64v8 主机 FORWARD 链到达 aarch64 主机,数据包的状态还是 NEW。
实验步骤(延续上一个实验):
-
当前 arm64v8 主机已打开转发,192.168.0.124 可以 ping 通 172.16.100.12;设置 arm64v8 主机 FORWARD 链为 DROP,看能否 ping 通。
[root@x86 ~]# ping 172.16.100.12 # 当前可以 Ping 通 PING 172.16.100.12 (172.16.100.12) 56(84) bytes of data. 64 bytes from 172.16.100.12: icmp_seq=1 ttl=63 time=1.74 ms 64 bytes from 172.16.100.12: icmp_seq=2 ttl=63 time=2.22 ms 64 bytes from 172.16.100.12: icmp_seq=3 ttl=63 time=2.81 ms ^C --- 172.16.100.12 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2003ms rtt min/avg/max/mdev = 1.745/2.259/2.810/0.437 ms [root@x86 ~]#[root@arm64v8 ~]# iptables -P FORWARD DROP # 设置 FORWARD 默认 DROP[root@x86 ~]# ping 172.16.100.12 # 不通 PING 172.16.100.12 (172.16.100.12) 56(84) bytes of data. ^C --- 172.16.100.12 ping statistics --- 7 packets transmitted, 0 received, 100% packet loss, time 6004ms [root@x86 ~]# -
arm64v8 主机 FORWARD 链设置如下规则,再 ping。
[root@arm64v8 ~]# iptables -A FORWARD -m state --state NEW,ESTABLISHED -j ACCEPT[root@x86 ~]# ping 172.16.100.12 # 可以通 PING 172.16.100.12 (172.16.100.12) 56(84) bytes of data. 64 bytes from 172.16.100.12: icmp_seq=1 ttl=63 time=4.14 ms 64 bytes from 172.16.100.12: icmp_seq=2 ttl=63 time=4.27 ms 64 bytes from 172.16.100.12: icmp_seq=3 ttl=63 time=7.98 ms- 转发过程中,数据包的状态是不会变的,所以在 FORWARD 链中定义规则类似其它链,只是数据包的来回都是通过 FORWARD 链。
2.5.8.3、SNAT
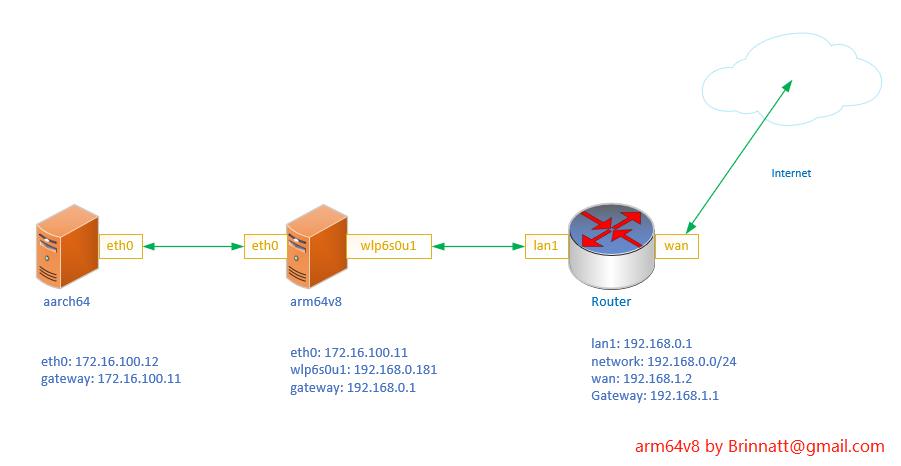
该实验环境是我当前的生产环境:aarch64 主机和 arm64v8 主机都是办公台式机,网络拓扑和关键信息如图所示。由于移动运营商不再为用户提供动态公网 IP 地址,所以路由器 WAN 口也是私有地址;我的办公 Router 和运营商的 Router 都默认设置 SNAT,因此,当前可以连入互联网的节点截止到 arm64v8 这台主机,aarch64 主机不能上网。
现在使用 SNAT 技术使 aarch64 主机也可以上网,很明显需要在 arm64v8 这台主机上面配置。
[root@aarch64 ~]# ping baidu.com # 当前是 ping 不通 baidu.com
^C
[root@aarch64 ~]#[root@arm64v8 ~]# echo 1 > /proc/sys/net/ipv4/ip_forward
[root@arm64v8 ~]# cat /proc/sys/net/ipv4/ip_forward
1
[root@arm64v8 ~]#
[root@arm64v8 ~]# iptables -t nat -A POSTROUTING -s 172.16.100.0/24 -j SNAT --to-source 192.168.0.181
[root@arm64v8 ~]#[root@aarch64 ~]# ping baidu.com # 现在 ping baidu.com 可以通
PING baidu.com (220.181.38.251) 56(84) bytes of data.
64 bytes from 220.181.38.251 (220.181.38.251): icmp_seq=1 ttl=46 time=48.9 ms
64 bytes from 220.181.38.251 (220.181.38.251): icmp_seq=3 ttl=46 time=146 ms
64 bytes from 220.181.38.251 (220.181.38.251): icmp_seq=5 ttl=46 time=145 ms另外,设置 SNAT 的写法有多种方式,如下:
iptables -t NAT -A POSTROUTING -s 172.16.100.0/24 -o wlp6s0u1 -j SNAT --to-source 192.168.0.181
iptables -t NAT -A POSTROUTING -s 172.16.100.0/24 -o wlp6s0u1 -j SNAT --to-source 192.168.0.100-192.168.0.200
iptables -t NAT -A POSTROUTING -s 172.16.100.0/24 -o wlp6s0u1 -j MASQUERADE- 第一条语句表示将内网1向外发出的数据包进行处理,将源地址转换为 192.168.0.181。
- 第二条语句表示将源地址转换成 192.168.0.{100-200} 之间的某个地址。
- 第三条语句表示动态获取流出接口 wlp6s0u1 的地址,并将源地址转换为此地址。这称为地址伪装(ip masquerade),地址伪装功能很实用,但是相比前两种,性能要稍差一些,因为处理每个数据包时都要获取 wlp6s0u1 的地址,也就是说多了一个查找动作。
2.5.8.4、DNAT
该实验把 x86 主机当作公网主机,arm64v8 主机当作防火墙,aarch64 主机当作内网私有服务器。
使用 DNAT 技术实现映射 192.168.0.181:7422 --> 172.16.100.12:22,从 x86 主机 ssh 到 192.168.0.181:7422 如果最终是 ssh 到 aarch64 主机,则实验成功。
[root@arm64v8 ~]# iptables -t nat -A PREROUTING -d 192.168.0.181/32 -p tcp --dport 7422 -j DNAT --to-destination 172.16.100.12:22
[root@arm64v8 ~]#[root@x86 ~]# ssh -p 7422 192.168.0.181
root@192.168.0.181's password:
Last login: Thu Oct 7 04:25:39 2021 from 192.168.0.124
[root@aarch64 ~]# # 很明显,实验成功;提示:在生产应用环境中,一般是使用公网 IP:PORT 映射到私网 IP:PORT 才具有实际生产意义。
2.5.9、mangle 表
mangle 表的主要功能是根据规则修改数据包的一些标志位,以便其他规则或程序可以利用这种标志对数据包进行过滤或策略路由。
一般来说,mangle 表的使用概率还是比较小的,在大型框架设计当中才有可能使用到 mangle 表,用来制定一些策略路由,无论是代码实现还是手动实现,大致思路如下:
-
创建路由表
编辑 /etc/iproute2/rt_tables,注意不要动里面默认的路由表。添加路由表条目格式如下:
[ID of your Table] [Name of your table]默认的路由表如下:
[root@arm64v8 ~]# grep -v "^#" /etc/iproute2/rt_tables 255 local 254 main 253 default 0 unspec [root@arm64v8 ~]#使用 ip route 命令查看路由表:
[root@arm64v8 ~]# ip route show table 254 default via 192.168.0.1 dev wlp6s0u1 proto dhcp metric 600 172.16.100.0/24 dev eth0 proto kernel scope link src 172.16.100.11 metric 100 192.168.0.0/24 dev wlp6s0u1 proto kernel scope link src 192.168.0.181 metric 600 [root@arm64v8 ~]# [root@arm64v8 ~]# ip route show table main default via 192.168.0.1 dev wlp6s0u1 proto dhcp metric 600 172.16.100.0/24 dev eth0 proto kernel scope link src 172.16.100.11 metric 100 192.168.0.0/24 dev wlp6s0u1 proto kernel scope link src 192.168.0.181 metric 600 [root@arm64v8 ~]# [root@arm64v8 ~]# ip route show default via 192.168.0.1 dev wlp6s0u1 proto dhcp metric 600 172.16.100.0/24 dev eth0 proto kernel scope link src 172.16.100.11 metric 100 192.168.0.0/24 dev wlp6s0u1 proto kernel scope link src 192.168.0.181 metric 600 [root@arm64v8 ~]#为路由表指定默认的路由设备:
ip route add default dev "${TUNDEV}" src "${INTERNAL_IP4_ADDRESS}" table "${TABLENAME}"# 在路由表100上添加一个默认路由(对所有地址), 使用本地网关192.168.1.1, 这是一个可以从eth0到达的地址 ip route add default via 192.168.1.1 dev eth0 table 100# 对10.1.1.0/30这个目的地址范围添加路由规则, 并添加MPLS标签 ip route add 10.1.1.0/30 encap mpls 200/300 via 10.1.1.1 dev eth0 -
数据包走哪个路由表
默认每个数据报文走的路由表都是 main,你可以给满足一定规则的数据报文指定不同的路由表, 而未满足的还继续使用默认的路由表。
-
路由规则
通过 man ip rule 可以获取参数列表, 如果还不够,你可以使用 fwmark 给数据报文打 fwmark 标签,可以通过 iptables 来处理,然后通过 ip rule 来处理。例如:
# 来源于 167.99.208.0/24 的用指定table ip rule add from 167.99.208.0/24 table [table-name] # 所有来源都用 table ztable1 ip rule add from all table ztable1 # 所有来源中带标签2的都用table 20 ip rule add from all fwmark 2 table 20 -
iptables 打标签
使用的格式为
-j MARK --set-mark <Your marknumber in decimal form>。MARK 这个 target 只在 mangle 中有效。对于流入的数据报文可以使用
-t mangle -A PREROUTING,对于流出的数据报文可以使用-t mangle -A OUTPUT。注意:当数据报文被进程(例如 apache)处理过之后,标签就丢失了。所以如果打过标签的报文在返回时不正确,只给流入的报文打标签是不够的,你必须给产生的流出报文也打上标签。
案例一:
内网的客户机通过 Linux 主机连入 Internet,而 Linux 主机有两个网口与 Internet 连接,分别有两条线路,它们的网关分别为 10.10.1.1 和 10.10.2.1。现要求对内网进行策略路由,所有通过 TCP 协议访问 80 端口的数据包都从 10.10.1.1 线路出去,而所有访问 UDP 协议 53 号端口的数据包都从 10.10.2.1 线路出去。
这是一个策略路由的问题,为了达到目的,在对数据包进行路由前,要先根据数据包的协议和目的端口给数据包做上一种标志,然后再指定相应规则,根据数据包的标志进行策略路由。
为了给特定的数据包做上标志,需要使用 mangle 表,mangle 表共有 5 条链,由于需要在路由选择前做标志,因此应该使用 PREROUTING 链,下面是具体的命令。
iptables -t mangle -A PREROUTING -i eth0 -p tcp --dport 80 -j MARK --set-mark 1
iptables -t mangle -A PREROUTING -i eth0 -p udp --dprot 53 -j MARK --set-mark 2 以上命令在 mangle 表的 PREROUTING 链中添加规则,为来自 eth0 接口的数据包做标志,其匹配规则分别是 TCP 协议、目的端口号是 80 和 UDP 协议、目的端口号是 53,标志的值分别是 1 和 2。数据包经过 PREROUTING 链后,将要进入路由选择模块,为了对其进行策略路由,执行以下两条命令,添加相应的规则。
编辑 /etc/iproute2/rt_tables,添加对应的路由表:
echo -e "${TABLEID}\t${TABLENAME}" >> /etc/iproute2/rt_tables添加路由:
ip rule add from all fwmark 1 table 10
ip rule add from all fwmark 2 table 20 - 两条命令表示所有标志是 1 的数据包使用路由表 10 进行路由,而所有标志是 2 的数据包使用路由表 20 进行路由。
- 路由表 10 和 20 分别使用了 10.10.1.1 和 10.10.2.1 作为默认网关。
- fwmark 实际上就是 netfilter mark,一种打标签的方式或者实现,没有特殊的含义。
ip route add default via 10.10.1.1 dev eth1 table 10
ip route add default via 10.10.2.1 dev eth2 table 20- 两条命令在路由表 10 和 20 上分别指定了 10.10.1.1 和 10.10.2.1 作为默认网关,于是使用路由表 10 的数据包将通过 10.10.1.1 线路出去,而使用路由表 20 的数据包将通过 10.10.2.1 线路出去。
案例二:
网关服务器有三块网卡:
- eth0 网通 ip:10.0.0.1
- eth1 电信 ip:20.0.0.1
- eth2 网关 ip:192.168.10.1
内网要求 192.168.10.1---100 以内的 ip 使用 10.0.0.1 网关上网,其他 IP 使用 20.0.0.1 上网。
# 设置默认路由
ip route add default gw 20.0.0.1
# eth0 是 10.0.0.1 所在的网卡, 10是路由表的编号
ip route add table 10 via 10.0.0.1 dev eth0
# fwmark 10 是标记, table 10 是路由表10, 标记了10的数据使用table 10路由表
ip rule add fwmark 10 table 10
# 使用iptables给相应的数据打上标记, 对于这种IP范围需要用到iprange模块
iptables -A PREROUTING -t mangle -i eth2 -m iprange --src-range 192.168.10.1-192.168.10.100 -j MARK --set-mark 10案例三:
网关服务器有三块网卡:
- eth0 网通 ip:10.0.0.1
- eth1 电信 ip:20.0.0.1
- eth2 网关 ip:192.168.10.1
内网要求员工访问外面的网站使用 10.0.0.1 网关上网,其他 IP 使用 20.0.0.1 上网。
iptables -t mangle -A PREROUTING -i eth2 -p tcp --dport 80 -j MARK --set-mark 20
ip route add default gw 20.0.0.1
ip route add table 20 via 10.0.0.1 dev eth0
ip rule add fwmark 20 table 20 2.5.10、raw 表
RAW 表只使用在 PREROUTING 链和 OUTPUT 链上,因为优先级最高,从而可以对收到的数据包在连接跟踪前进行处理。一但用户使用了 RAW 表处理完后,将跳过 NAT 表和 nf_conntrack 处理,即不再做地址转换和数据包的链接跟踪处理了。
RAW 表可以应用在那些不需要做 nat 的情况下,以提高性能。如大量访问的 web 服务器,可以让 80 端口不再让 iptables 做数据包的链接跟踪处理,以提高用户的访问速度。
增加 raw 表,在其他表处理之前,-j NOTRACK 跳过其它表处理,对应的 state 为 UNTRACKED。
例如:可以使用 "NOTRACK" target 允许规则指定 80 端口的包不进入链接跟踪或 NAT 子系统。
[root@arm64v8 ~]# iptables -t raw -A PREROUTING -d 192.168.0.181/32 -p tcp --dport 80 -j NOTRACK
[root@arm64v8 ~]# iptables -t raw -A PREROUTING -s 192.168.0.181/32 -p tcp --sport 80 -j NOTRACK
[root@arm64v8 ~]# iptables -A FORWARD -m state --state UNTRACKED -j ACCEPT
[root@arm64v8 ~]#-
在启用了 iptables web 服务器上,流量高的时候经常会出现错误:
ip_conntrack: table full, dropping packet。- 这个问题的原因是由于 web 服务器收到了大量的连接,在启用了 iptables 的情况下,iptables 会把所有的连接都做链接跟踪处理,这样 iptables 就会有一个链接跟踪表,当这个表满的时候,就会出现上面的错误。
- iptables 的链接跟踪表最大容量为
/proc/sys/net/ipv4/ip_conntrack_max,链接碰到各种状态的超时后就会从表中删除。
-
解决该问题的思路一般有三个:
- 加大 ip_conntrack_max 值
vi /etc/sysctl.conf net.ipv4.ip_conntrack_max = 393216 net.ipv4.netfilter.ip_conntrack_max = 393216- 降低 ip_conntrack timeout 时间
vi /etc/sysctl.conf net.ipv4.netfilter.ip_conntrack_tcp_timeout_established = 300 net.ipv4.netfilter.ip_conntrack_tcp_timeout_time_wait = 120 net.ipv4.netfilter.ip_conntrack_tcp_timeout_close_wait = 60 net.ipv4.netfilter.ip_conntrack_tcp_timeout_fin_wait = 120- 使用 raw 表制定不跟踪链接
iptables -t raw -A PREROUTING -d 192.168.0.181/32 -p tcp --dport 80 -j NOTRACK iptables -t raw -A PREROUTING -s 192.168.0.181/32 -p tcp --sport 80 -j NOTRACK iptables -A FORWARD -m state --state UNTRACKED -j ACCEPT
2.5.11、防火墙最佳实践
这里说的最佳实践只是针对某个服务器,对外提供服务时,在没有专业硬件防火墙的前提下,通过 iptables 实现比较严格的流量控制。
-
安装 iptables-services 软件包,启动 iptables 服务。
yum install iptables-services -y systemctl start iptables.service systemctl enable iptables.service -
避免 flush 后默认规则都是 DROP 无法远程
iptables -P INPUT ACCEPT iptables -P OUTPUT ACCEPT iptables -P FORWARD ACCEPT iptables -F iptables -t nat -F iptables -X iptables -t nat -X -
首先可以让 ssh 能连接
iptables -A INPUT -p tcp --dport 22 -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A OUTPUT -p tcp --sport 22 -m state --state ESTABLISHED -j ACCEPT -
保证 apt-get 或 yum 可以使用
iptables -A OUTPUT -m state --state RELATED,ESTABLISHED -j ACCEPT iptables -A OUTPUT -p tcp -m multiport --destination-ports 80,53,443 -m state --state NEW -j ACCEPT iptables -A OUTPUT -p udp --dport 53 -m state --state NEW -j ACCEPT iptables -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT -
正常情况这个总是要配置的,自己要能跟自己通信
iptables -A INPUT -i lo -j ACCEPT iptables -A OUTPUT -o lo -j ACCEPT -
以上配置都正确则可以设置默认 DROP,这个比较危险,没有把握时,建议在写 iptables 前写个 at 计划或者 crontab 来清空规则
iptables -P INPUT DROP iptables -P OUTPUT DROP iptables -P FORWARD DROP -
保存规则
centos7: iptables-save > /etc/sysconfig/iptables # 启动 iptables 服务后自动生效 ubuntu 16.04: iptables-save > /etc/iptables-rules # 不会自动生效 post-up iptables-restore < /etc/iptables-rules # 在 /etc/network/interface 后面加上一行
2.6、tcp_wrapper 过滤
wrap 工作在内核空间和应用程序中间的库层次中。在内核接受到数据包准备传送到用户空间时都会经过库层次,对于部分(只是部分)应用程序会在经过库层次时会被 wrap 库文件阻挡下来检查一番,如果允许通过则交给应用程序。
2.6.1、查看是否支持 wrapper
wrap 只会检查 tcp 数据包,所以称为 tcpwrapper。但还不是检查所有类型的 tcp 数据包,例如 httpd 就不支持。是否支持,可以通过查看应用程序是否依赖于 libwrap.so 库文件。(路径 /lib64/libwrap.so)
[root@arm64v8 ~]# ldd $(which sshd) | grep wrap
libwrap.so.0 => /lib64/libwrap.so.0 (0x0000ffffb7360000)
[root@arm64v8 ~]#[root@arm64v8 ~]# ldd $(which vsftpd) | grep wrap
libwrap.so.0 => /lib64/libwrap.so.0 (0x0000ffffa0494000)
[root@arm64v8 ~]#[root@arm64v8 ~]# ldd $(which httpd) | grep wrap
[root@arm64v8 ~]#说明 sshd 和 vsftpd 都支持 wrap 机制,而 apache 的 httpd 不支持。
当然上面 grep 不出结果只能说明不支持这样的动态链接的方式,有些应用程序可能静态编译进程序中了,如旧版本的 rpc 应用程序 portmap。
是否将 wrap 功能静态编译到应用程序中,可以通过以下方式查看。
strings $(which portmap) | grep hosts如果筛选出的结果中有 hosts_access 或者 /etc/hosts.allow 和 /etc/hosts.deny 这两个文件,则说明是支持的。后两个文件正是 wrap 访问控制的文件。
要注意的是,如果超级守护进程 xinetd 被 wrap 控制了,则其下的瞬时守护进程都受 wrap 控制。
2.6.2、配置文件格式
hosts.allow 和 hosts.deny 两个文件的语法格式是一样的,如下:
daemon_list: client_list [:options]daemon_list 表示方法:程序名必须是 which 查出来同名的名称,例如此处的 in.telnetd
sshd:
sshd,vsftpd,in.telnetd:
ALL
daemon@host:最后一项 daemon@host 指定连接 IP 地址,针对多个 IP 的情况。如本机有 192.168.100.8 和 172.16.100.1 两个地址,但是只想控制从其中一个 ip 连接的 vsftpd 服务,可以写 "vsftpd@192.168.100.8:"。
client_list 表示方法:
单IP:192.168.100.8
网段:两种写法:"172.16."和10.0.0.0/255.0.0.0
主机名或域匹配:fqdn或".a.com"
宏:ALL、KNOWN、UNKNOWN、PARANOID、EXCEPTALL 表示所有主机;LOCAL 表示和主机在同一网段的主机;(UN)KNOWN 表示 DNS 是否可以解析成功的;PARANOID 表示正解反解不匹配的;EXCEPT 表示 "除了"。
它们的语法可以 man hosts_access。
tcpwrapper 的检查顺序:hosts.allow --> hosts.deny --> 允许(默认规则)
例如 sshd 仅允许 172.16 网段主机访问。
hosts.allow:
sshd: 172.16.
hosts.deny:
sshd: ALLtelnet 服务不允许 172.16 网段访问但允许 172.16.100.200 访问。有几种表达方式:
表达方式一:
hosts.allow:
in.telnetd: 172.16.100.200
hosts.deny:
in.telnetd: 172.16.表达方式二:
hosts.deny:
in.telnetd: 172.16. EXCEPT 172.16.100.200- 此法不能写入 hosts.allow:"in.telnetd: 172.16.100.200 EXCEPT 172.16."
表达方式三:
hosts.allow:
in.telnetd: ALL EXCEPT 172.16. EXCEPT 172.16.100.200
hosts.deny:
in.telnetd: ALLEXCEPT 的最形象描述是 “在其前面的范围内挖一个洞,在洞范围内的都不匹配”。所以 hosts.allow 中,ALL 内有一个 172.16 的洞是不被 allow 的,在 172.16 中又有小洞 172.16.100.200 是被排除在 172.16 洞外的,所以 172.16.100.200 是被 allow 的。
注意:被 EXCEPT 匹配到的表示不经过此条规则的检查,而不是反意。例如在 allows 中指明一个 EXCEPT,当有 except 中的主机被匹配到,表示的不是该主机被拒绝。而是跳过 allow 检测进入 deny 的检测。
:options 表达方式:
:ALLOW
:DENY
:spawnALLOW 和 DENY 可以分别写入 deny 文件和 allow 文件,表示在 allow 文件中拒绝在 deny 文件中接受。如 allow 文件中:
in.telnetd: 172.16. :DENYspawn 表示启动某程序的意思(/etc/inittab 中的 respawn 表示重启指定程序)。例如启动一个 echo 程序。
in.telnetd: 172.16 :spawn echo "we are good $(date) >> /var/log/telnetd.log"